Courses
AIを理解する
2時間
401.8K
OpenAIは、デフォルトのGPTモデルを「本当に会話したくなる相手」にする試みをまだ諦めていません。
そのための今回のアップデートでは、次の点に重点が置かれています。
それだけなら語ることは多くありませんが、今回のリリースには他にも興味深い点があります。GPT-5.5 Instantは著名なベンチマークテストのスコアが向上しており、新しいメモリ機能も導入されました。
他の最先端AIモデルの概要については、以下のLLMに関するガイドもご覧ください。
GPT-5.5 Instantは、ChatGPTで使用される GPT-5.5 モデルの新しいデフォルトで、応答が速いバージョンです。日常的なタスク(質問への回答、文章作成、コーディングなど)に向けて設計され、スピードと応答性を優先します。
つまりGPT-5.5 Instantとは、GPT-5.5モデルを高速・汎用構成で動かす特定の組み合わせを指します。
実際には、このバージョンはGPT-5.3 Instantのような以前のリリースより、より正確な回答、無駄の少ない応答、複雑な質問のより良い扱いを実現しています。
GPT-5.4 Instantに触れていない理由が気になるかもしれませんが、存在しないためです。Instant系は5.4をスキップしました。
ChatGPTのインターフェースでは、モデル選択にフルネームではなく「Instant」とだけ表示されることがよくあります。つまり:
ちょっとした行き違いがあるわけです。
全体として、このアップデートはデフォルトのChatGPTモデルをより有用にすることを目的としています。具体的に見ていきましょう。
内部評価によれば、GPT-5.5 Instantは、いわゆる「重大なプロンプト」(誤答が実害につながり得る医療・法律・金融系の助言など)において、GPT-5.3 Instantより幻覚的な主張が約50%減少したとのことです。また関連して、不正確な主張も約3分の1減りました。
GPT-5.5 Instantは、同じ情報をより少ない言葉で伝えるよう設計されています。過度なフォーマットも控えめになるはずです。
OpenAIは、よく喋る同僚に関するカジュアルなプロンプトを例に挙げ、評価のために語数を数えたところ(語数のカウントをモデル自身に頼ったとは思いませんが)、30.2%少ない語数で回答したとしています。
会話面の改善が先に語られていますが、ベンチマークテストでも向上が見られ、GPT-5.3 Instantからの伸びは堅調です。
これは大きな変更になり得ます。GPT-5.5 Instantは、利用者が共有することを選んだ情報から文脈を引き出す能力が実質的に向上しました。対象は以下です。
Gmail連携自体は新機能ではありません(知らない人も多いですが)。これまでは、Gmailを連携していても受信箱関連の質問を明示したときだけGmail情報が参照される傾向がありました。今後は、(Gmailが連携されていれば)GPT-5.5 Instantが自動で、メールの文脈が回答の精度向上に役立つかどうかを判断します。
Gmailを連携するには、サイドバーを開いて「Apps」をクリックしてください。上部に表示されるはずです。
パーソナライズが機能だとすれば、メモリソースはその中身を見せる窓です。これはInstantに限らず、すべてのChatGPTモデルで展開されます。
パーソナライズされた回答では、どの文脈が回答を形作ったか(保存されたメモリ、過去チャット、上で述べたGmailのような連携アプリ)を確認でき、古い情報は削除・修正できます。
チャットを共有してもメモリソースは非公開のままで、すべての要因が表示されるとは限らないとOpenAIは注記していますが、それでも興味深い変更です。
冒頭で触れたベンチマークを見てみましょう。リリース情報によると、GPT-5.5 Instantは多様なテストでGPT-5.3 Instantを上回っています。
最近のGPT-5.5やGPT-5.4などのリリースを注意深く追っていれば、MMMU ProやGPQAのようなテストでGPTモデルがより高い数値を出していたのをすでに見ているはずです。印象がどうかは、Instantに何を求めるか(速度かスコアか)に完全に依存します。Instantは元々スコアで勝負する tier ではありません。
新モデルを、推論、ウェブ検索、医療分野の質問における幻覚回避でテストしました。医療分野はOpenAIが大きな改善点として挙げた領域です。
GPT-5.3 Instantの記事で用いたこのプロンプトは、有用な継続ベンチマークになっています。質問は一見簡単ですが、「1ブロック先の洗車場に歩いて行くべきか、車で行くべきか?」というものです。それでも、以前のモデルが苦手とした心的転換を要求します。GPT-5.2 Thinkingは歩くことを提案、GPT-5.3 Instantは正解しました。
プロンプト:
I want to wash my car at the car wash. The car wash is one block away. Should I walk or drive?GPT-5.5を前世代と比較します。こちらはGPT-5.3 Instantの回答です。
そしてGPT-5.5 Instantの回答がこちら。
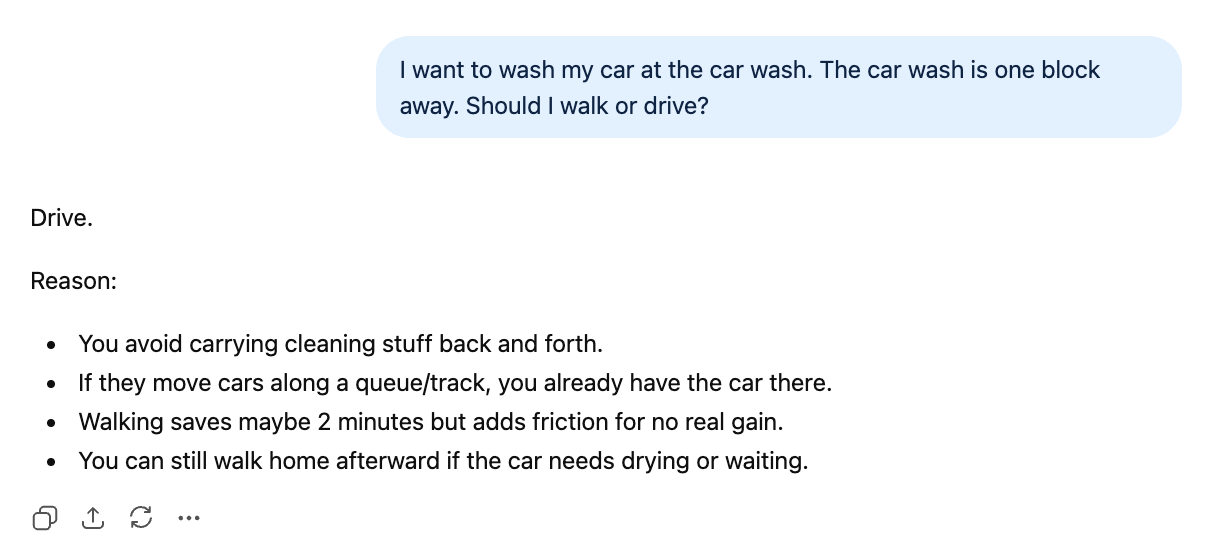
どちらも非常に簡潔(50語対49語)ですが、GPT-5.5は「〜の場合のみ歩くべき」といった逃げを打たないぶん、より自信に満ちています。個人的には、「(歩いて)得るものはない」というGPT-5.3 Instantの推論の方が「2分ほどの節約」というGPT-5.5 Instantより実情に近い気もします。とはいえ、どちらも結論は正しいです。
5.5のリリースは、とりわけ「重大なプロンプト」で幻覚が約50%減ったと主張しているため、もっともらしいが正解が明確な医療系の質問を使いました。質問は次のとおりです。
Can I take ibuprofen and aspirin together?これはLLMにとって典型的な落とし穴です。実際の答えは微妙なニュアンスがあります。どちらもNSAIDsであり、併用は消化管出血リスクを高め、特にタイミングを誤るとイブプロフェンがアスピリンの心血管保護効果を妨げる可能性があります。
モデルはしばしば「問題ない」と言い切るか、「絶対にやめるべき、医師に相談を」と過度に慎重な包括的回答を返します。5.5が幻覚や過度な逃げをせず、正確で具体的な回答を返すかを確認しました。
回答の正確性は高く、GI出血リスク、作用の相互影響、FDAのタイミングガイダンスに言及しています。幻覚は見当たらず、トーンも適切です。ただし、ややフォーマットが重い印象で、本来より短く会話的にまとめられる内容に箇条書きや構造化が多用されています。

総じて、この幻覚テストは合格です。回答は正確でニュアンスがあり、事実を捏造していません。GPT-5.3 Instantの回答とも比較してみましょう。
いずれも幻覚を避け、正確で有用な回答ですが、フォーマットは重めです。違いとして、5.5は(リスク要因の完全な列挙など)やや網羅的で、5.3はより簡潔です。
GPT-5.5 Instantがウェブ検索結果と自らの推論をどの程度うまく組み合わせられるかを見るため、直近の重層的なスポーツイベント――アーセナルのアトレティコ・マドリード相手のCL準決勝第2戦の勝利――について質問しました。
ここで良い回答には、複数の情報源から適切な事実を引き出し、単なる検索スニペットの羅列ではなく、首尾一貫した物語として編み上げることが求められます。
プロンプト:
What happened in the Champions League semifinal second leg yesterday, and what does the result mean for Arsenal historically?
GPT-5.5 Instantの回答は非常に優れています。合計スコアや決勝点の選手など、昨日起きたことを正しく把握し、こちらが意図した文脈で提示できています。
比較のため、GPT-5.3 Instantの回答も示します。
ここでも同じ傾向が見られます。どちらも要点を外さず、5.3は手短に結論へ、5.5は核となる答えに追加の文脈を添えています。
GPT-5.5はすべてのユーザー向けに新しいデフォルトのChatGPTモデルとして段階的に展開され、APIではchat-latestとして利用可能になります。GPT-5.3 Instantは3か月後に終了し、それまでは有料ユーザーがアクセスできます。
一部の機能は段階的に提供されます。
実際に体感するのは、おそらく「誤答が問題になる場面での明らかな誤りが減る」ことと、「必ずしも短くはないが、より行き届いた回答」です。
テストでは、GPT-5.5 Instantは(医療の質問でのリスク要因の網羅など)実際に役立つ詳細を加えていましたが、OpenAIの「より引き締まった回答」という主張にもかかわらず、GPT-5.3 Instantの方が端的な場面もありました。
パーソナライズは好みの問題です。ChatGPTがようやく有用な形で覚えてくれると感じるか、合意しきれない領域に踏み込み過ぎと感じるか。少なくともメモリソース機能は、回答に使われた情報源の概観を示すことを目指しています。
AI搭載アプリの開発に関心がある方には、AI Engineering with LangChainスキルトラックの受講を強くおすすめします。AIネイティブな講座構成で、現在のレベルからプロまでを見据えた、パーソナライズされた学習体験が得られます。
DataCampで学ぶ
Courses
Courses
Courses