
Course
Introduction to Data Science in Python
4 hr
498.3K

The data engineer develops, constructs, tests, and maintains architectures such as databases and large-scale processing systems. The data scientist, on the other hand, cleans, massages, and organizes (big) data.
You might find the choice of the verb "massage" particularly exotic, but it only reflects the difference between data engineers and data scientists even more.
Generally speaking, the efforts that both parties will need to make to get the data in a usable format are considerably different.
Data engineers deal with raw data that contains human, machine, or instrument errors. The data might not be validated and contain suspect records. It will be unformatted and can contain system-specific codes.
Data engineers will need to recommend and sometimes implement ways to improve data reliability, efficiency, and quality. To do so, they will need to employ a variety of languages and tools to marry systems together or hunt down opportunities to acquire new data from other systems so that the system-specific codes, for example, can become information for further processing by data scientists.
Very closely related to these two is the fact that data engineers will need to ensure that the architecture that is in place supports the requirements of the data scientists, the stakeholders, and the business.
Lastly, the data engineering team will need to develop data set processes for data modeling, mining, and production to deliver the data to the data science team.
Find out more about what a data engineer does in our full article.

Data scientists will usually already get data that has passed a first round of cleaning and manipulation, which they can use to feed to sophisticated analytics programs and machine learning and statistical methods to prepare data for use in predictive and prescriptive modeling. Of course, to build models, they need to do research on industry and business questions, and they will need to leverage large volumes of data from internal and external sources to answer business needs. This also sometimes involves exploring and examining data to find hidden patterns.
Once data scientists have done the analyses, they will need to present a clear story to the key stakeholders. When the results are accepted, they will need to ensure that the work is automated so that the insights can be delivered to the business stakeholders on a daily, monthly, or yearly basis.
It is clear that both parties need to work together to wrangle the data and provide insights into business-critical decisions. There is a clear overlap in skill, but the two are gradually becoming more distinct in the industry: while the data engineer will work with database systems, data APIs, and tools for ETL purposes and will be involved in data modeling and setting up data warehouse solutions, the data scientist needs to know about stats, math and machine learning to build predictive models.
The data scientist needs to be aware of distributed computing, as he will need to gain access to the data processed by the data engineering team. He or she will also need to be able to report to the business stakeholders, so a focus on storytelling and visualization is essential.
What this means in terms of focus on the steps of the data science workflow, you can see in the image below:

Of course, this difference in skillsets translates into differences in languages, tools, and software that both use. The following overview includes both commercial and open-source alternatives.
Even though the tools used by both parties heavily depend on how the role is conceived in the company context, data engineers often work with tools such as SAP, Oracle, Cassandra, MySQL, Redis, Riak, PostgreSQL, MongoDB, Neo4j, Hive, and Sqoop.
Data scientists will use languages such as SPSS, R, Python, SAS, Stata, and Julia to build models. The most popular tools here are, without a doubt, Python and R. When you're working with Python and R for data science, you will most often resort to packages such as ggplot2 to make amazing data visualizations in R or the Python data manipulation library Pandas. Of course, many more packages out there will come in handy when you're working on data science projects, such as scikit-learn, NumPy, Matplotlib, Statsmodels, etc.
In the industry, you'll also find that commercial SAS and SPSS do well, but other tools such as Tableau, Rapidminer, Matlab, Excel, and Gephi will find their way to the data scientist's toolbox.
You see again that one of the main distinctions between data engineers and data scientists, the emphasis on data visualization and storytelling, is reflected in the tools mentioned.
As you might have already guessed, Scala, Java, and C # are tools, languages, and software that both parties have in common.

These languages aren't necessarily popular with data scientists and engineers. You could argue that Scala is more popular with data engineers because its integration with Spark is especially handy for setting up large ETL flows.
The same goes for the Java language: at the moment, its popularity is on the rise among data scientists, but overall, it's not widely used on a daily basis by professionals. But, all in all, you'll see these languages popping up on job openings for both roles. The same can also be said about tools that both parties could have in common, such as Hadoop, Storm, and Spark.
Of course, the comparison in tools, languages, and software needs to be seen in the specific context in which you're working and how you interpret the data science roles in question; data science and data engineering can lie closely together in some specific cases, where the distinction between data science and data engineering teams is indeed so small that sometimes, the two teams are merged.
Whether this is a great idea or not is enough material for another discussion, which is outside the scope of today's blog.
Besides all of this, data scientists and data engineers might also have something in common: their computer science backgrounds. This study area is widely popular for both professions. Of course, you'll also see that data scientists have often studied econometrics, mathematics, statistics, and operations research. They often have a little bit more business acumen than data engineers. You often see that data engineers also come from engineering backgrounds; more often than not, they have had some prior education in computer engineering.
However, this doesn't mean that you won't find data engineers who have gathered knowledge in operations and business acumen from prior studies.

You have to realize that, in general, the data science industry is made up of professionals who come from different backgrounds: it is not uncommon for physicists, biologists, or meteorologists to find their way into data science. Others have switched careers to data science and come from web development, database administration, etc.
In the US, the average annual data scientist salary is $123,069, with a range of $78k to $194k. Across different countries, this is a similar trend, with the average data scientist salary at least 30% higher than the national average (and in India, this figure is significantly higher!).
The average annual salary for data engineers in the US is $125,686; in other countries, the average salary is very similar to that of a data scientist.
Both roles are hugely in demand. At the time of writing, Indeed lists 10,000+ data scientist and 5,000+ data engineer roles in the US. Leading companies such as Spotify, Meta, Amazon, Google, and Microsoft are nearly always hiring for both roles.

As described before, the creation of roles and titles is needed to reflect changing needs, but other times, they are created as a way to differentiate from fellow recruiting companies.
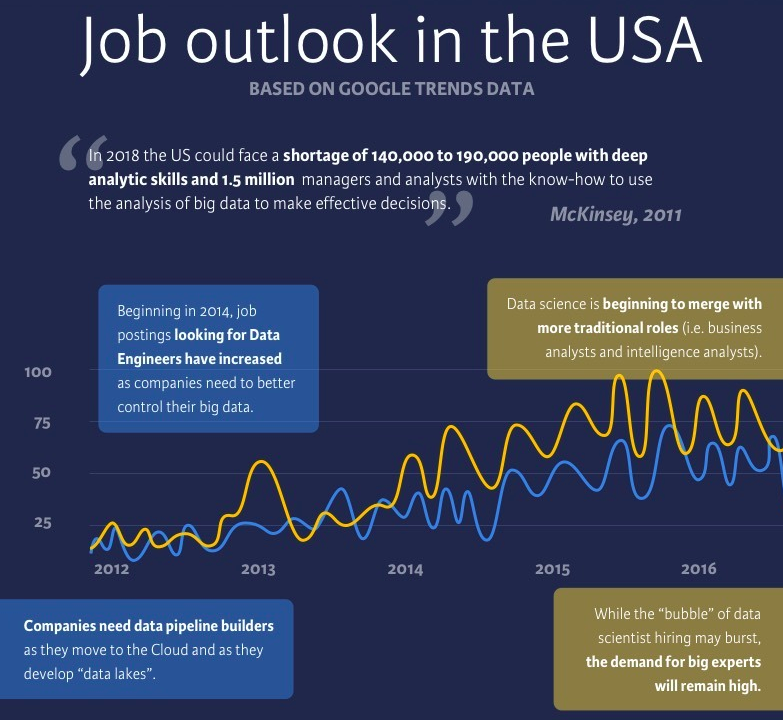
In addition to the rise in interest in data management issues, companies are looking for cheaper, flexible, and scalable solutions to store and manage their data. They want to move their data to the Cloud, and to do this, they need to build "data lakes" to complement the data warehouses they already have in place or replace the Operational Data Store (ODS).
Data flows will need to be redirected and replaced in the coming years, and as a result, the focus on and the number of job postings to hire data engineers has gradually increased over the years.
The data scientist role has been in demand since the start of the hype, but nowadays, companies are looking to compose data science teams instead of hiring unicorn data scientists who possess communication skills, creativity, cleverness, curiosity, technical expertise, etc. For recruiters, it's hard to find people who embody all the qualities that companies are looking for, and the demand clearly exceeds the supply.
You could argue that the "data scientist bubble" has burst. Or maybe it was about to burst until AI advancements like GPT-3 and GPT-4 took the world by storm.
One thing will remain constant throughout all of this: the demand for experts who are passionate about data science topics will always exist. The job outlook for these experts is highly positive. For example, the US Bureau of Labor Statistics projects 20,800 job openings for data scientists each year for the next decade, projected to grow 36 percent from 2023 to 2033, much faster than the average for all occupations. The outlook is similarly bullish for data engineer openings.
| Aspect | Data scientist | Data engineer | Similarities |
|---|---|---|---|
| Primary focus | Analyzing and interpreting data to derive insights | Building and maintaining data infrastructure | Work with data to enable decision-making |
| Responsibilities | Modeling, statistical analysis, and storytelling | Data pipeline creation, ETL processes, and data warehousing | Collaborate to ensure data is clean, accessible, and usable |
| Core skills | Machine learning, statistics, visualization | Data architecture, database management, and cloud tools | Proficiency in programming and handling large-scale datasets |
| Tools & software | Python, R, TensorFlow, PyTorch, Tableau, Power BI | Python, Apache Spark, Kafka, Airflow, dbt, Snowflake, Databricks | Shared use of tools like Spark, Hadoop, and SQL |
| Programming languages | Python, R, SQL | Python, SQL, Scala, Java | Proficiency in Python and SQL is valuable for both |
| Data processing | Focuses on data manipulation and model training using tools like Pandas, NumPy | Designs robust ETL pipelines with Apache Spark, Apache Flink | Often collaborate on data preparation processes |
| Visualization | Emphasizes data storytelling using Tableau, Power BI, Matplotlib | Visualization may occur during data validation but is not a primary focus | May use shared tools like Looker for reporting |
| Educational background | Statistics, mathematics, computer science | Computer science, data engineering, software engineering | Shared backgrounds in technical disciplines such as computer science |
| Salary (US average) | ~$123,000/year | ~$125,000/year | Competitive salaries and high demand across both roles |
| Job outlook | Growing focus on extracting actionable insights and AI | Increasing need for robust, scalable data management systems | Strong growth in data-driven industries |
If you'd like to plot your path to starting a career in either role, our guides are a great place to start:
If you'd like to get straight into your learning journey, DataCamp has you covered. We have many ideal courses if you want to start learning data engineering. For example, DataCamp's Importing Data in Python and the Importing Data in R courses. Our Data Engineer Certification is another great option to prove to hiring managers that you have the required skills for an entry-level role.
For those who want to get started with data science, there are the Exploratory Data Analysis, Introduction to R for Data Science, Machine Learning Toolbox, and Introduction to Python for Data Science courses. Likewise, our Data Scientist Certification is highly regarded and will help you get through the door at leading companies.
Learn more about data science and data engineering with these courses!
Course
Course
Course
blog
Matt Crabtree
15 min
blog
Jacob Moody
1 min
blog
Joleen Bothma
9 min
blog
Javier Canales Luna
13 min
blog
Travis Tang
10 min
Tutorial
Karlijn Willems
