
Kurs
Datenbearbeitung in SQL
4 Std.
324.1K
In der SQL-Welt ist es echt wichtig, Daten aus mehreren Abfragen zusammenzufassen, und SQL hat dafür coole Funktionen wie „ UNION “ und „ UNION ALL “.
Wie du sehen wirst, ist es für eine effiziente Datenabfrage und -verwaltung unerlässlich, die feinen Unterschiede zwischen den Funktionen „ UNION “ und „ UNION ALL “ in SQL zu verstehen. Dieses Tutorial erklärt die wichtigsten Gemeinsamkeiten, Unterschiede und Anwendungsszenarien anhand von Begleitdatensätzen, damit du deine SQL-Abfragen optimieren kannst.
Der Hauptunterschied ist, dass „ UNION “ doppelte Datensätze entfernt, während „ UNION ALL “ alle Duplikate mit einbezieht. Dieser Unterschied ändert nicht nur die Anzahl der Zeilen im Abfrageergebnis, sondern wirkt sich auch auf die Leistung aus.
| Feature | UNION | UNION ALL |
|---|---|---|
| Duplikate | Entfernt doppelte Einträge | Bewahrt alle Unterlagen auf (auch die doppelten) |
| Leistung | Langsamer (muss Daten sortieren/hashen, um Duplikate zu finden) | Schneller (hängt die Daten einfach an das Ergebnis an) |
| Betrieb | Mengenlehre (Mathematische Vereinigung) | Ergebnisse anhängen / stapeln |
Schauen wir uns zwei Beispiel-Tabellen an: „ employees_2023 “ und „ employees_2024 “, die die Mitarbeiterdaten für zwei verschiedene Jahre zeigen.
SELECT *
FROM employees_2023|
Mitarbeiter-ID |
Name |
Abteilung |
|
1 |
Alice |
HR |
|
2 |
Bob |
IT |
|
3 |
Charlie |
Finanzen |
SELECT *
FROM employees_2024|
Mitarbeiter-ID |
Name |
Abteilung |
|
2 |
Bob |
IT |
|
3 |
Charlie |
Finanzen |
|
4 |
David |
Marketing |
Jetzt verbinden wir unsere beiden Tabellen mit der Funktion „ UNION “.
SELECT employee_id, name, department FROM employees_2023
UNION
SELECT employee_id, name, department FROM employees_2024;|
Mitarbeiter-ID |
Name |
Abteilung |
|
1 |
Alice |
HR |
|
2 |
Bob |
IT |
|
3 |
Charlie |
Finanzen |
|
4 |
David |
Marketing |
In diesem Ergebnis werden doppelte Einträge rausgeschmissen. Vergleichen wir das jetzt mit dem Ergebnis, das wir nach der Verwendung von „ UNION ALL “ bekommen.
SELECT employee_id, name, department FROM employees_2023
UNION ALL
SELECT employee_id, name, department FROM employees_2024;|
Mitarbeiter-ID |
Name |
Abteilung |
|
1 |
Lebendig |
HR |
|
2 |
Bob |
IT |
|
3 |
Charlie |
Finanzen |
|
2 |
Bob |
IT |
|
3 |
Charlie |
Finanzen |
|
4 |
David |
Marketing |
In diesem Ergebnis sind alle Datensätze dabei, und Duplikate werden nicht rausgefiltert.
Die Funktion „ UNION “ kombiniert die Ergebnisse von zwei oder mehr „ SELECT “-Abfragen zu einem einzigen Ergebnis und entfernt dabei doppelte Zeilen. Jede Anweisung „ SELECT “ innerhalb der Anweisung „ UNION “ muss die gleiche Anzahl von Spalten haben. Außerdem müssen sie ähnliche Datentypen haben, und die Spalten müssen auch in derselben Reihenfolge sein. Um die Funktion zu verstehen, erstellen wir unten zwei Beispiel-Tabellen.
CREATE TABLE sales_team (
employee_id INT,
employee_name VARCHAR(50)
);
INSERT INTO sales_team (employee_id, employee_name) VALUES
(1, 'Alice'),
(2, 'Bob'),
(3, 'Charlie');
CREATE TABLE support_team (
employee_id INT,
employee_name VARCHAR(50)
);
INSERT INTO support_team (employee_id, employee_name) VALUES
(3, 'Charlie'),
(4, 'David'),
(5, 'Eve');Der obige Code erstellt die beiden Tabellen, die wir in diesem Tutorial verwenden werden: „ sales_team “ und „ support_team “. Du kannst die Tabellen mit dem folgenden Code anzeigen.
SELECT *
FROM sales_team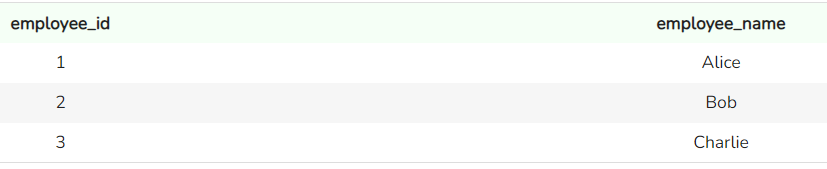
Datensätze in der Tabelle „sales_team“. Bild vom Autor
SELECT *
FROM support_team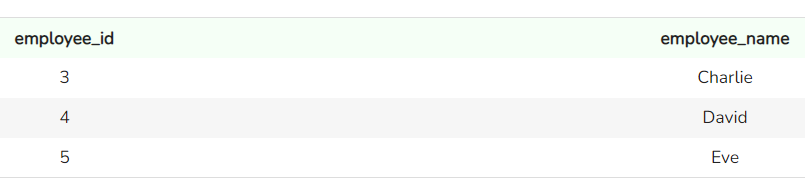
Einträge in der Tabelle „support_team“. Bild vom Autor
Das sind kleine Tabellen mit jeweils drei Datensätzen, und die Spaltennamen sind echt selbsterklärend. Jetzt, wo wir unsere beiden Tabellen erstellt haben, wenden wir die Funktion „ UNION “ an.
SELECT employee_id, employee_name
FROM sales_team
UNION
SELECT employee_id, employee_name
FROM support_team;
Ausgabe der UNION-Funktion. Bild vom Autor
Du kannst sehen, dass der doppelte Eintrag „ employee_id “, der den Wert „ 3 “ hat, entfernt wurde.
Hier sind ein paar typische Anwendungsfälle für die Funktion „ UNION “.
Ergebnisse aus verschiedenen Tabellen zusammenfassen: Wenn du Daten aus mehreren Tabellen zusammenführen und sicherstellen willst, dass keine doppelten Datensätze dabei sind, ist die Funktion „ UNION “ genau das Richtige.
Umgang mit verschiedenen Datenquellen: „ UNION ” ist super, wenn du Tabellen aus verschiedenen Datenquellen zusammenführen willst.
Duplikate über Abfragen hinweg entfernen: Wenn du sichergehen willst, dass die kombinierten Ergebnisse einzigartig sind, nimm „ UNION “.
Die Funktion „ UNION ALL “ kombiniert die Ergebnisse von zwei oder mehr „ SELECT “-Abfragen, inklusive aller doppelten Zeilen. Diese Funktion ist schneller als „ UNION “, weil sie keine Duplikate entfernt.
SELECT employee_id, employee_name
FROM sales_team
UNION ALL
SELECT employee_id, employee_name
FROM support_team;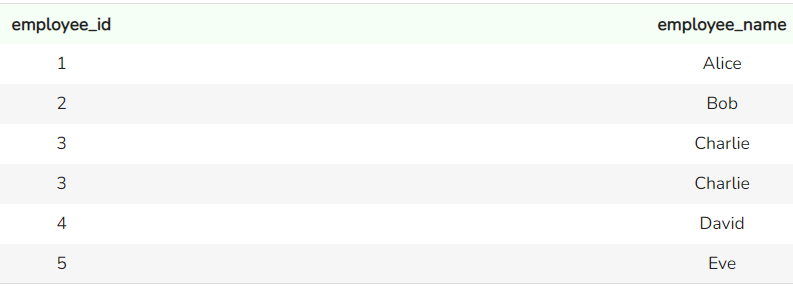
Ausgabe der Funktion UNION ALL. Bild vom Autor
Du siehst, dass in diesem Fall die doppelten Einträge wiederholt und nicht entfernt werden.
Hier sind ein paar typische Anwendungsfälle für die Funktion „ UNION ALL “.
UNION ALL “, wenn du Ergebnisse aus mehreren Abfragen zusammenführen und alle doppelten Zeilen behalten willst.UNION ALL ” ist zeitsparender als die Funktion „ UNION ”, weil man nicht extra Duplikate entfernen muss.UNION ALL “ die bessere Wahl.UNION ALL “ super.Lass uns eine Übersichtstabelle mit den Gemeinsamkeiten und Unterschieden erstellen.
|
Feature |
UNION |
UNION ALL |
|
Doppelte Zeilen |
Entfernt |
Mit dabei |
|
Leistung |
Langsamer |
Schneller |
|
Anwendungsfall |
Wenn du einzigartige Datensätze brauchst |
Wenn du alle Unterlagen brauchst |
|
Ergebnisgröße |
Kleiner |
Größer |
Die grundlegende Syntax ist zwar in den verschiedenen SQL-Dialekten gleich, aber je nach Plattform gibt's kleine Unterschiede. Wenn du dir den Code anschaust, sieht er bei den meisten Plattformen wie SQL Server, Oracle, MySQL, PostgreSQL oder BigQuery ungefähr so aus wie unten gezeigt.
SELECT employee_id, employee_name
FROM sales_team
UNION ALL
SELECT employee_id, employee_name
FROM support_team;Die grundlegenden Befehle in diesen SQL-Dialekten sind im Großen und Ganzen gleich, mit ein paar kleinen Unterschieden:
NULL “ und die Sortierung von Zeichenfolgen haben.UNION und UNION ALL für komplexere Szenarien genutzt werden können.Bei PySpark, das in einer verteilten Umgebung läuft, ist der Befehl ganz anders. Der Code ist unten angegeben, wobei angenommen wird, dass „ df1 ” und „ df2 ” die Namen der beiden Datenrahmen sind, die aus den beiden oben erstellten Tabellen bestehen. :
df1.union(df2)Die Befehle „ UNION “ und „ UNION ALL “ sind zwar leistungsstark, aber ziemlich streng, was die Syntax angeht. Wenn deine Abfrage einen Fehler zurückgibt, verstößt sie wahrscheinlich gegen eine dieser drei goldenen Regeln.
Der häufigste Fehler, auf den Nutzer stoßen, ist eine nicht übereinstimmende Spaltenanzahl. Um zwei Datensätze zusammenzufügen, muss die „Form“ der Tabellen gleich sein. Du kannst eine Tabelle mit 3 Spalten nicht auf eine Tabelle mit 2 Spalten setzen.
Der Fehler:
-- This will fail because the column counts do not match
SELECT employee_id, name, department
FROM employees_2023
UNION
SELECT employee_id, name
FROM employees_2024;Die Lösung: Stell sicher, dass beide „ SELECT “-Anweisungen genau die gleiche Anzahl an Spalten anfordern. Wenn in der zweiten Tabelle Daten fehlen (wie department), kannst du „ NULL “ als Platzhalter auswählen, damit die Zählungen übereinstimmen:
SELECT employee_id, name, department FROM employees_2023
UNION
SELECT employee_id, name, NULL as department FROM employees_2024;SQL kombiniert die Ergebnisse nach Position, nicht nach Spaltennamen. Der Datentyp der ersten Spalte in deiner ersten Abfrage muss mit dem Datentyp der ersten Spalte in deiner zweiten Abfrage übereinstimmen (oder kompatibel sein).
Der Fehler: Wenn du aus Versehen die Reihenfolge der Spalten vertauschst, versucht SQL, eine Zahl (ID) über eine Zeichenfolge (Name) zu stapeln, was zu einem Datentypkonvertierungsfehler führt.
-- This fails because Column 1 (ID - INT) cannot combine with Column 1 (Name - VARCHAR)
SELECT employee_id, name FROM employees_2023
UNION
SELECT name, employee_id FROM employees_2024;Die Lösung: Überprüfe immer, ob deine Spalten in jeder ` SELECT `-Anweisung innerhalb der ` UNION`-Anweisung in genau derselben Reihenfolge aufgeführt sind.
Oft ist unklar, wo man die Klausel „ ORDER BY “ (und) einfügen soll. Du kannst die einzelnen Unterabfragen innerhalb einer „ UNION “-Operation nicht sortieren; du kannst nur das endgültige kombinierte Ergebnis sortieren.
Der Fehler: Wenn du „ ORDER BY “ vor der letzten Abfrage benutzt, kommt es zu einem Syntaxfehler.
-- INCORRECT SYNTAX
SELECT employee_id, name FROM employees_2023
ORDER BY employee_id -- You cannot sort here!
UNION
SELECT employee_id, name FROM employees_2024;Die Lösung: Schreib die Klausel „ ORDER BY “ ganz ans Ende deiner Abfrage. Das sortiert die ganze kombinierte Ergebnismenge.
-- CORRECT SYNTAX
SELECT employee_id, name FROM employees_2023
UNION
SELECT employee_id, name FROM employees_2024
ORDER BY employee_id; -- Sorts the final resultEs ist wichtig, den Unterschied zwischen „ UNION ” und „ UNION ALL ” zu verstehen, um Daten mit SQL effizient zu verwalten. Während „ UNION “ nur eindeutige Datensätze auswählt, holt „ UNION ALL “ alle raus, was sich auf die Leistung und die Größe der Ergebnismenge auswirkt. Nutze dieses Wissen, um die richtige Funktion für deine speziellen Anforderungen auszuwählen.
Wenn du mehr wissen willst, schau dir doch mal die folgenden Quellen an:
Lerne SQL mit DataCamp
Kurs
Kurs
Kurs
Tutorial
Sejal Jaiswal
Tutorial
Matt Crabtree
Tutorial
Sejal Jaiswal
Tutorial
Satyabrata Pal
Tutorial
Laiba Siddiqui
Tutorial
Allan Ouko

