
Cursus
Deploying AI into Production with FastAPI
4 Hr
4.8K
Ben je gefascineerd door de transformerende kracht van Generative AI en LLM’s? Dan is deze tutorial perfect voor jou. We verkennen hier LangChain – een open-source Python-framework voor het bouwen van toepassingen op basis van Large Language Models zoals GPT.
Leer meer over het bouwen van AI-toepassingen met LangChain in onze Building Multimodal AI Applications with LangChain & the OpenAI API AI Code Along, waarin je ontdekt hoe je YouTube-video’s kunt transcriberen met de spraak-naar-tekst-AI Whisper en vervolgens GPT gebruikt om vragen over de inhoud te stellen.
Large Language Models (LLM’s) zijn geavanceerde AI-systemen die zijn ontworpen om mensachtige tekst te begrijpen en te genereren. Ze zijn getraind op enorme hoeveelheden data en kunnen daardoor complexe patronen herkennen, taalfinesses begrijpen en samenhangende antwoorden genereren. LLM’s kunnen allerlei taalgerelateerde taken uitvoeren, waaronder vertalen, tekstaanvulling, samenvatten en zelfs gesprekken voeren. GPT is een voorbeeld van een LLM.
Een LLM is een type Generative AI. Wil je meer leren over Generative AI en hoe het je creativiteit kan stimuleren? Lees dan onze blogs Using Generative AI to Boost Your Creativity en onze podcast Inside the Generative AI Revolution. Je kunt je ook inschrijven voor onze aankomende cursus Large Language Models Concepts.
LangChain is een open-source framework dat is ontworpen om de ontwikkeling van toepassingen op basis van large language models (LLM’s) te vereenvoudigen. Het biedt een set tools, componenten en interfaces die het bouwen van LLM-centrische apps makkelijker maken. Met LangChain beheer je moeiteloos interacties met taalmodellen, koppel je verschillende componenten naadloos aan elkaar en integreer je bronnen zoals API’s en databases. Je kunt meer lezen over LangChain For Data Engineering and Data Applications in een apart artikel.
Het LangChain-platform bevat een verzameling API’s die ontwikkelaars in hun applicaties kunnen inbedden, zodat ze taalverwerkingsmogelijkheden kunnen toevoegen zonder alles vanaf nul te bouwen. Zo vereenvoudigt LangChain het proces van het maken van LLM-gebaseerde toepassingen, geschikt voor ontwikkelaars van alle niveaus.
Toepassingen zoals chatbots, virtual assistants, vertaalsystemen en sentimentanalyse-tools zijn allemaal voorbeelden van LLM-gedreven apps. Ontwikkelaars gebruiken LangChain om op maat gemaakte toepassingen op basis van taalmodellen te bouwen die aan specifieke behoeften voldoen.
Met de voortdurende vooruitgang en bredere adoptie van natural language processing worden de toepassingsmogelijkheden van deze technologie vrijwel onbeperkt. Enkele opvallende kenmerken van LangChain zijn:
1. Aanpasbare prompts die aansluiten op jouw specifieke wensen
2. Het bouwen van ketencomponenten voor geavanceerde gebruiksscenario’s
3. Integratie van modellen voor data-augmentatie en toegang tot toonaangevende taalmodellen, zoals GPT en HuggingFace Hub
4. Veelzijdige componenten die je kunt mixen en matchen voor specifieke behoeften
5. Context sturen en vormgeven voor meer nauwkeurigheid en betere gebruikerservaring
LangChain installeren in Python is vrij eenvoudig. Je kunt het installeren met pip of conda.
pip install langchainInstalleren met conda
install langchain -c conda-forgeDit installeert de basisbenodigdheden van LangChain. Veel van de kracht van LangChain komt tot zijn recht wanneer het geïntegreerd wordt met diverse modelproviders, datastores en dergelijke.
Standaard worden de dependencies die hiervoor nodig zijn NIET meegeïnstalleerd. Om alle dependencies te installeren, kun je de volgende opdracht uitvoeren:
pip install langchain[all]De laatste optie is om de bibliotheek vanuit de bron te bouwen. In dat geval kun je het project klonen vanuit de GitHub-repo.
Het gebruik van LangChain vereist doorgaans integraties met verschillende modelproviders, datastores, API’s en vergelijkbare componenten. Zoals bij elke integratie moeten we de juiste API-sleutels aanleveren om LangChain te laten werken. Dat kan op twee manieren:
1. De sleutel instellen als omgevingsvariabele
OPENAI_API_KEY="..."Als je liever geen omgevingsvariabele instelt, kun je de sleutel direct meegeven via de parameter openai_api_key bij het initialiseren van de OpenAI LLM-klasse:
2. De sleutel direct instellen in de betreffende klasse
from langchain.llms import OpenAI
llm = OpenAI(openai_api_key="...")LangChain valt op door z’n focus op flexibiliteit en modulariteit. Het splitst de natural language processing-pijplijn op in losse componenten, waardoor ontwikkelaars workflows kunnen afstemmen op hun behoeften. Deze aanpasbaarheid maakt LangChain ideaal voor het bouwen van AI-toepassingen in uiteenlopende scenario’s en sectoren.
In LangChain zijn componenten modules die specifieke functies vervullen in de taalverwerkingspijplijn. Deze componenten kun je koppelen tot "chains" voor op maat gemaakte workflows, zoals een klantenservice-chatbotketen met modules voor sentimentanalyse, intentieherkenning en antwoordgeneratie.
Prompttemplates zijn herbruikbare, vooraf gedefinieerde prompts die je ketenbreed kunt inzetten. Deze templates kunnen dynamisch en aanpasbaar worden door specifieke "waarden" in te vullen. Zo kan een prompt die om de naam van een gebruiker vraagt, worden gepersonaliseerd door een concrete waarde in te voegen. Dit is handig voor het genereren van prompts op basis van dynamische bronnen.
Deze worden gebruikt om informatie op te slaan en te doorzoeken via embeddings: numerieke representaties van documentbetekenissen. VectorStore fungeert als opslag voor deze embeddings, zodat je efficiënt kunt zoeken op basis van semantische gelijkenis.
Indexen werken als databases die details en metadata over de trainingsdata van het model opslaan, terwijl retrievers snel in deze index naar specifieke informatie zoeken. Dit verbetert de antwoorden van het model door context en gerelateerde informatie te bieden.
Outputparsers worden gebruikt om de door het model gegenereerde antwoorden te beheren en te verfijnen. Ze kunnen ongewenste inhoud verwijderen, het uitvoerformaat aanpassen of extra data toevoegen. Zo helpen outputparsers om gestructureerde resultaten, zoals JSON-objecten, uit de antwoorden van het taalmodel te halen.
Voorbeeldselectors in LangChain helpen geschikte voorbeelden uit de trainingsdata van het model te kiezen, wat de precisie en relevantie van de gegenereerde antwoorden verbetert. Je kunt deze selectors instellen om bepaalde typen voorbeelden te bevoordelen of irrelevante te filteren, zodat de AI-respons is afgestemd op de gebruikersinput.
Agents zijn unieke LangChain-instanties, elk met specifieke prompts, geheugen en een chain voor een bepaald gebruiksscenario. Ze kunnen worden ingezet op verschillende platforms, waaronder web, mobiel en chatbots, zodat je een breed publiek kunt bedienen.
LangChain biedt een LLM-klasse voor interfaces met verschillende taalmodelproviders, zoals OpenAI, Cohere en Hugging Face. De meest basale functionaliteit van een LLM is het genereren van tekst. Het is heel eenvoudig om met LangChain een app te bouwen die een tekstprompt neemt en de output retourneert.
API_KEY ="..."
from langchain.llms import OpenAI
llm = OpenAI(model_name="text-ada-001", openai_api_key=API_KEY)
print(llm("Tell me a joke about data scientist"))Output:
>>> "What do you get when you tinker with data? A data scientist!"
In het bovenstaande voorbeeld gebruiken we het text-ada-001-model van OpenAI. Wil je dit omruilen voor een open-sourcemodel van HuggingFace? Dat is een kleine aanpassing:
API_KEY ="..."
from langchain import HuggingFaceHub
llm = HuggingFaceHub(repo_id = "google/flan-t5-xl", huggingfacehub_api_token = API_KEY)
print(llm("Tell me a joke about data scientist"))Je kunt de token-id voor Hugging Face Hub uit je HF-account halen.
Als je meerdere prompts hebt, kun je met de methode generate in één keer een lijst met prompts versturen:
llm_response = llm.generate(['Tell me a joke about data scientist',
'Tell me a joke about recruiter',
'Tell me a joke about psychologist'])Output:
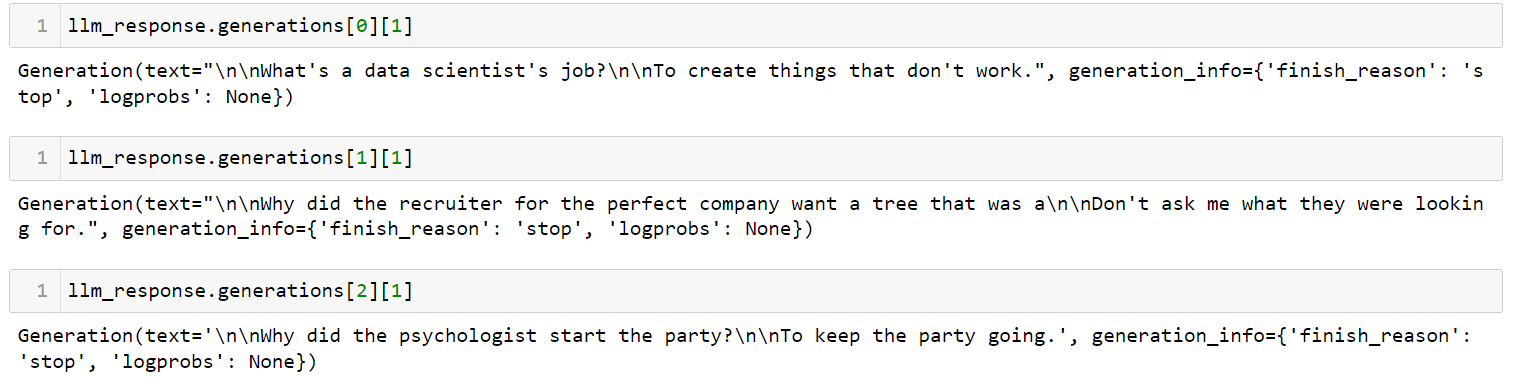
Dit is de eenvoudigste app die je met LangChain kunt maken. Hij neemt een prompt, stuurt die naar een taalmodel naar keuze en geeft het antwoord terug. Er zijn veel parameters die je kunt instellen, zoals `temperature`. De temperatuur bepaalt de mate van willekeur in de output en staat standaard op 0,7.
LLM’s hebben specifieke API’s. Hoewel het logisch lijkt om prompts in natuurlijke taal in te voeren, moet je de prompt vaak toch bijstellen om de gewenste output van een LLM te krijgen. Dit proces heet prompt engineering. Als je eenmaal een goede prompt hebt, wil je die misschien als template hergebruiken.
Een PromptTemplate in LangChain laat je via templating een prompt genereren. Dat is handig wanneer je dezelfde promptstructuur op meerdere plekken wilt gebruiken, maar met bepaalde waarden aangepast.
USER_INPUT = 'Paris'
from langchain.llms import OpenAI
from langchain import PromptTemplate
llm = OpenAI(model_name="text-davinci-003", openai_api_key=API_KEY)
template = """ I am travelling to {location}. What are the top 3 things I can do while I am there. Be very specific and respond as three bullet points """
prompt = PromptTemplate(
input_variables=["location"],
template=template,
)
final_prompt = prompt.format(location=USER_INPUT )
print(f"LLM Output: {llm(final_prompt)}")Output:
1. Climb the Eiffel Tower and take in the breathtaking views of the city
2. Enjoy a romantic cruise along the River Seine and admire the beautiful architecture along the riverbanks
3. Explore the Louvre and admire the world-renowned works of art on display
Wil je deze prompt hergebruiken voor een andere stad? Dan hoef je alleen de variabele USER_INPUT te wijzigen. Ik heb hem nu veranderd van Paris naar Cancun, Mexico. Zie hoe de output mee verandert:
Output:
1. Relax on the Beach: Enjoy the white sand beaches and crystal-clear waters of the Caribbean Sea.
2. Explore the Mayan Ruins: Visit ancient archaeological sites such as Chichen Itza, Tulum, and Coba to learn about the history and culture of the Mayans.
3. Take a Food Tour: Taste the traditional flavors and learn about the local cuisine by taking a food tour of Cancun.
Chaining binnen de context van LangChain betekent het integreren van LLM’s met andere elementen om een applicatie te bouwen. Enkele voorbeelden zijn:
Laten we een voorbeeld bekijken van het eerste scenario, waarin we de output van de eerste LLM gebruiken als input voor de tweede LLM.
from langchain.llms import OpenAI
from langchain.chains import LLMChain, SimpleSequentialChain
from langchain import PromptTemplate
llm = OpenAI(model_name="text-davinci-003", openai_api_key=API_KEY)
# first step in chain
template = "What is the most popular city in {country} for tourists? Just return the name of the city"
first_prompt = PromptTemplate(
input_variables=["country"],
template=template)
chain_one = LLMChain(llm = llm, prompt = first_prompt)
# second step in chain
second_prompt = PromptTemplate(
input_variables=["city"],
template="What are the top three things to do in this: {city} for tourists. Just return the answer as three bullet points.",)
chain_two = LLMChain(llm=llm, prompt=second_prompt)
# Combine the first and the second chain
overall_chain = SimpleSequentialChain(chains=[chain_one, chain_two], verbose=True)
final_answer = overall_chain.run("Canada")Output:

In dit voorbeeld bouwen we een keten met twee componenten. De eerste component bepaalt de populairste stad die hoort bij een land dat de gebruiker invoert. De tweede component geeft vervolgens informatie over de drie beste activiteiten of bezienswaardigheden voor toeristen in die specifieke stad.
Wil je meer geavanceerde concepten leren over het bouwen van toepassingen in LangChain? Bekijk dan deze livecursus Building AI Applications with LangChain and GPT op DataCamp.
Nog niet zo lang geleden waren we allemaal onder de indruk van de capaciteiten van ChatGPT. Maar het landschap is snel veranderd: met nieuwe ontwikkeltools zoals LangChain kunnen we nu soortgelijke, indrukwekkende prototypes in slechts enkele uren op onze eigen laptops bouwen.
LangChain, een open-source Python-framework, stelt je in staat om toepassingen te maken die worden aangedreven door LLM’s (Language Model Models). Dit framework biedt een veelzijdige interface naar tal van basismodellen, faciliteert promptbeheer en fungeert als een centrale hub voor andere componenten zoals prompttemplates, extra LLM’s, externe data en andere tools via agents (op het moment van schrijven).
Wil je alle ontwikkelingen in Generative AI en LLM bijhouden? Bekijk dan ons webinar Building AI Applications with LangChain and GPT. Je leert er de basis van het gebruik van LangChain voor het ontwikkelen van AI-toepassingen, hoe je een AI-applicatie structureert en hoe je tekstdata embedt voor hoge prestaties. Bekijk ook onze cheatsheet over het generative AI tools-landschap om de verschillende categorieën, toepassingen en impact in diverse sectoren te verkennen. Tot slot kun je onze lijst met de top open-source LLM’s bekijken om andere krachtige tools te ontdekken.
Leer AI met deze cursussen!
Cursus
Cursus
Cursus
blog
Adel Nehme
15 min
