As incorporações de texto são uma ferramenta essencial no campo do processamento de linguagem natural (NLP). São representações numéricas de texto em que cada palavra ou frase é representada como um vetor denso de números reais.
A vantagem significativa dessas incorporações é sua capacidade de capturar significados semânticos e relações entre palavras ou frases, o que permite que as máquinas entendam e processem a linguagem humana de forma eficiente.
As incorporações de texto são cruciais em cenários como classificação de texto, recuperação de informações e detecção de similaridade semântica.
A OpenAI, conhecida por suas notáveis contribuições para o campo da inteligência artificial, recomenda atualmente o uso do modelo Ada V2 para a criação de embeddings de texto. Esse modelo é derivado da série de modelos GPT e foi treinado para capturar ainda melhor o significado contextual e as associações presentes no texto.
Se você não estiver familiarizado com a API da OpenAI ou com o pacote openai Python, recomendamos que leia Usando o GPT-3.5 e o GPT-4 por meio da API da OpenAI em Python antes de prosseguir. Este guia o ajudará a configurar as contas e a entender os benefícios do uso da API.
Esse tutorial também envolve o uso de clustering, uma técnica de aprendizado de máquina usada para agrupar instâncias semelhantes. Se você não estiver familiarizado com o clustering, especialmente o k-Means, considere a leitura de Introduction to k-Means Clustering with scikit-learn in Python.
Para que você pode usar o Text Embeddings?
As incorporações de texto podem ser aplicadas a vários casos de uso, incluindo, entre outros, os seguintes:
- Classificação de texto. As incorporações de texto ajudam a criar modelos precisos para análise de sentimentos ou tarefas de identificação de tópicos.
- Recuperação de informações. Eles podem ser usados para recuperar informações relevantes para uma consulta específica, semelhante ao que podemos encontrar em um mecanismo de busca.
- Detecção de similaridade semântica. As incorporações podem identificar e quantificar a similaridade semântica entre trechos de texto.
- Sistemas de recomendação. Eles podem melhorar a qualidade das recomendações compreendendo as preferências do usuário com base em sua interação com dados de texto.
- Geração de texto. Os embeddings são usados para gerar textos mais coerentes e contextualmente relevantes.
- Tradução automática. As incorporações de texto podem capturar significados semânticos em vários idiomas, o que pode melhorar a qualidade do processo de tradução automática.
Preparação
Vários pacotes Python são necessários para trabalhar com embeddings de texto, conforme descrito abaixo:
- os: Uma biblioteca Python integrada para interagir com o sistema operacional.
- openai: o cliente Python para interagir com a API OpenAI.
- scipy.spatial.distance: fornece funções para calcular a distância entre diferentes pontos de dados.
- sklean.cluster.KMeans: usado para calcular o agrupamento KMeans.
- umap.UMAP: uma técnica usada para reduzir a dimensionalidade de dados de alta dimensão.
Antes de usá-los, certifique-se de instalar openai, scipy, plotly sklearn e umap com o seguinte comando. O código completo está disponível no DataCamp Workspace.
pip install -U openai, scipy, plotly-express, scikit-learn, umap-learnApós a execução bem-sucedida do comando anterior, todas as bibliotecas podem ser importadas da seguinte forma:
import os
import openai
from scipy.spatial import distance
import plotly.express as px
from sklearn.cluster import KMeans
from umap import UMAPAgora podemos configurar a chave da API da OpenAI da seguinte forma:
openai.api_key = "<YOUR_API_KEY_HERE>"Observação: Você precisará configurar sua própria API KEY. A do código-fonte não está disponível e era apenas para uso individual.
O padrão de código para chamar o GPT por meio da API
A função auxiliar a seguir pode ser usada para incorporar uma linha de texto usando a API OpenAI. No código, estamos usando a versão 2 do ada existente para gerar os embeddings.
def get_embedding(text_to_embed):
# Embed a line of text
response = openai.Embedding.create(
model= "text-embedding-ada-002",
input=[text_to_embed]
)
# Extract the AI output embedding as a list of floats
embedding = response["data"][0]["embedding"]
return embeddingSobre o conjunto de dados
Nesta seção, consideraremos os dados de avaliação de instrumentos musicais da Amazon disponíveis gratuitamente no Kaggle. Os dados também podem ser baixados da minha conta do Github da seguinte forma:
import pandas as pd
data_URL = "https://raw.githubusercontent.com/keitazoumana/Experimentation-Data/main/Musical_instruments_reviews.csv"
review_df = pd.read_csv(data_URL)
review_df.head()
De todas as colunas, estamos interessados apenas na coluna reviewText .
review_df = review_df[['reviewText']]
print("Data shape: {}".format(review_df.shape))
display(review_df.head())Data shape: (10261, 1)
Há muitas avaliações no conjunto de dados. Para fins de otimização de custos, usaremos apenas 100 linhas selecionadas aleatoriamente.

Agora, podemos gerar os embeddings para cada linha em todo o conjunto de dados aplicando a função anterior usando a expressão lambda:
review_df = review_df.sample(100)
review_df["embedding"] = review_df["reviewText"].astype(str).apply(get_embedding)
# Make the index start from 0
review_df.reset_index(drop=True)
review_df.head(10)
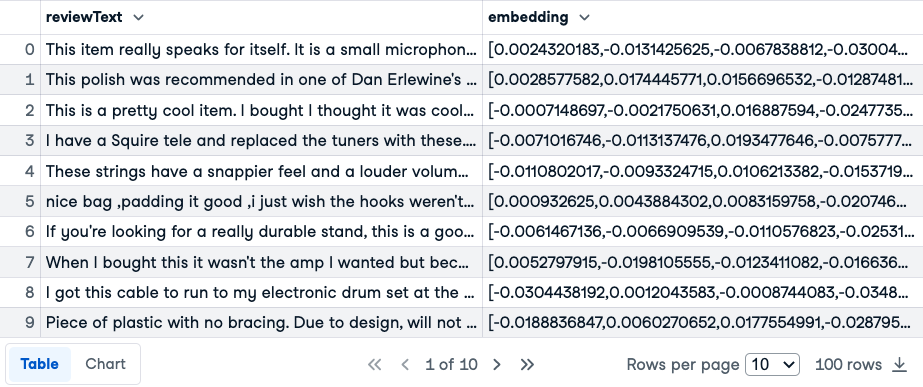
Primeiras 10 linhas das revisões e emdeddings
Compreender a similaridade do texto
Para mostrar o conceito de similaridade semântica, vamos considerar duas avaliações que podem ter sentimentos semelhantes:
"Este produto é fantástico!"
"Ele realmente superou minhas expectativas!"
Usando pdist() de scipy.spatial.distance, podemos calcular a distância euclidiana entre suas incorporações.
A distância euclidiana corresponde à raiz quadrada da soma da diferença quadrada entre os dois embeddings, e uma ilustração é dada abaixo:
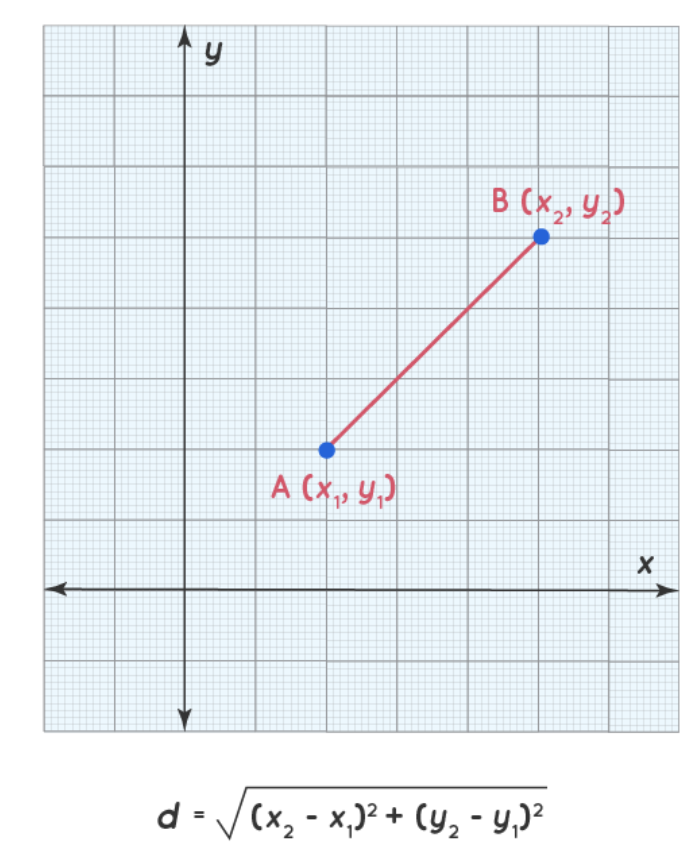
Ilustração da distância euclidiana(fonte)
Se essas avaliações forem de fato semelhantes, a distância deverá ser relativamente pequena.
Em seguida, considere duas revisões diferentes:
"Este produto é fantástico!"
"Não estou satisfeito com o item."
A distância entre os embeddings dessas avaliações será significativamente maior do que a distância entre as avaliações semelhantes.
Estudo de caso: Use a incorporação de texto para análise de cluster
As incorporações de texto que geramos podem ser usadas para realizar a análise de agrupamento, de modo que os instrumentos musicais mais semelhantes entre si possam ser agrupados.
Há vários algoritmos de agrupamento disponíveis, como K-Means, DBSCAN, agrupamento hierárquico e modelos de mistura gaussiana. Neste caso de uso específico, usaremos o clustering KMeans. No entanto, nossa Introdução ao agrupamento hierárquico em Python oferece uma boa estrutura para entender os detalhes do agrupamento hierárquico e sua implementação em Python.
Agrupar os dados de texto
O uso do agrupamento K-means requer a predefinição do número de agrupamentos a serem usados, e definiremos esse número como 3 com o parâmetro n_clusters da seguinte forma:
kmeans = KMeans(n_clusters=3)
kmeans.fit(review_df["embedding"].tolist())Reduzir as dimensões dos dados de texto incorporados
Em geral, os seres humanos só conseguem visualizar até três dimensões. Esta seção usará o UMAP, uma ferramenta relativamente rápida e dimensionável para realizar a redução da dimensionalidade.
Primeiro, definimos uma instância da classe UMAP e aplicamos a função fit_transform às incorporações, o que gera uma representação bidimensional das incorporações das revisões que podem ser plotadas.
reducer = UMAP()
embeddings_2d = reducer.fit_transform(review_df["embedding"].tolist())Visualize os clusters
Por fim, crie um gráfico de dispersão dos embeddings bidimensionais. As coordenadas x e y são obtidas respectivamente em embeddings_2d[: , 0] e embeddings_2d[: , 1]
Os clusters serão visualmente distintos:
fig = px.scatter(x=embeddings_2d[:, 0], y=embeddings_2d[:, 1], color=kmeans.labels_)
fig.show()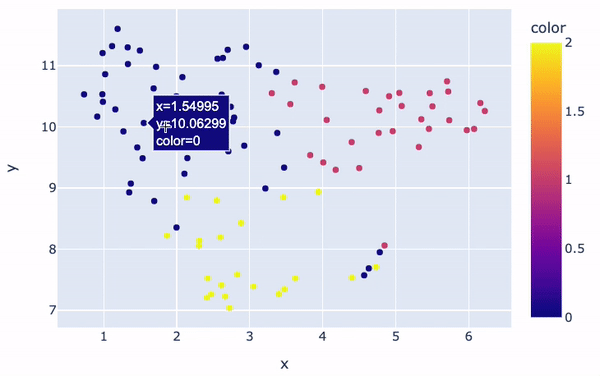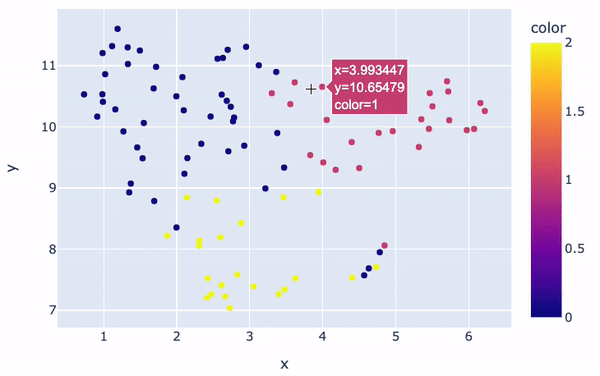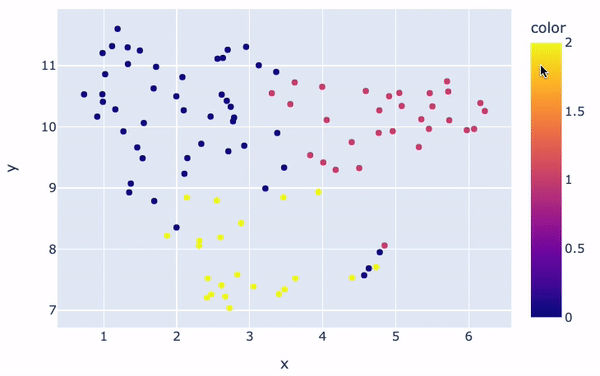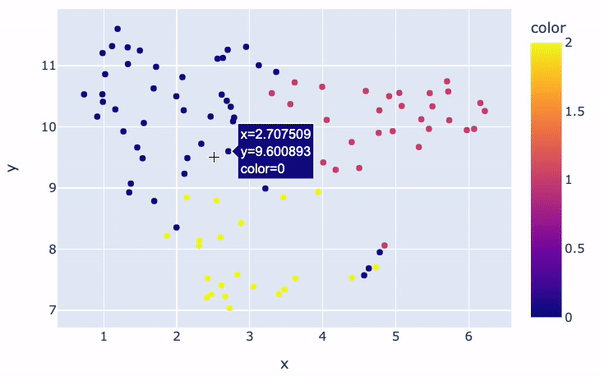
Visualização de clusters
No geral, há três clusters principais com cores diferentes. A cor de cada análise na figura é determinada pelo rótulo/número do cluster atribuído a ela pelo modelo K-Means. Além disso, o posicionamento de cada ponto fornece uma representação visual da semelhança de uma determinada análise com as demais.
Leve-o para o próximo nível
Para aprofundar seu conhecimento sobre embeddings de texto e a API OpenAI, considere o seguinte material do DataCamp: Ajuste fino do GPT-3 usando a API OpenAI e Python e a folha de dicas da API OpenAI em Python. Ele o ajuda a liberar todo o potencial do GPT-3 por meio do ajuste fino e também ilustra como usar a API OpenAI e o Python para aprimorar esse modelo avançado de rede neural para seu caso de uso específico.



