
Course
Introduction to SQL Server
4 hr
170.3K
The LAG() function is one of SQL’s window functions that allows you to create a new column that accesses a previous row from another column. It gets its name from the fact that each row in the new column you create would be lagging to fetch a value from a preceding row in the other column you specify.
Let’s see the basic syntax in action. Suppose we have a simple two-column table with daily stock prices that looks like this:
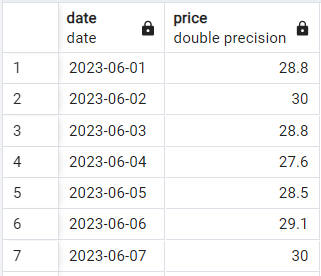
Sample stock price data. Image by Author.
We can use the following query to create a new column that gets the price of the previous day in each row with the following query:
SELECT date,
price,
LAG(price) OVER(ORDER BY date) AS one_day_before
FROM stock_price;And we would have the following result:
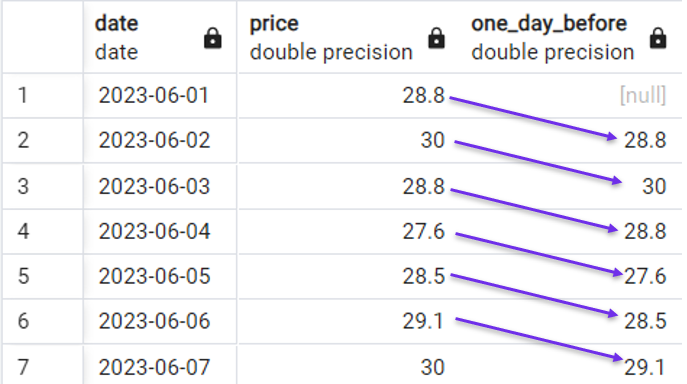
Quick example for using LAG() function. Image by Author.
Notice that we have introduced one [null] value because there is no previous day's value for the first row.
The LAG() function is written as part of the SELECT clause. In its most basic syntax, the function can be written as follows:
LAG(column1) OVER(ORDER BY column2)Here is the same LAG() function applied in a standalone query:
SELECT
column1,
column2,
LAG(column1) OVER (ORDER BY column2) AS previous_value
FROM
table_name;As you can see, the basic syntax consists of several parts. Let’s break them down together:
OVER() is a mandatory keyword for every window function. The clause defines the frame over which the window function will run. In the above example, the window function will run over the ordered column2.ORDER BY is not mandatory but it is highly recommended when used with the LAG() function; usually, the function does not make sense without it. LAG() function will follow. More than one column can be used as a basis for sorting.You might be wondering what is so great about the LAG() function. Well, the answer is that the new lagging column can be used to compare values from two different rows.
This is why the LAG() function is commonly used with time series data. For example, in our demo dataset, we can easily calculate the daily change in stock price with the following query:
SELECT date,
price,
LAG(price) OVER(ORDER BY date) AS one_day_before,
price - LAG(price) OVER(ORDER BY date) AS daily_change
FROM stock_price; 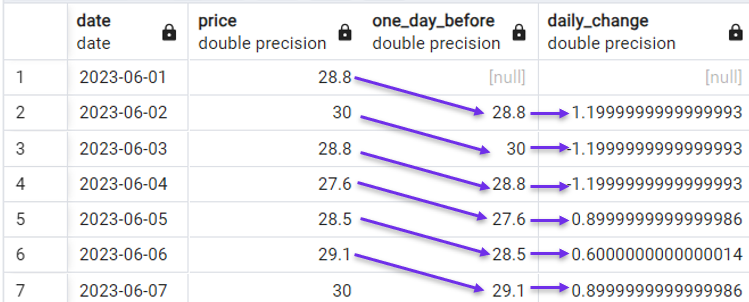
Calculating daily change with LAG(). Image by Author.
We can also graduate to a more sophisticated calculation and consider daily percent changes instead.
SELECT date,
price,
LAG(price) OVER(ORDER BY date) AS one_day_before,
price - LAG(price) OVER(ORDER BY date) AS daily_change,
((price - LAG(price) OVER(ORDER BY date))*100 /
(LAG(price) OVER(ORDER BY date))) AS daily_perc_change
FROM stock_price; 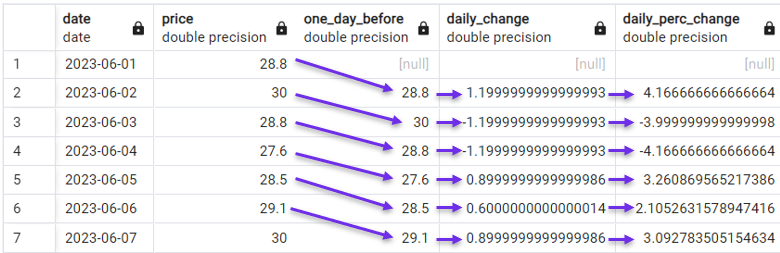
Calculating daily percent change with LAG(). Image by Author.
Now, as we understand the basic use of the LAG() function, let’s level up our game step by step and see what else we can do with it.
Here we will be switching to another demo dataset that records the monthly revenue for three imaginary companies: Welsh LLC, Jones Group, and Green-Keebler, from the start of 2022 till mid-2024. This is how the data is structured:
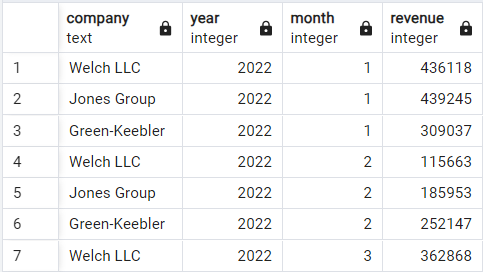
Demo revenues dataset. Image by Author.
In our new dataset, the lagging column should be ordered based on two columns: year and month. As we mentioned earlier, this can be done by giving the two columns to the ORDER BY clause.
In the following query we create a lagging column and a month-on-month (MoM) revenue difference column, ordered according to both year and month. We also filter our query with a WHERE clause to focus on one company for now.
SELECT *,
LAG(revenue) OVER(ORDER BY year, month) AS one_month_before,
revenue - LAG(revenue) OVER(ORDER BY year, month) AS mom_difference
FROM revenues
WHERE company = 'Welch LLC'; 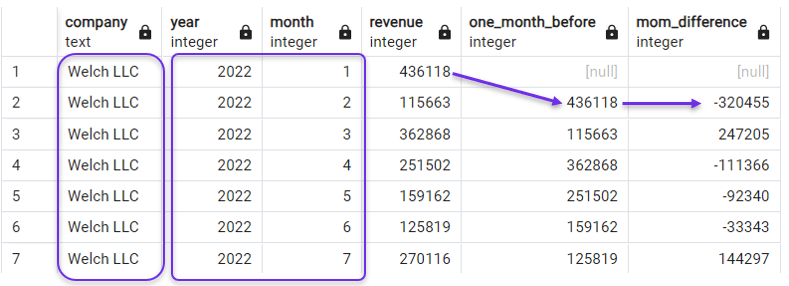
Ordering by year and month for LAG(). Image by Author.
Suppose we want to calculate the same two columns for the three companies that we have in our dataset. If we calculate them in the same way we have been using the LAG() function so far, the lagging column would be running over the three companies, and the difference column would be mixing between the revenues of all of them, and that is not what we want.
What we want is to get the previous month’s revenue, and calculate the MoM difference for each company alone, then start over for the new company.
To do this, we introduce a new clause in our LAG() function syntax. That clause is PARTITION BY, and it can be added to our basic syntax as follows:
LAG(column1) OVER(PARTITION BY column3 ORDER BY column2)The column that we need to partition by in our example is company. So, we will be modifying our previous query by adding the PARTITION BY clause and taking out the WHERE statement.
SELECT *,
LAG(revenue) OVER(PARTITION BY company ORDER BY year, month) AS one_month_before,
revenue - LAG(revenue) OVER(PARTITION BY company ORDER BY year, month) AS mom_difference
FROM revenues;In the result, we would see that the lagging and MoM columns now run over the monthly revenues of the first company alone, and then start over for the next one. We are able to see this in the screenshot below, which shows the last months of Green-Keebler and the first months of Jones Group.
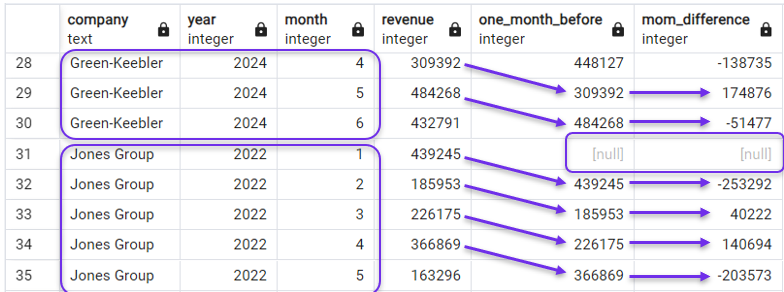
Using PARTITION BY with LAG(). Image by Author.
What if we do not need to fetch the value from the previous row, but from six rows or twelve rows above? In other words, what if we need to calculate the year-on-year (YoY) difference instead of the MoM?
In this case, we would add a new parameter to the LAG() function syntax. This parameter is called the offset, and it specifies how many rows above the current row we want the LAG() function to get the value from. Its position in the syntax is shown below:
LAG(column1, offset) OVER(PARTITION BY column3 ORDER BY column2)By default, and by the way we have used the function so far, the value of the offset is equal to one. However, by explicitly specifying the offset in the LAG() expression, we can change this default parameter.
Back to our example, to get the YoY revenue change, we need to get the revenue for the same month in the previous year. We can do so with the following query, where we specify 12 as our offset:
SELECT *,
LAG(revenue, 12) OVER(PARTITION BY company ORDER BY year, month) AS one_year_before,
revenue - LAG(revenue, 12) OVER(PARTITION BY company ORDER BY year, month) AS yoy_difference
FROM revenues;And the result would be:
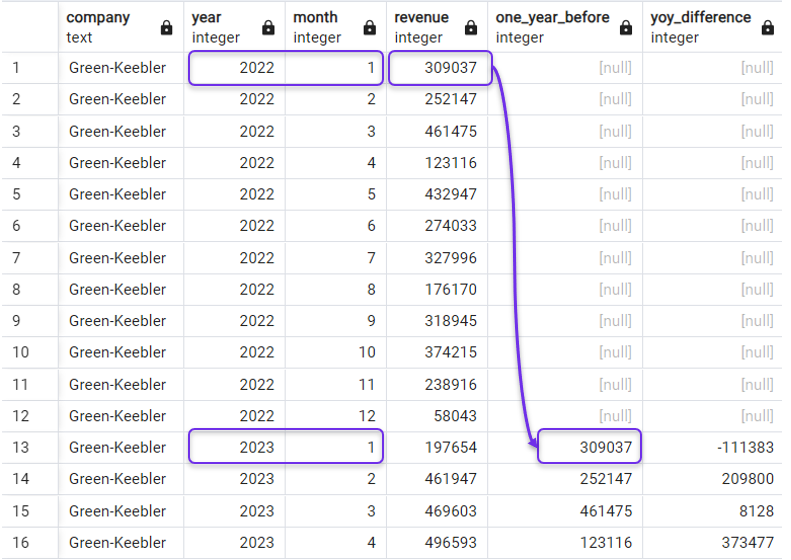
Year-on-year difference with LAG(). Image by Author.
You may have noticed that the LAG() function returns NULL in the rows where previous periods are not available, like in rows of the year 2022 in our previous query.
This is the default behavior of the LAG() function, but it can be altered by explicitly specifying a new parameter called “default”. This parameter can take any integer or float numerical value. In the function’s syntax, the parameter is positioned as follows:
LAG(column1, offset, default) OVER(PARTITION BY column3 ORDER BY column2)The common use case of the “default” parameter is when the values actually start from zero in the time series data.
In our example, we can assume that the three companies were founded in January 2022 (the earliest date in our dataset), and therefore we can consider the revenue before the foundation as zero. By doing so, we will more accurately calculate the change in revenues, as any revenue gained in the first months would be a positive change.
In our query, we will be specifying zero as the “default” parameter in both of our LAG() expressions as follows:
SELECT *,
LAG(revenue, 12, 0) OVER(PARTITION BY company ORDER BY year, month) AS one_year_before,
revenue - LAG(revenue, 12, 0) OVER(PARTITION BY company ORDER BY year, month) AS yoy_difference
FROM revenues;And the result would yield zeros in the lagging column, and the net revenue from zero in the YoY revenue change column:
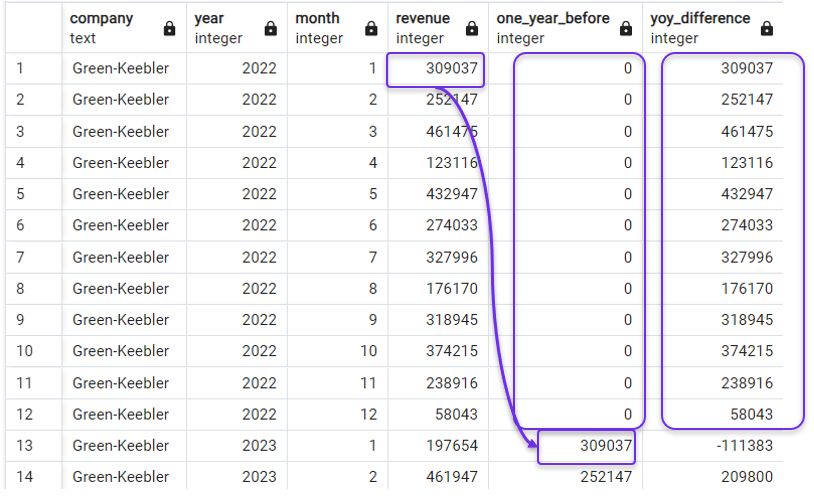
Replacing NULLs with zeros in LAG(). Image by Author.
Note that to be able to explicitly specify a value for the “default” parameter, it becomes mandatory to explicitly specify a value for the offset as well, as the first number given after the column name inside the LAG() function will be taken as the offset anyway.
If you need to change the “default” but not the offset, set the offset parameter as one, and it will behave as it normally does.
It is useful to know that the order that the LAG() function depends on does not need to be the same order of the resulting view. You can always change that order by normally using the ORDER BY clause in your query.
In our example, we can reorder our result to show the same month of the same year for the three companies before moving to the next month of the year, by ordering the query according to year and month in the outer ORDER BY clause:
SELECT *,
LAG(revenue, 12, 0) OVER(PARTITION BY company ORDER BY year, month) AS one_year_before,
revenue - LAG(revenue, 12, 0) OVER(PARTITION BY company ORDER BY year, month) AS yoy_difference
FROM revenues
ORDER BY year, month;And we would have what we need:
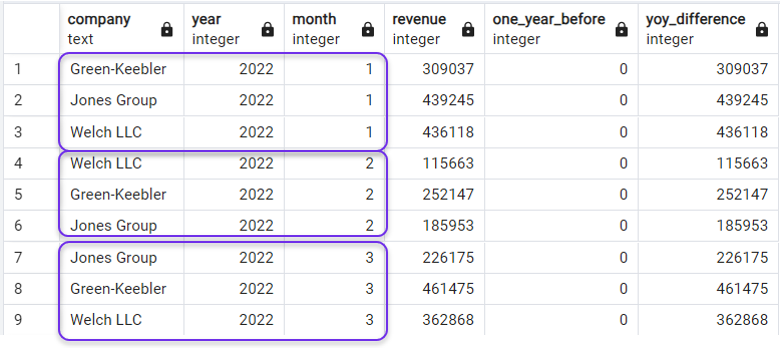
Ordering the query after LAG(). Image by Author.
Let's take a look at common issues, in case you need help troubleshooting.
ORDER BY clause in the LAG() statement can lead to incorrect results. Even if the original order of the source table is suitable for the function, never depend on that original order as it may change over time.ORDER BY clause in the LAG() statement, and make sure you order by the correct column.LAG() frame due to overlooking the use of PARTITION BY clause or using it with the wrong column. LAG() function runs over.NULL values in the LAG() function output when another value is more proper, by not declaring the “default” parameter.LAG() statement in more than one column, you would still have to write the full LAG() statement in the second column, not its alias. Using the alias of the first LAG() column would raise an error.LAG() statements in full within the SELECT statement.LAG() function, like all window functions, can be computationally expensive with large datasets. Therefore, ignoring the indexing of the columns used in the PARTITION BY and ORDER BY clauses can lead to poor performance.PARTITION BY and ORDER BY clauses are indexed, if possible, to improve query performance.LAG() and other window functions can get messy and not easy to read or understand, especially when more than one function is used.LAG() and other window functions, make sure to add comments and document what the query tries to achieve. This helps others and yourself understand the purpose and logic behind LAG() usage, whenever the query is revisited.In this tutorial, we have seen what the LAG() function is and how it can be a powerful tool to perform time series analytics. Additionally, we explored its arguments, and the clauses related to it. The next time you work with time-related, or any sequenced, data in SQL, consider the use of the LAG() function and what it enables you to do. In other contexts, the LAG() function is helpful in finding autocorrelations, smoothing data, or checking for irregular intervals as part of data cleaning.
If you are intrigued by what one window function can do, you can learn about the whole family and level up your analysis skills in SQL with our comprehensive PostgreSQL Summary Stats and Window Functions interactive course. And if you enjoyed this article, you would probably enjoy going through the Associate Data Analyst in SQL Career Track and obtaining the SQL Associate Certification at the end!
Learn SQL with DataCamp
Course
Course
Course
Tutorial
Sayak Paul
Tutorial
Allan Ouko
Tutorial
Allan Ouko
Tutorial
Travis Tang
Tutorial
Allan Ouko
Tutorial
Allan Ouko
