
Lernpfad
Datenwissenschaftler/in in Python
26 Std.
Egal, ob du Student, angehender Datenwissenschaftler oder Profi bist, der sich beruflich verändern will – wenn du ein erfahrener Datenwissenschaftler werden willst, musst du einen bestimmten Weg einschlagen. Das ist nicht immer einfach, weil das Feld der Datenwissenschaft ziemlich breit geworden ist und es deshalb verschiedene Arten von Datenwissenschaftlern mit unterschiedlichen Aufgaben und Fähigkeiten gibt.
Um dir einen Überblick über den Bereich Data Science zu geben, zeigt dieser Artikel, welche Jobs zu deinen Ambitionen passen könnten. Außerdem gibt es Tipps, wie man in verschiedene Rollen in diesem Bereich einsteigen oder sich in diese hinein entwickeln kann, und beantwortet Fragen wie: Welche Fähigkeiten solltest du entwickeln und mit welchen Methoden solltest du dich vertraut machen?
Lass uns mit unserer Roadmap für Data Science loslegen.
In diesem Artikel schauen wir uns alle Aspekte der Roadmap genauer an. Wenn du aber nur schnell wissen willst, worum es geht, findest du hier eine kurze Zusammenfassung:
Wenn du diesen Plan befolgst, kannst du dich effektiv in der Welt der Datenwissenschaft zurechtfinden, wichtige Fähigkeiten aufbauen und eine lohnende Karriere in diesem Bereich verfolgen.
Um den Kontext einer Data-Science-Roadmap zu verstehen, muss man wissen, was Data Science eigentlich ist. Wir haben einen kompletten Leitfaden mit Definitionen und Erklärungen zum Thema Data Science, aber für diesen Artikel betrachten wir Data Science einfach als die Gesamtheit der Aktivitäten, die darauf abzielen, Probleme mithilfe von Daten zu lösen.
Ein echt häufiges Problem ist: „Ich hab 'ne Frage, aber keine Ahnung, wie die Antwort lautet.“ Wenn du also 'ne SQL-Abfrage auf 'ne Verkaufsdatenbank machst, um rauszufinden, wie viel Umsatz 'ne Organisation letzten Monat gemacht hat, bist du 'n Datenwissenschaftler!
Oft sind die Probleme/Lösungen komplexer und erfordern vielfältigere Fähigkeiten. Um die vielen verschiedenen Rollen und Fähigkeiten in der Datenwissenschaft in dieser Roadmap zu besprechen, nehmen wir den Lebenszyklus eines Datenwissenschaftsprojekts als Grundlage. So können wir die verschiedenen Aktivitäten und Rollen abbilden und haben eine Basis, um die Bereiche der Datenwissenschaft zu strukturieren.
Data-Science-Projekte fangen meistens mit einer geschäftlichen Frage oder einem Problem an. Ein Problem löst eine Startphase aus, in der man mögliche Lösungen findet und schaut, ob sie überhaupt machbar sind. Zuerst sammeln wir Daten oder schauen uns die vorhandenen Daten an, um zu sehen, was geht und was nicht. Sind die Daten ausreichend umfangreich? Hat es genug Funktionen?
Sobald alle Ampeln auf Grün stehen, fangen wir an, ein Vorhersagemodell zu entwickeln. Das Modell nutzt die Eingaben, um die Ergebnisse vorherzusagen. Zuerst könnte das nur ein einmaliges Modell sein, das auf einem k-fachen Kreuzvalidierungssatz trainiert, getestet und validiert wurde (eine Technik des maschinellen Lernens, um zu beurteilen, wie gut ein Modell bei unbekannten Daten wahrscheinlich funktioniert). Das ist die Arbeit, die normalerweise von klassischen Datenwissenschaftlern gemacht wird. Sobald das Modell gut genug läuft, ist es Zeit, es in die Produktion zu bringen und in die bestehende Infrastruktur einzubauen, wo die Leistung überwacht wird und das Modell bei Bedarf neu trainiert wird.
Jede dieser Phasen braucht unterschiedliche Fähigkeiten. In der Anfangsphase sollten die Leute Geschäftssinn haben und sich mit Datenumwandlung, Datenbereinigung, deskriptiver Statistik und grundlegender inferentieller Statistik auskennen. Das ist 'ne Aufgabe, die ein Datenanalyst oder ein Datenwissenschaftler machen kann.
In der Modellierungsphase müssen Vorhersagemodelle erstellt werden. Einfache Modelle, wie zum Beispiel Regressionen, kann ein Datenanalyst erstellen. Wenn es aber komplizierter wird, braucht man einen Datenwissenschaftler, der ein Modell mit einem vorhandenen Algorithmus erstellt, oder sogar einen Machine-Learning-Ingenieur, der aktuelle Algorithmen anpasst oder neue entwickelt.
Wenn du das Modell einsetzt und in Betrieb nimmst, bist du im Bereich des Machine Learning Engineers oder des Data Engineers. Im Gegensatz zu den früheren Phasen gibt's nicht unbedingt eine enge Verbindung zum Geschäft, und die Aufgabe bestand darin, eine Pipeline rund um das Vorhersagemodell zu erstellen und zu überwachen, um zuverlässige Ergebnisse für die richtigen Zielsysteme zu liefern.
Während des ganzen Prozesses sollten alle Daten an den richtigen Stellen mit den richtigen Metainformationen verfügbar sein, und das ist die Aufgabe des Datenarchitekten. Wenn neue Daten reinkommen oder alte Daten in neue Infos umgewandelt werden, sorgen sie auch dafür, dass die Daten am richtigen Ort landen.
Wie die verschiedenen Rollen in den unterschiedlichen Phasen des Lebenszyklus dazu beitragen, siehst du in der Abbildung unten. Weil verschiedene Rollen in unterschiedlichen Phasen wichtig sind, braucht man auch unterschiedliche Fähigkeiten.
Die Aufgaben am Anfang des Lebenszyklus brauchen mehr Geschäftssinn und weniger Technik, während man in späteren Phasen weniger Geschäftssinn braucht, dafür mehr Technik und Optimierung der Algorithmen. Um das zu zeigen: Als Datenwissenschaftler kannst du mit einer nicht optimalen Rechenleistung auskommen, um den Wert und die Leistung deines Modells zu zeigen. Sobald du aber für die Produktion von Modellen verantwortlich bist, musst du die Rechenkomplexität optimieren können, um sicherzustellen, dass deine Pipeline (kosten-)effizient ist.
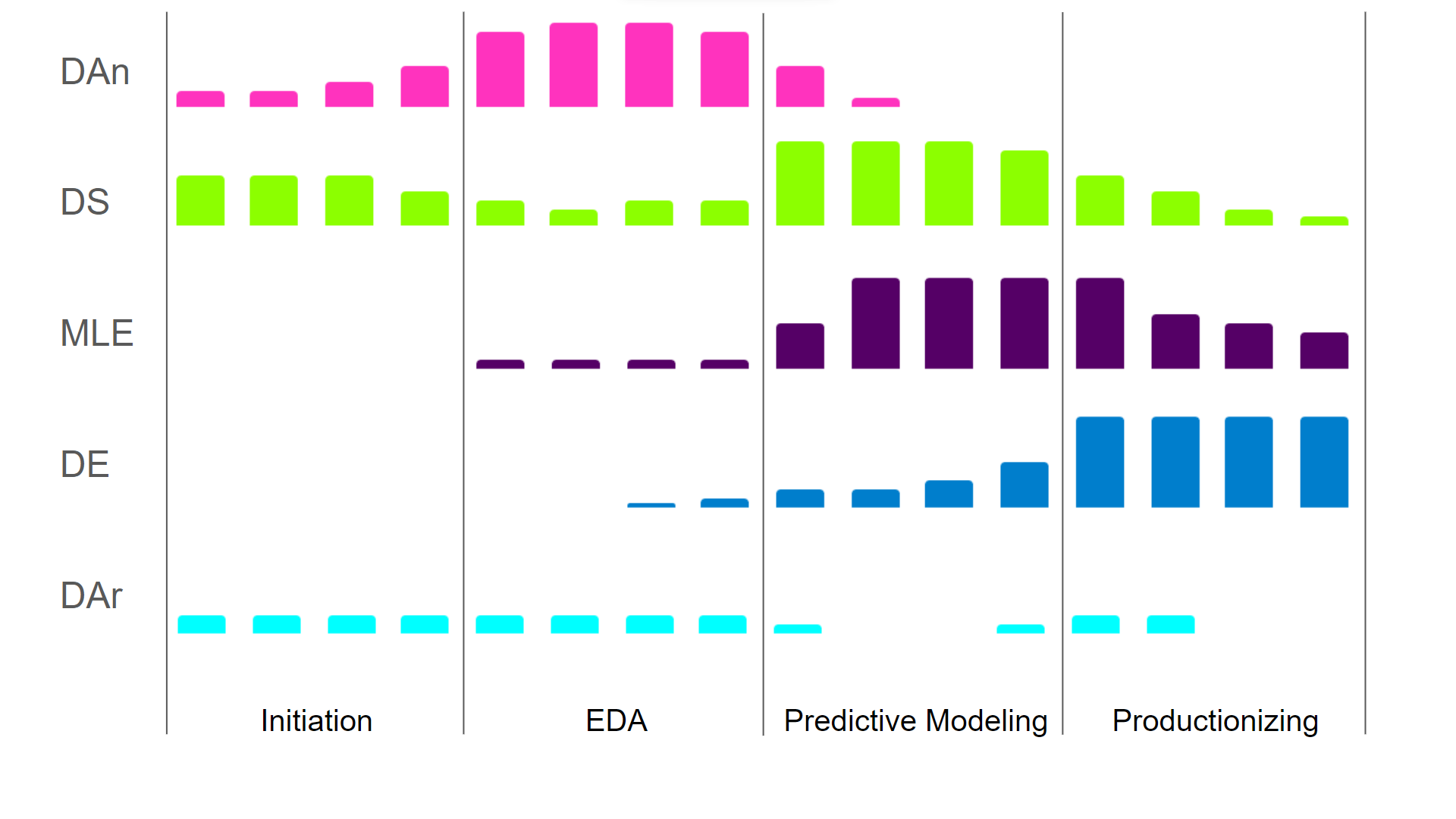
Der Beitrag der verschiedenen Data-Science-Rollen in einem Data-Science-Projekt (DAn – Datenanalyst, DS – Datenwissenschaftler, MLE – Machine-Learning-Ingenieur, DE – Dateningenieur, DAr – Datenarchitekt – Bild vom Autor
Man sollte wissen, dass die Rollen nicht streng voneinander getrennt sind. Viele Datenwissenschaftler denken schon an die richtigen Quell-/Zielsysteme und die Recheneffizienz und berücksichtigen diese in ihrem Code. Ein Machine-Learning-Ingenieur könnte merken, dass bestimmte Ansätze zur Merkmalsgenerierung die Modellleistung verbessern könnten. Ein Datenanalyst kann dir vielleicht gute Tipps geben, wo du die für den Datenarchitekten erstellten Funktionen im Datenkatalog speichern solltest. Mit anderen Worten: Alle Rollen sollten ein bisschen wissen, was die anderen Rollen machen, aber sie müssen nicht unbedingt genau verstehen, was die Aufgaben der anderen sind.
Was die Fähigkeiten und Werkzeuge angeht, die du brauchst, gibt's eine klare Grundlage. Egal, wo du im Lebenszyklus eines Data-Science-Projekts mitmachst, du solltest ein paar Grundkenntnisse in Mathe und Statistik, kollaborativer Softwareentwicklung und Datenbearbeitung haben. Im Großen und Ganzen fängt jede Roadmap für Data Science mit folgenden Schritten an:
Es gibt verschiedene Arten von Jobs in der Datenwissenschaft mit unterschiedlichen Anforderungen an die Fähigkeiten: Ein Datenanalyst braucht tiefere Kenntnisse in SQL als ein Dateningenieur. Ein Datenwissenschaftler muss sich mit maschinellem Lernen besser auskennen als ein Datenarchitekt. Hier teilt sich also der Weg in der Datenwissenschaft: Je nachdem, was du in der Datenwissenschaft erreichen willst, musst du verschiedene Fähigkeiten lernen. In den nächsten Abschnitten werden die verschiedenen Zweige der Roadmap beschrieben, die man sich vorstellen kann.
Egal, wie weit du auf deinem Weg in der Datenwissenschaft schon bist, ob du ein alter Hase bist oder gerade erst anfängst – alle Datenwissenschaftsprojekte fangen damit an, dass du deine Daten verstehst.
Ein gründliches Verständnis deiner Daten ist super wichtig, um zu sehen, ob dein Projekt machbar ist. Angefangen bei einfachen Fragen wie „Welche Variablen habe ich?“ und „Wie viele Beobachtungen habe ich?“ bis hin zu komplexeren Fragen wie „Wie hängen die Variablen zusammen?“
Oft sind die Ergebnisse einer EDA schon die Antwort auf die Fragen deiner Stakeholder. Wenn die Ergebnisse einer einfachen Datenanalyse richtig dargestellt und zum Beispiel in einem Dashboard übersichtlich präsentiert werden, kann man damit auch komplizierte Fragen beantworten. Das hängt aber echt von den Fähigkeiten in der Datenvisualisierung ab.
Aber schon wenn du mit deiner EDA zeigst, dass es zum Beispiel verschiedene Gruppen von Website-Besuchern gibt, hast du einen wertvollen Beitrag als Datenwissenschaftler geleistet.
Es gibt viele Möglichkeiten, deine Ergebnisse zu zeigen. Entweder in Visualisierungsbibliotheken/-paketen in der Sprache, die du benutzt (wie R's ggplot2 und Python's matplotlib), oder in speziellen Datenvisualisierungstools (wie PowerBI, Tableau oder sogar Excel).
Besonders wenn wir uns mehr auf die Aufgaben eines Datenanalysten konzentrieren, ist es echt hilfreich, ein tieferes Verständnis von Datenvisualisierung zu haben.
Bei den meisten Jobs im Bereich Data Science kann man mit Visualisierungen Annahmen anhand von Streudiagrammen und Histogrammen überprüfen. Wenn aber die Analyse selbst das Ergebnis ist, wie zum Beispiel bei einem Datenanalysten, kommt es vor, dass man die Analyseergebnisse leicht verständlich machen will.
Denk mal an individuelle Hausstile, neue Visualisierungen oder Infografiken, die als Input für eine Entscheidungseinheit dienen können. In solchen Situationen ist es echt hilfreich, wenn man eine Datenvisualisierung erstellen kann, die fast schon ein Kunstwerk ist. Der Kurs „Datenvisualisierung verstehen “ hilft dir echt dabei, deine Datenvisualisierungskenntnisse zu verbessern.
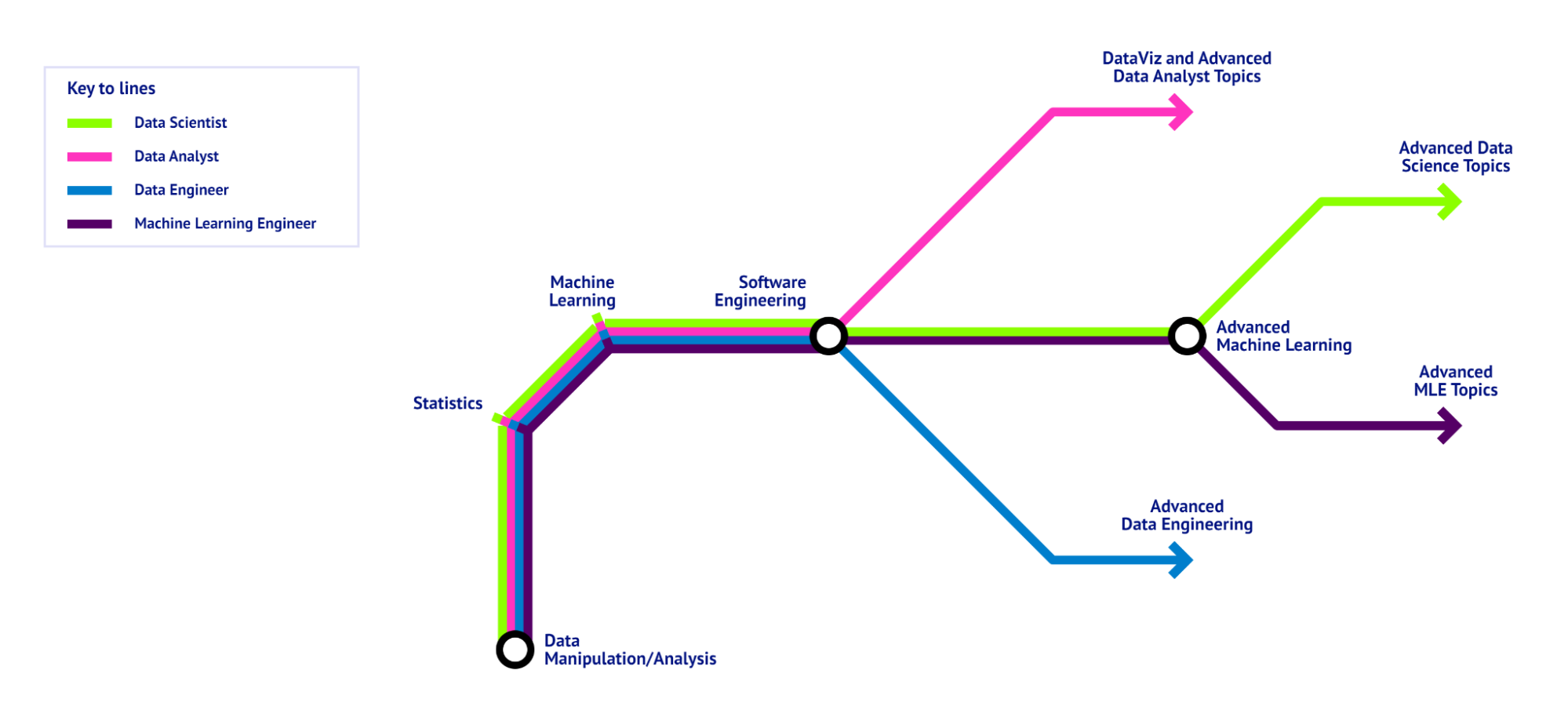
Eine Datenwissenschafts-Roadmap, die wie ein U-Bahn-Plan aussieht und die Grundlagen zeigt, die alle Datenwissenschaftsrollen gemeinsam haben, sowie die spezifischen Fähigkeiten für die verschiedenen Rollen. – Bild vom Autor
Ein weiterer erster Schritt auf dem Weg zur Datenwissenschaft ist die Statistik. Ein paar grundlegende Statistikkonzepte sollten für jeden Datenwissenschaftler selbstverständlich sein.
Du musst jederzeit in der Lage sein, deine Daten und Untergruppen in deinen Daten zu beschreiben. Wie hoch ist das durchschnittliche Einkommen in deinem Datensatz? Was sind die Mindest- und Höchsteinkommen? Was ist die Standardabweichung oder welche anderen Streuungsmaße gibt es? Und wenn du kategoriale Werte hast, wie viele eindeutige Werte gibt es? Was kommt am häufigsten vor? Kommen alle Werte gleich oft vor oder ist es nicht so gleichmäßig verteilt?
Die Beantwortung von Fragen mit beschreibenden Analysen über Gruppen/Untergruppen kann schon wertvolle Erkenntnisse liefern, aber meistens muss man sich die Beziehung zwischen den Variablen in deinem Datensatz anschauen und sich in Richtung inferentieller Statistik bewegen.
Das Spannende und Interessante an der inferentiellen Statistik sind die verschiedenen Arten von kategorialen und numerischen Werten und die Beziehungen zwischen ihnen. Beispiele dafür sind:
Um diese Fragen beantworten zu können, musst du die verschiedenen Arten von statistischen Tests kennen, vom einfachsten T-Test bis hin zu komplexeren Methoden wie multivariaten linearen Regressionen oder Zeitreihenanalysen.
Du kannst entsprechende Kurse belegen, um dein Verständnis von Statistik zu vertiefen in: Python, R und sogar unabhängig von Tools. Diese Kurse bieten eine gute Basis, um mit maschinellem Lernen loszulegen. Wenn du die Beziehung zwischen Prädiktoren und Zielvariablen statistisch verstehst, verstehst du auch die Prinzipien der Algorithmen, die für überwachte Lernmodelle verwendet werden.
Wie tief du dich in diesen Bereich reinsteigst, hängt wieder davon ab, wo du auf deiner Data-Science-Roadmap hinwillst. Wenn du Datenanalyst werden willst, reicht es vielleicht, die Grundlagen der Statistik zu verstehen. Datenarchitekten brauchen vielleicht gar keine Statistikkenntnisse. Aber Datenwissenschaftler und Machine-Learning-Ingenieure werden auf jeden Fall Situationen erleben, in denen sie sich auf ihr statistisches Fachwissen verlassen müssen.
Datenwissenschaft dreht sich um Zahlen und Berechnungen, deshalb ist Mathe echt wichtig. Auch wenn ein fortgeschrittener Abschluss in Mathe nicht unbedingt nötig ist, um in der Datenwissenschaft durchzustarten, hilft dir das Verständnis von Algebra und Analysis dabei, viele Methoden zu kapieren, die in der Datenwissenschaft oft benutzt werden. Die meisten Methoden zur Dimensionsreduktion (wie PCA und Matrixfaktorisierung) basieren auf linearer Algebra, und viele Optimierungsalgorithmen (wie Gradientenabstieg) basieren auf Analysis.
Und genau wie bei Statistiken und Datenanalysen ist dieses Wissen nicht unbedingt für alle Jobs im Bereich Data Science wichtig. Wenn du vorhast, Machine-Learning-Ingenieur zu werden, kommst du um Mathe nicht rum. Aber die meisten anderen Jobs – sogar als Datenwissenschaftler – kann man vielleicht auch machen, ohne sich mit Algebra und Analysis auszukennen.
Wenn du mehr über algebraische Konzepte erfahren und sie besser verstehen willst, schau dir unseren Kurs „Lineare Algebra für Data Science in R” an.
Maschinelles Lernen ist die Kunst, Software zu entwickeln, die aus Daten lernt. Das ist echt das A und O für Datenwissenschaftler, Machine-Learning-Ingenieure und sogar Dateningenieure. Der Teil deiner Lösung, der die erwarteten Umsatzerlöse für dein Unternehmen liefert, basierend auf deinem Lagerbestand und deinen Preisen? Das wird durch maschinelles Lernen gemacht!
Das Minimum an Wissen, das du als Datenwissenschaftler brauchst, ist die Fähigkeit, Modelle zu trainieren und zu bewerten. In manchen Fällen willst du vielleicht tiefer einsteigen und lernen, wie du bestehende Algorithmen anpassen oder sogar neue Algorithmen schreiben kannst, und so in den Bereich des Machine-Learning-Ingenieurs einsteigen.
Du hast viel Freiheit bei der Gestaltung deines maschinellen Lernens. Du kannst entweder alles selbst programmieren (in Python, R, C# oder Java mit den entsprechenden Bibliotheken), lokale Softwarepakete (wie Weka und RapidMiner) nutzen oder Cloud-Lösungen (wie Databricks und AWS SageMaker) verwenden. Das macht es zwar schwierig zu entscheiden, was man lernen soll, aber das Fachwissen, das man sich aneignet, lässt sich ziemlich leicht übertragen. Eine gute Idee, um zu entscheiden, welches Toolkit für maschinelles Lernen du verwenden solltest, wäre, entweder mit einer Sprache zu beginnen, die du schon kennst, oder zu schauen, welche Tools in der Branche, die dich interessiert, verwendet werden.
Du kannst mit unserem Karrierepfad „Machine Learning Scientist mit Python“ loslegen, der viele der Grundlagen abdeckt, die du für den Start deiner Karriere brauchst.
Die Beziehung zwischen maschinellem Lernen, Deep Learning und KI ist umstritten.
Als ich noch Maschinenlernen unterrichtete, war meine erste Vorlesung immer eine lebhafte Diskussion über die Aussage „Maschinenlernen ist eine Form der KI“. Auch wenn die Begriffe manchmal verwechselt werden, bin ich fest davon überzeugt, dass maschinelles Lernen KI ermöglicht, aber das heißt nicht, dass man KI geschaffen hat, wenn man maschinelles Lernen einsetzt.
Damit eine Datenanwendung zu KI wird, muss es unbedingt eine Feedbackschleife geben, in der die Anwendung oder das Modell aus ihren bzw. seinen Ergebnissen lernt. In diesem Fall ist ein einmaliger überwachter Lernalgorithmus nicht unbedingt KI. Wenn du die Ergebnisse des Modells wieder ins Modell reinpackst (wie beim Reinforcement Learning), bekommst du tatsächlich KI, weil du dann ein System hast, das ständig aus seinen richtigen und falschen Vorhersagen lernt.
Deep Learning ist im Grunde genommen nichts anderes als neuronale Netze auf Steroiden. Was Deep Learning so interessant macht, ist, dass es echt greifbare Ergebnisse liefert, weil diese Modelle Texte, Bilder und Sprache ausgeben können. Wenn du an einem Data-Science-Projekt arbeitest, bei dem es wichtig ist, dass die Modelle etwas liefern, das von den Endnutzern wahrgenommen oder erlebt werden kann, kann es echt hilfreich sein, Deep Learning zu verstehen. Ein super Kurs für den Einstieg ist „Einführung in Deep Learning mit Python“.
Keine Datenwissenschaftsarbeit passiert einfach so aus dem Nichts. Während du deinen Weg weitergehst, ist es wichtig, die Artefakte, die du erstellst, aufzubewahren und zu präsentieren. Ein wichtiger Teil der Arbeit als Datenwissenschaftler ist, zu zeigen, was du drauf hast.
Für mich ist das Coolste an der Datenwissenschaft, dass man nicht viel braucht. Du brauchst nur einen öffentlichen Datensatz und ein bisschen Kreativität, um eine interessante Frage zu finden und diese dann mit den Daten zu beantworten. Oder du kannst einfach bei DataLaboder Kaggle vorbeischauen und mit den Aufgaben und/oder Wettbewerben loslegen, wobei du dich von anderen Beiträgen inspirieren lassen kannst.
Du kannst auch deine eigenen Daten sammeln und nutzen. Ich hab meine von Strava runtergeladenen Fahrraddaten angeschaut und Immobilieninfos gesammelt, um mich bei der Suche nach einer Wohnung zu unterstützen.
Das Wichtigste ist, dass du dokumentierst, was du machst. Versuche, deine Arbeit reproduzierbar zu machen, erkläre die Schritte, die du unternommen hast, teile deinen Code und teile die Ergebnisse deiner Analyse oder deines Systems. Wer weiß? Vielleicht ist deine Übungsaufgabe genau die richtige Lösung für das Problem von jemandem.

Ich finde, die spannendsten Projekte sind die, die aus deiner eigenen Leidenschaft und deinen Interessen entstehen. Wenn du einen Datensatz von einem Ort nimmst, den du gut kennst, kannst du wahrscheinlich einzigartige und interessante Fragen stellen. Du kennst die Domain und du kennst die Daten... Aber wenn du wirklich ganz von vorne anfängst, gibt es jede Menge Sachen, mit denen du anfangen kannst, zum Beispiel Dating-Apps, Trading und Sport.
Auf DataCamp findest du auch eine riesige Auswahl an Data-Science-Projekten, mit denen du dich mit der Art der Arbeit vertraut machen kannst. Egal, ob du mit ein paar Datenanalyseprojekten anfängst oder an bestimmten Python-Projekten arbeitest, du kannst dich bis hin zu Machine-Learning- und sogar KI-Projekten hocharbeiten. Es gibt viele Möglichkeiten, die dir den Einstieg erleichtern.
Wenn du trotz allem, was da ist, keinen Einstieg findest, könnte die Teilnahme an Hackathons eine weitere nützliche Alternative sein. Viele Forschungsinstitute und größere Firmen machen regelmäßig Hackathons.
Bei diesen Hackathons geht's oft darum, dass Teams von Datenwissenschaftlern sich mit einem bestimmten Problem beschäftigen. So kann man mit anderen Datenwissenschaftlern zusammenarbeiten und von ihnen lernen. So kannst du dir ein Netzwerk aufbauen, von potenziellen Arbeitgebern entdeckt werden und gleichzeitig wertvolle Erfahrungen sammeln.
Heutzutage kann man sich kaum noch einen Datenwissenschaftler vorstellen, der kein GitHub-, DataCamp-Portfolio oder keine Medium-Seite oder keinen Blog mit Code hat. Ein Portfolio ist in der Datenwissenschaft genauso wichtig wie in anderen kreativen Branchen.
Wenn du frühere Projekte zeigen kannst, ist das eine super Möglichkeit, Leute davon zu überzeugen, dass du das Zeug dazu hast. Deshalb lohnt es sich, deine Arbeit in einem Portfolio zu dokumentieren. Du kannst deine Arbeit und deine Standpunkte auch als Blogbeiträge oder sogar als wissenschaftliche Publikationen festhalten. Schau dir unseren Beitrag zum Thema „Präsentieren deiner Datenkompetenz mit einem Portfolio“ an, um dich inspirieren zu lassen.
Egal, wofür du dich entscheidest, pass auf, dass du einen guten Überblick über die Projekte behältst, an denen du gearbeitet hast.
Dieser ganze Beitrag hat die verschiedenen Fähigkeiten, Kenntnisse und Tools aufgezeigt, die einem Datenwissenschaftler zur Verfügung stehen. Aber wo soll man anfangen, wenn man sich für einen Beruf entscheidet?
Ich denke, das kommt echt drauf an, wo deine Ziele liegen. Dieser Beitrag sollte bisher klar gemacht haben, dass ich nicht glaube, dass es eine einheitliche Roadmap für die Datenwissenschaft gibt.
Natürlich basiert jede Rolle im Bereich Data Science auf den Grundlagen der Statistik, Datenbearbeitung, des maschinellen Lernens und der Softwareentwicklung. Aber ansonsten kommt es echt drauf an.
Ein Datenwissenschaftler nutzt Algorithmen, während ein Machine-Learning-Ingenieur Algorithmen verändert oder erstellt. Der Datenwissenschaftler muss also einfach nur viele Algorithmen kennen und wissen, wann er sie anwendet, während der Machine-Learning-Ingenieur die mathematischen Konzepte hinter den Algorithmen wirklich verstehen muss.
Genauso, wenn du deine Energie aus dem Teilen von Analyseergebnissen ziehst, wie zum Beispiel als Datenwissenschaftler oder Datenanalyst, wirst du wahrscheinlich mehr von gründlichen Kenntnissen in Datenvisualisierung und EDA profitieren als davon, super gut in Datenmodellierung zu sein.
Die Roadmap für Data Science hat also einige Verzweigungen, und du kannst selbst entscheiden, wie tief du in die verschiedenen Bereiche der Data Science einsteigen möchtest.
Auch wenn die Jobs unterschiedlich sind, wirst du in jedem Vorstellungsgespräch auf deine Hard und Soft Skills geprüft. Diese Tests sind je nach der Stelle, die du anstrebst, unterschiedlich.
Wenn du nicht nach einer Stelle als Machine Learning- oder Dateningenieur suchst, wirst du wahrscheinlich nicht gefragt werden: „Wie würdest du den Algorithmus A oder B optimieren?“. Deshalb ist es wichtig, sich auf die Fähigkeiten und damit auf die Fragen zu konzentrieren, die von dir erwartet werden und an denen du arbeiten möchtest. Wenn du Fragen zu Themen bekommst, mit denen du nicht vertraut bist, könnte das ein Zeichen dafür sein, dass die Stelle nicht zu dir passt.
Weil es in diesem ziemlich neuen Bereich, vor allem in Firmen, wo Daten noch ziemlich neu sind, viele falsche Vorstellungen darüber gibt, was Datenwissenschaftler sind oder was sie machen.
Ich weiß, dass ich mich für die Stelle als Datenwissenschaftler beworben habe, bei der der Interviewer die Begriffe „Datenwissenschaftler“ und „Maschinelles Lernen-Ingenieur“ durchgemischt hat. Es kann also gut sein, dass der Personalchef was falsch gemacht hat, wenn du Fragen bekommst, die du nicht beantworten kannst. Ein Dateningenieur sollte zum Beispiel fast nie gefragt werden, wie er das Stakeholder-Management in einem Projekt machen würde.
Zum Glück gibt's verschiedene Ressourcen, die dir bei der Vorbereitung auf Vorstellungsgespräche in diesem Bereich helfen, je nachdem, für welche Stelle du dich bewirbst:
Der Bereich der Datenwissenschaft ist echt dynamisch, und es ist wichtig, immer auf dem Laufenden zu bleiben, was die neuesten Trends angeht. Mit chatGPT ist generative KI zum Mainstream geworden, und es ist jetzt schwer, sich einen Datenwissenschaftler vorzustellen, der nicht wenigstens eine Ahnung von Token-Einbettungen und/oder Aufmerksamkeitsmodellen hat. Genauso kann man sich mit MLOps kaum vorstellen, dass ein Dateningenieur die Leistung und Abweichung von Modellen noch manuell checkt.
Mit diesem dynamischen Wachstum werden verschiedene Aspekte der KI wichtig. Im Moment wird den ethischen und rechtlichen Aspekten der KI viel Aufmerksamkeit geschenkt, wie man an mehreren akademischen und politischen Debatten sieht, die unter anderem zu neuen Regeln und Vorschriften geführt haben.
Egal, was die Regierungen in Sachen KI entscheiden, niemand will für den nächsten Skandal in der Datenwissenschaft verantwortlich sein. Der einzige Weg, das zu vermeiden, ist, sich der ethischen und rechtlichen Grenzen bewusst zu bleiben. Oder noch besser: Als Experte für Datenwissenschaft kannst du zu diesen Entwicklungen beitragen, indem du deinen Hintergrund nutzt und dir eine Meinung bildest und diese auch sagst.
Es gibt viele Möglichkeiten, auf dem Laufenden zu bleiben. Klar, es gibt DataCamp als Plattform, aber du kannst auch einfach anfangen, inspirierende Data-Science-Experten in deinem Bereich zu suchen und ihnen zu folgen. Schau mal, ob sie Blogs, X- oder Medium-Beiträge oder irgendwas anderes haben, wo du einen Eindruck davon kriegen kannst, wie sie die sich verändernde und dynamische Landschaft sehen.

Wie wir in diesem Artikel gezeigt haben, gibt's viele Ressourcen für alle, die im Bereich Data Science anfangen oder sich weiterentwickeln wollen. Wenn du ganz nah an der Quelle sein willst, kannst du dir auch technische Konferenzen wie NeurIPS, ICML oder KDD anschauen. Schau dir diese und weitere Veranstaltungen auf unserer Liste der Top-Data-Science-Konferenzen für 2026 an .
Auch wenn es viele Stationen auf dem Weg zur Datenwissenschaft gibt, gibt es nicht nur einen einzigen Weg dorthin. Um sich in der Welt der Datenwissenschaft zurechtzufinden, musst du 1) eine Vorstellung von dieser Welt haben (die du hoffentlich durch diesen Beitrag bekommst) und 2) deine Stärken, Schwächen und Interessen kennen, damit du entscheiden kannst, was du verfolgen möchtest.
Wenn du diese Voraussetzungen erfüllst, kannst du dich auf diesen Artikel verlassen, um dich in die richtige Richtung zu lenken und zu erfahren, auf welche Fähigkeiten du während deiner Ausbildung den Schwerpunkt legen solltest. Zum Glück gibt's ein paar hilfreiche Ressourcen, die dir den Einstieg erleichtern, wie zum Beispiel die Lernpfade von DataCamp, die dir die Fähigkeiten vermitteln, die du brauchst, um verschiedene Berufe zu erkunden:
Starte noch heute deine Reise in die Welt der Datenwissenschaft!
Lernpfad
Kurs
Kurs
Blog
Nathaniel Taylor-Leach
8 Min.
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nathaniel Taylor-Leach
Blog
Nisha Arya Ahmed
15 Min.
Tutorial
Matt Crabtree
Tutorial
Javier Canales Luna

