Courses
理解 Artificial Intelligence
2小时
401.5K
OpenAI 并未放弃将其默认 GPT 模型打造成用户真正愿意进行对话的产品。
为此,OpenAI 的这次更新聚焦于通过以下方式改进对话体验:
如果只有这些,其实也没太多可说的。但这次发布还有一些有意思的点。GPT-5.5 Instant 在多项知名基准测试上也有提升,同时此次更新还引入了新的记忆功能。
若想了解其他前沿 AI 模型的概览,建议查看我们关于以下 LLM 的指南:
GPT-5.5 Instant 是 ChatGPT 所使用的 he GPT-5.5 模型的全新默认快速响应版本。它专为日常任务而设计——答疑、写作、编程等——同时优先保证速度与响应性。
因此,当您看到 GPT-5.5 Instant 时,指的是一个特定组合:在快速、通用配置下运行的 GPT-5.5 模型。
在实际使用中,该版本较早期版本(如 GPT-5.3 Instant)在生成更准确的答案、更紧凑的回应以及更好地处理复杂问题方面都有所提升。
如果您好奇为何没有提到 GPT-5.4 Instant,那是因为它并不存在:Instant 变体跳过了 5.4 版本。
您可能注意到,在 ChatGPT 界面中,模型选择器通常只显示“Instant”,而不是全名。这意味着:
这是一点小小的不一致:
总体而言,此次更新旨在让默认的 ChatGPT 模型更有帮助。我们来看看这意味着什么。
据内部评测,GPT-5.5 Instant 在所谓的高风险提示上产生的虚假断言约比 GPT-5.3 Instant 少 50%,所谓高风险提示是指错误答案可能带来实质负面影响的场景,如医疗、法律或金融类建议。此外,相关的:不准确断言减少了约三分之一。
GPT-5.5 Instant 旨在用更少的字数传达同等信息。同时也会减少过度格式化的倾向。
OpenAI 给出了一个示例,是关于一位健谈同事的随意问题。随后在评估中,他们统计了字数(我们怀疑他们并未依赖模型自身来计数),发现用词减少了 30.2%。
尽管 OpenAI 首先强调了对话改进,但该模型在基准测试中的表现也更佳,与 GPT-5.3 Instant 相比提升可观。
这一点可能是重大变化。GPT-5.5 Instant 现在能更有效地从您选择分享的内容中提取上下文。这包括:
Gmail 连接并非新功能,只是很多人并不了解。此前,若已连接 Gmail,只有在您明确提出与收件箱相关的问题时才会调用 Gmail 信息。现在,GPT-5.5 Instant 会自行判断(同样前提是已连接 Gmail)何时使用邮件上下文能让答案更到位。
要连接 Gmail,只需打开侧边栏并点击“Apps”。它应当就在最上方。
如果说个性化是功能本身,那么记忆来源就是观察窗口。该功能适用于所有 ChatGPT 模型,而不仅限于 Instant。
当回复带有个性化时,您现在可以看到是什么上下文影响了它——已保存的记忆、过往聊天、像 Gmail 这样的已连接应用(上文已提到)——并可删除或更正任何过时内容。
当您分享聊天时,记忆来源保持私密。OpenAI 也指出,该视图可能不会呈现影响回复的每个因素。但这仍是不小的变化。
来看我们已开始提及的基准测试。根据发布内容,OpenAI 展示了 GPT-5.5 Instant 在多项测试上优于 GPT-5.3 Instant:
如果您密切关注了近期其他 OpenAI 发布(如 GPT-5.5 或 GPT-5.4),应该已经看到 GPT 模型在 MMMU Pro、GPQA 等测试上的分数更高。因此,是否令人印象深刻,完全取决于您对 Instant 档位的期待——是速度还是分数。Instant 从来不是为了在分数上夺冠。
我们从推理、网页搜索,以及在医疗问题上的幻觉规避这三个方面对新模型进行了测试——OpenAI 指出这是一个主要改进领域。
我们在 GPT-5.3 Instant 的文章中用过这个提示,它已成为一个有用的长期对照。问题看似简单:“距离一个街区的洗车店,应该步行还是开车过去?”但它需要早期模型未能完成的心智迁移。GPT-5.2 Thinking 建议步行。GPT-5.3 Instant 给出了正确答案。
提示词:
I want to wash my car at the car wash. The car wash is one block away. Should I walk or drive?我们将 GPT-5.5 与其前代进行比较。以下是 GPT-5.3 Instant 的回复:
而这就是 GPT-5.5 Instant 的回答:
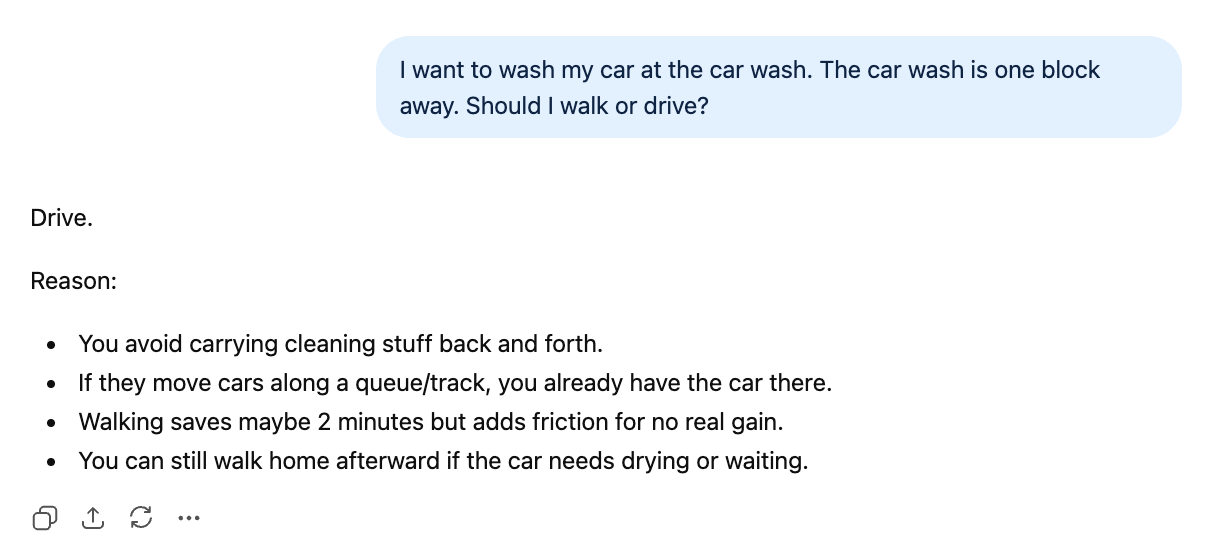
两者都非常简洁(50 vs 49 个词),但 GPT-5.5 更为笃定,因为它没有给出相同的保留条件(“只有在……时才步行”)。就我个人而言,GPT-5.3 Instant 的推理听起来比 GPT-5.5 Instant 更合理一些,因为“你并没有任何收益”比“也许能节省 2 分钟”更接近事实。话虽如此,两者都得出了正确结论。
鉴于 5.5 发布特别声称在“高风险提示”上幻觉减少约 50%,我们选择了一个看似合理但有明确正确答案的医疗问题。我们问:
Can I take ibuprofen and aspirin together?这对大语言模型而言是经典陷阱。真实答案很微妙:两者都是 NSAIDs,同时服用会增加胃肠道出血风险,而且重要的是,如果时间不当,布洛芬会干扰阿司匹林的心血管保护作用。
模型常常要么说“可以,没问题”,要么给出过度谨慎的“一概不要这么做,去看医生”。我们要检查的是,5.5 是否真的给出精确、准确的答案,而非产生幻觉或模糊其词。
该回复的准确度很高:它提到了胃肠道出血风险、作用相互影响,以及 FDA 的时间指引。我们未发现任何幻觉,语气也拿捏得当。不过,格式稍显繁重。对于本可更短或更口语化的回复,它包含了许多项目符号和结构化分段。

总体而言,在幻觉测试上,这是通过的。答案准确、细致,没有编造细节。我们再与 GPT-5.3 Instant 的回复对比:
两者都避免了幻觉,给出了准确、有用的回答,但格式都较重。差别在于 5.5 略为更详尽(例如包含更完整的风险因素列表),而 5.3 更为简洁。
为测试 GPT-5.5 Instant 将网页搜索结果与自身推理相结合的能力,我们以一场近期且层次丰富的体育赛事为题:阿森纳在欧冠半决赛次回合战胜马德里竞技。
好的回答需要从多方来源提炼出正确信息,并将其编织成连贯叙述,而不是简单堆砌搜索摘要。
提示词:
What happened in the Champions League semifinal second leg yesterday, and what does the result mean for Arsenal historically?
GPT-5.5 Instant 的回答非常强。它正确判断了昨天发生的事情,包括总比分和决定性进球者,并且恰好给出了我所期待的语境信息。
作为对比,这是 GPT-5.3 Instant 的回复:
我们再次看到同样的模式:两者都没有犯错;5.3 更快切入要点;5.5 在核心答案之外补充了更多上下文。
GPT-5.5 正作为新的默认 ChatGPT 模型向所有用户推送,并将在 API 中以 chat-latest 提供。GPT-5.3 Instant 将在三个月后退役,在此之前付费用户仍可访问。
部分功能将分阶段推出:
作为用户,您可能真正注意到的是:在错误代价较高的问题上,明显错误的回答更少;回复更为详尽,但未必更短。
在我们的测试中,GPT-5.5 Instant 能补充真正有用的细节(例如在医疗问题上给出更完整的风险因素),但尽管 OpenAI 宣称“更紧凑的回答”,GPT-5.3 Instant 有时更直截了当。
个性化功能的体验见仁见智。它要么让您觉得 ChatGPT 终于能有用地“记住”事情,要么让您觉得有些超出您本意的边界。至少,“记忆来源”功能旨在为您提供一个概览,了解模型在生成回复时使用了哪些信息。
对于有兴趣开发 AI 驱动应用的您,我们强烈推荐报名我们的AI Engineering with LangChain 技能路径。其课程原生于 AI,提供个性化学习体验,帮助您从当前水平进阶为专业人士。
与 DataCamp 一起学习
Courses
Courses
Courses