Curso
Introdução ao SQL Server
4 h
170.3K
As consultas SQL podem fazer muito mais do que recuperar ou manipular dados. O SQL tem muitas funções que nos permitem fazer análises avançadas que podem ser cruciais em nossos relatórios de business intelligence.
Uma dessas funções poderosas é a função LAG(), que é uma das funções de janela comumente usadas. Isso abre a porta para que você compare e calcule a alteração nos valores em uma sequência de dados. É por isso que as funções podem ser cruciais, especialmente para a análise de séries temporais em SQL.
A função LAG() é uma das funções de janela do SQL que permite que você crie uma nova coluna que acesse uma linha anterior de outra coluna. O nome se deve ao fato de que cada linha da nova coluna que você cria estaria atrasada para buscar um valor de uma linha anterior na outra coluna que você especificar.
Vamos ver a sintaxe básica em ação. Suponhamos que você tenha uma tabela simples de duas colunas com preços diários de ações com a seguinte aparência:
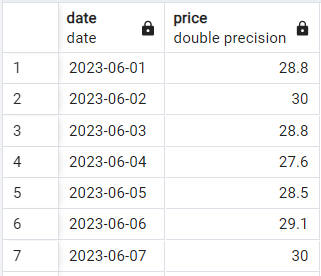
Amostra de dados de preços de ações. Imagem do autor.
Você pode usar a consulta a seguir para criar uma nova coluna que obtenha o preço do dia anterior em cada linha com a seguinte consulta:
SELECT date,
price,
LAG(price) OVER(ORDER BY date) AS one_day_before
FROM stock_price;E teríamos o seguinte resultado:
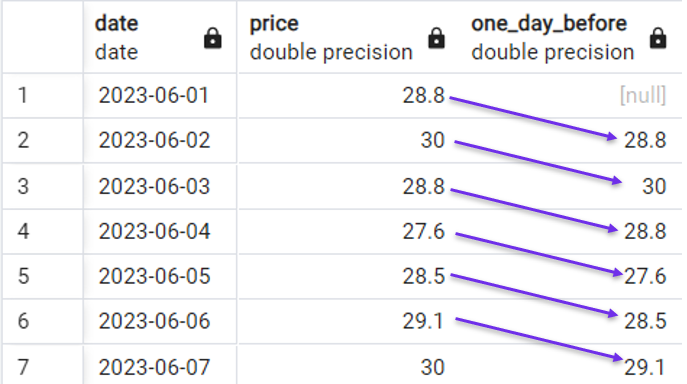
Exemplo rápido de uso da função LAG(). Imagem do autor.
Observe que introduzimos um valor [null] porque não há valor do dia anterior para a primeira linha.
A função LAG() é escrita como parte da cláusula SELECT. Em sua sintaxe mais básica, a função pode ser escrita da seguinte forma:
LAG(column1) OVER(ORDER BY column2)Aqui está a mesma função LAG() aplicada em uma consulta autônoma:
SELECT
column1,
column2,
LAG(column1) OVER (ORDER BY column2) AS previous_value
FROM
table_name;Como você pode ver, a sintaxe básica consiste em várias partes. Vamos detalhá-los juntos:
OVER() é uma palavra-chave obrigatória para todas as funções de janela. A cláusula define o quadro no qual a função de janela será executada. No exemplo acima, a função de janela será executada no site ordenado column2.ORDER BY não é obrigatório, mas é altamente recomendado quando usado com a função LAG(); normalmente, a função não faz sentido sem ele. LAG() seguirá. Mais de uma coluna pode ser usada como base para a classificação.Você deve estar se perguntando o que há de tão bom na função LAG(). Bem, a resposta é que a nova coluna de atraso pode ser usada para comparar valores de duas linhas diferentes.
É por isso que a função LAG() é comumente usada com dados de séries temporais. Por exemplo, em nosso conjunto de dados de demonstração, podemos calcular facilmente a alteração diária no preço das ações com a seguinte consulta:
SELECT date,
price,
LAG(price) OVER(ORDER BY date) AS one_day_before,
price - LAG(price) OVER(ORDER BY date) AS daily_change
FROM stock_price; 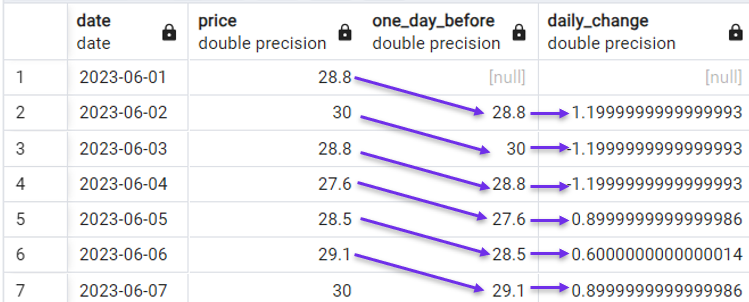
Cálculo da mudança diária com LAG(). Imagem do autor.
Também podemos passar para um cálculo mais sofisticado e considerar as alterações percentuais diárias.
SELECT date,
price,
LAG(price) OVER(ORDER BY date) AS one_day_before,
price - LAG(price) OVER(ORDER BY date) AS daily_change,
((price - LAG(price) OVER(ORDER BY date))*100 /
(LAG(price) OVER(ORDER BY date))) AS daily_perc_change
FROM stock_price; 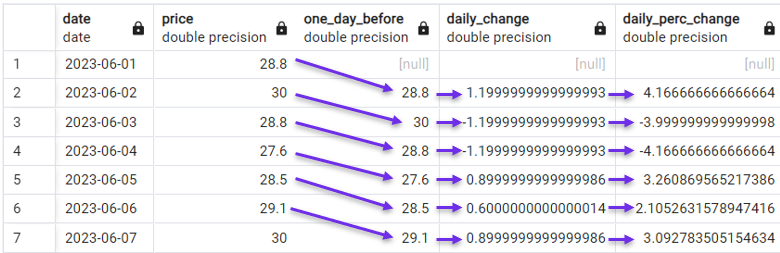
Cálculo da variação percentual diária com LAG(). Imagem do autor.
Agora que você já entendeu o uso básico da função LAG(), vamos melhorar nosso jogo passo a passo e ver o que mais podemos fazer com ela.
Aqui, mudaremos para outro conjunto de dados de demonstração que registra a receita mensal de três empresas imaginárias: Welsh LLC, Jones Group e Green-Keebler, do início de 2022 até meados de 2024. É assim que os dados são estruturados:
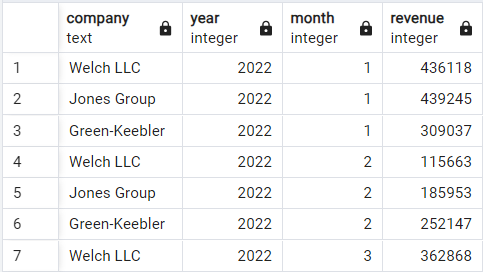
Conjunto de dados de receitas de demonstração. Imagem do autor.
Em nosso novo conjunto de dados, a coluna de atraso deve ser ordenada com base em duas colunas: year e month. Como mencionamos anteriormente, isso pode ser feito fornecendo as duas colunas à cláusula ORDER BY.
Na consulta a seguir, criamos uma coluna de defasagem e uma coluna de diferença de receita mês a mês (MoM), ordenadas de acordo com year e month. Também filtramos nossa consulta com uma cláusula WHERE para que você se concentre em uma empresa por enquanto.
SELECT *,
LAG(revenue) OVER(ORDER BY year, month) AS one_month_before,
revenue - LAG(revenue) OVER(ORDER BY year, month) AS mom_difference
FROM revenues
WHERE company = 'Welch LLC'; 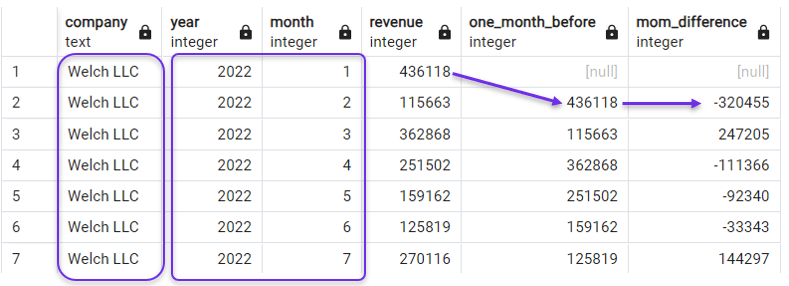
Ordenação por ano e mês para LAG(). Imagem do autor.
Suponha que queiramos calcular as mesmas duas colunas para as três empresas que temos em nosso conjunto de dados. Se as calcularmos da mesma forma que usamos a função LAG() até agora, a coluna de defasagem estaria percorrendo as três empresas, e a coluna de diferença estaria misturando as receitas de todas elas, e não é isso que queremos.
O que queremos é obter a receita do mês anterior e calcular a diferença do MoM para cada empresa isoladamente e, em seguida, recomeçar para a nova empresa.
Para isso, introduzimos uma nova cláusula em nossa sintaxe da função LAG(). Essa cláusula é PARTITION BY, e pode ser adicionada à nossa sintaxe básica da seguinte forma:
LAG(column1) OVER(PARTITION BY column3 ORDER BY column2)A coluna pela qual precisamos fazer a partição em nosso exemplo é company. Portanto, modificaremos nossa consulta anterior adicionando a cláusula PARTITION BY e retirando a declaração WHERE.
SELECT *,
LAG(revenue) OVER(PARTITION BY company ORDER BY year, month) AS one_month_before,
revenue - LAG(revenue) OVER(PARTITION BY company ORDER BY year, month) AS mom_difference
FROM revenues;No resultado, você verá que as colunas de atraso e MoM agora percorrem apenas as receitas mensais da primeira empresa e, em seguida, recomeçam para a próxima. Podemos ver isso na captura de tela abaixo, que mostra os últimos meses da Green-Keebler e os primeiros meses do Jones Group.
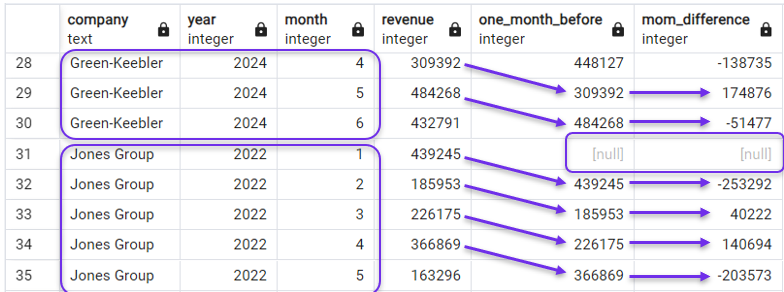
Usando PARTITION BY com LAG(). Imagem do autor.
E se não precisarmos buscar o valor da linha anterior, mas de seis ou doze linhas acima? Em outras palavras, e se precisarmos calcular a diferença ano a ano (YoY) em vez do MoM?
Nesse caso, adicionaríamos um novo parâmetro à sintaxe da função LAG(). Esse parâmetro é chamado de offset e especifica quantas linhas acima da linha atual queremos que a função LAG() obtenha o valor. Sua posição na sintaxe é mostrada abaixo:
LAG(column1, offset) OVER(PARTITION BY column3 ORDER BY column2)Por padrão, e pela forma como usamos a função até agora, o valor do deslocamento é igual a um. No entanto, ao especificar explicitamente o deslocamento na expressão LAG(), podemos alterar esse parâmetro padrão.
Voltando ao nosso exemplo, para obter a variação da receita anual, precisamos obter a receita do mesmo mês no ano anterior. Você pode fazer isso com a seguinte consulta, na qual especificamos 12 como nosso deslocamento:
SELECT *,
LAG(revenue, 12) OVER(PARTITION BY company ORDER BY year, month) AS one_year_before,
revenue - LAG(revenue, 12) OVER(PARTITION BY company ORDER BY year, month) AS yoy_difference
FROM revenues;E o resultado seria:
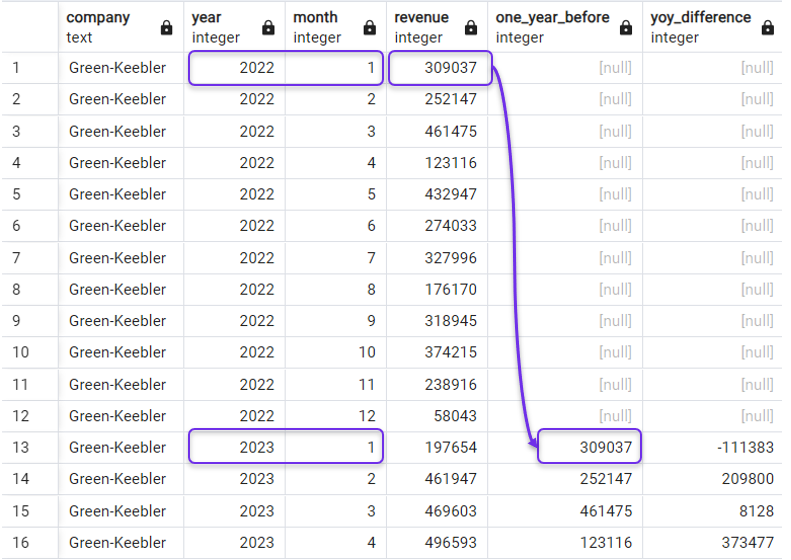
Diferença ano a ano com LAG(). Imagem do autor.
Você deve ter notado que a função LAG() retorna NULL nas linhas em que os períodos anteriores não estão disponíveis, como nas linhas do ano de 2022 em nossa consulta anterior.
Esse é o comportamento padrão da função LAG(), mas pode ser alterado especificando explicitamente um novo parâmetro chamado "default". Esse parâmetro pode receber qualquer valor numérico inteiro ou flutuante. Na sintaxe da função, o parâmetro é posicionado da seguinte forma:
LAG(column1, offset, default) OVER(PARTITION BY column3 ORDER BY column2)O caso de uso comum do parâmetro "padrão" é quando os valores realmente começam do zero nos dados da série temporal.
Em nosso exemplo, podemos presumir que as três empresas foram fundadas em janeiro de 2022 (a data mais antiga em nosso conjunto de dados) e, portanto, podemos considerar a receita antes da fundação como zero. Ao fazer isso, calcularemos com mais precisão a mudança nas receitas, pois qualquer receita obtida nos primeiros meses seria uma mudança positiva.
Em nossa consulta, especificaremos zero como o parâmetro "padrão" em ambas as nossas expressões LAG() da seguinte forma:
SELECT *,
LAG(revenue, 12, 0) OVER(PARTITION BY company ORDER BY year, month) AS one_year_before,
revenue - LAG(revenue, 12, 0) OVER(PARTITION BY company ORDER BY year, month) AS yoy_difference
FROM revenues;E o resultado produziria zeros na coluna de defasagem e a receita líquida de zero na coluna de alteração da receita anual:
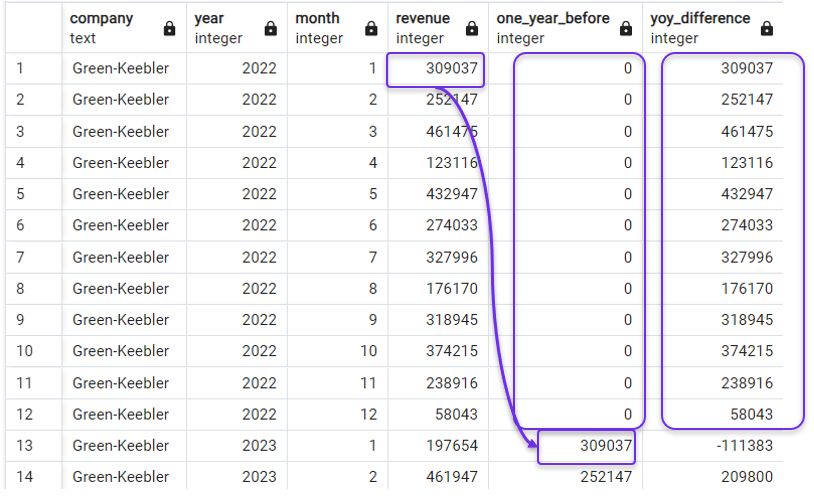
Substituição de NULLs por zeros em LAG(). Imagem do autor.
Observe que, para que você possa especificar explicitamente um valor para o parâmetro "default", é obrigatório especificar explicitamente um valor para o deslocamento também, pois o primeiro número fornecido após o nome da coluna dentro da função LAG() será considerado o deslocamento de qualquer forma.
Se você precisar alterar o "padrão", mas não o deslocamento, defina o parâmetro de deslocamento como um, e ele se comportará como normalmente.
É útil saber que a ordem da qual a função LAG() depende não precisa ser a mesma ordem da exibição resultante. Você sempre pode alterar essa ordem usando normalmente a cláusula ORDER BY em sua consulta.
Em nosso exemplo, podemos reordenar nosso resultado para mostrar o mesmo mês do mesmo ano para as três empresas antes de passar para o próximo mês do ano, ordenando a consulta de acordo com o ano e o mês na cláusula externa ORDER BY:
SELECT *,
LAG(revenue, 12, 0) OVER(PARTITION BY company ORDER BY year, month) AS one_year_before,
revenue - LAG(revenue, 12, 0) OVER(PARTITION BY company ORDER BY year, month) AS yoy_difference
FROM revenues
ORDER BY year, month;E teríamos o que precisamos:
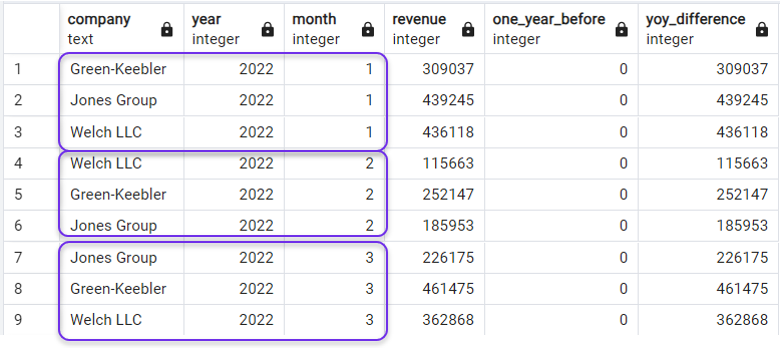
Ordenar a consulta após LAG(). Imagem do autor.
Vamos dar uma olhada nos problemas comuns, caso você precise de ajuda para solucioná-los.
ORDER BY na declaração LAG() pode levar a resultados incorretos. Mesmo que a ordem original da tabela de origem seja adequada para a função, nunca dependa dessa ordem original, pois ela pode mudar com o tempo.ORDER BY na declaração LAG() e certifique-se de que você ordenou pela coluna correta.LAG() devido ao fato de você não ter considerado o uso da cláusula PARTITION BY ou de tê-la usado com a coluna errada. LAG() é executada.NULL na saída da função LAG() quando outro valor for mais adequado, não declarando o parâmetro "default".LAG() em mais de uma coluna, você ainda terá que escrever o comando LAG() completo na segunda coluna, não o seu alias. Se você usar o alias da primeira coluna LAG(), ocorrerá um erro.LAG() por extenso na declaração do SELECT.LAG(), como todas as funções de janela, pode ser computacionalmente cara com grandes conjuntos de dados. Portanto, ignorar a indexação das colunas usadas nas cláusulas PARTITION BY e ORDER BY pode levar a um desempenho ruim.PARTITION BY e ORDER BY sejam indexadas, se possível, para melhorar o desempenho da consulta.LAG() e outras funções de janela podem ficar confusos e não ser fáceis de ler ou entender, especialmente quando mais de uma função é usada.LAG() e outras funções de janela, certifique-se de adicionar comentários e documentar o que a consulta tenta alcançar. Isso ajuda os outros e você mesmo a entender o propósito e a lógica por trás do uso do LAG(), sempre que a consulta for revisitada.Neste tutorial, vimos o que é a função LAG() e como ela pode ser uma ferramenta poderosa para realizar análises de séries temporais. Além disso, exploramos seus argumentos e as cláusulas relacionadas a eles. Na próxima vez que você trabalhar com dados relacionados ao tempo ou com qualquer dado sequenciado no SQL, considere o uso da função LAG() e o que ela permite que você faça. Em outros contextos, a função LAG() é útil para encontrar autocorrelações, suavizar dados ou verificar se há intervalos irregulares como parte da limpeza de dados.
Se você está intrigado com o que uma função de janela pode fazer, pode aprender sobre toda a família e elevar o nível de suas habilidades de análise em SQL com nosso curso interativo abrangente sobre estatísticas de resumo e funções de janela do PostgreSQL . E se você gostou deste artigo, provavelmente gostará de seguir o programa Associate Data Analyst in SQL Career Track e obter a certificação SQL Associate no final!
Aprenda SQL com a DataCamp
Curso
Curso
Curso
Tutorial
Travis Tang
Tutorial
Travis Tang
Tutorial
Travis Tang
Tutorial
Eugenia Anello
Tutorial
Travis Tang
Tutorial
Allan Ouko