
Cours
Introduction à SQL Server
4 h
170.4K
La fonction LAG() est l'une des fonctions de fenêtre de SQL qui vous permet de créer une nouvelle colonne qui accède à une ligne précédente à partir d'une autre colonne. Son nom vient du fait que chaque ligne de la nouvelle colonne que vous créez est retardée pour récupérer une valeur d'une ligne précédente dans l'autre colonne que vous spécifiez.
Voyons la syntaxe de base en action. Supposons que nous disposions d'un tableau simple à deux colonnes contenant les cours quotidiens des actions, qui se présente comme suit :
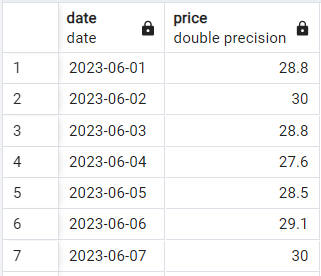
Échantillon de données sur le cours des actions. Image par l'auteur.
Nous pouvons utiliser la requête suivante pour créer une nouvelle colonne qui récupère le prix du jour précédent dans chaque ligne avec la requête suivante :
SELECT date,
price,
LAG(price) OVER(ORDER BY date) AS one_day_before
FROM stock_price;Et nous aurions le résultat suivant :
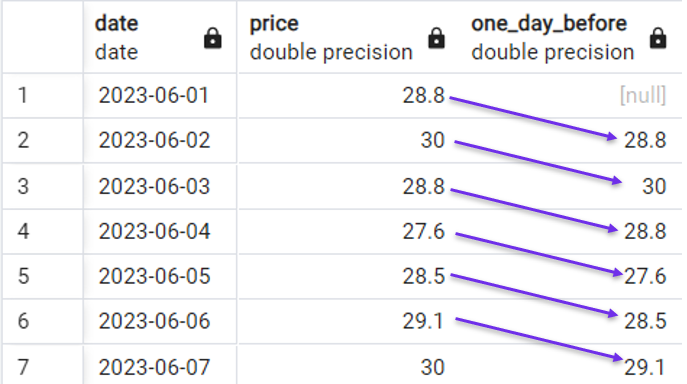
Exemple rapide d'utilisation de la fonction LAG(). Image par l'auteur.
Remarquez que nous avons introduit une valeur [null] parce qu'il n'y a pas de valeur du jour précédent pour la première ligne.
La fonction LAG() est écrite dans le cadre de la clause SELECT. Dans sa syntaxe la plus élémentaire, la fonction peut être écrite comme suit :
LAG(column1) OVER(ORDER BY column2)Voici la même fonction LAG() appliquée à une requête autonome :
SELECT
column1,
column2,
LAG(column1) OVER (ORDER BY column2) AS previous_value
FROM
table_name;Comme vous pouvez le constater, la syntaxe de base se compose de plusieurs parties. Décortiquons-les ensemble :
OVER() est un mot-clé obligatoire pour chaque fonction de fenêtre. La clause définit le cadre dans lequel la fonction de fenêtre sera exécutée. Dans l'exemple ci-dessus, la fonction fenêtre s'exécute sur l'ensemble ordonné column2.ORDER BY n'est pas obligatoire, mais il est fortement recommandé de l'utiliser avec la fonction LAG(); en général, la fonction n'a pas de sens sans cela. LAG() sera exécutée. Plusieurs colonnes peuvent être utilisées comme base de tri.Vous vous demandez peut-être ce qu'il y a de si génial dans la fonction LAG(). La réponse est que la nouvelle colonne de retard peut être utilisée pour comparer les valeurs de deux lignes différentes.
C'est pourquoi la fonction LAG() est couramment utilisée avec les données de séries temporelles. Par exemple, dans notre ensemble de données de démonstration, nous pouvons facilement calculer la variation quotidienne du prix des actions avec la requête suivante :
SELECT date,
price,
LAG(price) OVER(ORDER BY date) AS one_day_before,
price - LAG(price) OVER(ORDER BY date) AS daily_change
FROM stock_price; 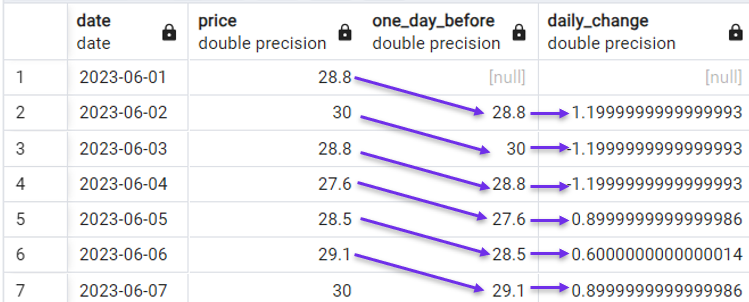
Calcul de la variation journalière avec LAG(). Image par l'auteur.
Nous pouvons également passer à un calcul plus sophistiqué et prendre en compte les variations quotidiennes en pourcentage.
SELECT date,
price,
LAG(price) OVER(ORDER BY date) AS one_day_before,
price - LAG(price) OVER(ORDER BY date) AS daily_change,
((price - LAG(price) OVER(ORDER BY date))*100 /
(LAG(price) OVER(ORDER BY date))) AS daily_perc_change
FROM stock_price; 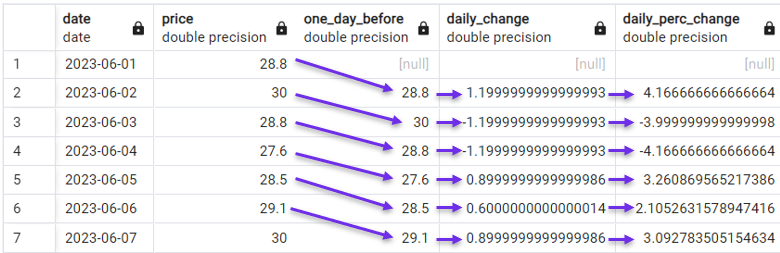
Calcul du pourcentage de changement quotidien avec LAG(). Image par l'auteur.
Maintenant que nous avons compris l'utilisation de base de la fonction LAG(), passons à la vitesse supérieure et voyons ce que nous pouvons faire d'autre avec cette fonction.
Nous allons ici passer à un autre ensemble de données de démonstration qui enregistre les revenus mensuels de trois entreprises imaginaires : Welsh LLC, Jones Group et Green-Keebler, du début de l'année 2022 à la mi-2024. C'est ainsi que les données sont structurées :
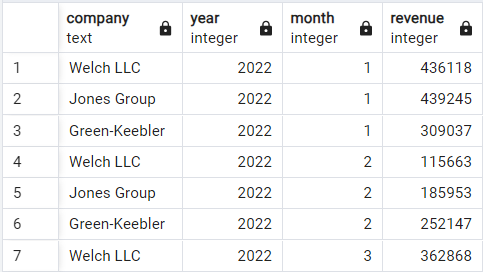
Ensemble de données sur les revenus de démonstration. Image par l'auteur.
Dans notre nouvel ensemble de données, la colonne de retard doit être ordonnée sur la base de deux colonnes : year et month. Comme nous l'avons mentionné précédemment, cela peut être fait en donnant les deux colonnes à la clause ORDER BY.
Dans la requête suivante, nous créons une colonne de décalage et une colonne de différence de revenus d'un mois sur l'autre (MoM), ordonnées selon year et month. Nous filtrons également notre requête à l'aide d'une clause WHERE afin de nous concentrer sur une seule entreprise pour l'instant.
SELECT *,
LAG(revenue) OVER(ORDER BY year, month) AS one_month_before,
revenue - LAG(revenue) OVER(ORDER BY year, month) AS mom_difference
FROM revenues
WHERE company = 'Welch LLC'; 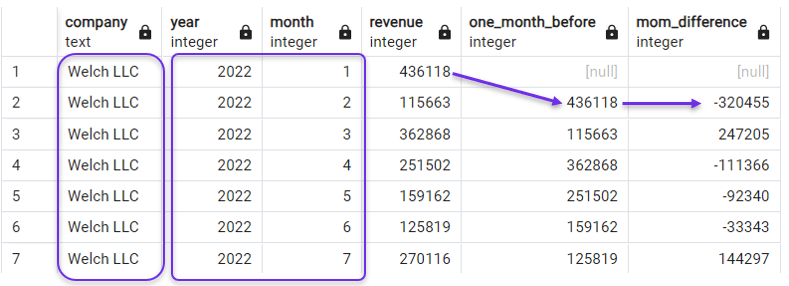
Classement par année et par mois pour LAG(). Image par l'auteur.
Supposons que nous voulions calculer les deux mêmes colonnes pour les trois entreprises que nous avons dans notre ensemble de données. Si nous les calculons de la même manière que nous avons utilisé la fonction LAG() jusqu'à présent, la colonne "lagging" s'étendrait sur les trois entreprises et la colonne "difference" mélangerait les revenus de toutes les entreprises, ce qui n'est pas ce que nous voulons.
Ce que nous voulons, c'est obtenir les recettes du mois précédent et calculer la différence MoM pour chaque entreprise seule, puis recommencer pour la nouvelle entreprise.
Pour ce faire, nous introduisons une nouvelle clause dans la syntaxe de la fonction LAG(). Cette clause est PARTITION BY, et elle peut être ajoutée à notre syntaxe de base comme suit :
LAG(column1) OVER(PARTITION BY column3 ORDER BY column2)La colonne que nous devons partitionner dans notre exemple est company. Nous allons donc modifier notre requête précédente en ajoutant la clause PARTITION BY et en supprimant la déclaration WHERE.
SELECT *,
LAG(revenue) OVER(PARTITION BY company ORDER BY year, month) AS one_month_before,
revenue - LAG(revenue) OVER(PARTITION BY company ORDER BY year, month) AS mom_difference
FROM revenues;Dans le résultat, nous verrions que les colonnes "lagging" et "MoM" couvrent maintenant les revenus mensuels de la première entreprise uniquement, puis recommencent pour la suivante. Nous pouvons le constater dans la capture d'écran ci-dessous, qui montre les derniers mois de Green-Keebler et les premiers mois de Jones Group.
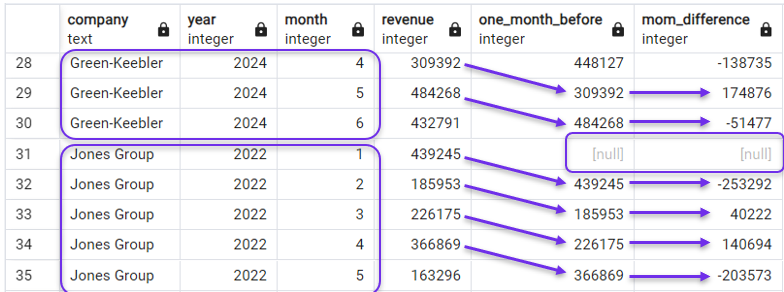
Utilisation de PARTITION BY avec LAG(). Image par l'auteur.
Que se passe-t-il si nous n'avons pas besoin de récupérer la valeur de la ligne précédente, mais de six ou douze lignes plus haut ? En d'autres termes, que se passe-t-il si nous devons calculer la différence d'une année sur l'autre (YoY) au lieu du MoM ?
Dans ce cas, nous ajouterons un nouveau paramètre à la syntaxe de la fonction LAG(). Ce paramètre s'appelle le décalage et indique combien de lignes au-dessus de la ligne actuelle nous voulons que la fonction LAG() obtienne la valeur. Sa position dans la syntaxe est indiquée ci-dessous :
LAG(column1, offset) OVER(PARTITION BY column3 ORDER BY column2)Par défaut, et de la manière dont nous avons utilisé la fonction jusqu'à présent, la valeur du décalage est égale à un. Cependant, en spécifiant explicitement le décalage dans l'expression LAG(), nous pouvons modifier ce paramètre par défaut.
Revenons à notre exemple : pour obtenir la variation du chiffre d'affaires en glissement annuel, nous devons obtenir le chiffre d'affaires du même mois de l'année précédente. Nous pouvons le faire avec la requête suivante, où nous spécifions 12 comme notre décalage :
SELECT *,
LAG(revenue, 12) OVER(PARTITION BY company ORDER BY year, month) AS one_year_before,
revenue - LAG(revenue, 12) OVER(PARTITION BY company ORDER BY year, month) AS yoy_difference
FROM revenues;Et le résultat serait :
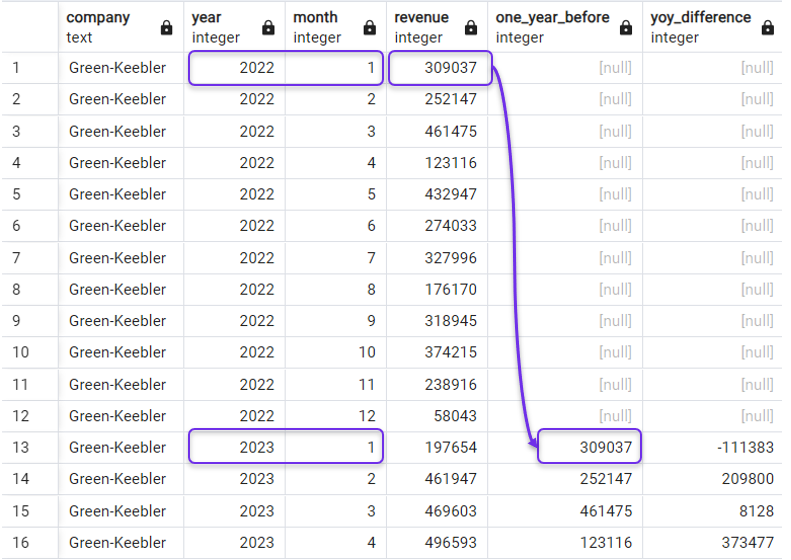
Différence d'une année sur l'autre avec LAG(). Image par l'auteur.
Vous avez peut-être remarqué que la fonction LAG() renvoie NULL dans les lignes où les périodes précédentes ne sont pas disponibles, comme dans les lignes de l'année 2022 dans notre requête précédente.
C'est le comportement par défaut de la fonction LAG(), mais il peut être modifié en spécifiant explicitement un nouveau paramètre appelé "default". Ce paramètre peut prendre n'importe quelle valeur numérique entière ou flottante. Dans la syntaxe de la fonction, le paramètre est positionné comme suit :
LAG(column1, offset, default) OVER(PARTITION BY column3 ORDER BY column2)Le paramètre "par défaut" est souvent utilisé lorsque les valeurs commencent à zéro dans les données de la série temporelle.
Dans notre exemple, nous pouvons supposer que les trois entreprises ont été créées en janvier 2022 (la date la plus ancienne dans notre ensemble de données), et nous pouvons donc considérer que les revenus avant la création sont nuls. Ce faisant, nous calculerons avec plus de précision la variation des recettes, car toute recette gagnée au cours des premiers mois constituerait une variation positive.
Dans notre requête, nous allons spécifier zéro comme paramètre "par défaut" dans nos deux expressions LAG() comme suit :
SELECT *,
LAG(revenue, 12, 0) OVER(PARTITION BY company ORDER BY year, month) AS one_year_before,
revenue - LAG(revenue, 12, 0) OVER(PARTITION BY company ORDER BY year, month) AS yoy_difference
FROM revenues;Il en résulterait des zéros dans la colonne "décalage" et des recettes nettes de zéro dans la colonne "variation des recettes en glissement annuel" :
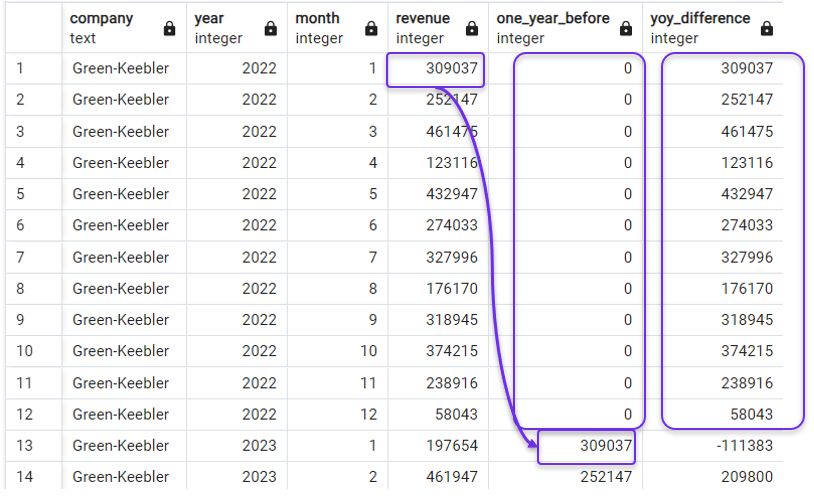
Remplacement des NULL par des zéros dans LAG(). Image par l'auteur.
Notez que pour pouvoir spécifier explicitement une valeur pour le paramètre "default", il devient obligatoire de spécifier explicitement une valeur pour l'offset également, puisque le premier nombre donné après le nom de la colonne dans la fonction LAG() sera pris comme offset de toute façon.
Si vous devez modifier la valeur "par défaut" mais pas le décalage, définissez le paramètre de décalage comme un, et il se comportera comme il le fait normalement.
Il est utile de savoir que l'ordre dont dépend la fonction LAG() ne doit pas nécessairement être le même que celui de la vue résultante. Vous pouvez toujours modifier cet ordre en utilisant normalement la clause ORDER BY dans votre requête.
Dans notre exemple, nous pouvons réorganiser nos résultats pour afficher le même mois de la même année pour les trois entreprises avant de passer au mois suivant de l'année, en ordonnant la requête en fonction de l'année et du mois dans la clause extérieure ORDER BY:
SELECT *,
LAG(revenue, 12, 0) OVER(PARTITION BY company ORDER BY year, month) AS one_year_before,
revenue - LAG(revenue, 12, 0) OVER(PARTITION BY company ORDER BY year, month) AS yoy_difference
FROM revenues
ORDER BY year, month;Et nous aurions ce dont nous avons besoin :
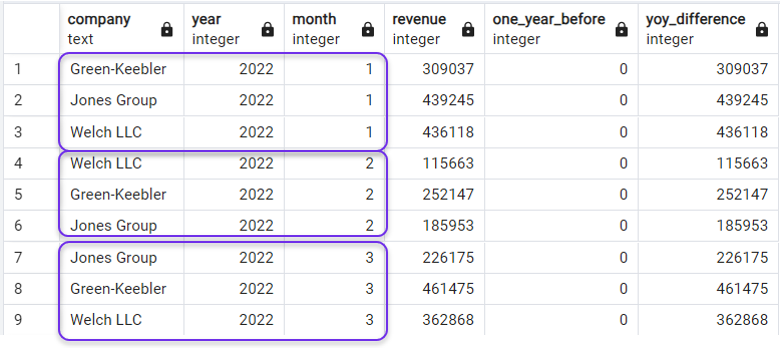
Ordonner la requête après LAG(). Image par l'auteur.
Examinons les problèmes les plus courants, au cas où vous auriez besoin d'aide pour les résoudre.
ORDER BY dans l'instruction LAG() peut conduire à des résultats incorrects. Même si l'ordre original du tableau source convient à la fonction, ne dépendez jamais de cet ordre original car il peut changer au fil du temps.ORDER BY dans l'instruction LAG() et veillez à classer les données dans la bonne colonne.LAG() incorrect en raison de l'oubli de l'utilisation de la clause PARTITION BY ou de son utilisation avec la mauvaise colonne. LAG() s'exécute.NULL dans la sortie de la fonction LAG() alors qu'une autre valeur est plus appropriée, en ne déclarant pas le paramètre "default".LAG() dans plus d'une colonne, vous devez toujours écrire la déclaration LAG() complète dans la deuxième colonne, et non son alias. L'utilisation de l'alias de la première colonne LAG() entraînerait une erreur.LAG() dans leur intégralité à l'intérieur de la déclaration SELECT.LAG(), comme toutes les fonctions de fenêtre, peut s'avérer coûteuse en termes de calcul pour les grands ensembles de données. Par conséquent, ignorer l'indexation des colonnes utilisées dans les clauses PARTITION BY et ORDER BY peut entraîner de mauvaises performances.PARTITION BY et ORDER BY soient indexées, si possible, afin d'améliorer les performances de la requête.LAG() et les autres fonctions de la fenêtre peuvent devenir confuses et difficiles à lire ou à comprendre, en particulier lorsque plusieurs fonctions sont utilisées.LAG() et d'autres fonctions de fenêtre, veillez à ajouter des commentaires et à documenter ce que la requête tente de réaliser. Cela permet aux autres et à vous-même de comprendre l'objectif et la logique qui sous-tendent l'utilisation de LAG(), chaque fois que la question est réexaminée.Dans ce tutoriel, nous avons vu ce qu'est la fonction LAG() et comment elle peut être un outil puissant pour effectuer des analyses de séries temporelles. En outre, nous avons exploré ses arguments et les clauses qui s'y rapportent. La prochaine fois que vous travaillerez avec des données temporelles ou des données séquentielles en SQL, pensez à utiliser la fonction LAG() et à ce qu'elle vous permet de faire. Dans d'autres contextes, la fonction LAG() est utile pour trouver des autocorrélations, lisser les données ou vérifier la présence d'intervalles irréguliers dans le cadre du nettoyage des données.
Si vous êtes intrigué par ce que peut faire une fonction de fenêtre, vous pouvez découvrir toute la famille et améliorer vos compétences d'analyse en SQL grâce à notre cours interactif complet sur les statistiques sommaires et les fonctions de fenêtre de PostgreSQL . Et si vous avez apprécié cet article, vous aimerez probablement suivre le cursus Associate Data Analyst in SQL et obtenir la certification SQL Associate à la fin !
Apprenez SQL avec DataCamp
Cours
Cours
Cours
blog
Kurtis Pykes
15 min
Tutoriel
Mark Pedigo
Tutoriel
Tutoriel
Laiba Siddiqui
Tutoriel
Aditya Sharma
Tutoriel
Sejal Jaiswal

