
Curso
Conceitos de Grandes Modelos de Linguagem (LLMs)
2 h
99.8K
Para demonstrar melhor o que é o RAG e como a técnica funciona, vamos considerar um cenário que muitas empresas enfrentam atualmente.
Imagine que você é um executivo de uma empresa de eletrônicos que vende dispositivos como smartphones e laptops. Você deseja criar um chatbot de suporte ao cliente para a sua empresa para responder às consultas dos usuários relacionadas a especificações de produtos, solução de problemas, informações sobre garantia e muito mais.
Você gostaria de usar os recursos de LLMs como GPT-3 ou GPT-4 para alimentar seu chatbot.
No entanto, os grandes modelos de linguagem têm as seguintes limitações, o que leva a uma experiência ineficiente para o cliente:
Os modelos de linguagem estão limitados a fornecer respostas genéricas com base em seus dados de treinamento. Se os usuários fizerem perguntas específicas sobre o software que você vende ou se tiverem dúvidas sobre como solucionar problemas em profundidade, um LLM tradicional poderá não ser capaz de fornecer respostas precisas.
Isso ocorre porque eles não foram treinados em dados específicos da sua organização. Além disso, os dados de treinamento desses modelos têm uma data de corte, o que limita sua capacidade de fornecer respostas atualizadas.
Os LLMs podem "alucinar", o que significa que eles tendem a gerar respostas falsas com confiança com base em fatos imaginados. Esses algoritmos também podem fornecer respostas fora do tópico se não tiverem uma resposta precisa para a consulta do usuário, levando a uma experiência ruim para o cliente.
Os modelos de linguagem geralmente fornecem respostas genéricas que não são adaptadas a contextos específicos. Isso pode ser uma grande desvantagem em um cenário de suporte ao cliente, pois as preferências individuais do usuário geralmente são necessárias para facilitar uma experiência personalizada do cliente.
O RAG preenche essas lacunas de forma eficaz, oferecendo a você uma maneira de integrar a base de conhecimento geral dos LLMs com a capacidade de acessar informações específicas, como os dados presentes no banco de dados do seu produto e nos manuais do usuário. Essa metodologia permite obter respostas altamente precisas e confiáveis, adaptadas às necessidades da sua organização.
Agora que você entende o que é RAG, vamos examinar as etapas envolvidas na configuração dessa estrutura:
Primeiro, você deve reunir todos os dados necessários para o seu aplicativo. No caso de um chatbot de suporte ao cliente para uma empresa de eletrônicos, isso pode incluir manuais do usuário, um banco de dados de produtos e uma lista de perguntas frequentes.
A fragmentação de dados é o processo de dividir seus dados em partes menores e mais gerenciáveis. Por exemplo, se você tiver um longo manual do usuário de 100 páginas, poderá dividi-lo em diferentes seções, cada uma respondendo potencialmente a diferentes perguntas dos clientes.
Dessa forma, cada bloco de dados é focado em um tópico específico. Quando uma informação é recuperada do conjunto de dados de origem, é mais provável que ela seja diretamente aplicável à consulta do usuário, pois evitamos incluir informações irrelevantes de documentos inteiros.
Isso também aumenta a eficiência, pois o sistema pode obter rapidamente as informações mais relevantes em vez de processar documentos inteiros.
Agora que os dados de origem foram divididos em partes menores, eles precisam ser convertidos em uma representação vetorial. Isso envolve a transformação de dados de texto em embeddings, que são representações numéricas que capturam o significado semântico por trás do texto.
Em palavras simples, as incorporações de documentos permitem que o sistema entenda as consultas do usuário e as combine com informações relevantes no conjunto de dados de origem com base no significado do texto, em vez de uma simples comparação palavra a palavra. Esse método garante que as respostas sejam relevantes e alinhadas com a consulta do usuário.
Se você quiser saber mais sobre como os dados de texto são convertidos em representações vetoriais, recomendamos que explore nosso tutorial sobre incorporação de texto com a API OpenAI.
Quando uma consulta do usuário entra no sistema, ela também deve ser convertida em uma representação vetorial ou de incorporação. O mesmo modelo deve ser usado para a incorporação do documento e da consulta para garantir a uniformidade entre os dois.
Depois que a consulta é convertida em uma incorporação, o sistema compara a incorporação da consulta com as incorporações do documento. Ele identifica e recupera blocos cujas incorporações são mais semelhantes às incorporações da consulta, usando medidas como similaridade de cosseno e distância euclidiana.
Esses blocos são considerados os mais relevantes para a consulta do usuário.
Os blocos de texto recuperados, juntamente com a consulta inicial do usuário, são alimentados em um modelo de linguagem. O algoritmo usará essas informações para gerar uma resposta coerente às perguntas do usuário por meio de uma interface de bate-papo.
Aqui está um fluxograma simplificado que resume como o RAG funciona:
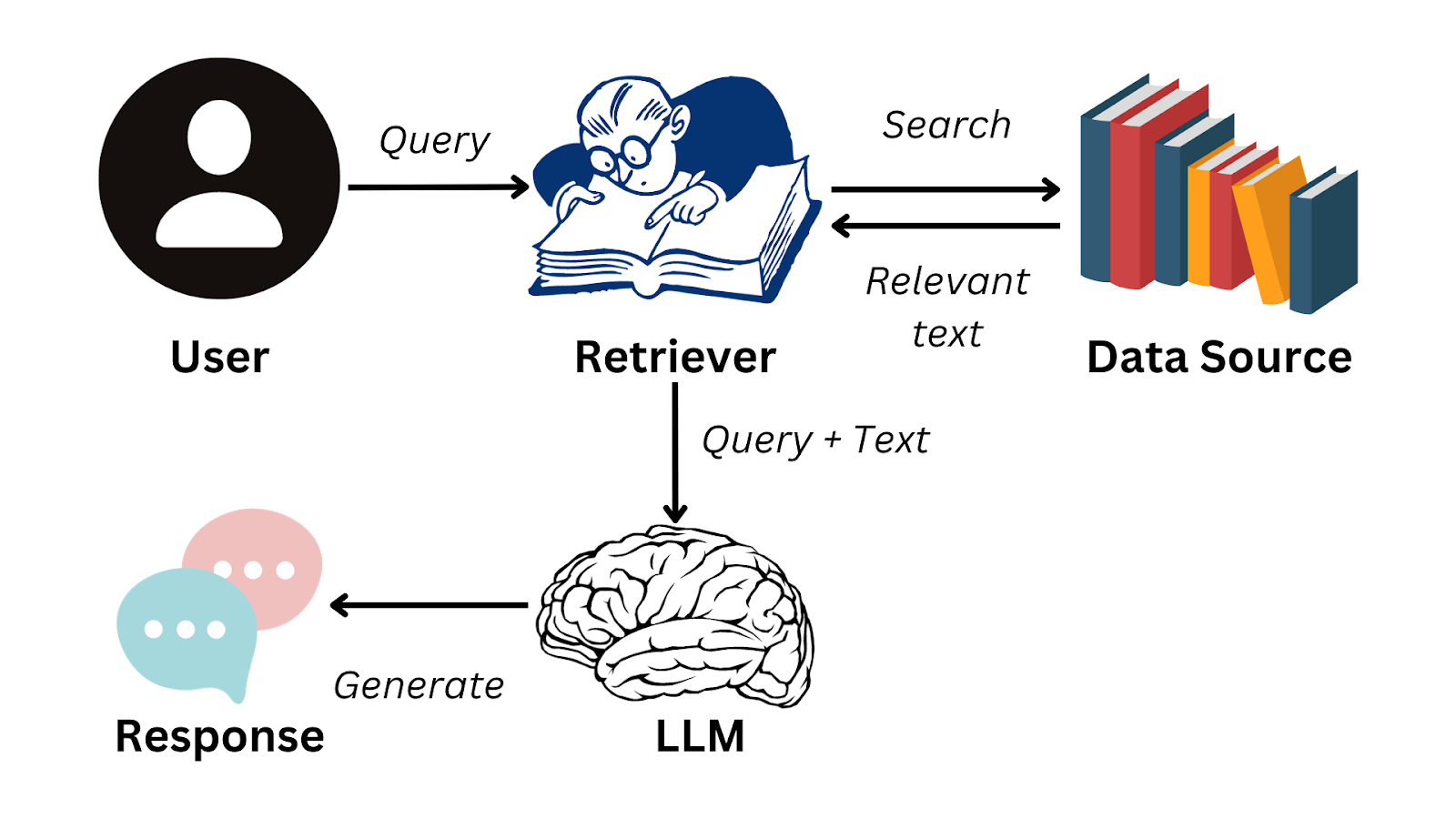
Imagem do autor
Para realizar com perfeição as etapas necessárias para gerar respostas com LLMs, você pode usar uma estrutura de dados como o LlamaIndex.
Essa solução permite que você desenvolva seus próprios aplicativos LLM, gerenciando com eficiência o fluxo de informações de fontes de dados externas para modelos de linguagem como o GPT-3. Para saber mais sobre essa estrutura e como você pode usá-la para criar aplicativos baseados em LLM, leia nosso tutorial sobre o LlamaIndex.
Agora sabemos que o RAG permite que os LLMs formem respostas coerentes com base em informações fora de seus dados de treinamento. Um sistema como esse tem uma variedade de casos de uso comercial que melhorarão a eficiência organizacional e a experiência do usuário. Além do exemplo do chatbot do cliente que vimos anteriormente no artigo, aqui estão algumas aplicações práticas do RAG:
O RAG pode usar conteúdo de fontes externas para produzir resumos precisos, o que resulta em uma economia de tempo considerável. Por exemplo, gerentes e executivos de alto nível são pessoas ocupadas que não têm tempo para examinar relatórios extensos.
Com um aplicativo com tecnologia RAG, eles podem acessar rapidamente as descobertas mais importantes dos dados de texto e tomar decisões com mais eficiência, em vez de ter que ler documentos extensos.
Os sistemas RAG podem ser usados para analisar dados de clientes, como compras anteriores e avaliações, para gerar recomendações de produtos. Isso aumentará a experiência geral do usuário e, por fim, gerará mais receita para a organização.
Por exemplo, os aplicativos RAG podem ser usados para recomendar melhores filmes em plataformas de streaming com base no histórico de visualização e nas classificações do usuário. Eles também podem ser usados para analisar avaliações escritas em plataformas de comércio eletrônico.
Como os LLMs são excelentes em compreender a semântica por trás dos dados de texto, os sistemas RAG podem oferecer aos usuários sugestões personalizadas com mais nuances do que as de um sistema de recomendação tradicional.
Normalmente, as organizações tomam decisões de negócios observando o comportamento da concorrência e analisando as tendências do mercado. Isso é feito por meio da análise meticulosa dos dados presentes em relatórios comerciais, demonstrações financeiras e documentos de pesquisa de mercado.
Com um aplicativo RAG, as organizações não precisam mais analisar e identificar manualmente as tendências nesses documentos. Em vez disso, um LLM pode ser empregado para obter com eficiência insights significativos e aprimorar o processo de pesquisa de mercado.
Embora os aplicativos RAG nos permitam preencher a lacuna entre a recuperação de informações e o processamento de linguagem natural, sua implementação apresenta alguns desafios exclusivos. Nesta seção, analisaremos as complexidades enfrentadas na criação de aplicativos RAG e discutiremos como elas podem ser atenuadas.
Pode ser difícil integrar um sistema de recuperação com um LLM. Essa complexidade aumenta quando há várias fontes de dados externos em formatos variados. Os dados que são alimentados em um sistema RAG devem ser consistentes, e as incorporações geradas precisam ser uniformes em todas as fontes de dados.
Para superar esse desafio, módulos separados podem ser projetados para lidar com diferentes fontes de dados de forma independente. Os dados de cada módulo podem então ser pré-processados para uniformidade, e um modelo padronizado pode ser usado para garantir que os embeddings tenham um formato consistente.
À medida que a quantidade de dados aumenta, fica mais difícil manter a eficiência do sistema RAG. Muitas operações complexas precisam ser realizadas, como a geração de embeddings, a comparação do significado entre diferentes partes do texto e a recuperação de dados em tempo real.
Essas tarefas são computacionalmente intensivas e podem tornar o sistema mais lento à medida que o tamanho dos dados de origem aumenta.
Para enfrentar esse desafio, você pode distribuir a carga computacional entre diferentes servidores e investir em uma infraestrutura de hardware robusta. Para melhorar o tempo de resposta, também pode ser útil armazenar em cache as consultas que são feitas com frequência.
A implementação de bancos de dados vetoriais também pode atenuar o desafio da escalabilidade nos sistemas RAG. Esses bancos de dados permitem que você manipule facilmente os embeddings e recupere rapidamente os vetores que estão mais alinhados com cada consulta.
Se quiser saber mais sobre a implementação de bancos de dados vetoriais em um aplicativo RAG, você pode assistir à nossa sessão de código ao vivo, intitulada Retrieval Augmented Generation with GPT and Milvus. Este tutorial oferece um guia passo a passo para você combinar o Milvus, um banco de dados vetorial de código aberto, com modelos GPT.
A eficácia de um sistema RAG depende muito da qualidade dos dados que estão sendo inseridos nele. Se o conteúdo de origem acessado pelo aplicativo for ruim, as respostas geradas serão imprecisas.
As organizações devem investir em um processo diligente de curadoria e ajuste de conteúdo. É necessário refinar as fontes de dados para melhorar sua qualidade. Para aplicativos comerciais, pode ser vantajoso envolver um especialista no assunto para revisar e preencher as lacunas de informações antes de usar o conjunto de dados em um sistema RAG.
Atualmente, o RAG é a técnica mais conhecida para aproveitar os recursos de linguagem dos LLMs juntamente com um banco de dados especializado. Esses sistemas abordam alguns dos desafios mais urgentes encontrados ao trabalhar com modelos de linguagem e apresentam uma solução inovadora no campo do processamento de linguagem natural.
No entanto, como qualquer outra tecnologia, os aplicativos RAG têm suas limitações, principalmente a dependência da qualidade dos dados de entrada. Para tirar o máximo proveito dos sistemas RAG, é fundamental incluir a supervisão humana no processo.
A curadoria meticulosa das fontes de dados, juntamente com o conhecimento especializado, é fundamental para garantir a confiabilidade dessas soluções.
Se quiser se aprofundar no mundo do RAG e entender como ele pode ser usado para criar aplicativos de IA eficazes, você pode assistir ao nosso treinamento ao vivo sobre a criação de aplicativos de IA com o LangChain. Este tutorial dará a você experiência prática com o LangChain, uma biblioteca projetada para permitir a implementação de sistemas RAG em cenários do mundo real.
Comece a trabalhar com LLMs hoje mesmo!
Curso
Curso
Curso
blog
Abid Ali Awan
11 min
blog
Hesam Sheikh Hassani
15 min
blog
Abid Ali Awan
4 min
blog
Abid Ali Awan
8 min
blog
Javier Canales Luna
8 min
Tutorial
Ryan Ong

