
Kurs
Einführung in SQL Server
4 Std.
170.4K
Die Funktion LAG() ist eine der Fensterfunktionen von SQL, mit der du eine neue Spalte erstellen kannst, die auf eine vorherige Zeile einer anderen Spalte zugreift. Der Name rührt daher, dass jede Zeile in der neuen Spalte, die du erstellst, einen Wert aus einer vorangehenden Zeile in der anderen Spalte, die du angibst, abrufen würde.
Sehen wir uns die grundlegende Syntax in Aktion an. Angenommen, wir haben eine einfache zweispaltige Tabelle mit täglichen Aktienkursen, die wie folgt aussieht:
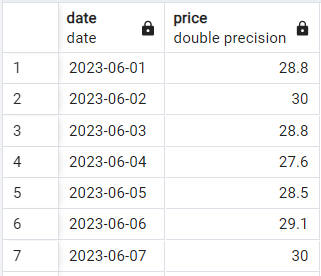
Beispielhafte Aktienkursdaten. Bild vom Autor.
Mit der folgenden Abfrage können wir eine neue Spalte erstellen, die in jeder Zeile den Preis des Vortags abfragt:
SELECT date,
price,
LAG(price) OVER(ORDER BY date) AS one_day_before
FROM stock_price;Und wir würden das folgende Ergebnis erhalten:
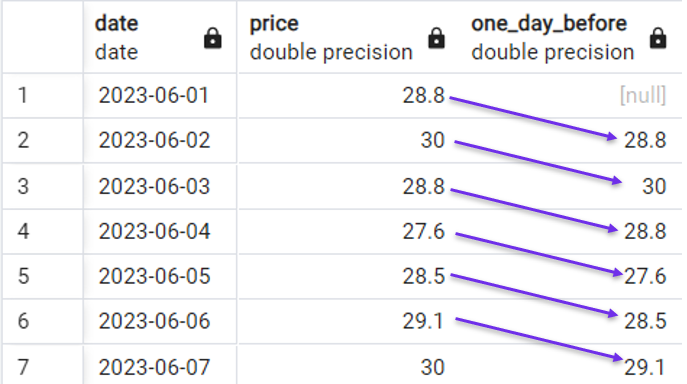
Schnelles Beispiel für die Verwendung der Funktion LAG(). Bild vom Autor.
Beachte, dass wir einen [null] Wert eingeführt haben, weil es für die erste Zeile keinen Wert vom Vortag gibt.
Die Funktion LAG() wird als Teil der SELECT Klausel geschrieben. In ihrer einfachsten Syntax kann die Funktion wie folgt geschrieben werden:
LAG(column1) OVER(ORDER BY column2)Hier ist die gleiche LAG() Funktion, die in einer eigenständigen Abfrage angewendet wird:
SELECT
column1,
column2,
LAG(column1) OVER (ORDER BY column2) AS previous_value
FROM
table_name;Wie du sehen kannst, besteht die grundlegende Syntax aus mehreren Teilen. Lass sie uns gemeinsam aufschlüsseln:
OVER() ist ein obligatorisches Schlüsselwort für jede Fensterfunktion. Die Klausel definiert den Rahmen, in dem die Fensterfunktion ausgeführt wird. Im obigen Beispiel wird die Fensterfunktion über die geordnete column2 laufen.ORDER BY ist nicht zwingend erforderlich, wird aber dringend empfohlen, wenn du die Funktion LAG() verwendest; normalerweise macht die Funktion ohne sie keinen Sinn. LAG() ausgeführt wird. Es kann mehr als eine Spalte als Grundlage für die Sortierung verwendet werden.Du fragst dich vielleicht, was an der Funktion LAG() so toll ist. Nun, die Antwort ist, dass die neue Nachlaufspalte dazu verwendet werden kann, Werte aus zwei verschiedenen Zeilen zu vergleichen.
Aus diesem Grund wird die Funktion LAG() häufig für Zeitreihendaten verwendet. In unserem Demo-Datensatz können wir zum Beispiel mit der folgenden Abfrage ganz einfach die tägliche Veränderung des Aktienkurses berechnen:
SELECT date,
price,
LAG(price) OVER(ORDER BY date) AS one_day_before,
price - LAG(price) OVER(ORDER BY date) AS daily_change
FROM stock_price; 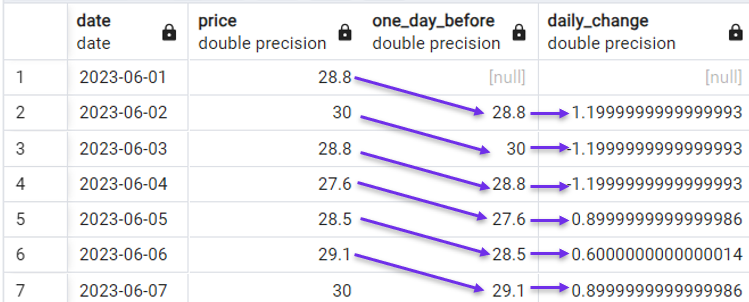
Berechnung der täglichen Veränderung mit LAG(). Bild vom Autor.
Wir können auch zu einer anspruchsvolleren Berechnung übergehen und stattdessen tägliche prozentuale Veränderungen berücksichtigen.
SELECT date,
price,
LAG(price) OVER(ORDER BY date) AS one_day_before,
price - LAG(price) OVER(ORDER BY date) AS daily_change,
((price - LAG(price) OVER(ORDER BY date))*100 /
(LAG(price) OVER(ORDER BY date))) AS daily_perc_change
FROM stock_price; 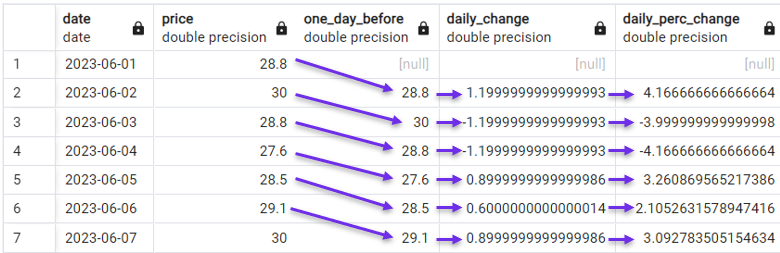
Berechnung der täglichen prozentualen Veränderung mit LAG(). Bild vom Autor.
Nachdem wir nun die grundlegende Verwendung der Funktion LAG() verstanden haben, wollen wir unser Spiel Schritt für Schritt verbessern und sehen, was wir sonst noch mit ihr machen können.
Hier wechseln wir zu einem anderen Demo-Datensatz, der die monatlichen Einnahmen von drei imaginären Unternehmen aufzeichnet: Welsh LLC, Jones Group, und Green-Keebler, von Anfang 2022 bis Mitte 2024. So sind die Daten strukturiert:
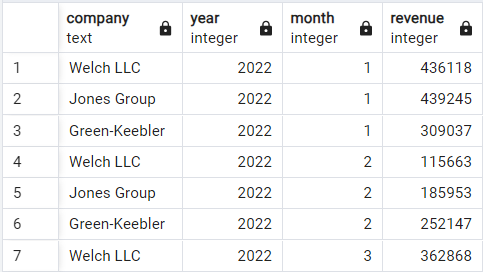
Demo-Einnahmen-Datensatz. Bild vom Autor.
In unserem neuen Datensatz sollte die nachlaufende Spalte auf der Grundlage von zwei Spalten geordnet werden: year und month. Wie wir bereits erwähnt haben, kannst du dies tun, indem du die beiden Spalten in der ORDER BY Klausel angibst.
In der folgenden Abfrage erstellen wir eine Nachlaufspalte und eine Monatsumsatzdifferenzspalte (MoM), geordnet nach year und month. Außerdem filtern wir unsere Abfrage mit einer WHERE Klausel, um uns vorerst auf ein Unternehmen zu konzentrieren.
SELECT *,
LAG(revenue) OVER(ORDER BY year, month) AS one_month_before,
revenue - LAG(revenue) OVER(ORDER BY year, month) AS mom_difference
FROM revenues
WHERE company = 'Welch LLC'; 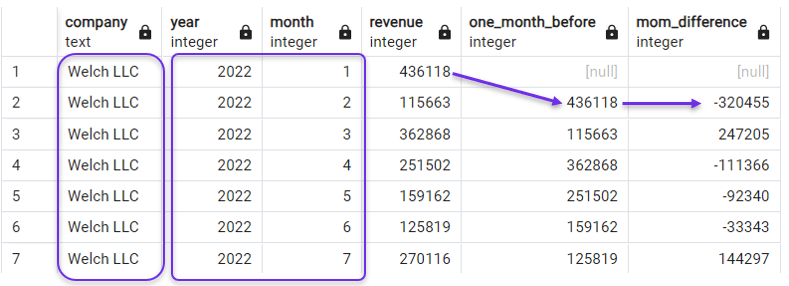
Sortierung nach Jahr und Monat für LAG(). Bild vom Autor.
Angenommen, wir wollen die gleichen zwei Spalten für die drei Unternehmen in unserem Datensatz berechnen. Wenn wir sie auf dieselbe Weise berechnen, wie wir es bisher mit der Funktion LAG() getan haben, würde die Nachzügler-Spalte über die drei Unternehmen laufen und die Differenzspalte würde die Einnahmen aller Unternehmen vermischen, und das ist nicht das, was wir wollen.
Wir wollen den Umsatz des Vormonats ermitteln und die MoM-Differenz für jedes Unternehmen einzeln berechnen, um dann für das neue Unternehmen neu zu beginnen.
Zu diesem Zweck führen wir eine neue Klausel in unsere LAG() Funktionssyntax ein. Diese Klausel ist PARTITION BY und kann wie folgt zu unserer Basissyntax hinzugefügt werden:
LAG(column1) OVER(PARTITION BY column3 ORDER BY column2)Die Spalte, nach der wir in unserem Beispiel partitionieren müssen, ist company. Wir werden also unsere vorherige Abfrage ändern, indem wir die PARTITION BY Klausel hinzufügen und die WHERE Anweisung herausnehmen.
SELECT *,
LAG(revenue) OVER(PARTITION BY company ORDER BY year, month) AS one_month_before,
revenue - LAG(revenue) OVER(PARTITION BY company ORDER BY year, month) AS mom_difference
FROM revenues;Im Ergebnis würden wir sehen, dass die nachlaufende und die MoM-Spalte jetzt nur über die monatlichen Umsätze des ersten Unternehmens laufen und dann für das nächste wieder von vorne beginnen. Das können wir im folgenden Screenshot sehen, der die letzten Monate von Green-Keebler und die ersten Monate von Jones Group zeigt.
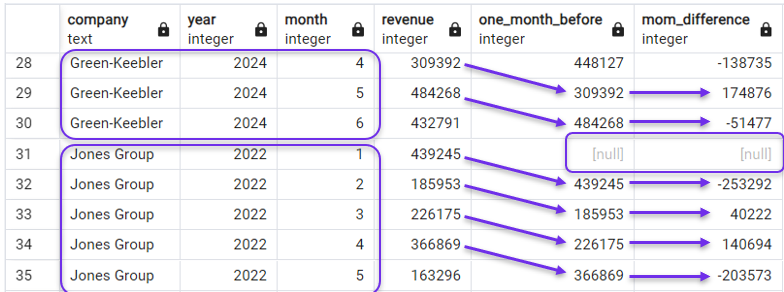
Verwendung von PARTITION BY mit LAG(). Bild vom Autor.
Was ist, wenn wir den Wert nicht aus der vorherigen Zeile abrufen müssen, sondern aus sechs oder zwölf Zeilen darüber? Mit anderen Worten: Was ist, wenn wir die Differenz von Jahr zu Jahr (YoY) statt von Monat zu Monat berechnen müssen?
In diesem Fall würden wir der LAG() Funktionssyntax einen neuen Parameter hinzufügen. Dieser Parameter wird Offset genannt und gibt an, wie viele Zeilen oberhalb der aktuellen Zeile die Funktion LAG() den Wert abrufen soll. Seine Position in der Syntax ist unten dargestellt:
LAG(column1, offset) OVER(PARTITION BY column3 ORDER BY column2)Standardmäßig, und so wie wir die Funktion bisher verwendet haben, ist der Wert des Versatzes gleich eins. Durch die explizite Angabe des Offsets im LAG() Ausdruck können wir diesen Standardparameter jedoch ändern.
Zurück zu unserem Beispiel: Um die Umsatzveränderung gegenüber dem Vorjahr zu ermitteln, müssen wir den Umsatz für den gleichen Monat im Vorjahr ermitteln. Wir können dies mit der folgenden Abfrage tun, bei der wir 12 als Offset angeben:
SELECT *,
LAG(revenue, 12) OVER(PARTITION BY company ORDER BY year, month) AS one_year_before,
revenue - LAG(revenue, 12) OVER(PARTITION BY company ORDER BY year, month) AS yoy_difference
FROM revenues;Und das Ergebnis wäre:
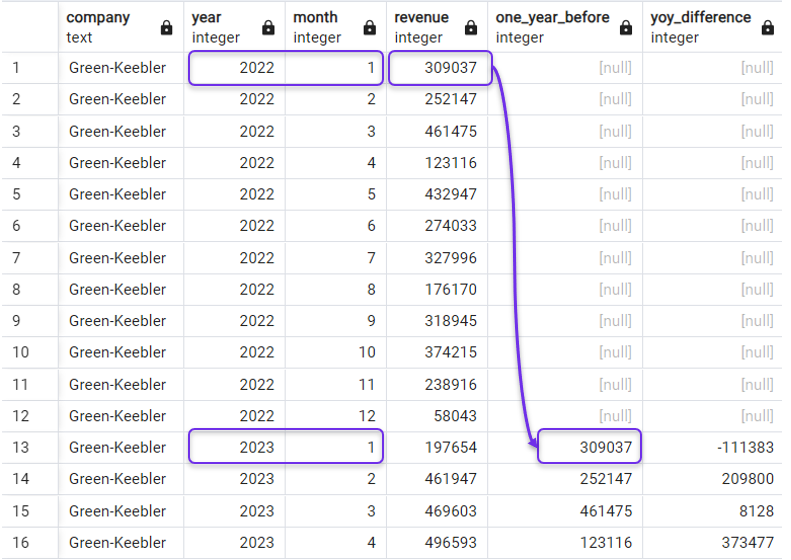
Differenz zum Vorjahr mit LAG(). Bild vom Autor.
Du hast vielleicht bemerkt, dass die Funktion LAG() NULL in den Zeilen zurückgibt, in denen keine vorherigen Perioden verfügbar sind, wie in den Zeilen des Jahres 2022 in unserer vorherigen Abfrage.
Das ist das Standardverhalten der Funktion LAG(), aber es kann durch die explizite Angabe eines neuen Parameters namens "default" geändert werden. Dieser Parameter kann einen beliebigen ganzzahligen oder fließenden numerischen Wert annehmen. In der Syntax der Funktion wird der Parameter wie folgt positioniert:
LAG(column1, offset, default) OVER(PARTITION BY column3 ORDER BY column2)Der übliche Anwendungsfall des Parameters "Standard" ist, wenn die Werte in den Zeitreihendaten tatsächlich bei Null beginnen.
In unserem Beispiel können wir davon ausgehen, dass die drei Unternehmen im Januar 2022 gegründet wurden (das früheste Datum in unserem Datensatz), und daher können wir die Einnahmen vor der Gründung als Null betrachten. Auf diese Weise können wir die Veränderung der Einnahmen genauer berechnen, da alle Mehreinnahmen in den ersten Monaten eine positive Veränderung darstellen würden.
In unserer Abfrage geben wir in beiden LAG() Ausdrücken Null als "Standard"-Parameter an, wie folgt:
SELECT *,
LAG(revenue, 12, 0) OVER(PARTITION BY company ORDER BY year, month) AS one_year_before,
revenue - LAG(revenue, 12, 0) OVER(PARTITION BY company ORDER BY year, month) AS yoy_difference
FROM revenues;Und das Ergebnis würde Nullen in der Nachlaufspalte und die Nettoeinnahmen von Null in der Jahresumsatzveränderungsspalte ergeben:
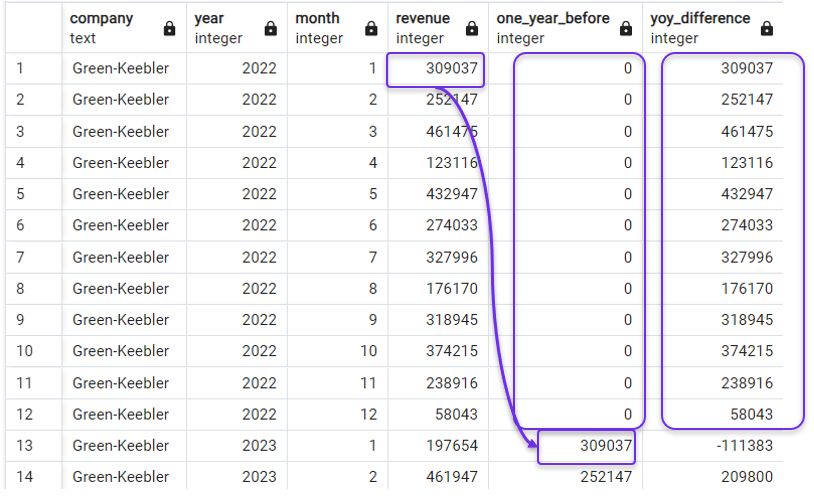
Ersetzen von NULLen durch Nullen in LAG(). Bild vom Autor.
Um einen Wert für den "Standard"-Parameter explizit angeben zu können, muss auch ein Wert für den Offset angegeben werden, da die erste Zahl, die nach dem Spaltennamen in der Funktion LAG() angegeben wird, ohnehin als Offset verwendet wird.
Wenn du den "Standard", aber nicht den Versatz ändern willst, setze den Versatz-Parameter auf eins, dann verhält er sich wie gewohnt.
Es ist nützlich zu wissen, dass die Reihenfolge, von der die Funktion LAG() abhängt, nicht dieselbe sein muss wie die Reihenfolge der resultierenden Ansicht. Du kannst diese Reihenfolge jederzeit ändern, indem du normalerweise die ORDER BY Klausel in deiner Abfrage verwendest.
In unserem Beispiel können wir unser Ergebnis neu ordnen, um denselben Monat desselben Jahres für die drei Unternehmen anzuzeigen, bevor wir zum nächsten Monat des Jahres übergehen, indem wir die Abfrage in der äußeren ORDER BY Klausel nach Jahr und Monat ordnen:
SELECT *,
LAG(revenue, 12, 0) OVER(PARTITION BY company ORDER BY year, month) AS one_year_before,
revenue - LAG(revenue, 12, 0) OVER(PARTITION BY company ORDER BY year, month) AS yoy_difference
FROM revenues
ORDER BY year, month;Und wir hätten, was wir brauchen:
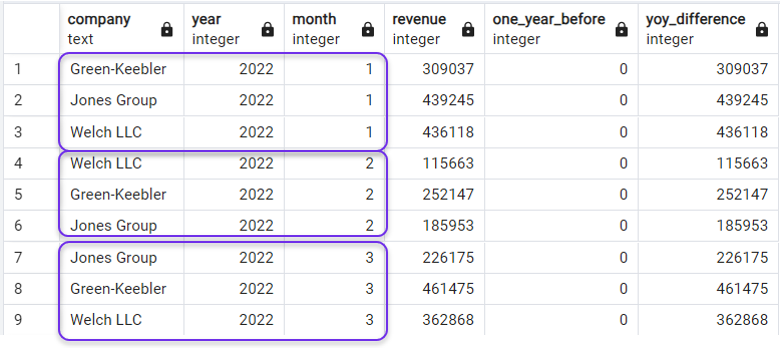
Ordnen der Abfrage nach LAG(). Bild vom Autor.
Werfen wir einen Blick auf die häufigsten Probleme, falls du Hilfe bei der Fehlersuche brauchst.
ORDER BY Klausel in der LAG() Anweisung nicht angibst, kann das zu falschen Ergebnissen führen. Auch wenn die ursprüngliche Reihenfolge der Tabelle für die Funktion geeignet ist, solltest du dich nie auf diese ursprüngliche Reihenfolge verlassen, da sie sich im Laufe der Zeit ändern kann.ORDER BY Klausel in der LAG() Anweisung und achte darauf, dass du nach der richtigen Spalte ordnest.LAG() Rahmen, weil die Verwendung der PARTITION BY Klausel übersehen oder mit der falschen Spalte verwendet wurde. LAG() Funktion läuft.NULL Werte in der LAG() Funktionsausgabe, wenn ein anderer Wert besser geeignet ist, indem der "Standard"-Parameter nicht deklariert wird.LAG() Anweisung in mehr als einer Spalte verwendest, musst du in der zweiten Spalte immer noch die vollständige LAG() Anweisung schreiben, nicht ihren Alias. Die Verwendung des Alias der ersten Spalte LAG() würde einen Fehler verursachen.LAG() Anweisungen immer vollständig in die SELECT Anweisung.LAG() kann, wie alle Fensterfunktionen, bei großen Datensätzen sehr rechenintensiv sein. Daher kann das Ignorieren der Indizierung der in den Klauseln PARTITION BY und ORDER BY verwendeten Spalten zu einer schlechten Leistung führen.PARTITION BY und ORDER BY verwendeten Spalten nach Möglichkeit indiziert sind, um die Abfrageleistung zu verbessern.LAG() und andere Fensterfunktionen unübersichtlich und nicht leicht zu lesen oder zu verstehen sein, vor allem, wenn mehr als eine Funktion verwendet wird.LAG() und andere Fensterfunktionen verwendest, solltest du unbedingt Kommentare hinzufügen und dokumentieren, was die Abfrage zu erreichen versucht. Das hilft anderen und dir selbst, den Zweck und die Logik hinter der Verwendung von LAG() zu verstehen, wenn die Anfrage erneut gestellt wird.In diesem Lernprogramm haben wir gesehen, was die Funktion LAG() ist und wie sie ein leistungsstarkes Werkzeug für die Analyse von Zeitreihen sein kann. Außerdem haben wir seine Argumente und die damit verbundenen Klauseln untersucht. Wenn du das nächste Mal mit zeitbezogenen oder anderen sequenzierten Daten in SQL arbeitest, solltest du dir überlegen, ob du die Funktion LAG() verwenden willst und welche Möglichkeiten sie dir bietet. In anderen Zusammenhängen ist die Funktion LAG() hilfreich, um Autokorrelationen zu finden, Daten zu glätten oder im Rahmen der Datenbereinigung auf unregelmäßige Intervalle zu prüfen.
Wenn du dich dafür interessierst, was eine Fensterfunktion alles kann, kannst du die ganze Familie kennenlernen und deine Analysefähigkeiten in SQL mit unserem umfassenden interaktiven Kurs PostgreSQL Summary Stats and Window Functions verbessern. Und wenn dir dieser Artikel gefallen hat, wird es dir wahrscheinlich auch Spaß machen, den Lernpfad zum Associate Data Analyst in SQL zu durchlaufen und am Ende die SQL Associate Zertifizierung zu erhalten!
SQL lernen mit DataCamp
Kurs
Kurs
Kurs
Tutorial
Mark Pedigo
Tutorial
Laiba Siddiqui
Tutorial
Aditya Sharma
Tutorial
Allan Ouko
Tutorial
Abid Ali Awan
Tutorial
Aditya Sharma

