Curso
Python intermedio
4 h
1.4M

En este post, hemos esbozado las preguntas más frecuentes durante las fases de entrevista sobre estadística y machine learning, análisis, programación y product sense. Practicar estas preguntas de entrevista para científicos de datos ayudará a los estudiantes que buscan prácticas y a los profesionales que buscan trabajo a superar todas las fases de la entrevista técnica.
Empecemos por ver algunas de las preguntas generales sobre competencias a las que podrías enfrentarte en tu entrevista. Estas son algunas de las habilidades blandas que necesitarás como científico de datos:
Esta pregunta evalúa tu capacidad de comunicación y tu habilidad para simplificar temas complejos. Aquí tienes un ejemplo de respuesta:
En mi anterior puesto, tuve que explicar el concepto de machine learning a nuestro equipo de marketing. Utilicé la analogía de enseñar a un niño a reconocer los distintos tipos de fruta. Igual que a un niño le enseñas muchos ejemplos para ayudarle a aprender, un modelo de machine learning se entrena con datos. Esta analogía ayudó a hacer que un concepto complejo fuera más cercano y fácil de entender.
Esto explora tus habilidades de colaboración en equipo y de resolución de conflictos. Podrías responder a esto con algo como:
En un proyecto, trabajé con un colega que tenía un estilo de trabajo muy diferente. Para resolver nuestras diferencias, programé una reunión para comprender su perspectiva. Encontramos un terreno común en los objetivos de nuestro proyecto y acordamos un enfoque compartido. Esta experiencia me enseñó el valor de la comunicación abierta y la empatía en el trabajo en equipo.
Esta pregunta trata sobre la gestión del tiempo y el establecimiento de prioridades. Aquí tienes un ejemplo de respuesta:
Una vez, tuve que entregar un análisis en un plazo muy ajustado. Prioricé las partes más críticas del proyecto, comuniqué mi plan al equipo y me centré en una ejecución eficiente. Dividiendo la tarea y estableciendo fechas límite parciales, conseguí terminar el proyecto a tiempo sin comprometer la calidad.
Aquí, el entrevistador se fija en tu capacidad para asumir los errores y aprender de ellos. Podrías responder con:
En un caso, interpreté mal los resultados de un modelo de datos. Al darme cuenta de mi error, informé inmediatamente a mi equipo y volví a analizar los datos. Esta experiencia me enseñó la importancia de comprobar dos veces los resultados y el valor de la transparencia en el lugar de trabajo.
Esto demuestra tu compromiso con la formación continua y con seguir siendo relevante en tu campo. Aquí tienes un ejemplo de respuesta:
Me mantengo al día leyendo revistas del sector, asistiendo a seminarios web y participando en foros en línea. También reservo tiempo cada semana para experimentar con nuevas herramientas y técnicas. Esto no solo me ayuda a mantenerme al día, sino también a mejorar continuamente mis habilidades.
Esta pregunta evalúa la capacidad de adaptación y de resolución de problemas. Como ejemplo, podrías decir:
En un proyecto anterior, los requisitos cambiaban con frecuencia. Me adapté manteniendo una comunicación abierta con las partes interesadas para comprender sus necesidades. También utilicé metodologías ágiles para ser más flexible en mi enfoque, lo que me ayudó a adaptarme a los cambios con eficacia.
Esto evalúa tu capacidad para tener en cuenta diversos aspectos más allá de los datos. Un ejemplo de respuesta podría ser:
En mi último puesto, tuve que equilibrar la necesidad de tomar decisiones basadas en datos con consideraciones éticas. Me aseguré de que todo uso de datos cumpliera las normas éticas y las leyes de privacidad, y presenté alternativas cuando fue necesario. Este enfoque ayudó a tomar decisiones con conocimiento de causa, respetando los límites éticos.
Los cuatro supuestos de una regresión lineal son:
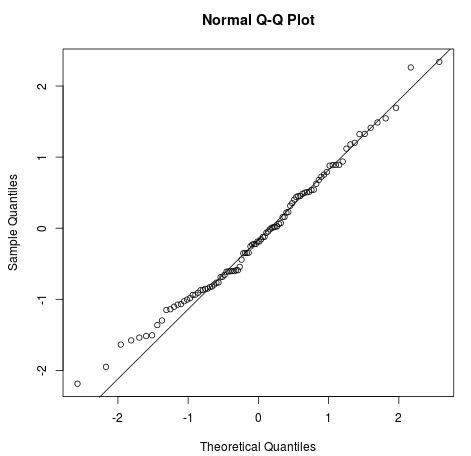
Imagen de Statology
Puedes explorar los conceptos y aplicaciones de los modelos lineales siguiendo nuestro curso Introducción al modelado lineal en Python.
Hay varias formas de tratar los datos que faltan. Puedes:
Aprende a diagnosticar, visualizar y tratar los datos que faltan completando el curso Gestión de datos que faltan con imputaciones en R.
En primer lugar, debes conocer mejor la formación de las partes interesadas y utilizar esta información para modificar tus palabras. Si tienen formación en finanzas, aprende los términos de uso común en finanzas y utilízalos para explicar la compleja metodología.
En segundo lugar, tienes que utilizar muchos elementos visuales y gráficos. Aprendemos de forma visual, ya que lo hacemos muchísimo mejor cuando se usan herramientas de comunicación creativas.
Imagen del autor
En tercer lugar, habla en términos de resultados. No intentes explicar las metodologías ni las estadísticas. Intenta centrarte en cómo pueden utilizar la información del análisis para mejorar la empresa o el flujo de trabajo.
Por último, anímales a que te hagan preguntas. Tenemos miedo o incluso vergüenza de hacer preguntas sobre temas desconocidos. Crea un canal de comunicación bidireccional haciéndoles participar en la conversación.
Aprende a crear tus propios informes y tableros SQL siguiendo nuestro curso Informes en SQL.
Hay tres métodos principales para la selección de características: métodos de filtro, wrapper e integrados.
Métodos de filtro
Los métodos de filtro se suelen utilizan en las fases de preprocesamiento. Estos métodos seleccionan características de un conjunto de datos independientemente de cualquier algoritmo de machine learning. Son rápidos, requieren menos recursos y eliminan características duplicadas, correlacionadas y redundantes.

Imagen del autor
Algunas técnicas utilizadas son:
Métodos wrapper
En los métodos wrapper, entrenamos el modelo iterativamente utilizando un subconjunto de características. En función de los resultados del modelo entrenado, se añaden o eliminan más características. Son computacionalmente más caros que los métodos de filtro, pero proporcionan una mayor precisión del modelo.
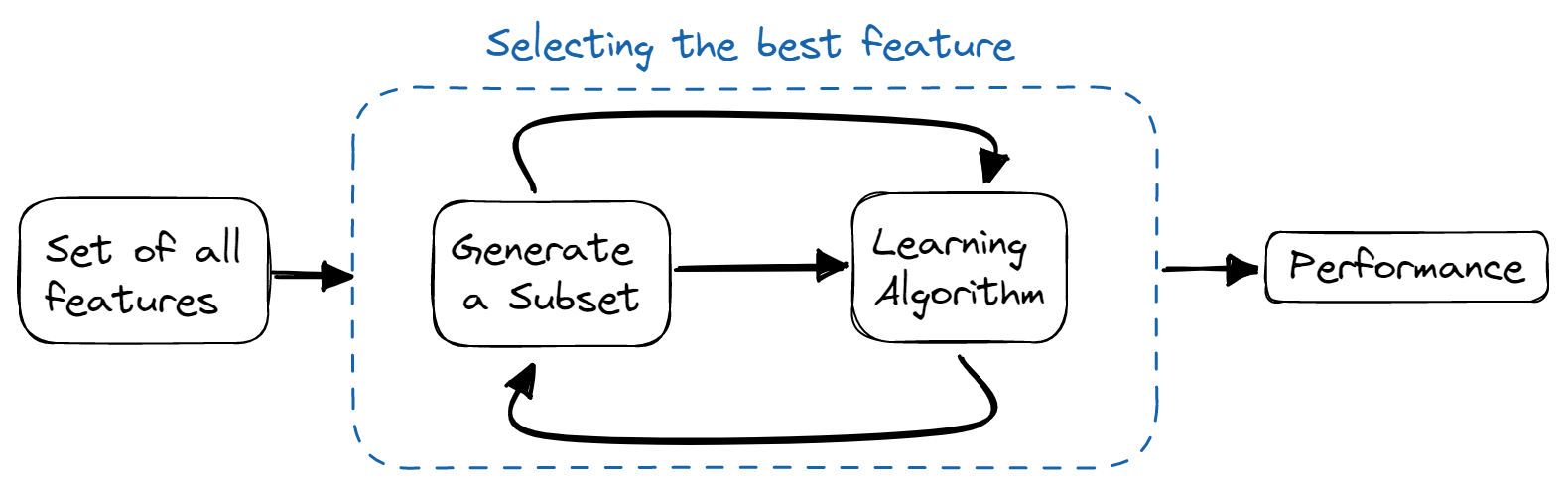
Imagen del autor
Algunas técnicas utilizadas son:
Métodos integrados
Los métodos integrados combinan las cualidades de los métodos de filtro y wrapper. El algoritmo de selección de características se mezcla como parte del algoritmo de aprendizaje, lo que proporciona al modelo un método de selección de características integrado. Estos métodos son más rápidos, como los métodos de filtro, precisos como los métodos wrapper, y también tienen en cuenta una combinación de características.
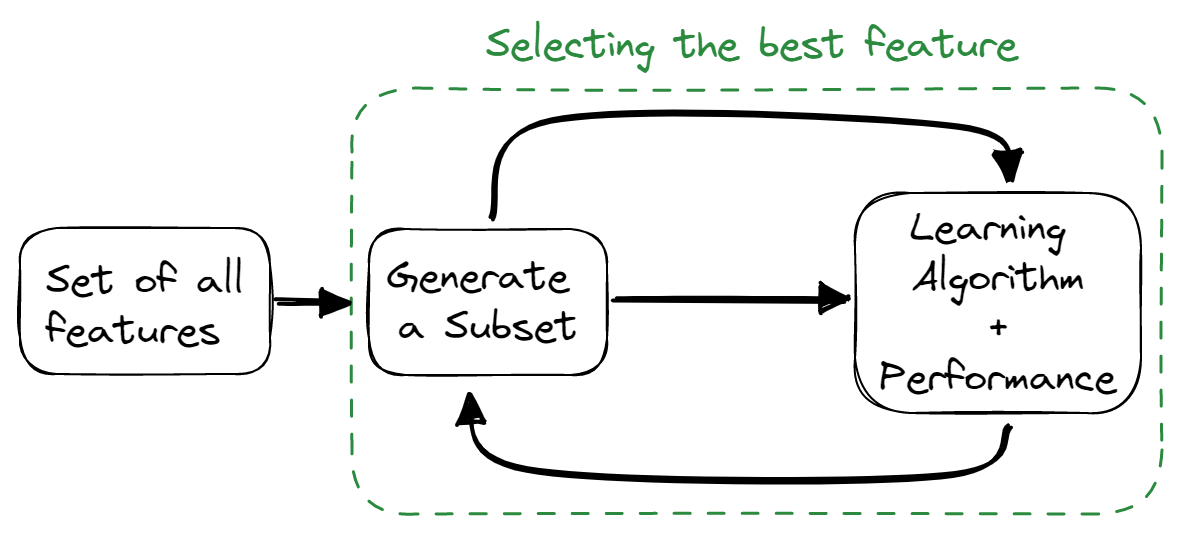
Imagen del autor
Algunas técnicas utilizadas son:
El sobreajuste se produce cuando un modelo se entrena demasiado bien con un conjunto de datos de entrenamiento, pero falla en el conjunto de datos de prueba y validación.
Puedes evitar el sobreajuste de la siguiente forma:
Hay cuatro tipos principales de relaciones SQL:
Aprende a explorar las tablas, las relaciones entre ellas y los datos almacenados en ellas completando nuestro curso Análisis exploratorio de datos en SQL.
La reducción de dimensionalidad es un proceso que convierte el conjunto de datos de varias dimensiones a menos dimensiones, manteniendo información similar.
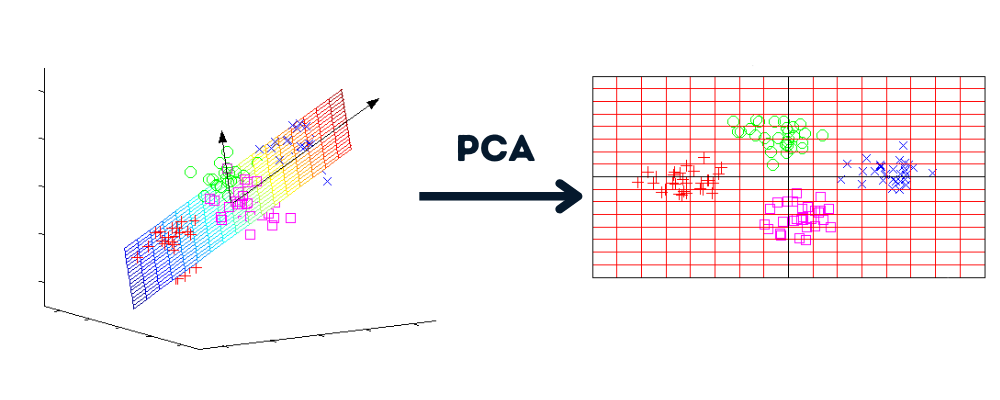
Imagen del autor | Gráficos de howecoresearch
Ventajas de la reducción de dimensionalidad:
Comprende el concepto de reducción de dimensionalidad y domina las técnicas practicando con el curso Reducción de dimensionalidad en Python.

Imagen del autor
Las pruebas A/B eliminan las conjeturas y nos ayudan a tomar decisiones basadas en datos para optimizar el producto o el sitio web. También se conocen como split testing, y en ellas se realizan experimentos aleatorios para analizar dos o más versiones de variables (página web, función de la app, etc.) y determinar qué versión genera el máximo en tráfico y métrica comercial.
Aprende a crear, ejecutar y analizar pruebas A/B siguiendo nuestro curso Análisis de clientes y pruebas A/B en Python.
Esta relación se utiliza habitualmente en el análisis de textos y de sentimientos. En esta pregunta, escribirás una función de Python que convertirá determinadas palabras de la lista a su forma raíz: consulta de la entrevista.
Entrada:
La función tomará dos argumentos: lista de palabras raíz y frase.
roots = ["cat", "bat", "rat"]
sentence = "the cattle was rattled by the battery"Salida:
Te devolverá la frase con las palabras raíz.
"the cat was rat by the bat"Antes de lanzarte a escribir código, debes comprender que realizaremos dos tareas: comprobar si la palabra tiene raíz y sustituirla.
roots = ["cat", "bat", "rat"]
sentence = "the cattle was rattled by the battery"
def replace_words(roots, sentence):
words = sentence.split(" ")
# looping over each word
for index, word in enumerate(words):
# looping over each root
for root in roots:
# checking if words start with root
if word.startswith(root):
# replacing the word with its root
words[index] = root
return " ".join(words)
replace_words(roots, sentence)
# 'the cat was rat by the bat'Dada la cadena text, devuelve True si es un palíndromo; en caso contrario, False.
Después de hacer minúsculas todas las letras y eliminar todos los caracteres no alfanuméricos, la palabra debe leerse igual hacia delante y hacia atrás.

Imagen del autor
Python proporciona formas sencillas de resolver este reto. Puedes tratar la cadena como iterable e invertirla mediante text[::-1] o utilizar el método integrado reversed(text).
[::-1].import re
def is_palindrome(text):
# lowering the string
text = text.lower()
# Cleaning the string
rx = re.compile('\W+')
text = rx.sub('',text).strip()
# Reversing and comparing the string
return text == text[::-1]En el segundo método, simplemente sustituirás la inversión del texto por ''.join(reversed(text)) y lo compararás con el texto limpio.
Ambos métodos son sencillos.
def is_palindrome(text):
# lowering the string
text = text.lower()
# Cleaning the string
rx = re.compile('\W+')
text = rx.sub('',text).strip()
# Reversing the string
rev = ''.join(reversed(text))
return text == revResultado:
Proporcionaremos la lista de la palabra a la función is_palindrome() e imprimiremos los resultados. Como puedes ver, incluso con caracteres especiales, la función ha identificado "Level" y "Radar" como palíndromos.
# Test cases
List = ['Anna', '**Radar****','Abid','(Level)', 'Data']
for text in List:
print(f"Is {text} a palindrome? {is_palindrome(text)}")
# Is Anna a palindrome? True
# Is **Radar**** a palindrome? True
# Is Abid a palindrome? False
# Is (Level) a palindrome? True
# Is Data a palindrome? FalsePrepárate para tus próximas entrevistas de programación practicando preguntas de entrevistas de programación en Python con nuestro curso interactivo.
Es fácil encontrar el valor más alto y el más bajo, pero difícil encontrar el segundo valor más alto o el enésimo valor más alto.
En la pregunta, se te proporciona la tabla de la base de datos que consta de id y base_salary. Escribirás la consulta SQL para encontrar el segundo salario más alto.
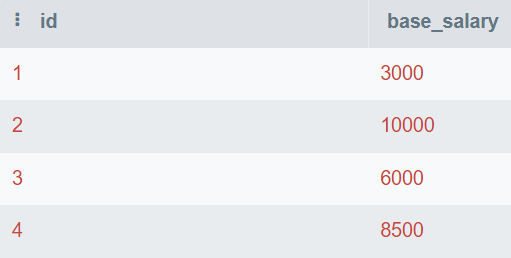
Imagen del autor
En esta consulta, encontrarás los valores únicos y los ordenarás de mayor a menor. A continuación, utilizarás LIMIT 1 para mostrar solo el valor más alto. Al final, desviarás el valor en 1 para mostrar el segundo número más alto.
También puedes cambiar el valor OFFSET para obtener el enésimo salario más alto.
SELECT DISTINCT base_salary AS "Second Highest Salary"
FROM employee
ORDER BY base_salary DESC
LIMIT 1
OFFSET 1;El segundo salario base más alto es de 8500.

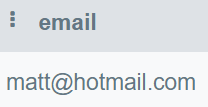
En esta pregunta, escribirás una consulta para mostrar todos los correos duplicados.

Imagen del autor
En esta consulta, mostrarás la columna email y agruparás la tabla por email. Después, utilizaremos la cláusula HAVING para encontrar correos electrónicos que se mencionen más de una vez.
HAVING se utiliza como sustituto de la sentencia WHERE junto con las agregaciones.
SELECT email
FROM employee_email
GROUP BY email
HAVING COUNT(email) > 1;Solo "matt@hotmail.com" aparece más de una vez.
Escribe código SQL mantenible para responder a preguntas empresariales siguiendo el curso Aplicación de SQL a problemas del mundo real.
Imagen del autor
En el último mes, los posts bajaron del 3 % al 2,5 % actual. Antes de llegar a una conclusión, tienes que aclarar el contexto del problema.
Tienes que hacer preguntas:
En la segunda parte, tienes que explicar en detalle qué ha provocado el descenso. ¿Ha aumentado el número de usuarios o ha disminuido el número de posts? Después, el entrevistador te pedirá que inicies un debate utilizando uno o ambos razonamientos.
En cuanto a la distribución del tiempo que se pasa al día en Facebook, cabe suponer que puede haber dos grupos:
Para la segunda parte, tienes que utilizar vocabulario estadístico para describir la distribución, como, por ejemplo:
En esta pregunta, escribirás código pandas para dividir primero la puntuación en varios buckets y luego calcular el porcentaje de alumnos que obtienen la puntuación en esos tramos.
Entrada:
Nuestro conjunto de datos tiene las columnas user_id, grade y test_score.
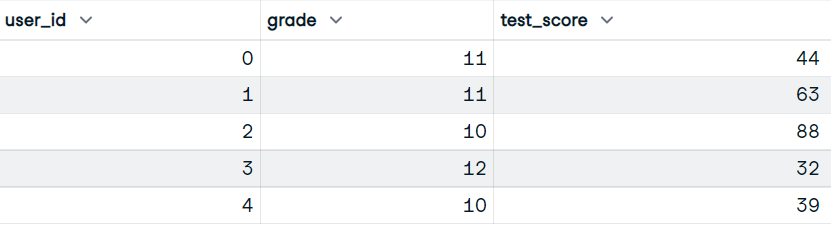
Imagen del autor
Salida:
Escribirás la función que utilizará las columnas grade y test_score. Y muestra el marco de datos con las calificaciones, las puntuaciones de los buckets y el porcentaje acumulado de alumnos que obtienen puntuaciones de buckets.
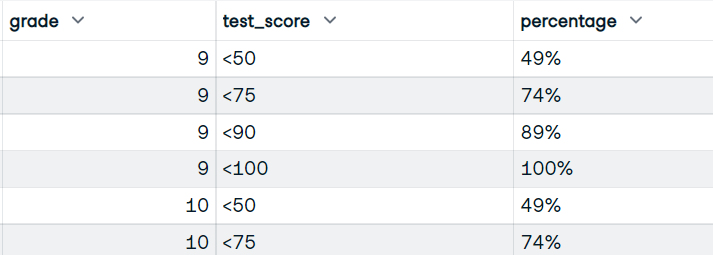
Imagen del autor
pandas.cut() para convertir puntuaciones en puntuaciones de los buckets utilizando bins y etiquetas de buckets. def bucket_test_scores(df):
bins = [0, 50, 75, 90, 100]
labels = ["<50", "<75", "<90", "<100"]
# converting the scores into buckets
df["test_score"] = pd.cut(df["test_score"], bins, labels=labels, right=False)
# Calculate size of each group, by grade and test score
df = df.groupby(["grade", "test_score"]).size()
# Calculate numerator and denominator for percentage
NUM = df.groupby("grade").cumsum()
DEN = df.groupby("grade").sum()
# Calculate percentage, multiply by 100, and add %
percentage = (NUM / DEN).map(lambda x: f"{int(100*x):d}%")
# reset the index
percentage = percntage.reset_index(name="percentage")
return percentage
bucket_test_scores(df)Has obtenido el resultado perfecto con la puntuación de la prueba del bucket y el porcentaje.
Aprende a limpiar datos, calcular estadísticas y crear visualizaciones con el curso Manipulación de datos con pandas.
El intervalo de confianza es un intervalo de estimaciones de un parámetro desconocido que esperas que caiga entre un determinado porcentaje del tiempo cuando vuelvas a realizar el experimento o vuelvas a muestrear de forma similar la población.
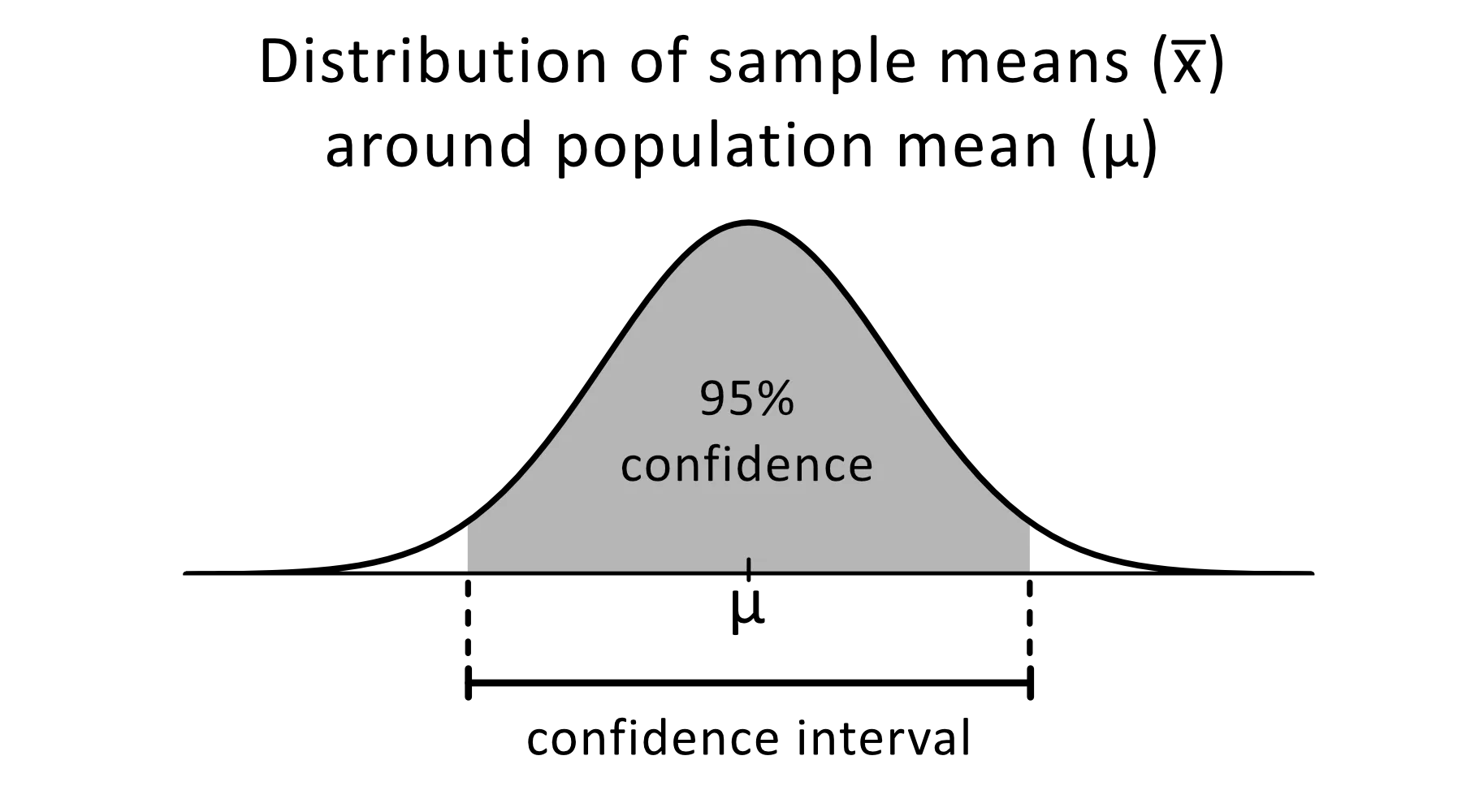
Imagen de omnicalculator
El nivel de confianza del 95 % se utiliza habitualmente en experimentos estadísticos, y es el porcentaje de veces que esperas que se reproduzca un parámetro estimado. Los intervalos de confianza tienen un límite superior e inferior que se establece mediante el valor alfa.
Puedes utilizar intervalos de confianza para diversas estimaciones estadísticas, como proporciones, medias poblacionales, diferencias entre proporciones o medias poblacionales y estimaciones de variación entre grupos.
Construye la base estadística completando nuestro curso Pensamiento estadístico en Python (parte 1).
En el conjunto de datos desequilibrado, las clases se distribuyen de forma desigual. Por ejemplo, en el conjunto de datos de detección de fraudes, solo hay 400 casos de fraude frente a 300 000 casos de no fraude. Los datos desequilibrados harán que el modelo funcione peor a la hora de detectar el fraude.
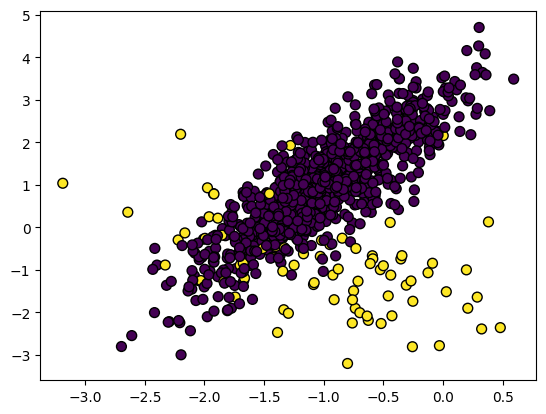
Imagen del autor
Para manejar datos desequilibrados, puedes utilizar:
Submuestreo
Remuestrea las características de la clase mayoritaria para igualarlas a los de la clase minoritaria.
En el conjunto de datos de detección del fraude, ambas clases serán iguales a 400 muestras. Puedes utilizar imblearn.under_sampling para remuestrear tu conjunto de datos con facilidad.
from imblearn.under_sampling import RandomUnderSampler
RUS = RandomUnderSampler(random_state=1)
X_US, y_US = RUS.fit_resample(X_train, y_train)Sobremuestreo
Remuestrea las características de la clase minoritaria para igualarlas a las de la clase mayoritaria. La repetición o la repetición ponderada de las características de la clase minoritaria son algunos de los métodos habituales utilizados para equilibrar los datos. En resumen, ambas clases tendrán 300 000 muestras.
from imblearn.over_sampling import RandomOverSampler
ROS = RandomOverSampler(random_state=0)
X_OS, y_OS = ROS.fit_resample(X_train, y_train)Creación de datos sintéticos
El problema de la repetición es que no aporta información adicional, lo que dará lugar a un rendimiento deficiente de los modelos. Para contrarrestar esto, podemos utilizar SMOTE (Synthetic Minority Oversampling technique) para crear puntos de datos sintéticos.
from imblearn.over_sampling import SMOTE
SM = SMOTE(random_state=1)
X_OS, y_OS = SM.fit_resample(X_train, y_train)Combinación de submuestreo y sobremuestreo
Para mejorar los sesgos y el rendimiento del modelo, puedes utilizar una combinación de sobremuestreo y submuestreo. Utilizaremos SMOTE para el sobremuestreo y EEN (Edited Nearest Neighbours) para la limpieza.
imblearn.combine nos proporciona diferentes funciones que realizan automáticamente ambas funciones de muestreo.
from imblearn.combine import SMOTEENN
SMTN = SMOTEENN(random_state=0)
X_OUS, y_OUS = SMTN.fit_resample(X_train, y_train)Como científico de datos, escribirás un tipo de consulta similar para extraer los datos y realizar el análisis de datos. En este reto, utilizarás la cláusula WHERE con signos de comparación o WHERE con la cláusula BETWEEN para realizar el filtrado.
Tabla: pedidos
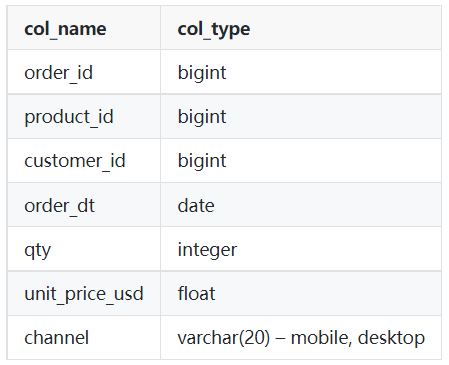
Imagen del autor
Muestra de salida:
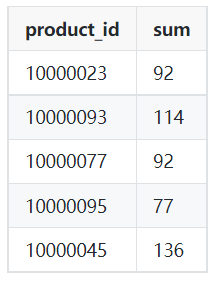
Imagen del autor
SELECT product_id,
SUM(qty)
FROM orders
WHERE order_dt >= '2022-03-01'
AND order_dt < '2022-04-01'
GROUP BY product_id;En el aprendizaje no supervisado, encontrar el rendimiento del proyecto de clustering puede ser complicado. Los criterios de un buen clustering son grupos distintos con poca similitud.
No existe una métrica de precisión en los modelos de clustering, por lo que utilizaremos la similitud o la distinción entre los grupos para evaluar el rendimiento del modelo.
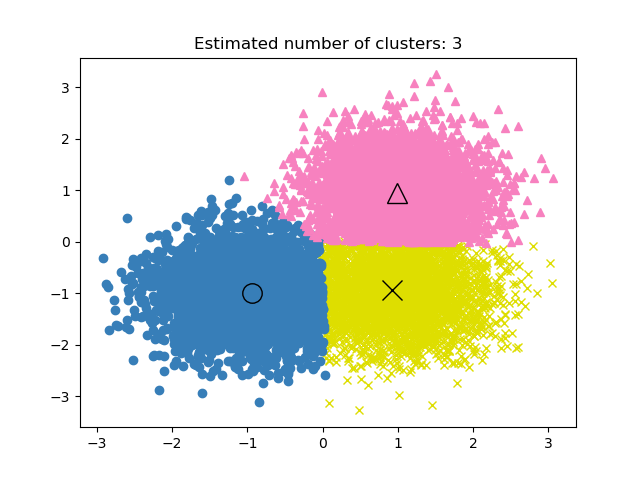
Imagen de la documentación de scikit-learn
Las tres métricas más utilizadas son:
Silhouette Score
Se calcula utilizando la distancia media intraclúster y la distancia media del clúster más cercano.
Podemos utilizar scikit-learn para calcular la métrica. Silhouette Score oscila entre -1 y 1, donde las puntuaciones más altas significan menor similitud entre grupos y clústeres distintos.
from sklearn import metrics
model = KMeans().fit(X)
labels = model.labels_
metrics.silhouette_score(X, labels)Calinski-Harabaz Index
Calcula la distinción entre grupos utilizando la dispersión entre clústeres y la dispersión dentro de clústeres. La métrica no tiene límite y, como en Silhoutte Score, una puntuación más alta significa un mejor rendimiento del modelo.
metrics.calinski_harabasz_score(X, labels)Davies-Bouldin Index
Calcula la similitud media de cada clúster con su clúster más similar. A diferencia de otras métricas, una puntuación más baja significa un mejor rendimiento del modelo y una mejor separación entre clústeres.
metrics.davies_bouldin_score(X, labels)
Aprende a aplicar el clustering jerárquico y de k-medias siguiendo nuestro curso Análisis de clústeres en R.

Imagen del autor
Utilizaremos:
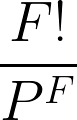
Para resolver este problema, primero tenemos que hallar el número total de formas de salir a las plantas: 44 = 4 × 4 × 4 × 4 = 256 formas.
Después, calcula el número de formas en que cada persona puede bajarse en una planta distinta: 4! = 24.
Para calcular la probabilidad de que cada persona se baje en una planta distinta, tenemos que dividir el número de formas en que cada persona se baja en una planta distinta entre el número total de formas de salir a las plantas.
24/256 = 3/32
Aprende estrategias para responder a preguntas complicadas sobre probabilidad con R siguiendo nuestro curso Puzzles de probabilidad en R.
Para generar N muestras de la distribución normal, puedes utilizar Numpy (np.random.randn(N)) o SciPy (sp.stats.norm.rvs(size=N)).
Para trazar un histograma, puedes utilizar Matplotlib o Seaborn.
La cuestión es bastante sencilla si conoces las herramientas adecuadas.
import numpy as np
import seaborn as sns
N = 10_000
def norm_dist_hist(N):
# Generating Random normal distribution samples
x = np.random.randn(N)
# Plotting histogram
sns.histplot(x, bins = 20, kde=True);
return x
X = norm_dist_hist(N)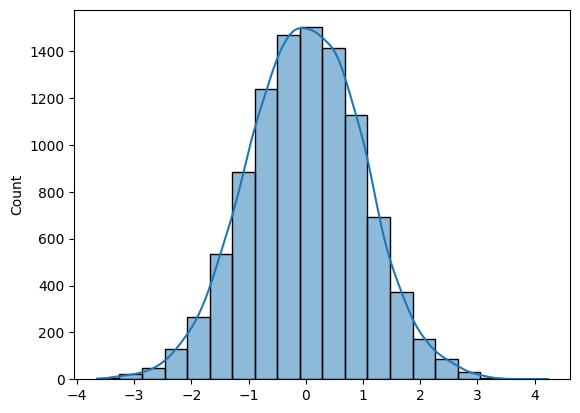
Aprende a crear visualizaciones informativas y atractivas en segundos completando el curso Introducción a la visualización de datos con Seaborn.
Imagen del autor
Las entrevistas de ciencia de datos se dividen en cuatro o cinco etapas. Se te harán preguntas sobre estadística y machine learning, programación (Python, R, SQL), comportamiento, product sense y, a veces, liderazgo.
Puedes prepararte para todas las etapas haciendo lo siguiente:
Lee el blog Preparación de la entrevista de ciencia de datos para saber qué esperar y cómo abordar la entrevista.
Cursos de ciencia de datos
Curso
Curso
Curso
blog
Abid Ali Awan
15 min
blog
Artur Sannikov
12 min
blog
Tim Lu
9 min
blog
Matt Crabtree
12 min
blog
Austin Chia
15 min
blog
Abid Ali Awan
15 min
