
Course
Deploying AI into Production with FastAPI
4 hr
4.5K
If you're captivated by the transformative powers of Generative AI and LLMs, this tutorial is perfect for you. Here, we explore LangChain - An open-source Python framework for building applications based on Large Language Models such as GPT.
Learn more about building AI applications with LangChain in our Building Multimodal AI Applications with LangChain & the OpenAI API AI Code Along where you'll discover how to transcribe YouTube video content with the Whisper speech-to-text AI and then use GPT to ask questions about the content.
Large Language Models (LLMs) refer to advanced artificial intelligence systems designed to understand and generate human-like text. These models are trained on vast amounts of data, enabling them to grasp complex patterns, comprehend language nuances, and generate coherent responses. LLMs have the capability to perform various language-related tasks, including language translation, text completion, summarization, and even engaging in conversational interactions. GPT is an example of LLM.
LLM is a type of Generative AI. If you would like to learn about Generative AI and how it can boost your creativity, check our blogs on Using Generative AI to Boost Your Creativity and our podcast, Inside the Generative AI Revolution. You can also register for our upcoming course on Large Language Models Concepts.
LangChain is an open-source framework designed to facilitate the development of applications powered by large language models (LLMs). It offers a suite of tools, components, and interfaces that simplify the construction of LLM-centric applications. With LangChain, it becomes effortless to manage interactions with language models, seamlessly link different components, and incorporate resources such as APIs and databases. You can read more about LangChain For Data Engineering and Data Applications in a separate article.
The LangChain platform comes with a collection of APIs that developers can embed in their applications, empowering them to infuse language processing capabilities without having to build everything from the ground up. Therefore, LangChain efficiently simplifies the process of crafting LLM-based applications, making it suitable for developers across the spectrum of expertise.
Applications like chatbots, virtual assistants, language translation utilities, and sentiment analysis tools are all instances of LLM-powered apps. Developers leverage LangChain to create bespoke language model-based applications that cater to specific needs.
With the continual advancements and broader adoption of natural language processing, the potential applications of this technology are expected to be virtually limitless. Here are several noteworthy characteristics of LangChain:
1. Tailorable prompts to meet your specific requirements
2. Constructing chain link components for advanced usage scenarios
3. Integrating models for data augmentation and accessing top-notch language model capabilities, such as GPT and HuggingFace Hub.
4. Versatile components that allow mixing and matching for specific needs
5. Manipulating context to establish and guide context for enhanced precision and user satisfaction
Installing LangChain in Python is pretty straightforward. You can either install it with pip or conda.
pip install langchainInstall using conda
install langchain -c conda-forgeThis will set up the basic necessities of LangChain. Much of LangChain's usefulness is realized when it's integrated with diverse model providers, data stores, and the like.
By default, the dependencies required for these integrations are NOT included in the installation. To install all dependencies, you can run the following command:
pip install langchain[all]The final option is to build the library from the source. In that case, you can clone the project from its GitHub repo.
Using LangChain usually requires integrations with various model providers, data stores, APIs, and similar components. As with any integration, we must provide appropriate and relevant API keys for LangChain to function. There are two ways to achieve this:
1. Setting up key as an environment variable
OPENAI_API_KEY="..."If you'd prefer not to set an environment variable, you can pass the key in directly via the openai_api_key named parameter when initiating the OpenAI LLM class:
2. Directly set up the key in the relevant class
from langchain.llms import OpenAI
llm = OpenAI(openai_api_key="...")LangChain stands out due to its emphasis on flexibility and modularity. It disassembles the natural language processing pipeline into separate components, enabling developers to tailor workflows according to their needs. This adaptability makes LangChain ideal for constructing AI applications across various scenarios and sectors.
In LangChain, components are modules performing specific functions in the language processing pipeline. These components can be linked into "chains" for tailored workflows, such as a customer service chatbot chain with sentiment analysis, intent recognition, and response generation modules.
Prompt templates are reusable predefined prompts across chains. These templates can become dynamic and adaptable by inserting specific "values." For example, a prompt asking for a user's name could be personalized by inserting a specific value. This feature is beneficial for generating prompts based on dynamic resources.
These are used to store and search information via embeddings, essentially analyzing numerical representations of document meanings. VectorStore serves as a storage facility for these embeddings, allowing efficient search based on semantic similarity.
Indexes act as databases storing details and metadata about the model's training data, while retrievers swiftly search this index for specific information. This improves the model's responses by providing context and related information.
Output parsers come into play to manage and refine the responses generated by the model. They can eliminate undesired content, tailor the output format, or supplement extra data to the response. Thus, output parsers help extract structured results, like JSON objects, from the language model's responses.
Example selectors in LangChain serve to identify appropriate instances from the model's training data, thus improving the precision and pertinence of the generated responses. These selectors can be adjusted to favor certain types of examples or filter out unrelated ones, providing a tailored AI response based on user input.
Agents are unique LangChain instances, each with specific prompts, memory, and chain for a particular use case. They can be deployed on various platforms, including web, mobile, and chatbots, catering to a wide audience.
LangChain provides an LLM class designed for interfacing with various language model providers, such as OpenAI, Cohere, and Hugging Face. The most basic functionality of an LLM is generating text. It is very straightforward to build an application with LangChain that takes a string prompt and returns the output.
API_KEY ="..."
from langchain.llms import OpenAI
llm = OpenAI(model_name="text-ada-001", openai_api_key=API_KEY)
print(llm("Tell me a joke about data scientist"))Output:
>>> "What do you get when you tinker with data? A data scientist!"
In the example above, we are using text-ada-001 model from OpenAI. If you would like to swap that for any open-source models from HuggingFace, it’s a simple change:
API_KEY ="..."
from langchain import HuggingFaceHub
llm = HuggingFaceHub(repo_id = "google/flan-t5-xl", huggingfacehub_api_token = API_KEY)
print(llm("Tell me a joke about data scientist"))You can get the Hugging Face hub token id from your HF account.
If you have multiple prompts, you can send a list of prompts at once using the generate method:
llm_response = llm.generate(['Tell me a joke about data scientist',
'Tell me a joke about recruiter',
'Tell me a joke about psychologist'])Output:
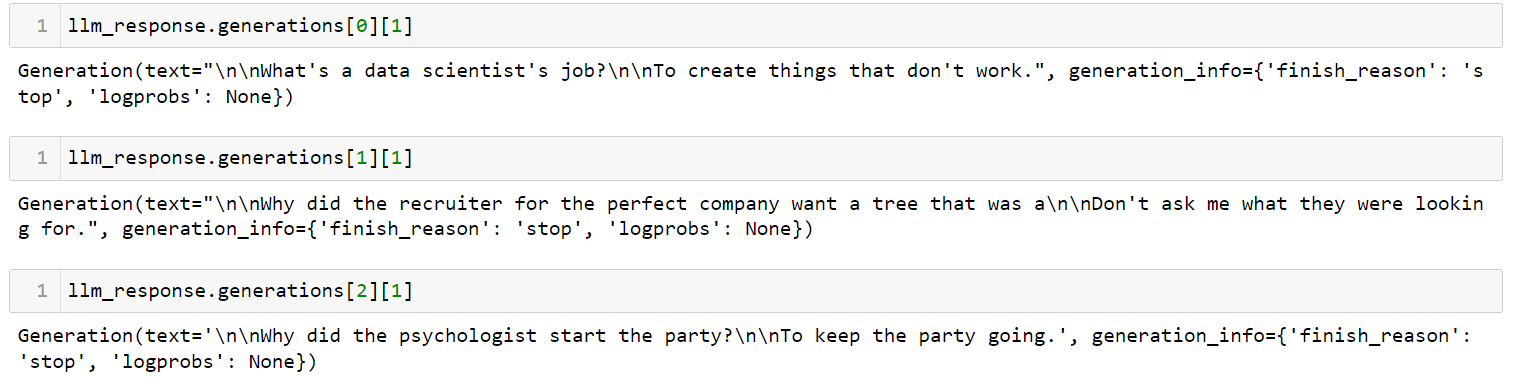
This is the simplest possible app you can create using LangChain. It takes a prompt, sends it to a language model of your choice, and returns the answer. There are many parameters that you can control, such as `temperature`. The temperature parameter adjusts the randomness of the output, and it is set to 0.7 by default.
LLMs have peculiar APIs. While it may seem intuitive to input prompts in natural language, it actually requires some adjustment of the prompt to achieve the desired output from an LLM. This adjustment process is known as prompt engineering. Once you have a good prompt, you may want to use it as a template for other purposes.
A PromptTemplate in LangChain allows you to use templating to generate a prompt. This is useful when you want to use the same prompt outline in multiple places but with certain values changed.
USER_INPUT = 'Paris'
from langchain.llms import OpenAI
from langchain import PromptTemplate
llm = OpenAI(model_name="text-davinci-003", openai_api_key=API_KEY)
template = """ I am travelling to {location}. What are the top 3 things I can do while I am there. Be very specific and respond as three bullet points """
prompt = PromptTemplate(
input_variables=["location"],
template=template,
)
final_prompt = prompt.format(location=USER_INPUT )
print(f"LLM Output: {llm(final_prompt)}")Output:
1. Climb the Eiffel Tower and take in the breathtaking views of the city
2. Enjoy a romantic cruise along the River Seine and admire the beautiful architecture along the riverbanks
3. Explore the Louvre and admire the world-renowned works of art on display
If you now want to re-use this prompt for a different city, you only have to change the USER_INPUT variable. I have now changed it from Paris to Cancun, Mexico. See how the output was changed:
Output:
1. Relax on the Beach: Enjoy the white sand beaches and crystal-clear waters of the Caribbean Sea.
2. Explore the Mayan Ruins: Visit ancient archaeological sites such as Chichen Itza, Tulum, and Coba to learn about the history and culture of the Mayans.
3. Take a Food Tour: Taste the traditional flavors and learn about the local cuisine by taking a food tour of Cancun.
Chaining within the LangChain context refers to the act of integrating LLMs with other elements to build an application. Several examples include:
Let’s see an example of the first scenario where we will use the output from the first LLM as an input to the second LLM.
from langchain.llms import OpenAI
from langchain.chains import LLMChain, SimpleSequentialChain
from langchain import PromptTemplate
llm = OpenAI(model_name="text-davinci-003", openai_api_key=API_KEY)
# first step in chain
template = "What is the most popular city in {country} for tourists? Just return the name of the city"
first_prompt = PromptTemplate(
input_variables=["country"],
template=template)
chain_one = LLMChain(llm = llm, prompt = first_prompt)
# second step in chain
second_prompt = PromptTemplate(
input_variables=["city"],
template="What are the top three things to do in this: {city} for tourists. Just return the answer as three bullet points.",)
chain_two = LLMChain(llm=llm, prompt=second_prompt)
# Combine the first and the second chain
overall_chain = SimpleSequentialChain(chains=[chain_one, chain_two], verbose=True)
final_answer = overall_chain.run("Canada")Output:

In this particular example, we create a chain with two components. The first component is responsible for identifying the most popular city corresponding to a particular country as input by the user. In contrast, the second component focuses on providing information about the top three activities or attractions available for tourists visiting that specific city.
If you would like to learn more advanced concepts of building applications in LangChain, check out this live course on Building AI Applications with LangChain and GPT on DataCamp.
Only a short while ago, we were all greatly impressed by the impressive capabilities of ChatGPT. However, the landscape has rapidly evolved, and now we have access to new developer tools like LangChain that empower us to create similarly remarkable prototypes on our personal laptops in just a matter of hours.
LangChain, an open-source Python framework, enables individuals to create applications powered by LLMs (Language Model Models). This framework offers a versatile interface to numerous foundational models, facilitating prompt management and serving as a central hub for other components such as prompt templates, additional LLMs, external data, and other tools through agents (at the time of writing).
If you are trying to keep up with all the advancements in Generative AI and LLM, check out our Building AI Applications with LangChain and GPT webinar. Here, you will learn the basics of using LangChain to develop AI applications, as well as how to structure an AI application and how to embed text data for high performance. You can also view our cheat sheet on the generative AI tools landscape to explore the different categories of generative AI tools, their applications, and their influence in various sectors. Finally, check out our list of the top open-source LLMs to learn about other powerful tools.
Learn AI with these courses!
Course
Course
Course
Tutorial
Richie Cotton
Tutorial
Bex Tuychiev
Tutorial
Bex Tuychiev
code-along
Emmanuel Pire
code-along
Richie Cotton
code-along
Korey Stegared-Pace




