Snowflake is een cloudgebaseerd dataplatform dat dataopslag en -analyse heeft vernieuwd. Terwijl de meeste cloudplatformen analytische berekeningen en opslaggerelateerde taken zoals datatransfers op dezelfde resources uitvoeren, scheidt Snowflake’s unieke architectuur de rekenlast van de opslaglast. Naarmate de hoeveelheid data toeneemt, wordt Snowflake’s vermogen om zich aan te passen aan de behoeften van de organisatie steeds crucialer in de moderne data-economie.
Dit artikel introduceert Snowflake vanaf de basis. Je hebt geen voorkennis van databases of cloud computing nodig om mee te kunnen doen. We leggen uit wat Snowflake is, wat het anders maakt, hoe het wordt gebruikt en hoe je vandaag nog kunt beginnen. Zoek je een meer hands-on aanpak, bekijk dan onze Snowflake Foundations skill track.
Wat is Snowflake?
Traditionele on-premises databases hebben al hun opslagruimte, rekenkracht en netwerkapparatuur op het terrein van het bedrijf (on-prem).
Snowflake is een cloud-native dataplatform waarmee organisaties data op schaal kunnen opslaan, beheren, analyseren en delen. Snowflake draait volledig in de cloud en biedt krachtige tools voor datawarehousing, data lakes, business intelligence en machine learning, allemaal in één platform.
Bovendien maakt het het delen van data tussen verschillende teams eenvoudig. Data engineers en data-analisten gebruiken vaak een programmeertaal genaamd SQL om respectievelijk datatransformatie en data-analyse uit te voeren. Omdat Snowflake op SQL draait, kunnen deze twee groepen makkelijker communiceren over hun databehoeften.
Het integreert uitstekend met andere cloudproviders en wordt vaak gekozen vanwege de unieke architectuur die helpt bij efficiënte dataverwerking.
Cloudintegratie
Snowflake is zelf een complete data cloud-omgeving, maar dat betekent niet dat gebruikers volledig vastzitten aan het eigen ecosysteem. Het integreert met de drie grote cloudplatformen:
- Amazon Web Services (AWS)
- Microsoft Azure
- Google Cloud Platform (GCP)
Dankzij deze integraties kunnen Snowflake-gebruikers eenvoudig data delen van Snowflake naar hun bestaande cloudplatform en omgekeerd. Dit geeft organisaties de flexibiliteit om Snowflake te implementeren in de cloudomgeving die ze al gebruiken, met minimale ontwikkelinspanning.
Unieke architectuur
Snowflake heeft drie hoofdlagen: een servicelaag, een rekenlaag (compute) en een opslaglaag. De servicelaag is gemeenschappelijk en host alle cloudfuncties zoals beveiliging, toegang en infrastructuur. Wat Snowflake zo interessant maakt, is hoe het de reken- en opslaglaag van elkaar scheidt.
Meestal delen rekenresources zoals CPU en geheugen zowel de verwerking als het opslaan van data. Snowflake’s scheiding van die twee biedt een paar mooie voordelen die het schaalbaar en efficiënter maken. Dat doet het met het concept van “virtuele warehouses” waarbij elke gebruiker in Snowflake zijn eigen set virtuele resources krijgt die niet met anderen worden gedeeld.
Zo is data delen eenvoudig, omdat je meer resources kunt inzetten voor het verplaatsen en kopiëren van data naar gebruikers. In plaats van dat iedereen in je bedrijf data uit één kopie haalt, maakt Snowflake tijdelijke kopieën voor iedere gebruiker.
En omdat je geen kostbare resources meer besteedt aan de opslag en het kopiëren van data, heb je meer CPU beschikbaar voor analyse en dataverwerking. Dat betekent dat je SQL-query’s en analytische pipelines sneller draaien, zolang je virtuele warehouse groot genoeg is voor de benodigde rekenkracht.
Hier is een samenvatting van de voordelen:
- Opslag: Je data staat in een centrale repository. Alles wat de data benadert, zoals het partitioneren of indexeren van de data, wordt uitgevoerd door workers die gespecialiseerd zijn in opgeslagen data. Snowflake deelt vervolgens de componenten van de data die nodig zijn voor de sessie van de gebruiker.
- Compute: Rektaken worden uitgevoerd door virtuele warehouses, wat in feite clusters van rekenresources (CPU en geheugen) zijn die zaken als analytische SQL-taken, het laden/wegschrijven van data, enzovoort afhandelen.
Snowflake’s architectuur biedt enkele belangrijke voordelen door opslag en rekenresources te scheiden:
- Schaalbaarheid: Schaal rekenkracht en opslag eenvoudig onafhankelijk van elkaar. Meer opslag nodig? Voeg het toe zonder extra CPU-kosten. Meer verwerkingskracht nodig? Vergroot je virtuele warehouse zonder de dataopslag te beïnvloeden.
- Gelijktijdigheid: Meerdere gebruikers en taken draaien gelijktijdig zonder om resources te concurreren, wat consistente prestaties voor iedereen waarborgt.
- Kostenefficiëntie: Je betaalt alleen voor wat je gebruikt. Schaal resources snel op of af op basis van de vraag, waardoor onnodige kosten worden beperkt.
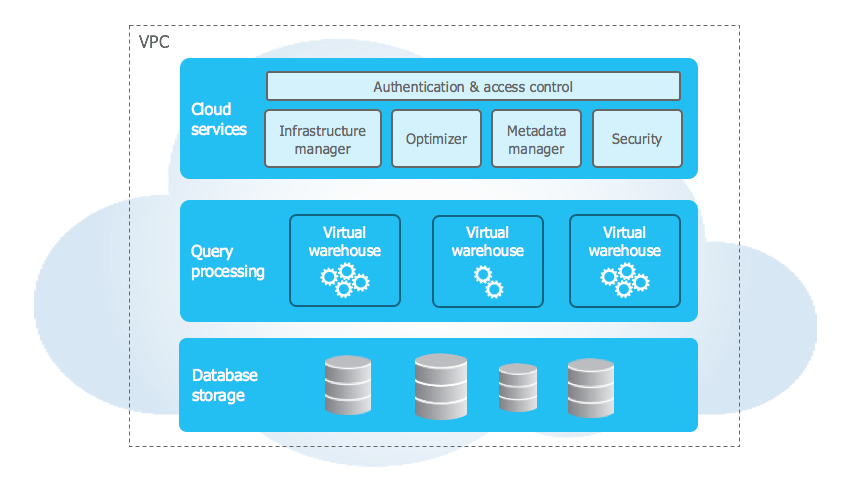
Snowflake-architectuur (docs.snowflake.com)
Voor een deep dive, bekijk dit artikel over de architectuur van Snowflake.
Belangrijkste functies van Snowflake
Snowflake is een volledig beheerd, cloud-native dataplatform dat is gebouwd om te voldoen aan de behoeften van moderne datateams. Zoals we hebben gezien, biedt het uitstekende schaalbaarheid, prestaties en beveiliging. Het is ook vrij eenvoudig te gebruiken dankzij SQL-ondersteuning en een gebruiksvriendelijke interface.
Schaalbaarheid
Schaalbaarheid verwijst naar hoe goed een systeem kan groeien en meer data of meer gebruikers aankan zonder prestatieverlies. Snowflake blinkt hierin uit dankzij de gescheiden opslag- en rekenarchitectuur. Heb ik meer rekenkracht nodig, dan kan ik de virtuele warehouses groter maken. Heb ik meer opslag nodig, dan kan ik gewoon meer opslagruimte aanvragen.
In traditionele systemen betekent opschalen vaak downtime of het herconfigureren van hardware. Als ik meer compute of meer opslag wil, kan dat een langdurig proces zijn van oude hardware verwijderen en data of software kopiëren naar nieuwe hardware. In Snowflake is het slechts één klik (of commando) verwijderd.
Voorbeelden:
- Een kleine startup kan beginnen met een X-Small warehouse voor lichte query’s en incidentele rapporten.
- Naarmate de data groeit, kunnen ze upgraden naar een Large of X-Large warehouse, zonder data te migreren. Traditionele dataservices vereisen mogelijk dat je die data eerst naar een groter fysiek warehouse overzet voordat je over meer rekenkracht kunt beschikken.
- Voor hoge gelijktijdigheid (veel gebruikers die het systeem tegelijk benaderen) ondersteunt Snowflake multi-cluster warehouses die automatisch extra clusters opstarten om de belasting aan te kunnen.
Snowflake schaalt rekenclusters ook automatisch op of af op basis van de werklast. Dit zorgt voor:
- Snelle query-prestaties tijdens piekgebruik.
- Kostenbesparing tijdens idle-periodes (rekenresources pauzeren automatisch).
Prestaties
Snowflake is geoptimaliseerd voor veeleisende dataworkloads en biedt consistente snelheid, of je nu complexe analyses draait, batchuploads uitvoert of live dashboards voedt. Belangrijke technologieën die zorgen voor hoge prestaties zijn onder meer:
- Kolomgebaseerde opslag: Data opgeslagen in kolommen in plaats van rijen versnelt analytische query’s doordat alleen de benodigde data snel wordt opgehaald.
- Automatische query-optimalisatie: Snowflake analyseert en optimaliseert query’s automatisch, waardoor de prestaties verbeteren naarmate je het meer gebruikt.
- Resultaatcaching: Vaak uitgevoerde query’s worden direct bediend vanuit de cache, wat zowel rekentijd als kosten vermindert.
- Metadata-beheer: Intelligent bijhouden van datastatistieken en querypatronen zorgt voor efficiënte query-executie.
Beveiliging
Snowflake geeft prioriteit aan beveiliging op ondernemingsniveau met robuuste maatregelen die je data beschermen:
- End-to-end encryptie: AES-256-encryptie beveiligt data zowel in rust als tijdens transport.
- Role-Based Access Control (RBAC): Fijnmazig toegangsbeheer zorgt dat gebruikers alleen zien wat nodig is, wat het risico minimaliseert.
- Multi-factor-authenticatie: Voegt een extra beveiligingslaag toe voor toegang tot Snowflake.
- Datamasking en security op rijniveau: Fijnmazige controles beperken de zichtbaarheid van gevoelige data per rol.
- Compliance-certificeringen: Voldoet aan industrienormen zoals HIPAA en GDPR.
- Time travel en fail-safe: Herstel historische data en verwijderde records tot 90 dagen terug, ter bescherming tegen fouten of kwaadwillende activiteiten.
Gebruiksgemak
Snowflake staat bekend om zijn gebruiksvriendelijke ontwerp, vooral prettig voor beginners met SQL-kennis. Belangrijke gebruiksfeatures zijn:
- Webgebaseerde interface: Een intuïtieve UI vereenvoudigt database-navigatie, het schrijven van query’s en gebruikersbeheer.
- Compatibel met standaard SQL: Geen nieuwe taal nodig. Snowflake ondersteunt vertrouwde SQL-instructies direct uit de doos.
- Geen infrastructuurbeheer: Volledig beheerd, met automatische schaalvergroting en -optimalisatie waardoor setup of onderhoud van infrastructuur overbodig is.
- Brede toolintegratie: Sluit naadloos aan op analysetools (PowerBI, Tableau), ETL-diensten (Fivetran) en talen (Python, Java).
- Datamarktplaats: Verken en abonneer je eenvoudig op externe datasets zonder data te verplaatsen, wat je analysecapaciteiten vergroot.
Snowflake wil elke overgang vanaf een andere dienst of platform zo eenvoudig mogelijk maken. Hier is een prima code-along-sessie om te leren hoe eenvoudig Snowflake kan worden gebruikt voor data-analyse met talen als Python en SQL.
| Functie | Omschrijving | Belangrijkste voordelen/voorbeelden |
|---|---|---|
| Schaalbaarheid | Schaalt rekenkracht en opslag eenvoudig onafhankelijk van elkaar. |
|
| Prestaties | Geoptimaliseerd voor snelle analytics en betrouwbare workloadafhandeling. |
|
| Beveiliging | Robuuste beveiliging op ondernemingsniveau ter bescherming van dataintegriteit. |
|
| Gebruiksgemak | Gebruiksvriendelijke interface en vertrouwde SQL-compatibiliteit. |
|
Waarvoor wordt Snowflake gebruikt?
Snowflake kent een breed scala aan toepassingen, van datawarehouse tot real-time analytics. In deze sectie behandelen we de basis van Snowflake’s functies.
Datawarehousing
Een datawarehouse is in essentie een centraal knooppunt voor gestructureerde data die uit verschillende bronnen is verzameld. Snowflake is populair omdat het alle technische complexiteit automatisch afhandelt. Je hoeft je geen zorgen te maken over serveronderhoud of het handmatig optimaliseren van je opslag; Snowflake regelt dat voor je.
- Automatisch schalen betekent dat je warehouse groeit of krimpt op basis van de vraag.
- Minimale inspanning voor infrastructuur—focus gewoon op het analyseren van je data.
- Snelle query-prestaties zonder gespecialiseerde skills nodig te hebben.
Datalakes
Datalakes slaan ruwe, onbewerkte data op, die gestructureerd (zoals spreadsheets), semigestructureerd (zoals e-mails of JSON-bestanden) of ongestructureerd (audio of video) kan zijn. Traditioneel vereiste het opzetten van een datalake veel voorbereiding, maar Snowflake vereenvoudigt dit door diverse dataformaten zoals JSON, Parquet, ORC, Avro en XML native te ondersteunen.
- Geen externe verwerking of ingewikkelde setups.
- Combineert de flexibiliteit van datalakes met het gemak van een datawarehouse, wat vaak een “lakehouse” wordt genoemd.
Datadeling
Data delen tussen teams of zelfs verschillende organisaties gaat meestal gepaard met veel kopiëren en exporteren. Snowflake maakt dit proces moeiteloos—je houdt je data in je eigen omgeving en geeft anderen simpelweg realtime-toegang.
- Direct en veilig data delen.
- Eenvoudige samenwerking zonder bestanden te hoeven overzetten.
Real-time analytics
Real-time analytics verwijst naar het vermogen om data te verwerken en analyseren zodra deze binnenkomt, in plaats van te wachten op periodieke batchladingen. Snowflake maakt dit mogelijk door ondersteuning voor datainname met lage latency en streamingpijplijnen. Snowflake biedt verschillende tools die real-time analytics ondersteunen:
- Snowpipe: Een serverloze ingestiedienst die bestanden automatisch laadt zodra ze in cloudopslag (bijv. S3, Azure Blob) aankomen.
- Snowpipe Streaming: Een nieuwere mogelijkheid waarmee applicaties data rij-voor-rij naar Snowflake kunnen pushen via SDK’s met sub-seconde latency.
- Streams en Tasks: Native features om wijzigingen te volgen en transformaties te automatiseren
Leer meer over de verschillende datapijplijnen in Snowflake die real-time analytics eenvoudig maken met deze beginnersgids voor het bouwen van pijplijnen in Snowflake.
Het Snowflake-ecosysteem verkennen
Naast krachtige tools voor datapijplijnen heeft Snowflake een volledig analytics-ecosysteem. Het biedt AI- en ML-oplossingen en stelt ontwikkelaars in staat om in hun eigen programmeertaal datatransformaties te bouwen.
Snowflake Cortex: AI en ML integreren
Snowflake Cortex is Snowflake’s ingebouwde laag voor artificial intelligence en machine learning (AI/ML). Het stelt teams in staat om generatieve AI, voorspellende modellen en natural language-ervaringen te bouwen, draaien en opschalen, rechtstreeks waar hun data zich bevindt, zonder data naar externe AI-platformen te hoeven verplaatsen.
Snowflake biedt kant-en-klare AI-functies die je met simpele SQL kunt draaien, zoals het gebruiken van LLM’s (zoals Deepseek of Facebook’s Llama) om klantbeoordelingen samen te vatten, te vertalen en te begrijpen. Cortex Analyst laat gebruikers met natuurlijke taal data bevragen, ideaal voor wie minder SQL-gericht is. Je kunt Snowflake simpelweg vragen: “Hoe waren de verkopen in het afgelopen kwartaal?” en Snowflake voert de query voor je uit.
Snowflake biedt ook een ML Studio met uitstekende no/low-code-opties om machinelearningmodellen te testen en te evalueren op live Snowflake-data. Voor een hands-on gids voor Snowflake Cortex AI, volg deze handleiding over tekstverwerking in Snowflake.
Snowpark: Ontwikkelaars machtigen
Snowpark is een ontwikkelaarsframework waarmee je complexe datalogica kunt bouwen en draaien met vertrouwde programmeertalen, zoals Python, Java of Scala, rechtstreeks binnen de Snowflake-omgeving.
Traditioneel moesten data engineers data uit warehouses halen om die elders te verwerken. Snowpark draait dit model om door de logica naar de data te brengen, wat prestaties, beveiliging en kostenefficiëntie verbetert.
Nu kun je in-databaseverwerking doen waarbij je Python of Java native in Snowflake draait, zonder een aparte Spark-sessie nodig te hebben. Teamleden kunnen op hetzelfde platform SQL of Python gebruiken en op dezelfde data samenwerken. Daarnaast, in plaats van connectors te gebruiken om data lokaal naar deze programmeeromgevingen te halen, draait alles in Snowflake, waardoor het risico op data-exposure afneemt.
Voor meer informatie over het draaien van programmeertalen in Snowflake, leer meer over Snowpark in deze introductie tot Snowflake Snowpark.
Snowflake op AWS
Snowflake is vanaf de basis gebouwd om in de cloud te draaien, met de eerste en meest volwassen implementatie op AWS. Dankzij deze vroege en diepe integratie heeft Snowflake een nauwe interoperabiliteit met belangrijke AWS-diensten, waardoor gebruikers veilige, schaalbare en sterk geautomatiseerde datapijplijnen kunnen bouwen met vertrouwde AWS-tools en -infrastructuur.
Als je organisatie al AWS gebruikt, maakt Snowflake op AWS implementeren het aanzienlijk eenvoudiger om je data te verplaatsen, verwerken en analyseren. Er zijn veel diensten die naadloos met Snowflake samenwerken.
Belangrijke AWS-diensten die met Snowflake werken
1. Amazon S3 (Simple Storage Service)
S3 is AWS’ cloudopslagsysteem, veelgebruikt voor het opslaan van databestanden zoals logs, CSV’s, JSON, Parquet en meer. Hier is een artikel dat meer vertelt over Amazon S3. Snowflake integreert out-of-the-box met S3 en stelt je in staat om:
- Data uit S3 te laden: Je kunt
COPY INTOof Snowpipe gebruiken om gestructureerde of semigestructureerde data uit S3-buckets in Snowflake-tabellen te laden. - Data naar S3 te schrijven: Snowflake laat je ook data exporteren of “stagen” naar S3 voor delen, back-up of verdere verwerking.
- Zero-copy-toegang (via external tables): Snowflake kan data rechtstreeks in S3 bevragen zonder die eerst te kopiëren, met external tables—wat tijd en opslagkosten bespaart.
2. AWS PrivateLink
AWS PrivateLink is een netwerkfeature die private, veilige verbindingen met hoge bandbreedte creëert tussen je AWS Virtual Private Cloud (VPC) en Snowflake.
Zonder PrivateLink zou verkeer tussen je AWS-systemen en Snowflake doorgaans over het publieke internet gaan. Het waarborgt strikte compliance- of latentie-eisen met de volgende kenmerken:
- Je data blijft binnen de grenzen van je AWS-netwerk.
- Je elimineert blootstelling aan het publieke internet.
- Het helpt te voldoen aan beveiligings- en regelgevingseisen, vooral in de financiële sector, gezondheidszorg of overheid.
3. AWS Lambda, SNS en S3 Event Notifications
Snowflake ondersteunt event-gedreven architectuur via automatische ingestie die wordt getriggerd door AWS-diensten. Zo werken ze samen:
- S3 Event Notifications: Elke keer dat een bestand naar een S3-bucket wordt geüpload, kan AWS een melding versturen.
- SNS (Simple Notification Service): Deze meldingen kunnen berichten triggeren naar andere AWS-diensten of systemen.
- AWS Lambda: Dit is een serverloze functie die een script draait wanneer een event plaatsvindt. Je kunt het gebruiken om Snowpipe, Snowflake’s continue datalader, aan te roepen.
Deze workflow maakt handmatig inplannen van dataloads overbodig en maakt ingestiepijplijnen met quasi realtime mogelijk, perfect voor loganalytics, sensordata of applicatietelemetrie.
Wil je meer leren over de nuances van Amazon’s AWS-infrastructuur, bekijk dan deze gidsen over AWS Lambda, over AWS SNS, en S3 EFS.
Ik raad ook sterk deze cursus aan over AWS Cloud- en servicedomeinen om te begrijpen hoe al deze componenten in detail samenwerken.
Aan de slag met Snowflake
Dit is een zeer beknopt overzicht van enkele fundamentele stappen om te beginnen met Snowflake. Wil je meer leren over Snowflake’s essentiële features, volg dan deze cursus Introduction to Snowflake, die de basis behandelt van het laden en verkennen van data in Snowflake.
Toegang krijgen tot Snowflake
De allereerste stap is toegang krijgen. Snowflake biedt (ten tijde van schrijven in mei 2025) een proefperiode met credits om Snowflake’s features te gebruiken. Beginnen is eenvoudig:
- Meld je aan op signup.snowflake.com
- Kies een cloudprovider (AWS, Azure, GCP)
- Log in op de Snowflake-UI
Data laden
Je kunt data in Snowflake laden via een paar opties. Je kunt een ondersteund bestandstype (parquet, JSON, csv, enz.) slepen-en-neerzetten in de UI, waarna het wordt verwerkt tot een tabel in de database en het schema van jouw keuze, SQL gebruiken of derdenprogramma’s inzetten.
Een veelgebruikte manier is om je Snowflake te verbinden met een cloudopslagsysteem zoals Amazon’s S3 en SQL-commando’s zoals COPY INTO te gebruiken om data van je cloudopslag naar je Snowflake-database over te zetten.
Tot slot kun je ook ETL-tools van derden zoals Fivetran en Matillion gebruiken om data te verwerken voordat die in Snowflake wordt gezet. Deze tools helpen je data op te schonen voordat je het in Snowflake laadt. Voor meer details over data in Snowflake krijgen, bekijk deze gids over Snowflake Data Ingestion.
Query’s uitvoeren
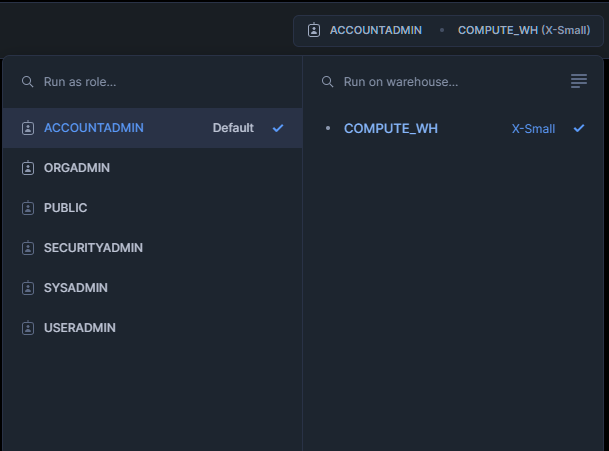
Snowflake maakt het eenvoudig om query’s in de UI uit te voeren. Eerst log je in op je Snowflake-account en open je een worksheet. Het belangrijkste om te begrijpen is dat Snowflake wil dat je een specifieke accountrol en virtuele warehouses selecteert. Dit is onderdeel van Snowflake’s architectuur die je opslagtoegang en rekenresources scheidt.
Als jij, of degene die jouw Snowflake beheert, je verschillende accountrollen heeft gegeven, dan kan elke rol een ander niveau van toegang hebben. Misschien is één rol bedoeld voor live productiedata en een andere voor testen. Dit voorkomt dat je per ongeluk data uit verschillende bronnen in je analyse vermengt!
Elke rol heeft zijn eigen set virtuele warehouses; selecteer het juiste warehouse dat je de benodigde rekenresources geeft. Simpele dingen hebben misschien genoeg aan X-Small, maar grotere taken hebben Large of zelfs X-Large nodig.
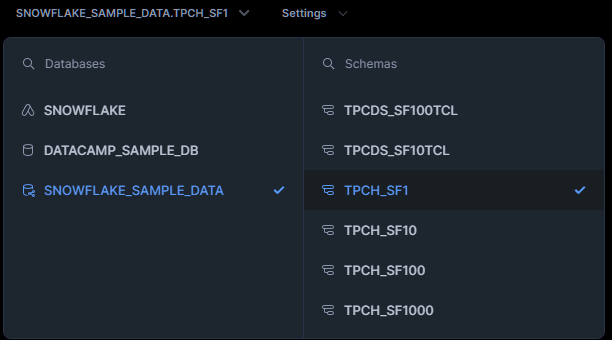
Kies daarna je database en schema en draai SQL zoals normaal. De database is de hoofdopslageenheid, waar de schema’s je verzamelingen van tabellen zijn.
Als dat eenmaal is ingesteld, kun je SQL-query’s zoals gebruikelijk uitvoeren. Een voorbeeldquery kan er als volgt uitzien:
use schema snowflake_sample_data.tpch_sf1;
-- or tpch_sf100, tpch_sf1000
SELECT
l_returnflag,
l_linestatus,
sum(l_quantity) as sum_qty,
sum(l_extendedprice) as sum_base_price,
sum(l_extendedprice * (1-l_discount))
as sum_disc_price,
sum(l_extendedprice * (1-l_discount) *
(1+l_tax)) as sum_charge,
avg(l_quantity) as avg_qty,
avg(l_extendedprice) as avg_price,
avg(l_discount) as avg_disc,
count(*) as count_order
FROM
lineitem
WHERE
l_shipdate <= dateadd(day, -90, to_date('1998-12-01'))
GROUP BY
l_returnflag,
l_linestatus
ORDER BY
l_returnflag,
l_linestatus;Wil je meer inzicht in Snowflake en leren hoe je de interface onder de knie krijgt, bekijk dan dit artikel over How to Learn Snowflake. Wil je meer SQL leren, bekijk dan de talrijke SQL-cursussen op Datacamp.
Conclusie
Snowflake is veel meer dan een cloud datawarehouse. Het is een krachtig platform dat datawarehousing, lakes, sharing, AI en ontwikkeltools samenbrengt in één ervaring. Voor beginners is het een van de eenvoudigste, meest schaalbare manieren om te starten in de wereld van data. Met de SQL-vriendelijke interface, ontwikkelopties zoals Snowpark en AI-mogelijkheden via Cortex stelt Snowflake individuen en organisaties in staat meer uit hun data te halen. Voor meer informatie over Snowflake, bekijk de volgende bronnen:
