Snowflake là một nền tảng dữ liệu trên đám mây đã cách mạng hóa việc lưu trữ và phân tích dữ liệu. Trong khi hầu hết các nền tảng đám mây thực hiện tính toán phân tích và các tác vụ liên quan đến lưu trữ như chuyển dữ liệu trên cùng một tài nguyên, kiến trúc độc đáo của Snowflake tách rời tải tính toán khỏi tải lưu trữ. Khi khối lượng dữ liệu tăng lên, khả năng của Snowflake trong việc thích ứng với nhu cầu của tổ chức ngày càng trở nên quan trọng trong nền kinh tế dữ liệu hiện đại.
Bài viết này giới thiệu Snowflake từ những khái niệm cơ bản nhất. Bạn không cần có kinh nghiệm trước về cơ sở dữ liệu hay điện toán đám mây để theo dõi. Chúng tôi sẽ giải thích Snowflake là gì, điều gì khiến nó khác biệt, cách nó được sử dụng và cách bạn có thể bắt đầu ngay hôm nay. Nếu bạn muốn cách tiếp cận thực hành hơn, hãy xem lộ trình kỹ năng Snowflake Foundations.
Snowflake là gì?
Các cơ sở dữ liệu on-premises truyền thống có toàn bộ không gian lưu trữ, sức mạnh tính toán và thiết bị mạng tại trụ sở công ty (on-prem).
Snowflake là một nền tảng dữ liệu thuần đám mây cho phép doanh nghiệp lưu trữ, quản lý, phân tích và chia sẻ dữ liệu ở quy mô lớn. Snowflake hoạt động hoàn toàn trên đám mây và cung cấp các công cụ mạnh mẽ cho kho dữ liệu, data lake, business intelligence và machine learning, tất cả trên một nền tảng.
Ngoài ra, nó giúp việc chia sẻ dữ liệu giữa các nhóm trở nên đơn giản. Kỹ sư dữ liệu và nhà phân tích dữ liệu thường dùng một ngôn ngữ lập trình gọi là SQL để lần lượt thực hiện chuyển đổi và phân tích dữ liệu. Vì Snowflake chạy trên SQL, hai nhóm này có thể trao đổi nhu cầu dữ liệu với nhau dễ dàng hơn.
Snowflake cũng tích hợp rất tốt với các nhà cung cấp đám mây khác và thường được lựa chọn nhờ kiến trúc độc đáo hỗ trợ hiệu quả xử lý dữ liệu.
Tích hợp đám mây
Bản thân Snowflake là một môi trường data cloud hoàn chỉnh, tuy nhiên điều đó không có nghĩa người dùng bị khóa hoàn toàn trong hệ sinh thái của nó. Nó tích hợp với ba nền tảng đám mây lớn:
- Amazon Web Services (AWS)
- Microsoft Azure
- Google Cloud Platform (GCP)
Những tích hợp này cho phép người dùng Snowflake dễ dàng chia sẻ dữ liệu từ Snowflake sang nền tảng đám mây hiện có của họ và ngược lại. Điều này mang đến sự linh hoạt để triển khai Snowflake trong môi trường đám mây mà tổ chức đang dùng với tối thiểu công sức phát triển.
Kiến trúc độc đáo
Snowflake có ba lớp chính: lớp dịch vụ, lớp tính toán và lớp lưu trữ. Lớp dịch vụ là dùng chung, lưu trữ tất cả các chức năng đám mây như bảo mật, truy cập và hạ tầng. Điều khiến Snowflake thật gọn gàng là cách nó tách biệt lớp tính toán và lớp lưu trữ.
Phần lớn thời gian, tài nguyên tính toán như CPU và bộ nhớ được dùng chung cho cả tính toán và lưu trữ dữ liệu. Việc Snowflake tách rời hai phần này mang lại vài lợi ích hay ho giúp dễ mở rộng và hiệu quả hơn. Nó làm được điều đó nhờ khái niệm “virtual warehouse”, nơi mỗi người dùng Snowflake có bộ tài nguyên ảo riêng không chia sẻ với người khác.
Chẳng hạn, việc chia sẻ dữ liệu trở nên dễ dàng vì bạn có thể dành nhiều tài nguyên hơn cho việc chuyển và sao chép dữ liệu tới người dùng. Thay vì mọi người trong công ty đều truy xuất từ một bản dữ liệu, Snowflake tạo các bản sao tạm thời cho từng người.
Tương tự, khi bạn không còn phải tiêu tốn tài nguyên quý giá cho lưu trữ và sao chép dữ liệu, bạn sẽ có nhiều CPU hơn cho phân tích và xử lý dữ liệu. Điều này có nghĩa các truy vấn SQL và pipeline phân tích của bạn chạy nhanh hơn miễn là virtual warehouse đủ lớn để xử lý khối tính toán.
Tóm tắt các lợi ích:
- Lưu trữ: Dữ liệu của bạn nằm trong một kho trung tâm. Mọi thứ truy cập dữ liệu như phân vùng hay lập chỉ mục dữ liệu được thực hiện bởi các tác vụ chuyên xử lý dữ liệu lưu trữ. Snowflake sau đó chia sẻ những phần dữ liệu cần thiết cho phiên làm việc của người dùng.
- Tính toán: Các tác vụ tính toán được thực hiện bởi virtual warehouse, về cơ bản là cụm tài nguyên tính toán (CPU và bộ nhớ) xử lý các nhiệm vụ như SQL phân tích, nạp/xuất dữ liệu, v.v.
Kiến trúc của Snowflake mang lại một số lợi thế then chốt nhờ tách biệt lưu trữ khỏi tài nguyên tính toán:
- Khả năng mở rộng: Dễ dàng mở rộng sức mạnh tính toán và lưu trữ một cách độc lập. Cần thêm lưu trữ? Bổ sung mà không tốn thêm chi phí CPU. Cần thêm sức mạnh xử lý? Mở rộng virtual warehouse mà không ảnh hưởng đến lưu trữ dữ liệu.
- Tính đồng thời: Nhiều người dùng và tác vụ chạy đồng thời mà không tranh chấp tài nguyên, đảm bảo hiệu năng ổn định cho tất cả.
- Hiệu quả chi phí: Chỉ trả tiền cho những gì bạn dùng. Nhanh chóng tăng/giảm tài nguyên theo nhu cầu, giảm chi phí không cần thiết.
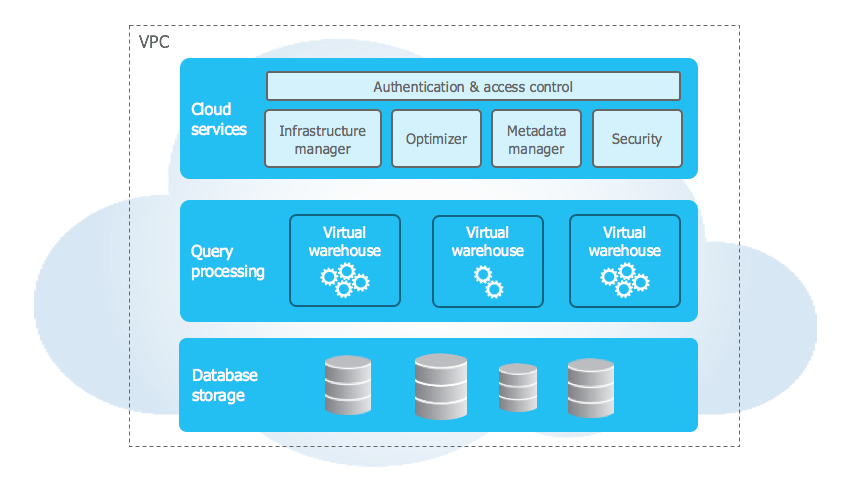
Kiến trúc Snowflake (docs.snowflake.com)
Để tìm hiểu sâu, hãy xem bài viết về kiến trúc của Snowflake.
Các tính năng chính của Snowflake
Snowflake là một nền tảng dữ liệu thuần đám mây, được quản lý hoàn toàn, được xây dựng để đáp ứng nhu cầu của các đội dữ liệu hiện đại. Như chúng ta đã thấy, nó mang lại khả năng mở rộng, hiệu năng và bảo mật tuyệt vời. Nó cũng khá dễ dùng với hỗ trợ SQL và giao diện thân thiện.
Khả năng mở rộng
Khả năng mở rộng đề cập đến mức độ một hệ thống có thể phát triển và xử lý nhiều dữ liệu hoặc nhiều người dùng hơn mà không giảm hiệu năng. Snowflake vượt trội ở điểm này nhờ kiến trúc tách rời lưu trữ và tính toán. Nếu tôi cần nhiều sức mạnh tính toán hơn, tôi có thể tăng kích thước virtual warehouse. Nếu cần thêm lưu trữ, tôi chỉ việc xin thêm dung lượng.
Trong các hệ thống truyền thống, mở rộng thường đồng nghĩa với downtime hoặc cấu hình lại phần cứng. Nếu muốn thêm tính toán hay lưu trữ, đó có thể là quá trình dài dằng dặc tháo phần cứng cũ, sao chép dữ liệu hoặc phần mềm sang phần cứng mới. Với Snowflake, chỉ cần một cú nhấp (hoặc lệnh) là xong.
Ví dụ:
- Một startup nhỏ có thể bắt đầu với warehouse X-Small cho truy vấn nhẹ và báo cáo thỉnh thoảng.
- Khi dữ liệu tăng, họ có thể nâng cấp lên Large hoặc X-Large mà không cần di chuyển dữ liệu. Các dịch vụ dữ liệu truyền thống có thể yêu cầu bạn chuyển dữ liệu sang kho vật lý lớn hơn trước khi có thể truy cập sức mạnh tính toán lớn hơn.
- Đối với mức độ đồng thời cao (nhiều người dùng truy cập cùng lúc), Snowflake hỗ trợ multi-cluster warehouse, tự động khởi tạo thêm cụm để xử lý tải.
Snowflake cũng tự động mở rộng cụm tính toán lên/xuống dựa trên nhu cầu công việc. Điều này đảm bảo:
- Hiệu năng truy vấn nhanh trong giờ cao điểm.
- Tiết kiệm chi phí trong thời gian nhàn rỗi (tài nguyên tính toán tự động tạm dừng).
Hiệu năng
Snowflake được tối ưu cho khối lượng công việc dữ liệu nặng, mang lại tốc độ ổn định dù chạy phân tích phức tạp, tải dữ liệu theo lô hay dashboard thời gian thực. Các công nghệ chủ chốt thúc đẩy hiệu năng cao gồm:
- Lưu trữ dạng cột: Dữ liệu lưu theo cột thay vì theo hàng giúp tăng tốc truy vấn phân tích bằng cách chỉ truy cập nhanh phần dữ liệu cần thiết.
- Tối ưu truy vấn tự động: Snowflake tự phân tích và tối ưu truy vấn, càng dùng nhiều càng cải thiện hiệu năng.
- Bộ nhớ đệm kết quả: Các truy vấn thường chạy được phục vụ ngay từ kết quả đã đệm, giảm thời gian tính toán và chi phí.
- Quản lý metadata: Theo dõi thông minh thống kê dữ liệu và mẫu truy vấn đảm bảo thực thi truy vấn hiệu quả.
Bảo mật
Snowflake ưu tiên bảo mật cấp doanh nghiệp với các biện pháp mạnh mẽ nhằm bảo vệ dữ liệu của bạn:
- Mã hóa end-to-end: Mã hóa AES-256 bảo vệ dữ liệu cả khi lưu trữ và khi truyền tải.
- Kiểm soát truy cập dựa trên vai trò (RBAC): Quản lý truy cập chi tiết đảm bảo người dùng chỉ thấy những gì cần, giảm thiểu rủi ro.
- Xác thực đa yếu tố: Thêm một lớp bảo mật khi truy cập Snowflake.
- Che giấu dữ liệu và bảo mật ở cấp hàng: Các điều khiển chi tiết giới hạn khả năng xem dữ liệu nhạy cảm theo vai trò.
- Chứng chỉ tuân thủ: Đáp ứng các tiêu chuẩn ngành như HIPAA và GDPR.
- Time Travel và Fail-safe: Khôi phục dữ liệu lịch sử và khôi phục bản ghi đã xóa lên đến 90 ngày, bảo vệ khỏi lỗi hoặc hành vi độc hại.
Dễ sử dụng
Snowflake được đánh giá cao nhờ thiết kế thân thiện với người dùng, đặc biệt hữu ích cho người mới nhưng rành SQL. Các tính năng dễ dùng chính gồm:
- Giao diện web: Giao diện trực quan giúp điều hướng cơ sở dữ liệu, viết truy vấn và quản lý người dùng trở nên đơn giản.
- Tương thích SQL tiêu chuẩn: Không cần ngôn ngữ mới. Snowflake hỗ trợ các câu lệnh SQL quen thuộc ngay từ đầu.
- Không cần quản trị hạ tầng: Được quản lý hoàn toàn, tự động mở rộng và tối ưu hóa, loại bỏ việc thiết lập hay bảo trì hạ tầng.
- Tích hợp rộng rãi công cụ: Kết nối mượt mà với công cụ phân tích (PowerBI, Tableau), dịch vụ ETL (Fivetran) và ngôn ngữ (Python, Java).
- Chợ dữ liệu: Dễ dàng khám phá và đăng ký bộ dữ liệu bên thứ ba mà không cần di chuyển dữ liệu, tăng cường khả năng phân tích.
Snowflake hướng tới việc giúp mọi quá trình chuyển đổi từ dịch vụ hay nền tảng khác trở nên đơn giản nhất có thể. Đây là một phiên code-along tuyệt vời để tìm hiểu thêm về việc Snowflake có thể được dùng cho phân tích dữ liệu với các ngôn ngữ như Python và SQL dễ dàng thế nào.
| Tính năng | Mô tả | Lợi ích/ Ví dụ chính |
|---|---|---|
| Khả năng mở rộng | Dễ dàng mở rộng sức mạnh tính toán và lưu trữ một cách độc lập. |
|
| Hiệu năng | Tối ưu cho phân tích nhanh và xử lý khối lượng công việc ổn định. |
|
| Bảo mật | Bảo mật cấp doanh nghiệp vững chắc bảo vệ tính toàn vẹn dữ liệu. |
|
| Dễ sử dụng | Giao diện thân thiện và tương thích SQL quen thuộc. |
|
Snowflake được dùng để làm gì?
Snowflake có nhiều mục đích sử dụng, từ kho dữ liệu đến phân tích thời gian thực. Chúng ta sẽ đề cập các chức năng cơ bản của Snowflake trong phần này.
Kho dữ liệu (Data warehousing)
Kho dữ liệu về bản chất là một trung tâm lưu trữ dữ liệu có cấu trúc thu thập từ nhiều nguồn. Snowflake phổ biến vì nó xử lý tự động mọi phức tạp kỹ thuật. Bạn không cần lo bảo trì máy chủ hay tối ưu lưu trữ thủ công, Snowflake xử lý giúp bạn.
- Tự động mở rộng nghĩa là kho của bạn phóng to/thu nhỏ theo nhu cầu.
- Hầu như không tốn công cho hạ tầng—chỉ tập trung phân tích dữ liệu của bạn.
- Hiệu năng truy vấn nhanh mà không cần kỹ năng chuyên biệt.
Data lake
Data lake lưu trữ dữ liệu thô, chưa xử lý, có thể là có cấu trúc (như bảng tính), bán cấu trúc (như email hoặc tệp JSON) hoặc phi cấu trúc (âm thanh, video). Truyền thống, tạo data lake đòi hỏi nhiều thiết lập ban đầu, nhưng Snowflake đơn giản hóa nhờ hỗ trợ nguyên bản các định dạng đa dạng như JSON, Parquet, ORC, Avro và XML.
- Không cần xử lý bên ngoài hay thiết lập phức tạp.
- Kết hợp sự linh hoạt của data lake với sự tiện lợi của kho dữ liệu, tạo nên cái thường gọi là "lakehouse".
Chia sẻ dữ liệu
Chia sẻ dữ liệu giữa các nhóm hoặc thậm chí giữa các tổ chức thường liên quan đến nhiều công đoạn sao chép và xuất dữ liệu. Snowflake khiến quá trình này trở nên nhẹ nhàng—bạn giữ dữ liệu trong môi trường của mình và chỉ cần cấp quyền truy cập thời gian thực cho bên khác.
- Chia sẻ dữ liệu tức thời và an toàn.
- Hợp tác đơn giản không cần chuyển tệp.
Phân tích thời gian thực
Phân tích thời gian thực là khả năng xử lý và phân tích dữ liệu ngay khi nó đến, thay vì chờ các đợt tải theo lô định kỳ. Snowflake cho phép điều này bằng cách hỗ trợ nạp dữ liệu độ trễ thấp và các pipeline streaming. Snowflake cung cấp nhiều công cụ hỗ trợ phân tích thời gian thực:
- Snowpipe: Dịch vụ nạp dữ liệu serverless tự động tải tệp ngay khi chúng xuất hiện trong lưu trữ đám mây (ví dụ: S3, Azure Blob).
- Snowpipe Streaming: Khả năng mới cho phép ứng dụng đẩy dữ liệu theo từng hàng vào Snowflake qua SDK với độ trễ dưới một giây.
- Streams và Tasks: Tính năng nguyên bản để theo dõi thay đổi và tự động hóa chuyển đổi
Tìm hiểu thêm về các pipeline dữ liệu khác nhau trong Snowflake giúp phân tích thời gian thực trở nên đơn giản với hướng dẫn cho người mới bắt đầu về xây dựng pipeline trong Snowflake.
Khám phá hệ sinh thái của Snowflake
Vượt ra ngoài việc cung cấp các công cụ pipeline dữ liệu mạnh mẽ, Snowflake còn có cả một hệ sinh thái phân tích. Nó cung cấp các giải pháp AI và ML đồng thời cho phép nhà phát triển viết bằng ngôn ngữ lập trình quen thuộc để tạo các chuyển đổi dữ liệu.
Snowflake Cortex: Tích hợp AI và ML
Snowflake Cortex là lớp trí tuệ nhân tạo và machine learning (AI/ML) tích hợp sẵn của Snowflake. Nó cho phép các nhóm xây dựng, chạy và mở rộng AI sinh sinh, mô hình dự đoán và trải nghiệm ngôn ngữ tự nhiên trực tiếp tại nơi dữ liệu đang nằm mà không cần di chuyển dữ liệu sang các nền tảng AI bên ngoài.
Snowflake cung cấp các hàm AI dùng ngay với SQL đơn giản, chẳng hạn khả năng dùng LLM (như Deepseek hoặc Llama của Facebook) để tóm tắt, dịch và hiểu đánh giá của khách hàng. Cortex Analyst cho phép người dùng dùng ngôn ngữ tự nhiên để truy vấn dữ liệu, rất hữu ích cho người ít thiên về SQL. Bạn có thể đơn giản hỏi Snowflake những câu như “Doanh số quý trước như thế nào?” và Snowflake sẽ truy vấn dữ liệu giúp bạn.
Snowflake cũng cung cấp ML Studio với các lựa chọn no/low-code tuyệt vời để thử nghiệm và đánh giá mô hình machine learning trên dữ liệu Snowflake trực tiếp. Để thực hành với Snowflake Cortex AI, hãy làm theo hướng dẫn này về xử lý văn bản trong Snowflake.
Snowpark: Trao quyền cho nhà phát triển
Snowpark là một framework cho nhà phát triển cho phép bạn xây dựng và chạy logic dữ liệu phức tạp bằng các ngôn ngữ lập trình quen thuộc như Python, Java hoặc Scala, ngay bên trong môi trường Snowflake.
Truyền thống, kỹ sư dữ liệu phải trích xuất dữ liệu khỏi kho để xử lý ở nơi khác. Snowpark đảo ngược mô hình này bằng cách đưa logic đến gần dữ liệu, cải thiện hiệu năng, bảo mật và hiệu quả chi phí.
Giờ đây, bạn có thể xử lý trong cơ sở dữ liệu, nơi Python hoặc Java của bạn chạy nguyên bản trong Snowflake mà không cần phiên Spark riêng. Thành viên nhóm có thể dùng SQL hoặc Python trên cùng một nền tảng và cộng tác trên cùng dữ liệu. Thêm nữa, thay vì dùng connector để kéo dữ liệu về môi trường lập trình cục bộ, mọi thứ chạy trong Snowflake, giảm rủi ro lộ dữ liệu.
Để biết thêm về việc chạy các ngôn ngữ lập trình trong Snowflake, bạn nên tìm hiểu thêm về Snowpark trong giới thiệu về Snowflake Snowpark.
Snowflake trên AWS
Snowflake được xây dựng từ đầu để chạy trên đám mây, với triển khai đầu tiên và trưởng thành nhất trên AWS. Nhờ sự tích hợp sớm và sâu này, Snowflake tương tác chặt chẽ với các dịch vụ trọng yếu của AWS, cho phép người dùng xây dựng pipeline dữ liệu an toàn, có khả năng mở rộng và tự động hóa cao bằng các công cụ và hạ tầng AWS quen thuộc.
Nếu tổ chức của bạn đã dùng AWS, triển khai Snowflake trên AWS giúp việc di chuyển, xử lý và phân tích dữ liệu trở nên dễ dàng hơn rất nhiều. Có nhiều dịch vụ hoạt động liền mạch với Snowflake.
Các dịch vụ AWS chính hoạt động với Snowflake
1. Amazon S3 (Simple Storage Service)
S3 là hệ thống lưu trữ đám mây của AWS, được dùng rộng rãi để lưu các tệp dữ liệu như log, CSV, JSON, Parquet, v.v. Đây là bài viết nói chi tiết hơn về Amazon S3. Snowflake tích hợp sẵn với S3 và cho phép bạn:
- Nạp dữ liệu từ S3: Bạn có thể dùng
COPY INTOhoặc Snowpipe để tải dữ liệu có cấu trúc hoặc bán cấu trúc từ bucket S3 vào bảng Snowflake. - Ghi dữ liệu ra S3: Snowflake cũng cho phép bạn xuất hoặc stage dữ liệu lên S3 để chia sẻ, sao lưu hoặc xử lý tiếp.
- Truy cập không sao chép (qua bảng ngoài): Snowflake có thể truy vấn trực tiếp dữ liệu trong S3 mà không cần sao chép trước, sử dụng external table—tiết kiệm thời gian và chi phí lưu trữ.
2. AWS PrivateLink
AWS PrivateLink là tính năng mạng tạo kết nối riêng tư, an toàn, băng thông cao giữa AWS VPC của bạn và Snowflake.
Nếu không có PrivateLink, lưu lượng giữa hệ thống AWS của bạn và Snowflake thường đi qua internet công cộng. Nó đảm bảo đáp ứng nghiêm ngặt nhu cầu tuân thủ hoặc độ trễ với các đặc điểm sau:
- Dữ liệu của bạn ở trong ranh giới mạng AWS của bạn.
- Bạn loại bỏ việc phơi bày lên internet công cộng.
- Giúp đáp ứng yêu cầu bảo mật và quy định, đặc biệt trong tài chính, y tế hoặc khu vực công.
3. AWS Lambda, SNS và S3 Event Notifications
Snowflake hỗ trợ kiến trúc hướng sự kiện thông qua nạp dữ liệu tự động kích hoạt bởi các dịch vụ AWS. Cách chúng hoạt động cùng nhau như sau:
- S3 Event Notifications: Mỗi khi một tệp được tải lên bucket S3, AWS có thể gửi thông báo.
- SNS (Simple Notification Service): Những thông báo này có thể kích hoạt thông điệp tới các dịch vụ hay hệ thống AWS khác.
- AWS Lambda: Đây là hàm serverless chạy script khi có sự kiện. Bạn có thể dùng nó để gọi Snowpipe, bộ nạp dữ liệu liên tục của Snowflake.
Quy trình này loại bỏ nhu cầu lập lịch tải dữ liệu thủ công và cho phép pipeline nạp gần thời gian thực, lý tưởng cho phân tích log, dữ liệu cảm biến hoặc telemetry ứng dụng.
Để tìm hiểu thêm về những điểm tinh tế trong hạ tầng AWS của Amazon, hãy xem các hướng dẫn về AWS Lambda, AWS SNS và S3 EFS.
Tôi cũng rất khuyến nghị khóa học về công nghệ và dịch vụ đám mây AWS để hiểu sâu cách các thành phần này vận hành.
Bắt đầu với Snowflake
Đây sẽ là phần tổng quan rất ngắn về vài bước cơ bản để bắt đầu với Snowflake. Để tìm hiểu thêm về các tính năng thiết yếu của Snowflake, hãy học khóa học Giới thiệu về Snowflake bao quát các kiến thức cơ bản dùng Snowflake để nạp và khám phá dữ liệu.
Truy cập Snowflake
Bước đầu tiên là có quyền truy cập. Snowflake (tại thời điểm viết vào tháng 5/2025) cung cấp bản dùng thử tặng tín dụng để sử dụng các tính năng của Snowflake. Bắt đầu rất đơn giản:
- Đăng ký tại signup.snowflake.com
- Chọn nhà cung cấp đám mây (AWS, Azure, GCP)
- Đăng nhập vào giao diện Snowflake
Nạp dữ liệu
Bạn có thể nạp dữ liệu vào Snowflake theo vài cách. Bạn có thể kéo-thả tệp được hỗ trợ (parquet, JSON, csv, v.v.) trong UI để được xử lý thành một bảng trong cơ sở dữ liệu và schema bạn chọn, dùng SQL, hoặc dùng chương trình bên thứ ba.
Một cách phổ biến là kết nối Snowflake của bạn với hệ thống lưu trữ đám mây như S3 của Amazon và dùng lệnh SQL như COPY INTO để chuyển dữ liệu từ lưu trữ đám mây sang cơ sở dữ liệu Snowflake của bạn.
Cuối cùng, bạn cũng có thể dùng công cụ ETL bên thứ ba như Fivetran và Matillion để xử lý dữ liệu trước khi đưa vào Snowflake. Các công cụ này giúp làm sạch dữ liệu trước khi tải vào Snowflake. Để biết chi tiết về việc đưa dữ liệu vào Snowflake, hãy xem hướng dẫn về Snowflake Data Ingestion.
Chạy truy vấn
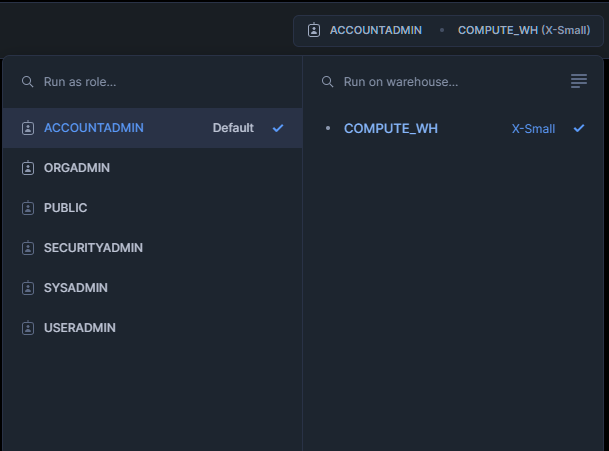
Snowflake giúp bạn chạy truy vấn dễ dàng trong UI. Trước tiên, bạn đăng nhập vào tài khoản Snowflake rồi mở worksheet. Điều quan trọng nhất là Snowflake cần bạn chọn một vai trò tài khoản cụ thể và virtual warehouse. Đây là một phần trong kiến trúc của Snowflake tách biệt quyền truy cập lưu trữ và tài nguyên tính toán.
Nếu bạn, hoặc người quản trị Snowflake của bạn, đã cấp cho bạn các vai trò tài khoản khác nhau, thì mỗi vai trò có thể có mức truy cập khác nhau. Có thể một vai trò dành cho dữ liệu production trực tiếp và một vai trò dành cho thử nghiệm. Điều này ngăn bạn vô tình trộn dữ liệu từ các nguồn khác nhau trong phân tích!
Mỗi vai trò sẽ có bộ virtual warehouse riêng, hãy chọn warehouse phù hợp với tài nguyên tính toán bạn cần. Có thể tác vụ đơn giản chỉ cần X-Small, nhưng tác vụ lớn hơn cần Large hoặc thậm chí X-Large.
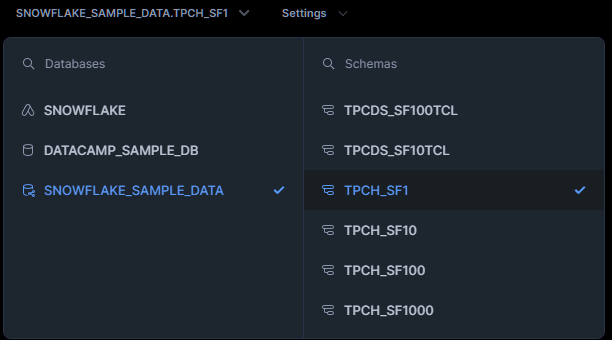
Sau đó, bạn chọn cơ sở dữ liệu và schema rồi chạy SQL như bình thường. Cơ sở dữ liệu là đơn vị lưu trữ chính, còn schema là tập hợp các bảng.
Khi đã thiết lập xong, bạn có thể chạy truy vấn SQL như bình thường. Ví dụ, một truy vấn có thể như sau:
use schema snowflake_sample_data.tpch_sf1;
-- or tpch_sf100, tpch_sf1000
SELECT
l_returnflag,
l_linestatus,
sum(l_quantity) as sum_qty,
sum(l_extendedprice) as sum_base_price,
sum(l_extendedprice * (1-l_discount))
as sum_disc_price,
sum(l_extendedprice * (1-l_discount) *
(1+l_tax)) as sum_charge,
avg(l_quantity) as avg_qty,
avg(l_extendedprice) as avg_price,
avg(l_discount) as avg_disc,
count(*) as count_order
FROM
lineitem
WHERE
l_shipdate <= dateadd(day, -90, to_date('1998-12-01'))
GROUP BY
l_returnflag,
l_linestatus
ORDER BY
l_returnflag,
l_linestatus;Để hiểu thêm về Snowflake và học cách làm chủ giao diện của nó, hãy xem bài viết Cách học Snowflake. Nếu bạn muốn học thêm SQL, hãy xem nhiều khóa học SQL trên Datacamp.
Kết luận
Snowflake không chỉ là một kho dữ liệu đám mây. Đó là một nền tảng mạnh mẽ kết hợp kho dữ liệu, data lake, chia sẻ dữ liệu, AI và công cụ cho nhà phát triển trong một trải nghiệm duy nhất. Đối với người mới bắt đầu, đây là một trong những cách dễ dàng và có khả năng mở rộng nhất để bước vào thế giới dữ liệu. Với giao diện thân thiện SQL, các lựa chọn cho nhà phát triển như Snowpark, và khả năng AI qua Cortex, Snowflake giúp cá nhân và tổ chức khai thác dữ liệu hiệu quả hơn. Để biết thêm về Snowflake, hãy xem các tài nguyên sau: