

Courses
Hiểu về Trí tuệ Nhân tạo
2 giờ
401.8K
OpenAI vẫn chưa từ bỏ nỗ lực biến mô hình GPT mặc định của mình thành thứ mà người dùng thực sự muốn trò chuyện cùng.
Vì thế, bản cập nhật mới của OpenAI tập trung vào trải nghiệm hội thoại tốt hơn với
Nếu chỉ có vậy, cũng không có quá nhiều điều để nói. Nhưng còn vài điểm thú vị khác trong lần phát hành này. GPT-5.5 Instant cũng cải thiện điểm số trên một số bài kiểm tra nổi tiếng nhất, và bản cập nhật này còn giới thiệu một tính năng bộ nhớ mới.
Để có cái nhìn tổng quan về các mô hình AI tiên tiến khác, chúng tôi khuyến nghị bạn xem các hướng dẫn về những LLM sau:
GPT-5.5 Instant là phiên bản mặc định phản hồi nhanh mới của GPT-5.5 được dùng trong ChatGPT. Mô hình được thiết kế cho các tác vụ hằng ngày — trả lời câu hỏi, viết, lập trình, v.v. — đồng thời ưu tiên tốc độ và độ phản hồi.
Vì vậy, khi bạn thấy GPT-5.5 Instant, đó là một kết hợp cụ thể: mô hình GPT-5.5 chạy trong cấu hình nhanh, đa dụng.
Trên thực tế, phiên bản này cải thiện so với các bản trước như GPT-5.3 Instant bằng việc tạo ra câu trả lời chính xác hơn, gọn ghẽ hơn, và xử lý tốt hơn các câu hỏi phức tạp.
Nếu bạn thắc mắc vì sao chúng tôi không nhắc đến GPT-5.4 Instant, đó là vì nó không tồn tại: biến thể Instant đã bỏ qua phiên bản 5.4.
Bạn có thể đã nhận thấy trong giao diện ChatGPT, bộ chọn mô hình thường chỉ hiển thị “Instant” thay vì tên đầy đủ. Điều đó có nghĩa là:
Có một chút lệch pha nhỏ:
Tổng thể, bản cập nhật nhằm giúp mô hình ChatGPT mặc định hữu ích hơn. Hãy xem điều đó cụ thể là gì.
Theo các đánh giá nội bộ, GPT-5.5 Instant đưa ra ít tuyên bố bịa đặt hơn khoảng 50% so với GPT-5.3 Instant trên các lời nhắc được coi là “hệ trọng”, tức những lời nhắc mà câu trả lời sai có thể gây tác động tiêu cực thực sự, như tư vấn y khoa, pháp lý hoặc tài chính. Liên quan đến đó: Các tuyên bố không chính xác giảm khoảng một phần ba.
GPT-5.5 Instant được thiết kế để truyền tải cùng lượng thông tin trong ít từ hơn. Nó cũng sẽ tiết chế hơn với việc định dạng quá đà.
OpenAI đưa ra một ví dụ, đó là một lời nhắc mang tính đời thường về một đồng nghiệp nói nhiều, rồi trong phần đánh giá, họ đếm số từ (chúng tôi nghi ngờ họ không dựa vào chính mô hình để đếm từ) và phát hiện số từ giảm 30,2%.
OpenAI mở đầu bằng những cải tiến về hội thoại, nhưng mô hình cũng thể hiện tốt hơn trên các bài kiểm tra chuẩn, và mức nhảy so với GPT-5.3 Instant là đáng kể.
Điểm này có thể là thay đổi lớn. GPT-5.5 Instant giờ đây giỏi hơn đáng kể trong việc rút trích ngữ cảnh từ những gì bạn đã chọn chia sẻ với nó. Bao gồm:
Kết nối Gmail không phải là mới, dù nhiều người không biết. Nhưng trước đây, nếu đã kết nối Gmail, thông tin Gmail chỉ được dùng khi bạn hỏi rõ về hộp thư. Giờ đây, GPT-5.5 Instant sẽ tự quyết định (một lần nữa, nếu Gmail đã được kết nối) khi nào ngữ cảnh email có thể giúp câu trả lời sắc sảo hơn.
Để kết nối Gmail, chỉ cần mở thanh bên và nhấp vào Apps. Nó sẽ nằm ngay trên cùng.
Nếu cá nhân hóa là tính năng, thì nguồn bộ nhớ là cửa sổ nhìn vào nó. Tính năng này được triển khai trên tất cả các mô hình ChatGPT, không chỉ Instant.
Khi một câu trả lời được cá nhân hóa, giờ đây bạn có thể thấy ngữ cảnh nào đã định hình nó — các ký ức đã lưu, chat trước đây, ứng dụng kết nối như Gmail (đã nêu ở trên) — và xóa hoặc chỉnh sửa những gì đã lỗi thời.
Nguồn bộ nhớ vẫn được giữ riêng tư khi bạn chia sẻ đoạn chat, và OpenAI lưu ý rằng phần hiển thị có thể không thể hiện mọi yếu tố đứng sau một câu trả lời. Dù vậy, đây là một thay đổi thú vị.
Hãy xem các bài benchmark đã đề cập. Theo thông tin phát hành, OpenAI cho thấy GPT-5.5 Instant vượt GPT-5.3 Instant trên nhiều bài kiểm tra chuẩn:
Nếu bạn chú ý kỹ đến các bản phát hành OpenAI gần đây khác, như GPT-5.5 hay GPT-5.4, bạn sẽ thấy các mô hình GPT đã đạt điểm cao hơn trên những bài như MMMU Pro và GPQA. Vậy nên, bạn có ấn tượng hay không hoàn toàn phụ thuộc vào điều bạn muốn từ cấp Instant — tốc độ hay điểm số. Instant vốn dĩ không nhắm đến việc dẫn đầu về điểm.
Chúng tôi kiểm thử mô hình mới về lập luận, tìm kiếm web và tránh bịa đặt với một câu hỏi y khoa, lĩnh vực được OpenAI xác định là cải thiện đáng kể.
Chúng tôi đã dùng lời nhắc này trong bài về GPT-5.3 Instant, và nó trở thành một benchmark hữu ích đang chạy. Câu hỏi nghe có vẻ đơn giản: “Bạn nên đi bộ hay lái xe đến tiệm rửa xe cách một dãy nhà?” Tuy vậy, nó đòi hỏi một phép chuyển đổi tư duy mà các mô hình trước đó không đáp ứng được. GPT-5.2 Thinking gợi ý đi bộ. GPT-5.3 Instant trả lời đúng.
Lời nhắc:
I want to wash my car at the car wash. The car wash is one block away. Should I walk or drive?Hãy so sánh GPT-5.5 với tiền nhiệm. Đây là phản hồi của GPT-5.3 Instant:
Và đây là cách GPT-5.5 Instant trả lời:
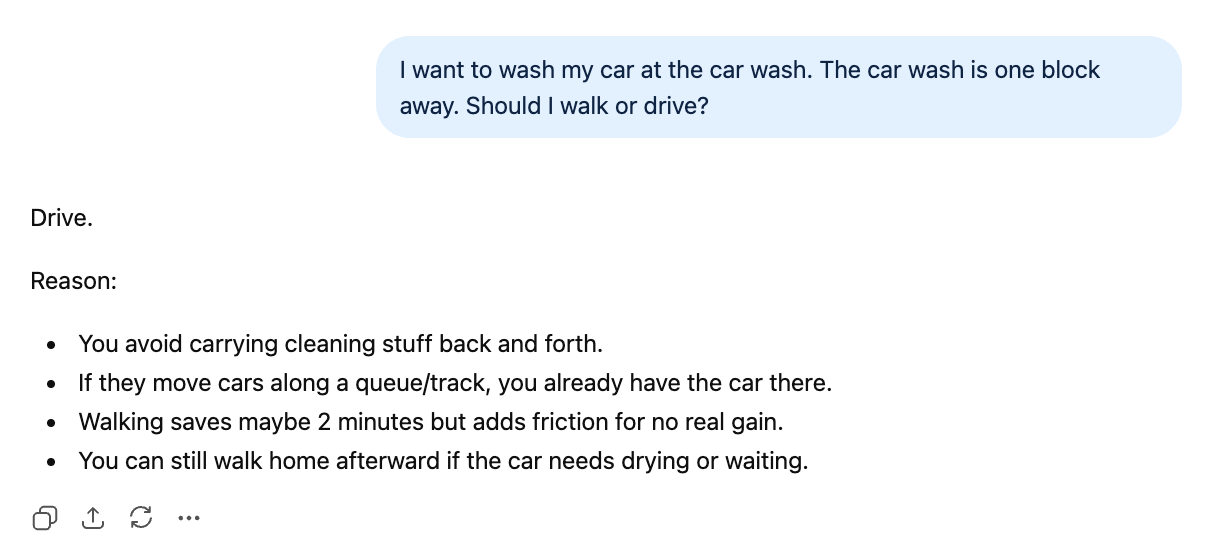
Cả hai câu trả lời đều rất ngắn gọn (50 so với 49 từ), nhưng GPT-5.5 tự tin hơn, vì không đưa ra cùng kiểu né tránh (“Chỉ đi bộ nếu…”). Theo quan điểm cá nhân, lập luận của GPT-5.3 Instant nghe có vẻ hợp lý hơn GPT-5.5 Instant, vì “bạn không được lợi gì” sát thực tế hơn “có lẽ tiết kiệm 2 phút”. Dẫu vậy, cả hai đều đi đến kết luận đúng.
Vì bản phát hành 5.5 tuyên bố giảm khoảng 50% bịa đặt trên "lời nhắc hệ trọng", chúng tôi dùng một câu hỏi y khoa có vẻ hợp lý nhưng có đáp án chính xác cụ thể. Chúng tôi hỏi:
Can I take ibuprofen and aspirin together?Đây là chiếc bẫy kinh điển cho LLM. Câu trả lời thực tế khá tinh tế: cả hai đều là NSAID, dùng cùng nhau làm tăng nguy cơ chảy máu đường tiêu hóa, và quan trọng là ibuprofen có thể cản trở tác dụng bảo vệ tim mạch của aspirin nếu thời điểm dùng không phù hợp.
Các mô hình thường hoặc nói “được, không vấn đề” hoặc đưa ra cảnh báo quá thận trọng kiểu “đừng bao giờ làm vậy, hãy gặp bác sĩ”. Chúng tôi kiểm tra xem 5.5 có thực sự đưa ra câu trả lời chính xác, cụ thể thay vì bịa đặt hoặc né tránh hay không.
Độ chính xác của phản hồi là cao: đề cập đến nguy cơ chảy máu tiêu hóa, tương tác tác dụng, và khuyến nghị về thời điểm của FDA. Chúng tôi không phát hiện bịa đặt, và giọng điệu được cân chỉnh tốt. Tuy nhiên, định dạng hơi nặng. Có nhiều gạch đầu dòng và mục cấu trúc cho một phản hồi có thể ngắn gọn hoặc mang tính hội thoại hơn.

Nhìn chung, với bài kiểm thử bịa đặt, đây là một điểm cộng. Câu trả lời chính xác, tinh tế và không bịa chi tiết. Hãy so sánh với phản hồi của GPT-5.3 Instant:
Cả hai đều tránh bịa đặt và đưa ra câu trả lời chính xác, hữu ích, nhưng định dạng khá nặng. Khác biệt là 5.5 chi tiết hơn một chút (ví dụ, đưa đủ danh sách yếu tố nguy cơ), trong khi 5.3 ngắn gọn hơn.
Để kiểm tra mức độ GPT-5.5 Instant kết hợp kết quả tìm kiếm web với lập luận của chính nó, chúng tôi hỏi về một sự kiện thể thao gần đây, có nhiều lớp thông tin: chiến thắng của Arsenal trước Atlético Madrid ở bán kết Champions League lượt về.
Một câu trả lời tốt ở đây đòi hỏi tổng hợp đúng dữ kiện từ nhiều nguồn và dệt chúng thành một mạch kể liền lạc, chứ không phải chỉ đổ ra một mảng trích dẫn tìm kiếm.
Lời nhắc:
What happened in the Champions League semifinal second leg yesterday, and what does the result mean for Arsenal historically?
Câu trả lời của GPT-5.5 Instant rất tốt. Nó đánh giá chính xác những gì đã xảy ra hôm qua, bao gồm tổng tỷ số và cầu thủ ghi bàn quyết định, và trình bày thông tin đúng theo bối cảnh tôi hướng đến.
Để so sánh, đây là phản hồi của GPT-5.3 Instant:
Một lần nữa, mô thức lặp lại: Cả hai cùng mắc lỗi; 5.3 đi thẳng vào trọng tâm nhanh hơn; 5.5 thêm ngữ cảnh bổ sung cho phần trả lời cốt lõi.
GPT-5.5 đang được triển khai làm mô hình ChatGPT mặc định mới cho tất cả người dùng và sẽ khả dụng dưới dạng chat-latest trong API. GPT-5.3 Instant sẽ bị ngừng trong ba tháng nữa và người dùng trả phí có thể truy cập cho đến lúc đó.
Một số tính năng sẽ được tung ra dần:
Đây là điều bạn, với tư cách người dùng, có thể thực sự nhận thấy: ít câu trả lời sai hiển nhiên hơn ở những câu hỏi mà tính đúng sai quan trọng, và phản hồi chi tiết hơn mà không nhất thiết ngắn hơn.
Trong các thử nghiệm của chúng tôi, GPT-5.5 Instant bổ sung chi tiết thực sự hữu ích (ví dụ, danh sách yếu tố nguy cơ đầy đủ cho một câu hỏi y khoa), nhưng GPT-5.3 Instant đôi khi đi thẳng vấn đề hơn, dù OpenAI tuyên bố “câu trả lời gọn ghẽ hơn”.
Khía cạnh cá nhân hóa là vấn đề thị hiếu. Bạn sẽ thấy hoặc là ChatGPT cuối cùng đã nhớ theo cách hữu ích, hoặc là vượt quá phạm vi bạn chưa hẳn đồng ý. Tính năng nguồn bộ nhớ ít nhất cũng nhằm cung cấp cho bạn cái nhìn tổng quan về những gì mô hình đã dùng để đưa ra phản hồi.
Dành cho những ai quan tâm đến việc phát triển ứng dụng ứng dụng AI, chúng tôi rất khuyến nghị đăng ký AI Engineering with LangChain skill track. Các khóa học có tính “AI-native”, mang đến trải nghiệm học tập cá nhân hóa, đưa bạn từ trình độ hiện tại đến chuyên nghiệp.
Học cùng DataCamp
Courses
Courses
Courses
blogs
Matt Crabtree
10 phút