Snowflake est une plateforme de données basée sur le cloud qui a révolutionné le stockage et l'analyse des données. Alors que la plupart des plateformes cloud effectuent le calcul analytique et les tâches liées au stockage, comme le transfert de données, sur les mêmes ressources, l'architecture unique de Snowflake sépare la charge de calcul de la charge de stockage. Avec un volume de données croissant, la capacité de Snowflake à s'adapter aux besoins de l'organisation devient de plus en plus vitale dans l'économie moderne des données.
Cet article vous présente Snowflake sous toutes ses coutures. Vous n'avez pas besoin d'expérience préalable avec les bases de données ou le cloud computing pour suivre. Nous vous expliquerons ce qu'est Snowflake, ce qui le rend différent, comment il est utilisé et comment vous pouvez commencer dès aujourd'hui. Si vous êtes à la recherche d'une approche plus pratique, consultez notre piste de compétences cursus de compétences "Snowflake Foundations.
Qu'est-ce que le Snowflake ?
Les bases de données traditionnelles sur site disposent d'un espace de stockage, d'une puissance de calcul et d'un équipement de réseau dans les locaux de l'entreprise (sur site).
Snowflake est une plateforme de données cloud-native qui permet aux entreprises de stocker, gérer, analyser et partager des données à l'échelle. Snowflake vit entièrement dans le cloud et fournit des outils puissants pour l'entreposage de données, les lacs de données, la veille stratégique et l'apprentissage automatique, le tout sur une seule plateforme.
En outre, il facilite le partage des données entre les différentes équipes. Les ingénieurs et les analystes de données utilisent souvent un langage de programmation connu sous le nom de SQL pour effectuer respectivement la transformation et l'analyse des données. Comme Snowflake fonctionne sur SQL, ces deux groupes peuvent communiquer plus facilement sur leurs besoins en données.
Il dispose d'une excellente intégration avec d'autres fournisseurs de cloud et est souvent choisi pour son architecture unique qui contribue à l'efficacité du traitement des données.
Intégration dans le cloud
Snowflake est un environnement complet de nuage de données, mais cela ne signifie pas que les utilisateurs sont entièrement liés à son écosystème. Il s'intègre aux trois principales plateformes cloud :
- Amazon Web Services (AWS)
- Microsoft Azure
- Google Cloud Platform (GCP)
Ces intégrations permettent aux utilisateurs de Snowflake de partager facilement des données de Snowflake vers leur plateforme cloud existante et vice-versa. Les entreprises ont ainsi la possibilité de déployer Snowflake dans l'environnement cloud qu'elles utilisent déjà avec un minimum de développement.
Une architecture unique
Snowflake comporte trois couches principales : une couche de services, une couche de calcul et une couche de stockage. La couche de service est commune, elle héberge toutes les fonctions du cloud comme la sécurité, l'accès et l'infrastructure. Ce qui rend Snowflake si intéressant, c'est la façon dont il sépare la couche de calcul et la couche de stockage.
La plupart du temps, les ressources informatiques telles que l'unité centrale et la mémoire sont partagées pour le calcul et le stockage des données. La séparation des deux par Snowflake offre quelques avantages intéressants qui facilitent la mise à l'échelle et la rendent plus efficace. Pour ce faire, il utilise le concept d'"entrepôts virtuels", où chaque personne utilisant Snowflake dispose de son propre ensemble de ressources virtuelles qui ne sont pas partagées avec d'autres.
Par exemple, le partage des données est facile puisque vous pouvez consacrer plus de ressources au transfert et à la copie des données vers les utilisateurs. Ainsi, au lieu que tous les membres de votre entreprise tirent des données d'une seule copie, Snowflake crée des copies temporaires pour chaque personne.
De même, maintenant que vous ne dépensez plus de précieuses ressources pour le stockage et la copie des données, vous avez accès à davantage d'unités centrales pour l'analyse et le traitement des données. Cela signifie que vos requêtes SQL et vos pipelines analytiques s'exécutent plus rapidement tant que votre entrepôt virtuel est suffisamment grand pour gérer les calculs.
Voici un résumé des avantages :
- Stockage: Vos données sont conservées dans un référentiel central. Tout ce qui a trait à l'accès aux données, comme le partitionnement ou l'indexation des données, est effectué par des travailleurs spécialisés dans les données stockées. Snowflake partage ensuite les composants des données qui sont nécessaires à la session de l'utilisateur.
- Calculer: Les tâches informatiques sont exécutées par des entrepôts virtuels, qui sont en fait des grappes de ressources informatiques (CPU et mémoire) qui gèrent des tâches analytiques SQL, le chargement/déchargement de données, etc.
L'architecture de Snowflake offre plusieurs avantages clés en séparant le stockage des ressources de calcul :
- Évolutivité: Faites évoluer facilement la puissance de calcul et le stockage de manière indépendante. Vous avez besoin de plus d'espace de stockage ? Ajoutez-le sans frais supplémentaires d'unité centrale. Vous avez besoin de plus de puissance de traitement ? Développez votre entrepôt virtuel sans affecter le stockage des données.
- Concurrence: Plusieurs utilisateurs et tâches s'exécutent simultanément sans se disputer les ressources, ce qui garantit des performances constantes pour tout le monde.
- Coût-efficacité: Ne payez que ce que vous utilisez. Augmentez ou réduisez rapidement les ressources en fonction de la demande, réduisant ainsi les coûts inutiles.
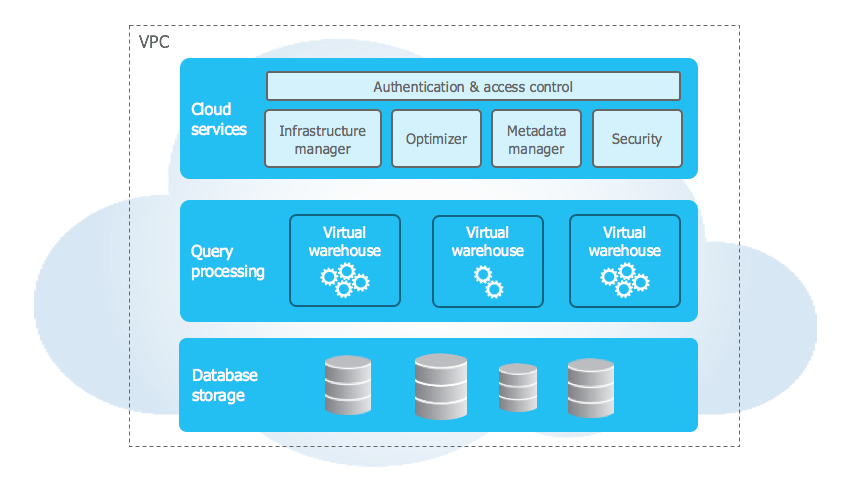
Snowflake Architecture (docs.snowflake.com)
Pour en savoir plus, consultez cet article sur l'architecture de l'architecture de Snowflake.
Caractéristiques principales de Snowflake
Snowflake est une plateforme de données cloud-native entièrement gérée, conçue pour répondre aux besoins des équipes de données modernes. Comme nous l'avons vu, il offre une grande évolutivité, de bonnes performances et une grande sécurité. Il s'agit également d'une plateforme assez facile à utiliser grâce à son support SQL et à son interface conviviale.
Évolutivité
L'évolutivité fait référence à la capacité d'un système à croître et à gérer davantage de données ou d'utilisateurs sans perdre en performance. Snowflake excelle ici en raison de son architecture séparée de stockage et de calcul. Si j'ai besoin de plus de puissance de calcul, je peux agrandir les entrepôts virtuels. Si j'ai besoin de plus d'espace de stockage, je n'ai qu'à demander plus d'espace de stockage.
Dans les systèmes traditionnels, la mise à l'échelle est souvent synonyme de temps d'arrêt ou de reconfiguration du matériel. Si je veux plus de capacité de calcul ou de stockage, le processus de démontage de l'ancien matériel et de copie des données ou des logiciels sur le nouveau matériel peut être long. Dans Snowflake, il suffit d'un clic (ou d'une commande) pour y parvenir.
Exemples:
- Une petite entreprise peut commencer avec un entrepôt X-Small pour des requêtes légères et des rapports occasionnels.
- Au fur et à mesure que les données augmentent, ils peuvent passer à un entrepôt Large ou X-Large, sans avoir à migrer les données. Les services de données traditionnels peuvent vous obliger à transférer ces données vers un entrepôt physique plus important avant de pouvoir accéder à une plus grande puissance de calcul.
- En cas de forte concurrence (de nombreux utilisateurs accédant au système en même temps), Snowflake prend en charge les entrepôts multi-clusters qui mettent automatiquement en route des clusters supplémentaires pour faire face à la charge.
Snowflake fait également évoluer automatiquement les clusters de calcul vers le haut ou vers le bas en fonction de la demande de la charge de travail. Cela permet de garantir :
- Des performances de requête rapides lors des pics d'utilisation.
- Réduction des coûts pendant les périodes d'inactivité (les ressources informatiques se mettent automatiquement en pause).
Performance
Snowflake est optimisé pour les charges de travail de données exigeantes, offrant une vitesse constante, qu'il s'agisse d'analyses complexes, de téléchargements par lots ou de tableaux de bord en direct. Les technologies clés qui permettent d'obtenir des performances élevées sont les suivantes
- Stockage en colonnes: Les données stockées en colonnes plutôt qu'en lignes accélèrent les requêtes analytiques en accédant rapidement aux seules données nécessaires.
- Optimisation automatique des requêtes: Snowflake analyse et optimise automatiquement les requêtes, améliorant ainsi les performances au fur et à mesure que vous l'utilisez.
- Mise en cache des résultats: Les requêtes fréquentes sont instantanément servies à partir des résultats mis en cache, ce qui réduit à la fois le temps de calcul et le coût.
- Gestion des métadonnées: Le cursus intelligent des statistiques de données et des schémas de requête garantit une exécution efficace des requêtes.
Sécurité
Snowflake donne la priorité à la sécurité au niveau de l'entreprise avec des mesures robustes conçues pour protéger vos données :
- Cryptage de bout en boutn : Le cryptage AES-256 protège les données au repos et en transit.
- Contrôle d'accès basé sur les rôles (RBAC): La gestion granulaire des accès garantit que les utilisateurs ne voient que ce dont ils ont besoin, ce qui minimise les risques.
- Authentification multifactorielle : Ajoute une couche de sécurité supplémentaire pour l'accès à Snowflake.
- Masquage des données et sécurité au niveau des lignes : Des contrôles précis limitent la visibilité des données sensibles par rôle.
- Certifications de conformité: Répond aux normes industrielles telles que HIPAA et GDPR.
- Voyage dans le temps et sécurité intégrée: Récupérez les données historiques et restaurez les enregistrements supprimés jusqu'à 90 jours, en vous protégeant contre les erreurs ou les activités malveillantes.
Facilité d'utilisation
Snowflake est largement plébiscité pour sa conception conviviale, particulièrement bénéfique pour les débutants en SQL. Les principales caractéristiques d'utilisation sont les suivantes
- Interface basée sur le web: Une interface utilisateur intuitive simplifie la navigation dans la base de données, la rédaction des requêtes et la gestion des utilisateurs.
- Compatibilité SQL standard: Aucune nouvelle langue n'est nécessaire. Snowflake prend en charge les instructions SQL familières dès le départ.
- Gestion de l'infrastructure zéro: Entièrement géré, avec une mise à l'échelle et une optimisation automatiques qui éliminent la mise en place ou la maintenance de l'infrastructure.
- Large intégration des outils: Se connecte de manière transparente avec des outils d'analyse (PowerBI, Tableau), des services ETL (Fivetran) et des langages (Python, Java).
- Place de marché des données: Explorez et abonnez-vous facilement à des ensembles de données de tiers sans déplacer les données, ce qui améliore les capacités d'analyse.
Snowflake vise à rendre toute transition depuis un autre service ou une autre plateforme aussi simple que possible. Voici une excellente session de code-along pour en savoir plus sur la facilité avec laquelle Snowflake peut être utilisé pour l'analyse de données avec des langages comme Python et SQL.
| Fonctionnalité | Description | Principaux avantages/exemples |
|---|---|---|
| Évolutivité | La puissance de calcul et le stockage évoluent facilement et de manière indépendante. |
|
| Performance | Optimisé pour une analyse rapide et une gestion fiable de la charge de travail. |
|
| Sécurité | Sécurité robuste de niveau entreprise protégeant l'intégrité des données. |
|
| Facilité d'utilisation | Interface conviviale et compatibilité avec le langage SQL. |
|
À quoi sert Snowflake ?
Snowflake a une grande variété d'utilisations, allant de l'entrepôt de données à l'analyse en temps réel. Dans cette section, nous aborderons les principes fondamentaux de la fonction de Snowflake.
Entrepôt de données
Un entrepôt de données est essentiellement un centre de données structurées collectées à partir de diverses sources. Snowflake est populaire parce qu'il gère automatiquement toutes les complexités techniques. Vous n'avez pas à vous soucier de la maintenance des serveurs ou de l'optimisation manuelle de votre stockage, Snowflake s'en charge pour vous.
- La mise à l'échelle automatique signifie que votre entrepôt s'agrandit ou se rétrécit en fonction de la demande.
- Un effort minimal sur l'infrastructure - concentrez-vous sur l'analyse de vos données.
- Des requêtes rapides sans avoir besoin de compétences spécialisées.
Lacs de données
Les lacs de données stockent des données brutes, non traitées, qui peuvent être structurées (comme des feuilles de calcul), semi-structurées (comme des courriels ou des fichiers JSON) ou non structurées (audio ou vidéo). Traditionnellement, la création d'un lac de données nécessitait beaucoup de configuration initiale, mais Snowflake simplifie cela en gérant nativement divers formats de données tels que JSON, Parquet, ORC, Avro et XML.
- Pas de traitement externe ni de configuration compliquée.
- Combine la flexibilité des lacs de données avec la commodité des entrepôts de données, créant ainsi ce que l'on appelle souvent une "maison de lac".
Partage des données
Le partage de données entre des équipes ou même des organisations différentes implique généralement beaucoup de copies et d'exportations. Snowflake facilite ce processus : vous conservez vos données dans votre propre environnement et accordez simplement à d'autres un accès en temps réel.
- Partage instantané et sécurisé des données.
- Collaboration simplifiée sans transfert de fichiers.
Analyse en temps réel
L'analyse en temps réel fait référence à la capacité de traiter et d'analyser les données au fur et à mesure qu'elles arrivent, au lieu d'attendre des chargements périodiques par lots. Snowflake permet cela en prenant en charge l'ingestion de données à faible latence et les pipelines de streaming. Snowflake offre une variété d'outils qui supportent l'analyse en temps réel :
- Snowpipe: Un service d'ingestion sans serveur qui charge automatiquement les fichiers à mesure qu'ils arrivent dans le stockage cloud (par exemple, S3, Azure Blob).
- Snowpipe Streaming: Une capacité plus récente qui permet aux applications de pousser des données ligne par ligne dans Snowflake via des SDK avec une latence inférieure à la seconde.
- Flux et tâches: Fonctionnalités natives pour le suivi des modifications et l'automatisation des transformations.
Découvrez les différents pipelines de données de Snowflake qui simplifient l'analyse en temps réel grâce à ce guide du débutant sur la création de pipelines dans Snowflake.
Explorer l'écosystème de Snowflake
Au-delà de la simple mise à disposition de puissants outils de pipeline de données, Snowflake dispose d'un écosystème analytique complet. Elle offre des solutions d'IA et de ML tout en permettant aux développeurs d'écrire dans leur langage de programmation natif pour créer des transformations de données.
Cortex du Snowflake : Intégrer l'IA et la ML
Snowflake Cortex est la couche intégrée d'intelligence artificielle et d'apprentissage automatique (AI/ML) de Snowflake. Il permet aux équipes de construire, d'exécuter et de mettre à l'échelle l'IA générative, les modèles prédictifs et les expériences de langage naturel directement là où se trouvent leurs données, sans avoir besoin de déplacer les données vers des plateformes d'IA externes.
Snowflake propose des fonctions d'IA prêtes à l'emploi que vous pouvez exécuter avec du simple SQL, comme la possibilité d'utiliser des LLM (comme Deepseek ou Llama de Facebook) pour résumer, traduire et comprendre les avis des clients. Cortex Analyst permet aux utilisateurs d'utiliser le langage naturel pour interroger les données, ce qui est très utile pour les utilisateurs qui ne sont pas nécessairement orientés vers le langage SQL. Vous pouvez simplement poser à Snowflake des questions telles que "Quelles ont été les ventes au cours du dernier trimestre ?" et Snowflake interrogera les données pour vous.
Snowflake propose également un ML Studio qui offre d'excellentes options no/low-code pour tester et évaluer des modèles d'apprentissage automatique sur des données Snowflake en direct. Pour un guide pratique sur l'IA de Snowflake Cortex, suivez ce guide qui parle de le traitement de texte dans Snowflake.
Snowpark : Responsabiliser les développeurs
Snowpark est un cadre de développement qui vous permet de construire et d'exécuter une logique de données complexe en utilisant des langages de programmation familiers, tels que Python, Java ou Scala, directement dans l'environnement Snowflake.
Traditionnellement, les ingénieurs de données devaient extraire les données des entrepôts pour les traiter ailleurs. Snowpark renverse ce modèle en amenant la logique aux données, améliorant ainsi les performances, la sécurité et la rentabilité.
Désormais, vous pouvez avoir un traitement dans la base de données où votre Python ou Java s'exécute nativement dans Snowflake sans avoir besoin d'une session Spark séparée. Les membres de l'équipe peuvent utiliser SQL ou Python sur la même plateforme et collaborer sur les mêmes données. En outre, au lieu d'utiliser des connecteurs pour apporter des données localement à ces environnements de programmation, tout s'exécute dans Snowflake, ce qui réduit le risque d'exposition des données.
Pour plus d'informations sur l'exécution de langages de programmation dans Snowflake, vous devriez en savoir plus sur Snowpark dans cette Introduction à Snowflake Snowpark.
Snowflake sur AWS
Snowflake a été conçu dès le départ pour fonctionner dans le cloud, avec son premier déploiement, le plus mature, sur AWS. Grâce à cette intégration précoce et approfondie, Snowflake présente une interopérabilité étroite avec les principaux services AWS, ce qui permet aux utilisateurs de créer des pipelines de données sécurisés, évolutifs et hautement automatisés à l'aide d'outils et d'infrastructures AWS familiers.
Si votre organisation utilise déjà AWS, le déploiement de Snowflake sur AWS facilite considérablement le déplacement, le traitement et l'analyse de vos données. De nombreux services fonctionnent sans interruption à Snowflake.
Principaux services AWS fonctionnant avec Snowflake
1. Amazon S3 (Simple Storage Service)
S3 est le système de stockage cloud d'AWS, largement utilisé pour stocker des fichiers de données tels que des journaux, des CSV, des JSON, des Parquet, etc. Voici un article qui en dit plus sur Amazon S3. Snowflake s'intègre à S3 dès le départ et vous permet de :
- Ingérer des données à partir de S3: Vous pouvez utiliser
COPY INTOou Snowpipe pour charger des données structurées ou semi-structurées depuis des buckets S3 dans des tableaux Snowflake. - Écriture de données dans S3: Snowflake vous permet également d'exporter ou de mettre en scène des données vers S3 à des fins de partage, de sauvegarde ou de traitement ultérieur.
- Accès en copie zéro (via des tableaux externes): Snowflake peut interroger les données directement dans S3 sans les copier au préalable, en utilisant des tableaux externes, ce qui permet de gagner du temps et de réduire les coûts de stockage.
2. AWS PrivateLink
AWS PrivateLink est une fonctionnalité de mise en réseau qui crée des connexions privées, sécurisées et à large bande passante entre votre cloud privé virtuel (VPC) AWS et Snowflake.
Sans PrivateLink, le trafic entre vos systèmes AWS et Snowflake passerait généralement par l'internet public. Il garantit une conformité stricte ou des besoins en matière de latence grâce aux caractéristiques suivantes :
- Vos données restent dans les limites de votre réseau AWS.
- Vous éliminez l'exposition à l'internet public.
- Il permet de répondre aux exigences en matière de sécurité et de réglementation, en particulier dans les secteurs de la finance, de la santé ou de l'administration.
3. Notifications d'événements AWS Lambda, SNS et S3
Snowflake prend en charge l'architecture pilotée par les événements grâce à l'ingestion automatisée déclenchée par les services AWS. Voici comment ils fonctionnent ensemble :
- Notifications d'événements S3 : Chaque fois qu'un fichier est téléchargé dans un godet S3, AWS peut envoyer une notification.
- SNS (Simple Notification Service) : Ces notifications peuvent déclencher l'envoi de messages à d'autres services ou systèmes AWS.
- AWS Lambda : Il s'agit d'une fonction sans serveur qui exécute un script lorsqu'un événement se produit. Vous pouvez l'utiliser pour invoquer Snowpipe, le chargeur de données en continu de Snowflake.
Ce flux de travail supprime la nécessité de planifier manuellement les chargements de données et permet des pipelines d'ingestion en temps quasi réel, parfaits pour l'analyse des journaux, les données de capteurs ou la télémétrie des applications.
Pour en savoir plus sur les nuances de l'infrastructure AWS d'Amazon, consultez ces guides sur AWS Lambdasur AWS SNSet sur S3 EFS.
Je vous recommande également ce cours sur les concepts du cloud et des services AWS pour comprendre en profondeur le fonctionnement de tous ces composants.
Premiers pas avec Snowflake
Il s'agit d'un aperçu très bref de quelques étapes fondamentales pour démarrer avec Snowflake. Pour en savoir plus sur les fonctionnalités essentielles de Snowflake, suivez cette Introduction à Snowflake qui couvre les bases de l'utilisation de Snowflake pour le chargement et l'exploration des données.
Accéder à Snowflake
La toute première étape consiste à obtenir un accès. Snowflake propose (au moment de la rédaction de ce document en mai 2025) une version d'essai qui donne des crédits pour utiliser les fonctionnalités de Snowflake. Pour commencer, rien de plus simple :
- Inscrivez-vous sur signup.snowflake.com
- Choisissez un fournisseur de cloud (AWS, Azure, GCP)
- Connectez-vous à l'interface utilisateur de Snowflake
Chargement des données
Vous pouvez charger des données dans Snowflake grâce à quelques options. Vous pouvez glisser-déposer un type de fichier pris en charge (parquet, JSON, csv, etc.) dans l'interface utilisateur, qui sera ensuite transformé en tableau dans la base de données et le schéma de votre choix, en utilisant SQL ou en faisant appel à des programmes tiers.
Une méthode courante consiste à connecter votre Snowflake à un système de stockage dans le cloud, comme S3 d'Amazon, et à utiliser des commandes SQL comme COPY INTO pour transférer les données de votre stockage dans le cloud vers votre base de données Snowflake.
Enfin, vous pouvez également utiliser des outils ETL tiers tels que Fivetran et Matillion pour traiter les données avant de les déposer dans Snowflake. Ces outils tiers vous aident à nettoyer vos données avant de les charger dans Snowflake. Pour plus de détails sur l'ingestion de données dans Snowflake, jetez un coup d'œil à ce guide sur l'ingestion de données dans Snowflake. L'ingestion de données dans Snowflake.
Requêtes en cours d'exécution
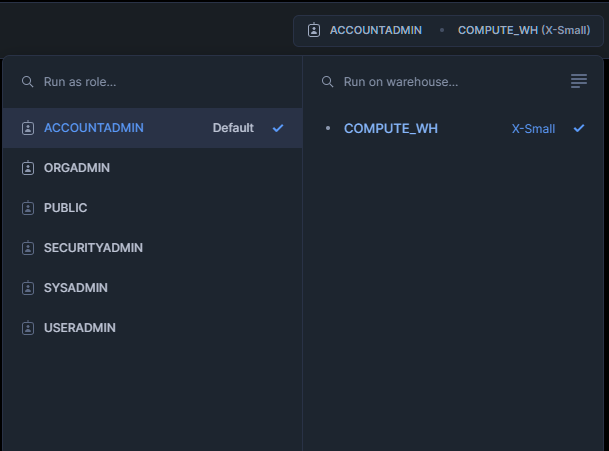
Snowflake facilite l'exécution de requêtes dans son interface utilisateur. Tout d'abord, vous vous connectez à votre compte Snowflake, puis vous ouvrez une feuille de travail. La chose la plus importante à comprendre est que Snowflake a besoin que vous sélectionniez un rôle de compte spécifique et des entrepôts virtuels. Cela fait partie de l'architecture de Snowflake qui sépare votre accès au stockage et les ressources de calcul.
Si vous, ou la personne qui gère votre Snowflake, vous avez attribué différents rôles de compte, chaque rôle peut avoir différents niveaux d'accès. Il se peut qu'un rôle soit conçu pour les données de production en direct et qu'un autre soit conçu pour les tests. Cela vous évite de mélanger accidentellement des données provenant de différentes sources dans votre analyse !
Chaque rôle dispose de son propre ensemble d'entrepôts virtuels. Sélectionnez l'entrepôt qui vous fournira les ressources informatiques dont vous avez besoin. Peut-être que les choses simples ne nécessitent que l'entrepôt X-Small, mais que les choses plus importantes nécessitent l'entrepôt Large ou même X-Large.
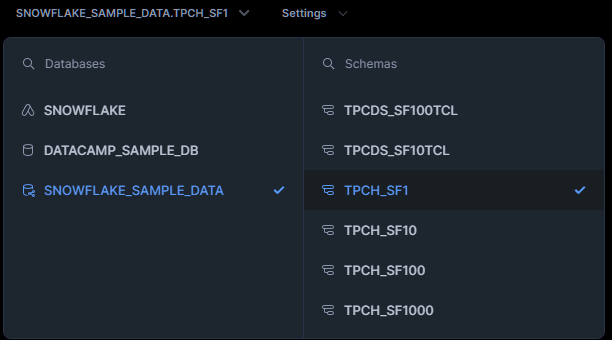
Ensuite, vous pouvez choisir votre base de données et votre schéma, puis exécuter SQL comme d'habitude. La base de données est l'unité de stockage principale où les schémas sont vos collections de tableaux.
Une fois que vous avez configuré cela, vous pouvez exécuter des requêtes SQL comme d'habitude. Par exemple, une requête peut ressembler à ce qui suit :
use schema snowflake_sample_data.tpch_sf1;
-- or tpch_sf100, tpch_sf1000
SELECT
l_returnflag,
l_linestatus,
sum(l_quantity) as sum_qty,
sum(l_extendedprice) as sum_base_price,
sum(l_extendedprice * (1-l_discount))
as sum_disc_price,
sum(l_extendedprice * (1-l_discount) *
(1+l_tax)) as sum_charge,
avg(l_quantity) as avg_qty,
avg(l_extendedprice) as avg_price,
avg(l_discount) as avg_disc,
count(*) as count_order
FROM
lineitem
WHERE
l_shipdate <= dateadd(day, -90, to_date('1998-12-01'))
GROUP BY
l_returnflag,
l_linestatus
ORDER BY
l_returnflag,
l_linestatus;Pour en savoir plus sur Snowflake et apprendre à maîtriser son interface, consultez l'article suivant Comment apprendre Snowflake. Si vous souhaitez apprendre plus de SQL, consultez les nombreux cours SQL sur DataCamp.
Conclusion
Snowflake est bien plus qu'un entrepôt de données en nuage. Il s'agit d'une plateforme puissante qui rassemble l'entreposage de données, les lacs, le partage, l'IA et les outils de développement en une seule expérience. Pour les débutants, c'est l'un des moyens les plus simples et les plus évolutifs de se lancer dans le monde des données. Avec son interface conviviale pour SQL, ses options pour les développeurs comme Snowpark et ses capacités d'IA grâce à Cortex, Snowflake permet aux individus et aux organisations d'en faire plus avec leurs données. Pour plus d'informations sur Snowflake, consultez les ressources suivantes :
