Curso
Conceitos de Grandes Modelos de Linguagem (LLMs)
2 h
99.8K
No último ano e meio, o campo do processamento de linguagem natural (PLN) passou por uma transformação significativa devido à popularização dos grandes modelos de linguagem (LLMs, Large Language Models). As habilidades de linguagem natural que esses modelos apresentam permitiram aplicações que pareciam impossíveis de serem realizadas há alguns anos.
Os LLMs estão ampliando os limites do que antes era considerado possível, com recursos que vão desde a tradução de idiomas até a análise de sentimentos e a geração de textos.
No entanto, todos nós sabemos que o treinamento desses modelos é demorado e caro. Por isso, o ajuste fino de grandes modelos de linguagem é importante para adaptar esses algoritmos avançados a tarefas ou domínios específicos.
Esse processo aprimora o desempenho do modelo em tarefas especializadas e amplia consideravelmente sua aplicabilidade em várias áreas. Isso significa que podemos aproveitar a capacidade de processamento de linguagem natural dos LLMs pré-treinados e de código aberto e treiná-los ainda mais para executar tarefas específicas.
Hoje, você vai conhecer a essência dos modelos de linguagem pré-treinados e se aprofundar no processo de ajuste fino.
Então, vamos ver etapas práticas para fazer o ajuste fino de um modelo como o GPT-2 usando a Hugging Face.
Um modelo de linguagem é um tipo de algoritmo de machine learning desenvolvido para prever a próxima palavra de uma frase, tomando por base os segmentos anteriores. É baseado na arquitetura de transformadores, que é explicada em detalhes em nosso artigo Como Funcionam os Transformadores.
Modelos de linguagem pré-treinados, como o GPT (Generative Pre-trained Transformer), são treinados em grandes quantidades de dados de textos. Isso permite que os LLMs compreendam os princípios fundamentais que regem o uso de palavras e sua disposição na linguagem natural.

Imagem do autor Entrada e saída de um LLM.
A parte mais importante é que esses modelos são bons não só em compreender a linguagem natural, mas também em gerar textos semelhantes aos de humanos com base na entrada que recebem.
E a melhor parte de tudo isso?
Esses modelos já estão disponíveis para o público em geral via APIs. Se quiser saber como tirar proveito dos LLMs mais avançados da OpenAI, você pode aprender a fazer isso seguindo esta folha de dicas sobre a API da OpenAI.
Ajuste fino é o processo de pegar um modelo pré-treinado e treiná-lo ainda mais com um conjunto de dados específico do domínio.
A maioria dos modelos LLM atuais tem um desempenho geral muito bom, mas apresenta falhas em problemas específicos orientados a tarefas. O processo de ajuste fino oferece vantagens consideráveis, como despesas de computação reduzidas e a capacidade de utilizar modelos de ponta sem a necessidade de desenvolver um modelo desde o início.
Os transformadores permitem acesso a uma ampla coleção de modelos pré-treinados adequados a várias tarefas. O ajuste fino desses modelos é uma etapa crucial para melhorar a capacidade do modelo de executar tarefas específicas, como análise de sentimentos, resposta a perguntas ou resumo de documentos, com maior precisão.
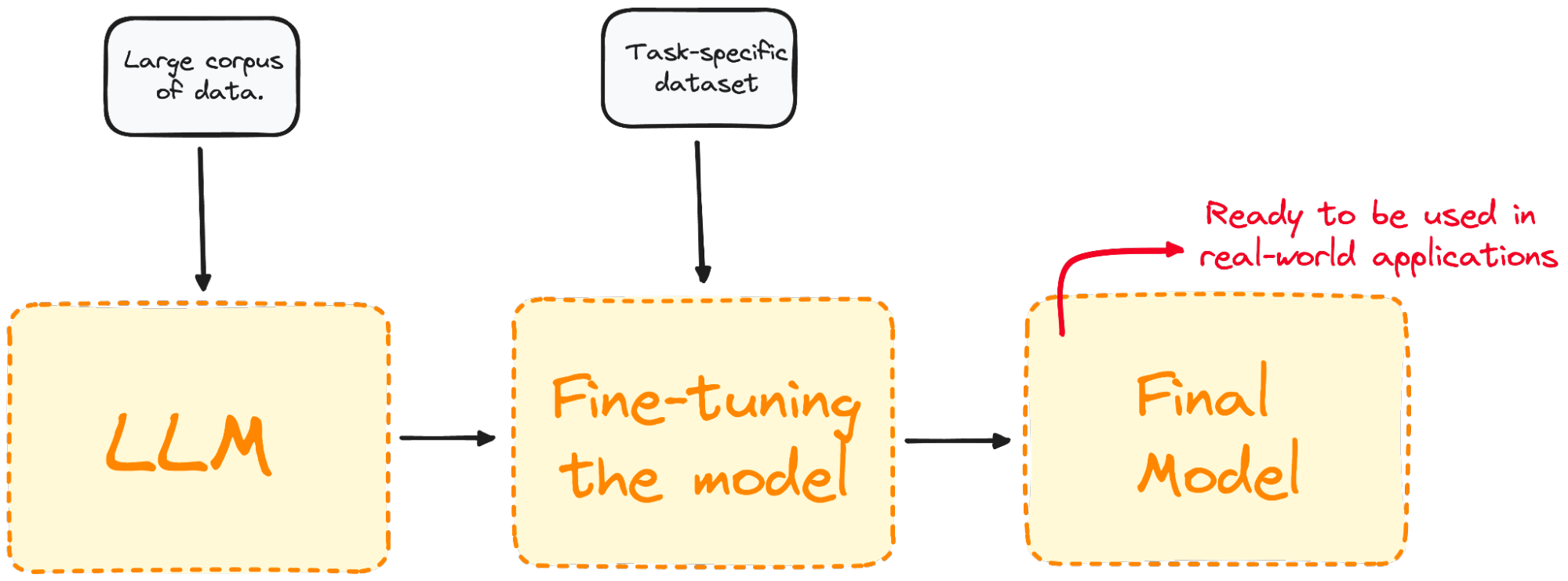
Imagem do autor. Visualização do processo de ajuste fino.
O ajuste fino adapta o modelo para que ele tenha um melhor desempenho em tarefas específicas, tornando-o mais eficaz e versátil em aplicações reais. Esse processo é essencial para adaptar um modelo já existente a uma tarefa ou domínio específico.
A decisão de fazer o ajuste fino depende de suas metas, que normalmente variam de acordo com o domínio específico ou a tarefa em questão.
O ajuste fino pode ser abordado de várias maneiras, dependendo principalmente do foco principal e de seus objetivos específicos.
A abordagem de ajuste fino mais simples e comum. O modelo é treinado com um conjunto de dados rotulado específico para a tarefa-alvo a ser executada, como classificação de textos ou reconhecimento de entidades nomeadas.
Por exemplo: para análise de sentimentos, devemos treinar o modelo com um conjunto de dados contendo amostras de texto rotuladas com o sentimento correspondente.
Há alguns casos em que a coleta de um grande conjunto de dados rotulados não é prática. O aprendizado com poucos exemplos (few-shot learning) busca resolver isso disponibilizando alguns exemplos (shots) da tarefa necessária no início dos prompts de entrada. Isso ajuda o modelo a ter um contexto melhor da tarefa sem um extenso processo de ajuste fino.
Embora todas as técnicas de ajuste fino sejam uma forma de aprendizado por transferência, essa categoria tem o objetivo específico de permitir que um modelo execute uma tarefa diferente daquela com que foi inicialmente treinado. A ideia principal é aproveitar o conhecimento que o modelo adquiriu com um conjunto de dados grande e geral e aplicá-lo a uma tarefa mais específica ou relacionada.
Esse tipo de ajuste fino tenta adaptar o modelo para entender e gerar textos específicos de um determinado domínio ou setor. O modelo é ajustado com um conjunto de dados composto de textos do domínio desejado para melhorar seu contexto e conhecimento de tarefas específicas do domínio.
Por exemplo: para gerar um chatbot para um aplicativo médico, o modelo deve ser treinado com registros médicos, visando adaptar sua capacidade de compreensão de linguagem à área da saúde.
Execute e edite o código deste tutorial online
Executar códigoJá sabemos que o ajuste fino é o processo de pegar um modelo pré-treinado e atualizar seus parâmetros treinando-o com um conjunto de dados específico para sua tarefa. Então, vamos exemplificar esse conceito com o ajuste fino de um modelo real.
Imagine que estamos trabalhando com o GPT-2, mas percebemos que ele é muito ruim para inferir os sentimentos de tweets.
Uma pergunta natural que vem à mente é: podemos fazer algo para melhorar seu desempenho?
Para que o desempenho melhore, podemos aproveitar o ajuste fino treinando nosso modelo GPT-2 pré-treinado a partir do modelo da Hugging Face com um conjunto de dados contendo tweets e seus sentimentos correspondentes. Veja um exemplo básico de ajuste fino de um modelo para classificação de sequências:
Para fazer o ajuste fino de um modelo, sempre precisamos ter em mente um modelo pré-treinado. No nosso caso, vamos fazer um ajuste fino simples usando o GPT-2.
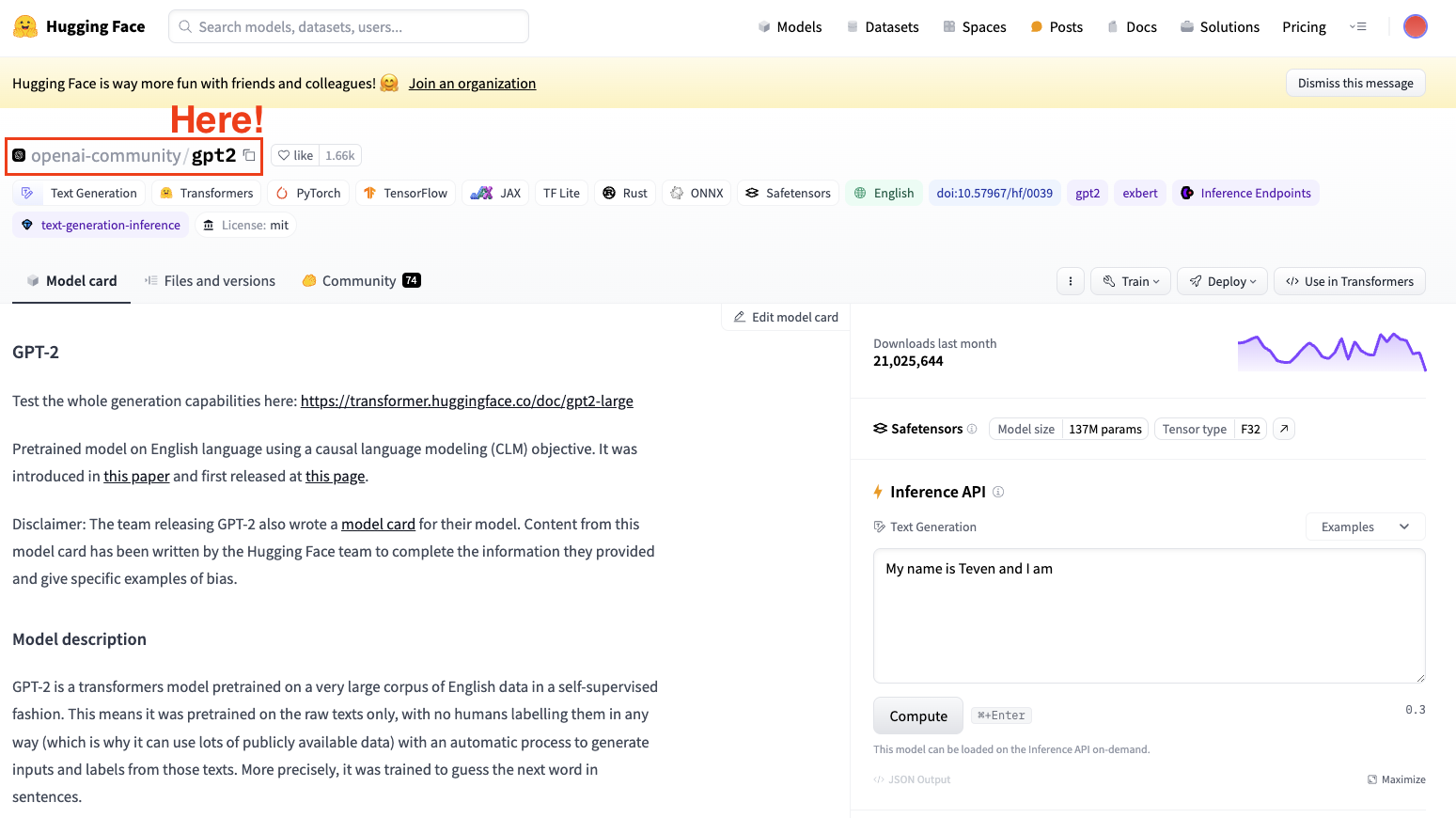
Captura de tela do hub de conjuntos de dados da Hugging Face. Seleção do modelo GPT2 da OpenAI.
Lembre-se sempre de selecionar uma arquitetura de modelo adequada para a tarefa.
Agora que temos nosso modelo, precisamos de dados de qualidade para trabalhar, e é exatamente aí que a biblioteca datasets entra em ação.
No meu caso, vou usar a biblioteca datasets da Hugging Face para importar um conjunto de dados contendo tweets segmentados por sentimento (positivos, neutros ou negativos).
from datasets import load_dataset
dataset = load_dataset("mteb/tweet_sentiment_extraction")
df = pd.DataFrame(dataset['train'])
Ao verificar o conjunto de dados que acabamos de baixar, vemos que é um conjunto de dados que contém um subconjunto de treinamento e outro de teste. Ao converter o subconjunto de treinamento em um DataFrame, ele fica assim:

Conjunto de dados a ser usado.
Agora que já temos o conjunto de dados, precisamos de um tokenizador a fim de prepará-lo para ser analisado pelo nosso modelo.
Como os LLMs trabalham com tokens, precisamos de um tokenizador para processar o conjunto de dados. Para processar o conjunto de dados em uma única etapa, use o método map de Datasets para aplicar uma função de pré-processamento em todo o conjunto de dados.
É por isso que a segunda etapa é carregar um tokenizador pré-treinado e tokenizar o conjunto de dados para que ele possa ser usado para o ajuste fino.
from transformers import GPT2Tokenizer
# Loading the dataset to train our model
dataset = load_dataset("mteb/tweet_sentiment_extraction")
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
tokenizer.pad_token = tokenizer.eos_token
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True)
tokenized_datasets = dataset.map(tokenize_function, batched=True)BÔNUS: para melhorar os requisitos de processamento, podemos criar um subconjunto menor do conjunto de dados completo para ajustar o modelo. O conjunto de treinamento será usado para ajuste fino do modelo, enquanto o conjunto de teste será usado para avaliá-lo.
small_train_dataset = tokenized_datasets["train"].shuffle(seed=42).select(range(1000))
small_eval_dataset = tokenized_datasets["test"].shuffle(seed=42).select(range(1000))Comece carregando o modelo e especifique o número de rótulos esperados. No cartão do conjunto de dados de sentimento dos tweets, você sabe que há três rótulos:
from transformers import GPT2ForSequenceClassification
model = GPT2ForSequenceClassification.from_pretrained("gpt2", num_labels=3)A biblioteca Transformers disponibiliza a classe Trainer, otimizada para treinamento. No entanto, esse método não inclui uma forma de avaliar o modelo. É por isso que, antes de iniciar o treinamento, precisamos passar ao Trainer uma função para avaliar o desempenho do modelo.
import evaluate
metric = evaluate.load("accuracy")
def compute_metrics(eval_pred):
logits, labels = eval_pred
predictions = np.argmax(logits, axis=-1)
return metric.compute(predictions=predictions, references=labels)A última etapa é configurar os argumentos de treinamento e iniciar o processo de treinamento. A biblioteca Transformers contém a classe Trainer, que disponibiliza uma ampla gama de opções e recursos de treinamento, como registro em log, acúmulo de gradiente e precisão mista. Primeiro, definimos os argumentos de treinamento juntamente com a estratégia de avaliação. Quando tudo estiver definido, é possível treinar o modelo com facilidade usando o comando train().
from transformers import TrainingArguments, Trainer
training_args = TrainingArguments(
output_dir="test_trainer",
#evaluation_strategy="epoch",
per_device_train_batch_size=1, # Reduce batch size here
per_device_eval_batch_size=1, # Optionally, reduce for evaluation as well
gradient_accumulation_steps=4
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=small_train_dataset,
eval_dataset=small_eval_dataset,
compute_metrics=compute_metrics,
)
trainer.train()
Após o treinamento, avalie o desempenho do modelo com um conjunto de validação ou teste. Novamente, a classe Trainer já contém um método de avaliação que cuida disso.
import evaluate
trainer.evaluate()
Essas são as etapas mais básicas para fazer o ajuste fino de qualquer LLM. Lembre-se de que o ajuste fino de um LLM exige muita capacidade de computação, e talvez seu computador local não tenha capacidade suficiente para isso.
Você pode aprender a fazer o ajuste fino de LLMs mais avançados diretamente na interface da OpenAI seguindo este tutorial sobre Como fazer o ajuste fino do GPT 3.5.
Comece sua jornada de IA hoje mesmo!
Curso
Curso
Curso
blog
Nisha Arya Ahmed
12 min
blog
Stanislav Karzhev
9 min
Tutorial
Abid Ali Awan
Tutorial
Abid Ali Awan
Tutorial
Zoumana Keita
Tutorial
Moez Ali


