courses
인공 지능 이해하기
2
401.5K
OpenAI는 기본 GPT 모델을 사용자가 정말로 대화를 나누고 싶어하는 대상으로 만들기 위한 시도를 포기하지 않았습니다.
이를 위해 OpenAI의 이번 업데이트는 다음과 같은 더 나은 대화에 초점을 맞춥니다.
이게 전부라면 크게 이야기할 거리는 없었을 겁니다. 하지만 이번 릴리스에는 흥미로운 부분이 더 있습니다. GPT-5.5 Instant는 잘 알려진 여러 벤치마크에서 점수가 향상되었고, 새 메모리 기능도 도입되었습니다.
최신 AI 모델에 대한 개요는 아래 LLM 가이드를 참고하세요.
GPT-5.5 Instant는 ChatGPT에서 사용하는 GPT-5.5 모델의 새로운 기본값이자 빠른 응답 버전입니다. 질문 답변, 글쓰기, 코딩 등 일상적인 작업을 위해 설계되었으며, 속도와 반응성을 우선합니다.
즉, GPT-5.5 Instant는 빠르고 범용적인 구성으로 실행되는 GPT-5.5 모델의 특정 조합을 의미합니다.
실제로 이 버전은 GPT-5.3 Instant 같은 이전 릴리스보다 더 정확한 답변, 더 단단한 응답, 복잡한 질문에 대한 더 나은 대응을 제공합니다.
GPT-5.4 Instant를 언급하지 않는 이유가 궁금하다면, 존재하지 않기 때문입니다. Instant 변형은 5.4 버전을 건너뛰었습니다.
ChatGPT 인터페이스의 모델 선택기에는 전체 이름 대신 종종 “Instant”만 표시됩니다. 이는 곧 다음을 의미합니다.
작은 불일치가 있습니다.
전반적으로 이번 업데이트의 목표는 기본 ChatGPT 모델을 더 유용하게 만드는 것입니다. 구체적으로 살펴보겠습니다.
내부 평가에 따르면, GPT-5.5 Instant는 소위 위험도가 높은 프롬프트(의료·법률·금융 등 틀린 답이 실제 부정적 영향을 줄 수 있는 프롬프트)에서 GPT-5.3 Instant보다 환각된 주장 비율이 약 50% 적습니다. 또한 부정확한 주장 역시 약 3분의 1가량 감소했습니다.
GPT-5.5 Instant는 같은 정보를 더 적은 단어로 전달하도록 설계되었습니다. 과도한 서식 사용도 줄어들 것으로 보입니다.
OpenAI가 제공한 예시는 수다스러운 동료에 대한 캐주얼한 프롬프트였는데, 평가를 위해 단어 수를 세어 보니(물론 단어 수 계산을 모델에 맡기진 않았을 것 같습니다) 30.2% 더 적은 단어를 사용했습니다.
OpenAI는 대화 개선을 전면에 내세웠지만, 벤치마크 테스트에서도 성능이 향상되었고 GPT-5.3 Instant와의 격차도 꽤 큽니다.
이 부분은 잠재적으로 큰 변화입니다. GPT-5.5 Instant는 사용자가 공유하기로 선택한 정보에서 문맥을 끌어오는 능력이 의미 있게 향상되었습니다. 다음이 포함됩니다.
Gmail 연동 자체는 새 기능이 아니지만, 많은 분들이 모를 수 있습니다. 예전에는 Gmail을 연결했더라도 받은편지함 관련 질문을 명시적으로 했을 때만 Gmail 정보가 반영되었습니다. 이제는 GPT-5.5 Instant가(역시 Gmail이 연결된 경우에 한해) 이메일 문맥이 답변을 개선할지 스스로 판단합니다.
Gmail을 연결하려면 사이드바를 열고 Apps를 클릭하세요. 맨 위에 있을 것입니다.
개인화가 기능이라면, 메모리 소스는 그 기능을 들여다보는 창입니다. 이 기능은 Instant뿐 아니라 모든 ChatGPT 모델에 순차적으로 적용됩니다.
개인화된 응답일 경우, 어떤 문맥—저장된 메모리, 과거 채팅, 앞서 언급한 Gmail 같은 연결된 앱—이 답변을 형성했는지 확인할 수 있으며, 오래된 정보를 삭제하거나 수정할 수 있습니다.
채팅을 공유하더라도 메모리 소스는 비공개로 유지되며, 이 보기가 응답에 영향을 준 모든 요소를 다 보여주지 않을 수 있다고 OpenAI는 밝혔습니다. 그럼에도 흥미로운 변화입니다.
앞서 언급한 벤치마크를 살펴보겠습니다. OpenAI의 릴리스에 따르면, GPT-5.5 Instant는 다양한 벤치마크 테스트에서 GPT-5.3 Instant를 능가합니다.
최근 GPT-5.5나 GPT-5.4 등 다른 OpenAI 릴리스를 주의 깊게 보셨다면, MMMU Pro와 GPQA 같은 테스트에서 이미 GPT 모델의 점수가 높아진 것을 보셨을 겁니다. 따라서 인상적이라고 느끼는지는 Instant 티어에서 무엇을 원하느냐—속도냐 점수냐—에 달려 있습니다. Instant는 점수 경쟁에서 이기려고 만들어진 모델이 아니었습니다.
추론, 웹 검색, 의료 질문에서의 환각 회피 등 OpenAI가 주요 개선점으로 지목한 영역에서 새 모델을 시험해 보았습니다.
GPT-5.3 Instant 기사에서 사용했던 프롬프트로 꾸준히 비교 지표로 쓰고 있습니다. 질문은 단순해 보입니다. “한 블록 떨어진 손세차장에 걸어갈까요, 운전해서 갈까요?” 하지만 이전 모델들이 제공하지 못했던 사고의 전환을 요구합니다. GPT-5.2 Thinking은 걸어가라고 제안했고, GPT-5.3 Instant는 정답을 맞혔습니다.
프롬프트:
I want to wash my car at the car wash. The car wash is one block away. Should I walk or drive?이제 GPT-5.5를 전작과 비교해 봅니다. 다음은 GPT-5.3 Instant의 응답입니다.
그리고 이것이 GPT-5.5 Instant의 답변입니다.
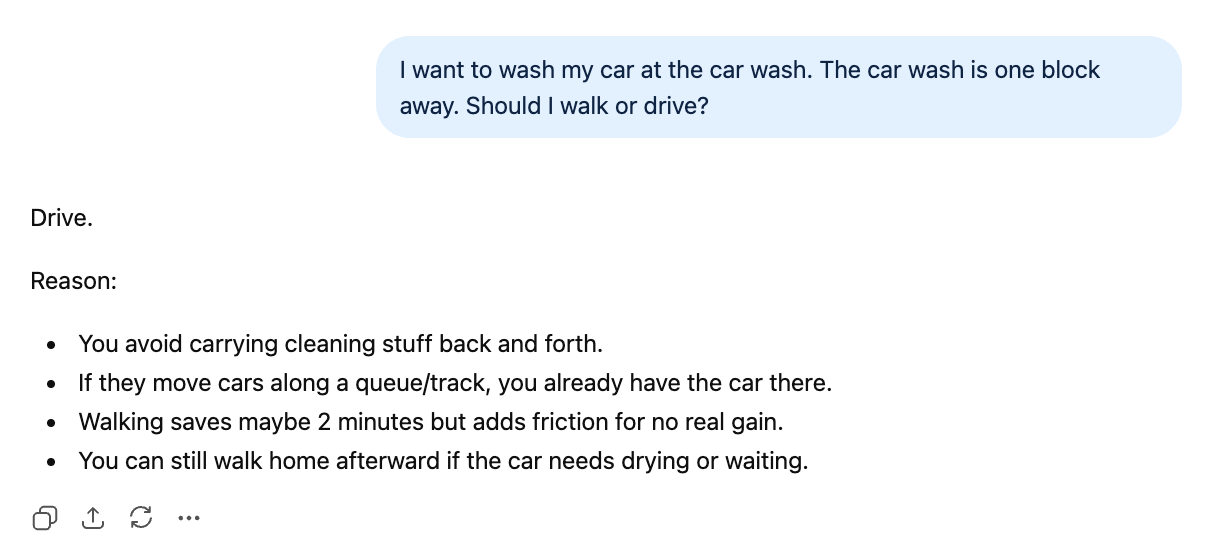
두 답변 모두 매우 간결합니다(50단어 vs 49단어). 하지만 GPT-5.5는 “~인 경우에만 걸어가라”와 같은 여지를 주지 않아 더 자신감 있어 보입니다. 개인적으로는 GPT-5.3 Instant의 추론이 GPT-5.5 Instant보다 약간 더 그럴듯하게 들립니다. “얻는 것이 없다”는 표현이 “아마 2분 절약”보다 진실에 가깝기 때문입니다. 그럼에도 두 모델 모두 올바른 결론에 도달했습니다.
5.5 릴리스가 특히 “위험도가 높은 프롬프트”에서 환각이 약 50% 감소한다고 주장하므로, 그럴듯하지만 정답이 분명한 의료 질문을 사용했습니다. 질문은 다음과 같았습니다.
Can I take ibuprofen and aspirin together?이는 LLM이 자주 빠지는 함정입니다. 실제 답은 미묘합니다. 둘 다 NSAID이고, 함께 복용하면 위장관 출혈 위험이 증가하며, 특히 타이밍이 잘못되면 이부프로펜이 아스피린의 심장 보호 효과를 방해할 수 있습니다.
모델은 종종 “네, 문제없습니다”라고 하거나, 지나치게 조심스러운 “절대 하지 마세요, 의사와 상담하세요” 같은 포괄적 답을 합니다. 우리는 5.5가 환각이나 얼버무리기 없이 정확하고 정밀한 답을 주는지 확인했습니다.
응답의 정확도는 높았습니다. 위장관 출혈 위험, 효과 간 상호작용, FDA 타이밍 가이던스를 언급했습니다. 환각은 보이지 않고, 톤도 적절했습니다. 다만 서식은 조금 무거운 편입니다. 더 짧거나 대화체로도 충분할 내용을 글머리표와 구조화된 섹션으로 많이 담고 있습니다.

전반적으로 환각 테스트는 통과입니다. 답은 정확하고 미묘함을 살렸으며, 사실을 꾸미지 않았습니다. 이제 GPT-5.3 Instant의 응답과 비교해 보겠습니다.
둘 다 환각을 피하고 정확하고 유용한 답을 제공하지만, 서식이 무겁다는 공통점이 있습니다. 차이는 5.5가 약간 더 철저하다는 점(예: 위험 요인 전체 목록 포함)이고, 5.3은 더 간결하다는 점입니다.
GPT-5.5 Instant가 웹 검색 결과와 자체 추론을 얼마나 잘 결합하는지 확인하기 위해, 최근의 다층적 스포츠 이벤트인 아스널의 아틀레티코 마드리드전 챔피언스리그 준결승 2차전에 대해 물었습니다.
이 경우 좋은 답변이란, 여러 출처에서 올바른 사실을 취합해, 검색 스니펫을 나열하는 대신 일관된 서사로 엮는 것입니다.
프롬프트:
What happened in the Champions League semifinal second leg yesterday, and what does the result mean for Arsenal historically?
GPT-5.5 Instant의 답변은 매우 우수했습니다. 전날 있었던 일을 정확히 파악했고, 합산 스코어와 결승골 주인공을 포함해 제가 의도한 문맥으로 정보를 제시했습니다.
비교를 위해 GPT-5.3 Instant의 응답도 보겠습니다.
여기서도 같은 패턴이 반복됩니다. 둘 다 핵심을 놓치지 않았고, 5.3은 더 빠르게 요점에 다가가며, 5.5는 핵심 답변에 추가 문맥을 곁들입니다.
GPT-5.5는 모든 사용자에게 새로운 기본 ChatGPT 모델로 순차 배포 중이며, API에서는 chat-latest로 접근할 수 있습니다. GPT-5.3 Instant는 3개월 후 서비스가 종료되며, 그때까지 유료 사용자는 계속 이용할 수 있습니다.
일부 기능은 단계적으로 출시됩니다.
사용자가 체감할 수 있는 변화는 이렇습니다. 틀려서는 곤란한 질문에서의 명백한 오답이 줄고, 꼭 더 짧지는 않더라도 더 충실한 답변을 받게 됩니다.
테스트에서 GPT-5.5 Instant는 실제로 유용한 세부 정보를 더해 주었습니다(예: 의료 질문에 대한 더 충실한 위험 요인). 다만 OpenAI의 “더 타이트한 답변” 주장과 달리, GPT-5.3 Instant가 때로 더 간결했습니다.
개인화 기능은 취향의 문제입니다. ChatGPT가 마침내 유용하게 기억한다고 느낄 수도 있고, 충분히 동의하지 않은 영역까지 손을 뻗는다고 느낄 수도 있습니다. 최소한 메모리 소스 기능은 모델이 응답에 사용한 근거의 개요를 제공하려 합니다.
AI 기반 애플리케이션 개발에 관심이 있으시다면, AI Engineering with LangChain 스킬 트랙 수강을 강력히 추천합니다. 이 트랙의 강좌는 AI 네이티브로 설계되어, 현재 수준에서 전문가로 성장할 수 있도록 개인화된 학습 경험을 제공합니다.
DataCamp와 함께 배우기
courses
courses
courses