Kurs
Explorative Datenanalyse in SQL
4 Std.
180.6K
Die Struktur einer Datenbank kann sich sehr ähnlich anfühlen wie Excel. Allerdings sind Datenbanken im Allgemeinen leistungsfähiger als Excel-Tabellen. Hier sind drei Gründe, warum du das sagen kannst:
Bist du aufgeregt, mit SQL anzufangen? Das DataCamp bietet dir tolle Materialien für den Einstieg; die Lernpfade, denen du folgen kannst, um deine SQL-Kenntnisse zu vertiefen, werden hier vorgestellt!
Lass uns jetzt tiefer in SQL-Abfragen eintauchen...
Eine SQL-Abfrage ist eine Anweisung, die aus verschiedenen SQL-Befehlen zusammengesetzt ist. Diese SQL-Befehle erfüllen zusammen eine bestimmte Aufgabe, um auf deine in einer Datenbank gespeicherten und über ein DBMS verwalteten Daten zuzugreifen, sie zu verwalten, zu ändern, zu aktualisieren, zu kontrollieren und zu organisieren.
SQL ist unglaublich vielseitig und wird von allen genutzt, von Datenwissenschaftlern und Ingenieuren bis hin zu Marketing- und Personalteams - im Grunde von allen, die einfach mehr über Daten wissen wollen!
Sie wird nicht nur in der Tech-Branche eingesetzt oder ist auf große Unternehmen beschränkt. Zahlreiche Branchen aller Größenordnungen nutzen es direkt oder indirekt. Fachleute, die im Finanz- und Gesundheitswesen arbeiten, verwenden zum Beispiel häufig SQL, da sie große Datenmengen produzieren.
Daten sind die neue Ware, und SQL ist ein sehr mächtiges Werkzeug, wenn es um den Umgang mit Big Data geht. Du fragst dich, wie du SQL optimal nutzen kannst? Das DataCamp-Tutorial "Was kann man mit SQL machen?" hilft dir bei der Beantwortung dieser Frage.
Bevor wir uns mit der Abfrageformulierung selbst befassen, lass uns die Frage betrachten: "Wo kann ich meine SQL-Abfrage schreiben und ausführen?"
DataCamp's Learn SQL Hub kann ein guter Ausgangspunkt sein, um mit SQL auf einem Mac oder Windows-Rechner zu arbeiten und loszulegen.
Wenn du aber einfach nur die Muttersprache der Datenbanken - SQL - lernen willst, kannst du mit dem DataCamp-Kurs Einführung in SQL beginnen. In diesem Kurs lernst du die SQL-Syntax, die von vielen Datenbanktypen verwendet wird, z.B. PostgreSQL, MySQL, SQL Server und Oracle. Du arbeitest mit der eingebauten SQL-Schnittstelle von DataCamp und musst dich nicht mit den anfänglichen Schwierigkeiten eines RDBMS herumschlagen.
DataCamp hat auch ein tolles Notizbuch-Tool, mit dem du deine eigenen Notizbücher erstellen kannst: DataLab. DataLab ist ein kollaboratives, cloudbasiertes Notizbuch, mit dem du Daten analysieren, mit deinem Team zusammenarbeiten und Erkenntnisse teilen kannst. DataLab wurde entwickelt, um dich vom Erlernen der Datenwissenschaft zum Handeln in der Datenwissenschaft zu bringen. Mit den integrierten Datensätzen kannst du innerhalb von Minuten mit der Analyse von Daten beginnen.
Werfen wir nun einen Blick auf den Datensatz, mit dem wir in diesem Lernprogramm arbeiten werden.
Wir beginnen mit "films" - einer SQL-Tabelle mit den Daten von 10 Filmen. Diese Daten sind nur eine kleine Teilmenge des IMDb Film-Datensatzes, der im bereits erwähnten DataCamp-Kurs Einführung in SQL verwendet wurde.
|
title |
release_year |
budget |
brutto |
imdb_score |
|
|
1 |
Der Pate |
1972 |
6000000 |
134821952 |
9.2 |
|
2 |
Der dunkle Ritter |
2008 |
185000000 |
533316061 |
9 |
|
3 |
Der Pate: Teil II |
1974 |
13000000 |
57300000 |
9 |
|
4 |
Schindlers Liste |
1993 |
22000000 |
96067179 |
8.9 |
|
5 |
Pulp Fiction |
1994 |
8000000 |
107930000 |
8.9 |
|
6 |
Der Herr der Ringe: Die Rückkehr des Königs |
2003 |
94000000 |
377019252 |
8.9 |
|
7 |
Fight Club |
1999 |
63000000 |
37023395 |
8.8 |
|
8 |
Inception |
2010 |
160000000 |
292568851 |
8.8 |
|
9 |
Star Wars: Episode V - Das Imperium schlägt zurück |
1980 |
18000000 |
290158751 |
8.8 |
|
10 |
Die Verurteilten - Die Erlösung |
1994 |
25000000 |
28341469 |
9.3 |
Die Tabelle "Filme" enthält zehn Datensätze - die Filmnamen, die in 10 Zeilen gespeichert sind. Die Felder sind die fünf Spalten in der Tabelle, in denen die Informationen über den Film gespeichert sind.
Beginnen wir die Übung mit einigen grundlegenden SQL-Befehlen, mit denen wir die obige Tabelle "Filme" untersuchen. Wir erwarten nicht, dass du die Lösungsabfragen sofort ausführst, sondern nutzen sie als Grundlage, um einige Schlüsselkonzepte zu lernen. Mach dir also keine Sorgen, wenn du dich noch nicht für eine Plattform entschieden hast, auf der du die Abfragen durchführen willst.
Denke daran, dass bei SQL-Schlüsselwörtern oder -Befehlen nicht zwischen Groß- und Kleinschreibung unterschieden wird; wenn du "select" schreibst, ist das dasselbe wie "SELECT".
Wir werden ein Semikolon am Ende jeder SQL-Anweisung verwenden, die wir schreiben. Dies ist bei einigen Datenbanksystemen üblich und dient dazu, die einzelnen SQL-Anweisungen voneinander zu trennen, damit sie mit demselben Aufruf an den Server ausgeführt werden können.
Lass uns mit einer Frage beginnen. Q1: Was sind die Filme, die in der Tabelle gespeichert sind?
Mit der SELECT-Anweisung wählst du die Felder aus, die du in der Tabelle der Datenbank sehen möchtest. Für Q1 brauchst du das Feld "Titel".
Der FROM-Befehl bzw. das FROM-Schlüsselwort gibt die Tabelle in der Datenbank an, aus der du die Daten beziehen möchtest. Denke daran, dass eine Datenbank aus mehreren Tabellen bestehen kann.
Syntax: SELECT column1, column2, … FROM table_name;
SQL-Abfrage: SELECT title FROM films;
Ergebnis:
|
title |
|
|
1 |
Der Pate |
|
2 |
Der dunkle Ritter |
|
3 |
Der Pate: Teil II |
|
4 |
Schindlers Liste |
|
5 |
Pulp Fiction |
|
6 |
Der Herr der Ringe: Die Rückkehr des Königs |
|
7 |
Fight Club |
|
8 |
Inception |
|
9 |
Star Wars: Episode V - Das Imperium schlägt zurück |
|
10 |
Die Verurteilten - Die Erlösung |
Du fragst dich vielleicht, was passiert, wenn du die obige Tabelle noch nie gesehen hast und die Namen der Spalten nicht kennst, die du in der SELECT-Anweisung angeben musst. Gutes Argument! Über das magische '*' (Sternchen) werden wir später in diesem Lernprogramm lernen.
Q2: Welche Filme kommen 2010 in die Kinos?
Für diese Frage möchtest du die Filme "herausfiltern", damit du Filmnamen hast, die die Bedingung erfüllen: "release_year" ist 2010.
Mit der "WHERE"-Klausel kannst du nur die Datensätze extrahieren, die eine bestimmte Bedingung erfüllen.
Syntax: SELECT spalte1, spalte2, ... FROM tabellenname WHERE condition;
SQL-Abfrage: SELECT title, release_year FROM films WHERE release_year = 2010;
Ergebnis:
|
title |
release_year |
|
|
1 |
Inception |
2010 |
Die folgenden Operatoren können innerhalb der WHERE-Klausel verwendet werden:
|
Betreiber |
Beschreibung |
|
= |
Gleichgestellt mit |
|
> |
Größer als |
|
< |
Weniger als |
|
>= |
Größer als oder gleich |
|
<= |
Weniger als oder gleich |
|
<> oder != |
Nicht gleich. |
|
ZWISCHEN |
Zwischen einem bestimmten Bereich |
|
LIKE |
Suche nach einem Muster, das mit dem angegebenen Muster übereinstimmt |
|
IN |
Gibt mehrere mögliche Werte an |
Mit den mathematischen Symbolen kannst du in SQL einfache arithmetische Berechnungen durchführen: +, -, *, /. Allerdings kannst du mit diesen arithmetischen Symbolen nur spaltenübergreifende Operationen durchführen. Du kannst auch Klammern verwenden, um die Reihenfolge der Operationen zu verwalten.
Aber keine Angst, für kompliziertere Operationen gibt es in SQL Aggregatfunktionen, mit denen du Operationen innerhalb derselben Zeile durchführen kannst. Wir behandeln dieses Thema später im Lernprogramm.
Q3: Berechne den Gewinn, den jeder Film in der Tabelle "Filme" gemacht hat.
Hint: Führe Brutto - Budget aus und speichere das Ergebnis in einer Spalte namens "movie_profit" mit AS
SQL-Abfrage: SELECT Titel, (Brutto - Budget) AS movie_profit FROM films
Ergebnis:
|
title |
movie_profit |
|
|
1 |
Der Pate |
128821952 |
|
2 |
Der dunkle Ritter |
348316061 |
|
3 |
Der Pate: Teil II |
44300000 |
|
4 |
Schindlers Liste |
74067179 |
|
5 |
Pulp Fiction |
99930000 |
|
6 |
Der Herr der Ringe: Die Rückkehr des Königs |
283019252 |
|
7 |
Fight Club |
-25976605 |
|
8 |
Inception |
132568851 |
|
9 |
Star Wars: Episode V - Das Imperium schlägt zurück |
272158751 |
|
10 |
Die Verurteilten - Die Erlösung |
3341469 |
Haftungsausschluss: Die Filmfans da draußen könnten sich an den negativen Ergebnissen für Fight Club stören. Die verwendete Formel ((brutto - budget) AS movie_profit) ist sehr einfach und angesichts der Formel und der Daten ist sie auch das richtige Ergebnis.
Aber das obige Beispiel soll dich daran erinnern, dass du bei der Datenerfassung achtsam sein musst! Selbst eine einfache Datenuntersuchung kann Datenfehler aufdecken, die durch einen Fehler bei der Datenerfassung oder Datenspeicherung (Änderung des Datentyps usw.) verursacht werden können - das könnte bei der Erstellung des verwendeten Datensatzes der Fall gewesen sein.
Achte immer auf die Daten, mit denen du arbeitest!
Die WHERE-Klausel kann mit anderen bedingten Klauseln mit den Operatoren AND, OR und NOT kombiniert werden. Die Operatoren AND und OR werden verwendet, um Datensätze nach mehr als einer Bedingung zu filtern, und der Operator NOT wird verwendet, um eine Bedingung zu negieren.
Sehen wir uns ihre Verwendung anhand von Beispielen an:
Q4: Welche Filme kommen 2010 in die Kinos und haben eine höhere Bewertung als 9?
Syntax: SELECT spalte1, spalte2, ... FROM tabelle_name WHERE bedingung1 UND bedingung2 UND bedingung3 UND bedingung4.....;
SQL-Abfrage: SELECT title, release_year, imdb_score FROM films WHERE release_year = 2010 AND imdb_score >= 9;
Der Operator AND zeigt einen Datensatz an, wenn alle durch AND getrennten Bedingungen wahr sind.
In der Tabelle "Filme" haben wir den Film "Inception". Es ist der einzige Wert, der für release_year = 2010 wahr ist, aber er ist falsch für imdb_score >= 9 und erfüllt somit nicht die gesetzte UND-Bedingung. Die Abfrage liefert also eine leere Ergebnismenge.
Q5: Welche Filme kommen 2010 in die Kinos oder haben eine höhere Bewertung als 9?
Syntax: SELECT spalte1, spalte2, ... FROM tabellenname WHERE condition1 OR condition2 OR condition3 OR condition4.....;
SQL-Abfrage: SELECT title, release_year, imdb_score FROM films WHERE release_year = 2010 OR imdb_score >= 9;
Ergebnis:
|
title |
release_year |
imdb_score |
|
|
1 |
Der Pate |
1972 |
9.2 |
|
2 |
Der dunkle Ritter |
2008 |
9 |
|
3 |
Der Pate: Teil II |
1974 |
9 |
|
4 |
Inception |
2010 |
8.8 |
|
5 |
Die Verurteilten - Die Erlösung |
1994 |
9.3 |
Der Operator OR zeigt einen Datensatz an, wenn eine der durch OR getrennten Bedingungen WAHR ist.
Die Filme: Der Pate, The Dark Knight, The Godfather: Part II, The Shawshank Redemption sind wahr für imdb_score >= 9, während Inception wahr ist für release_year = 2010, und daher schaffen sie den Cut für die OR-Bedingung.
Q6: Welches sind die Filme, die ein anderes Erscheinungsjahr als 2010 haben?
Syntax: SELECT column1, column2, … FROM table_name WHERE NOT condition1;
SQL-Abfrage: SELECT title, release_year FROM films WHERE NOT release_year = 2010;
Ergebnis:
|
title |
release_year |
|
|
1 |
Der Pate |
1972 |
|
2 |
Der dunkle Ritter |
2008 |
|
3 |
Der Pate: Teil II |
1974 |
|
4 |
Schindlers Liste |
1993 |
|
5 |
Pulp Fiction |
1994 |
|
6 |
Der Herr der Ringe: Die Rückkehr des Königs |
2003 |
|
7 |
Fight Club |
1999 |
|
8 |
Star Wars: Episode V - Das Imperium schlägt zurück |
1980 |
|
9 |
Die Verurteilten - Die Erlösung |
1994 |
Du könntest auch schreiben: SELECT title, release_year FROM films WHERE release_year != 2010;
Auch dies würde das gleiche Ergebnis wie oben liefern.Es kann mehrere Wege geben, um in SQL das gleiche Ergebnis zu erzielen. Einige Abfragen können jedoch leistungsfähiger sein als andere. Die Leistung kann von mehreren Faktoren abhängen - von der Datenmenge, den in der Abfrage verwendeten Befehlen, der Struktur der Datenbank, dem Datentyp usw. Dies ist ein etwas komplizierteres und fortgeschrittenes Thema, das wir in diesem SQL-Abfrage-Tutorial nicht behandeln werden.
Wenn du dich dafür interessierst, kannst du im DataCamp-Kurs Datenbankdesign tiefer in diese Themen eintauchen.
Mit dem Schlüsselwort ORDER BY kannst du das Ergebnis entweder in aufsteigender (mit dem Schlüsselwort ASC) oder absteigender Reihenfolge (mit dem Schlüsselwort DESC) sortieren. Die Sortierung erfolgt standardmäßig in aufsteigender Reihenfolge.
Q7: Was sind die Filme, die in der Tabelle gespeichert sind? Sortiere sie in absteigender Reihenfolge nach release_year.
Syntax: SELECT spalte1, spalte2, ... FROM tabelle_name ORDER BY spalte1, spalte2, ... ASC|DESC;
SQL-Abfrage: SELECT title, release_year FROM films ORDER BY release_year DESC;
Ergebnis:
|
title |
release_year |
|
|
1 |
Inception |
2010 |
|
2 |
Der dunkle Ritter |
2008 |
|
3 |
Der Herr der Ringe: Die Rückkehr des Königs |
2003 |
|
4 |
Fight Club |
1999 |
|
5 |
Pulp Fiction |
1994 |
|
6 |
Die Verurteilten - Die Erlösung |
1994 |
|
7 |
Schindlers Liste |
1993 |
|
8 |
Star Wars: Episode V - Das Imperium schlägt zurück |
1980 |
|
9 |
Der Pate: Teil II |
1974 |
|
10 |
Der Pate |
1972 |
Manchmal kann es sehr lange dauern, bis die Datenbank deine Abfrage ausführt, vor allem, wenn die in der Datenbank gespeicherte Datenmenge sehr groß ist.
Eine einfache und schnelle Möglichkeit, eine Abfrage zu testen oder zu sehen, welche Art von Ergebnis du zurückbekommst, ist die LIMIT-Funktion. Mit LIMIT kannst du die Anzahl der Ergebnisse einschränken, die du erhältst.
Q8: Was sind die Top 5 der neuesten Filme in der Tabelle?
Hint: Sortiere die Ergebnismenge in absteigender Reihenfolge nach dem Erscheinungsjahr und verwende dann LIMIT.
Syntax: SELECT column1, column2, … FROM table_name LIMIT x;
SQL-Abfrage: SELECT title, release_year FROM films ORDER BY release_year DESC LIMIT 5;
Ergebnis:
|
title |
release_year |
|
|
1 |
Inception |
2010 |
|
2 |
Der dunkle Ritter |
2008 |
|
3 |
Der Herr der Ringe: Die Rückkehr des Königs |
2003 |
|
4 |
Fight Club |
1999 |
|
5 |
Pulp Fiction |
1994 |
INSERT INTO wird verwendet, um neue Datensätze in eine Tabelle einzufügen. Du kannst eine INSERT INTO-Anweisung auf zwei Arten schreiben:
Syntax: INSERT INTO tabelle_name (spalte1, spalte2, spalte3, ...) VALUES (wert1, wert2, wert3, ...);
Syntax: INSERT INTO table_name VALUES (wert1, wert2, wert3, ...);
Q9: Eintrag hinzufügen für "Der Pate": Teil III" in die Tabelle mit den Details: ('Der Pate: Teil III", 1990, 54000000, 136900000, 7.6)
Syntax: SELECT spalte1, spalte2, ... FROM tabellen_name ORDER BY spalte1, spalte2,... ASC|DESC;
SQL-Abfrage: INSERT INTO films (title, release_year, budget, gross, imdb_score)
VALUES ("Der Pate": Teil III", 1970, 54000000, 136900000, 7.6);
Die resultierende Tabelle:
|
title |
release_year |
budget |
brutto |
imdb_score |
|
|
1 |
Der Pate |
1972 |
6000000 |
134821952 |
9.2 |
|
2 |
Der dunkle Ritter |
2008 |
185000000 |
533316061 |
9 |
|
3 |
Der Pate: Teil II |
1974 |
13000000 |
57300000 |
9 |
|
4 |
Schindlers Liste |
1993 |
22000000 |
96067179 |
8.9 |
|
5 |
Pulp Fiction |
1994 |
8000000 |
107930000 |
8.9 |
|
6 |
Der Herr der Ringe: Die Rückkehr des Königs |
2003 |
94000000 |
377019252 |
8.9 |
|
7 |
Fight Club |
1999 |
63000000 |
37023395 |
8.8 |
|
8 |
Inception |
2010 |
160000000 |
292568851 |
8.8 |
|
9 |
Star Wars: Episode V - Das Imperium schlägt zurück |
1980 |
18000000 |
290158751 |
8.8 |
|
10 |
Die Verurteilten - Die Erlösung |
1994 |
25000000 |
28341469 |
9.3 |
|
11 |
Der Pate: Teil III |
1970 |
54000000 |
136900000 |
7.6 |
Wir verwenden die UPDATE-Anweisung, um die vorhandenen Datensätze in einer Tabelle zu ändern.
Q10: Korrigiere das Erscheinungsjahr für "Der Pate": Teil III" soll 1990 statt 1970 lauten
Syntax: UPDATE tabelle_name SET spalte1 = wert1, spalte2 = wert2, ...WHERE bedingung;
SQL-Abfrage: UPDATE films SET release_year = 1990 WHERE title = 'Der Pate': Teil III";
Die resultierende Tabelle:
|
title |
release_year |
budget |
brutto |
imdb_score |
|
|
1 |
Der Pate |
1972 |
6000000 |
134821952 |
9.2 |
|
2 |
Der dunkle Ritter |
2008 |
185000000 |
533316061 |
9 |
|
3 |
Der Pate: Teil II |
1974 |
13000000 |
57300000 |
9 |
|
4 |
Schindlers Liste |
1993 |
22000000 |
96067179 |
8.9 |
|
5 |
Pulp Fiction |
1994 |
8000000 |
107930000 |
8.9 |
|
6 |
Der Herr der Ringe: Die Rückkehr des Königs |
2003 |
94000000 |
377019252 |
8.9 |
|
7 |
Fight Club |
1999 |
63000000 |
37023395 |
8.8 |
|
8 |
Inception |
2010 |
160000000 |
292568851 |
8.8 |
|
9 |
Star Wars: Episode V - Das Imperium schlägt zurück |
1980 |
18000000 |
290158751 |
8.8 |
|
10 |
Die Verurteilten - Die Erlösung |
1994 |
25000000 |
28341469 |
9.3 |
|
11 |
Der Pate: Teil III |
1990 |
54000000 |
136900000 |
7.6 |
Die DELETE-Anweisung wird verwendet, um einen bestehenden Datensatz in einer Tabelle zu löschen.
Q11: Lösche den Eintrag für "Der Pate": Teil III" aus der Tabelle "Filme".
Syntax: DELETE FROM table_name WHERE condition;
SQL-Abfrage: DELETE FROM films WHERE title = 'Der Pate': Teil III";
Die resultierende Tabelle: Genau wie die ursprüngliche Tabelle, die wir mit insgesamt 10 Datensätzen begonnen haben.
Erinnerst du dich, dass wir das magische "*" für eine spätere Diskussion an das Ende von Q1 gesetzt haben? Das * ist ein Sternchen. Es ist ein übergreifendes Zeichen, das wir als "alle" lesen könnten.
Wir bringen Q1 zurück: Was sind die Filme, die in der Tabelle gespeichert sind?
Wir haben SELECT - FROM mit der Syntax verwendet: SELECT column1, column2, … FROM table_name;
Wir haben die Abfrage verwendet: SELECT title FROM films;
Was aber, wenn du nicht wusstest, dass "Titel" ein Feld in der Tabelle "Filme" ist? Oder den Namen eines beliebigen Feldes in der Tabelle? Oder willst du einfach alle Felder der Tabelle sehen, um ein Gefühl für die Daten zu bekommen? Nun, hier kommt * ins Spiel.
Wir könnten die Abfrage wie folgt umschreiben: SELECT * FROM filme;
So erhalten wir alle in der Tabelle verfügbaren Felder.
Der LIKE-Operator wird in einer WHERE-Klausel verwendet, um nach einem bestimmten Muster in einer Spalte zu suchen.
Q12: Finde alle Namen des Films, die mit "The" beginnen
Syntax: SELECT column1, column2, … FROM table_name WHERE column1 LIKE patternToMatch;
SQL-Abfrage: Select * FROM films WHERE title LIKE 'The%';
Die resultierende Tabelle:
|
title |
release_year |
budget |
brutto |
imdb_score |
|
|
1 |
Der Pate |
1972 |
6000000 |
134821952 |
9.2 |
|
2 |
Der dunkle Ritter |
2008 |
185000000 |
533316061 |
9 |
|
3 |
Der Pate: Teil II |
1974 |
13000000 |
57300000 |
9 |
|
4 |
Der Herr der Ringe: Die Rückkehr des Königs |
2003 |
94000000 |
377019252 |
8.9 |
|
5 |
Die Verurteilten - Die Erlösung |
1994 |
25000000 |
28341469 |
9.3 |
|
Jokerzeichen |
Beschreibung |
Verwendung: Beispiel |
|
% (Prozentsatz) |
Steht für null oder mehr Zeichen |
Die%: Der, Der Pate, Theodore |
|
_ (Unter Punktzahl) |
Stellt ein einzelnes Zeichen dar |
T_e: Die, Krawatte |
|
[ ] (eckige Klammern) |
Steht für jedes einzelne Zeichen innerhalb der Klammern |
C[ao]t: Katze, Bettchen aber nicht Fell |
|
^ (Wedge) |
Steht für jedes Zeichen, das nicht in den Klammern steht |
Ca[^r]: Katze, Taxi, Dose, aber nicht Auto |
|
- (Dash) |
Stellt jedes einzelne Zeichen innerhalb des angegebenen Bereichs dar |
C[a-o]: Dose, Taxi, aber nicht Auto, Katze |
Das Tolle ist, dass wir Wildcards in Kombinationen verwenden können! Du kannst also ziemlich komplexe Match-Anweisungen erstellen, indem du Platzhalterzeichen zusammen mit LIKE verwendest.
SQL eignet sich hervorragend zum Aggregieren von Daten, wie du es in einer Pivot-Tabelle in Excel tun würdest. Aggregatfunktionen können Berechnungen nicht zwischen zwei Spalten, sondern innerhalb einer Spalte durchführen, also mit allen oder einigen Zeilen in derselben Spalte arbeiten.
Dies sind die Aggregatfunktionen in SQL:
|
Funktion |
Beschreibung |
|
ZÄHLEN |
Zählt die Anzahl der Datensätze in einer bestimmten Spalte |
|
SUMME |
Addiert alle Werte in einer bestimmten Spalte zusammen |
|
MIN |
Gibt den niedrigsten Wert in einer bestimmten Spalte zurück |
|
MAX |
Gibt die höchsten Werte in einer bestimmten Spalte zurück |
|
AVG |
Gibt den Durchschnittswert für eine ausgewählte Gruppe zurück |
Q13: Was ist der letzte Film, der in der Tabelle gespeichert ist?
SQL-Abfrage: SELECT title AS latest_movie, MAX(release_year) AS released_in FROM films;
Ergebnis:
|
latest_movie |
released_in |
|
|
1 |
Inception |
2010 |
SQL-Aggregatfunktionen aggregieren über eine ganze Spalte. Was aber, wenn du nur einen Teil einer Spalte aggregieren willst? Du möchtest zum Beispiel die Anzahl der Filme zählen, die in einem Jahr veröffentlicht werden.
An dieser Stelle brauchst du eine GROUP BY-Klausel. Mit GROUP BY kannst du Daten in Gruppen unterteilen, die dann unabhängig voneinander aggregiert werden können.
Q13: Zähle die Anzahl der Filme, die in einem Jahr veröffentlicht werden.
SQL-Abfrage: SELECT release_year, COUNT(*) AS number_of_movies FROM films GROUP BY release_year;
Ergebnis:
|
release_year |
number_of_movies |
|
|
1 |
1972 |
1 |
|
2 |
2008 |
1 |
|
3 |
1974 |
1 |
|
4 |
1993 |
1 |
|
5 |
1994 |
2 |
|
6 |
2003 |
1 |
|
7 |
1999 |
1 |
|
8 |
2010 |
1 |
|
9 |
1980 |
1 |
Bis jetzt haben wir immer nur mit einer Tabelle gearbeitet. Aber die wahre Stärke von Datenbanken und SQL liegt in der Möglichkeit, mit Daten aus mehreren Tabellen zu arbeiten.
Der Begriff "relationale Datenbank" in RDBMS kommt daher, dass die Tabellen innerhalb der Datenbank miteinander in Beziehung stehen. Sie haben gemeinsame Bezeichner, mit denen Daten aus mehreren Tabellen leicht kombiniert werden können. Hier verwenden wir SQL-Tabellen JOINS.
Sehen wir uns ein einfaches Beispiel an, um uns mit der JOIN-Syntax vertraut zu machen und etwas über die verschiedenen Arten von JOINS zu lernen.
Betrachten wir eine weitere Tabelle mit dem Namen "movieDirectors", die die Namen der Regisseure für einige der Filme enthält, die wir in der Tabelle "films" haben.
|
title |
director |
|
|
1 |
Der Pate |
Francis Ford Coppola |
|
2 |
Der Pate: Teil II |
Francis Ford Coppola |
|
3 |
Der Pate: Teil III |
Francis Ford Coppola |
|
4 |
Schindlers Liste |
Steven Spielberg |
|
5 |
The Dark Knight Rises |
Christopher Nolan |
Wir könnten die Daten in diesen beiden Tabellen mit einem gemeinsamen Bezeichner kombinieren: "Titel".
Q14: Füge der Tabelle "Filme" eine Spalte hinzu und fülle sie mit dem Namen des Regisseurs aus der Tabelle "movieDirectors".
Syntax: SELECT leftTable.column1, rightTable.column1, leftTable.column2.... FROM leftTable INNER JOIN rightTable ON leftTable.commonIdentifier = rightTable.commonIdentifier;
SQL-Abfrage: Select films.title, films.release_year, movieDirectors.director FROM films INNER JOIN movieDirectors ON films.title = movieDirectors.title
Ergebnis:
|
title |
release_year |
director |
|
|
1 |
Der Pate |
1972 |
Francis Ford Coppola |
|
2 |
Der Pate: Teil II |
1974 |
Francis Ford Coppola |
|
3 |
Schindlers Liste |
1993 |
Steven Spielberg |
|
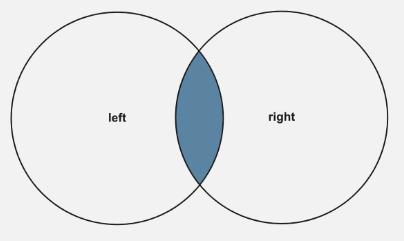
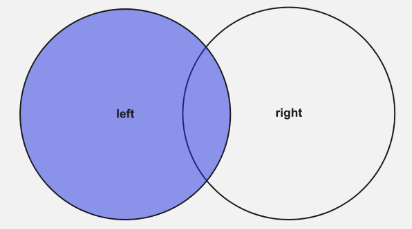
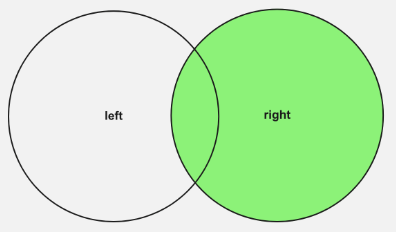
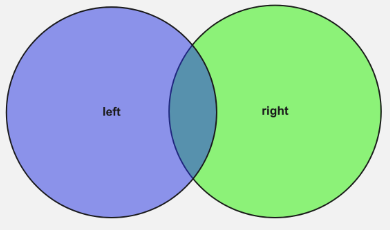
JOIN |
Beschreibung |
Diagramm |
|
Innere Verbindung |
Gibt nur die Datensätze zurück, die in beiden Tabellen übereinstimmende Werte haben |
|
|
Linker (äußerer) Join |
Gibt alle Datensätze aus der linken Tabelle und die übereinstimmenden Datensätze aus der rechten Tabelle zurück |
|
|
Rechter (äußerer) Join |
Gibt alle Datensätze aus der rechten Tabelle und die übereinstimmenden Datensätze aus der linken Tabelle zurück |
|
|
Voller (äußerer) Join |
Gibt alle Datensätze zurück, wenn es eine Übereinstimmung in der linken oder rechten Tabelle gibt |
|
In der Beispielabfrage oben ist "films" die linke Tabelle und "movieDirectors" die rechte Tabelle. Mit dem INNER JOIN, den wir durchgeführt haben, erhielten wir also nur Filme zurück, die in beiden Tabellen vorhanden waren. Die Ergebnismenge war eine Schnittmenge der beiden Tabellen.
Mit SQL JOINS kannst du zwei Datensätze nebeneinander kombinieren. Aber mit SQL UNION kannst du einen Datensatz über den anderen stapeln. Der UNION-Operator wird verwendet, um die Ergebnismenge von zwei oder mehr SELECT-Anweisungen zu kombinieren, wenn die folgenden "Regeln" erfüllt sind:
Syntax: SELECT spalten_name(s) FROM tabelle1 UNION ALL SELECT spalten_name(s) FROM tabelle2;
Betrachten wir die Tabelle "movies_2000s":
|
title |
release_year |
budget |
brutto |
imdb_score |
|
|
1 |
Inception |
2010 |
160000000 |
292568851 |
8.8 |
|
2 |
Der Prozess gegen die Chicago 7 |
2020 |
35000000 |
7.7 |
Wenn wir nun die beiden Tabellen kombinieren würden...
SQL-Abfrage: SELECT title FROM films UNION SELECT title FROM movies_2000s;
Ergebnis:
|
title |
|
|
1 |
Der Pate |
|
2 |
Der dunkle Ritter |
|
3 |
Der Pate: Teil II |
|
4 |
Schindlers Liste |
|
5 |
Pulp Fiction |
|
6 |
Der Herr der Ringe: Die Rückkehr des Königs |
|
7 |
Fight Club |
|
8 |
Inception |
|
9 |
Star Wars: Episode V - Das Imperium schlägt zurück |
|
10 |
Die Verurteilten - Die Erlösung |
|
12 |
Der Prozess gegen die Chicago 7 |
Du hast vielleicht bemerkt, dass "Inception" nur einmal in der Ergebnisliste auftaucht. Das liegt daran, dass UNION nur eindeutige Werte auswählt; wenn du alle Werte haben willst, kannst du UNION ALL verwenden.
SQL kann mit Daten wahre Wunder vollbringen. Verschachtelte Abfragen sind ein weiteres Werkzeug, das SQL zu einer Sprache macht, die man kennen sollte. Eine verschachtelte Abfrage ist nichts anderes als eine Abfrage innerhalb einer Abfrage (so ähnlich wie die Träume in Inception!)
Mit verschachtelten Abfragen kannst du sehr komplizierte Operationen in mehreren Schritten durchführen, ohne dass der Code unleserlich oder unverständlich wird.
Q15: Bestimme die durchschnittliche Rentabilität der Filme in der Tabelle "Filme".
Hint: Du hast die Rentabilität vorhin mit Q3 berechnet. Jetzt musst du das Ergebnis dieser Abfrage nehmen und die AVG-Funktion darauf anwenden.
SQL Nested Query:
SELECT AVG(*) AS average_profit FROM
(SELECT title, (brutto - budget) AS movie_profit FROM films where gross > budget);
Wir haben den negativen Wert von "Fight Club" in der Berechnung innerhalb der inneren SQL-Abfrage entfernt, indem wir Brutto > Budget hinzugefügt haben.
In der obigen verschachtelten Abfrage wird zuerst die innere Abfrage ausgeführt und dann wird diese Ergebnismenge als temporäre Tabelle für die äußere Abfrage verwendet, um Daten abzufragen und zu erhalten.
Wir werden nicht zu sehr auf das Thema verschachtelte SQL-Abfragen eingehen. Wir empfehlen dir aber dringend, den DataCamp-Kurs Intermediate SQL zu besuchen, um SQL-Abfragen zu beherrschen. Du spielst mit der europäischen Fußballdatenbank und lernst dabei mehr über verschachtelte Abfragen. Du wirst auch etwas über CASE-Anweisungen und Fensterfunktionen lernen - Themen, die wir in diesem SQL-Abfrage-Tutorial nicht behandeln konnten.
Du hast eine Menge über SQL-Abfragen gelernt und bist in einer guten Position, um deine Reise mit der Lösung von realen Problemen mit SQL zu beginnen. In diesem SQL-Abfrage-Tutorial hast du gelernt, was eine SQL-Abfrage ist und wie man SQL-Abfragen schreibt.
Du hast die Abfragesyntax gesehen und dabei einige Fragen beantwortet. Wir haben mit einfachen SQL-Abfragebeispielen mit SELECT - FROM - WHERE-Anweisungen begonnen und uns dann zu etwas komplexeren SQL-Abfragen mit Joins, Union und verschachtelten Abfragen vorgearbeitet.
Wir haben im Tutorial viel behandelt, aber das ist KEINE erschöpfende Liste aller möglichen einfachen und fortgeschrittenen SQL-Abfragen - es gibt noch mehr. Außerdem empfehlen wir dir, den Lernpfad SQL Fundamentals von DataCamp zu besuchen, um ein tieferes und umfassenderes Verständnis von SQL zu erlangen.
Denke daran, dass Übung der Schlüssel zur Beherrschung jeder Fähigkeit ist und SQL ist da keine Ausnahme! Mit Practise kannst du deine SQL-Kenntnisse vom Anfänger bis zum Fortgeschrittenen verbessern.
Also, leg los und viel Spaß beim Querying!
Kurse für SQL
Kurs
Kurs