Curso
Machine learning con PySpark
4 h
29.7K
Estos proyectos de machine learning para principiantes consisten en trabajar con datos estructurados y tabulares. Aplicarás las habilidades de limpieza, procesamiento y visualización de datos con fines analíticos y utilizarás el marco scikit-learn para entrenar y validar modelos de machine learning.
Si quieres aprender primero los conceptos básicos de machine learning, tenemos un fantástico curso de machine learning sin código. También puedes echar un vistazo a algunos de nuestros proyectos de IA si deseas mejorar tus habilidades en ese ámbito.
En el proyecto «Predict Energy Consumption» (Predicción del consumo energético), utilizarás modelos de regresión y machine learning para predecir el consumo energético diario basándote en factores temporales como la hora del día y la temperatura. El objetivo es descubrir patrones que permitan optimizar el uso de la energía, mejorando la eficiencia y reduciendo los costes. Esto es especialmente importante para las empresas de servicios públicos y las empresas que desean reducir los gastos operativos, promover el ahorro energético y gestionar mejor sus recursos de una forma más sostenible.
El proyecto «Predict Energy Consumption» (Predicción del consumo energético) es un proyecto guiado, pero puedes replicar los objetivos en un conjunto de datos diferente, como «Seoul's Bike Sharing Demand» (Demanda de bicicletas compartidas en Seúl). Trabajar con un conjunto de datos completamente nuevo te ayudará a depurar el código y mejorar tus habilidades para resolver problemas.
En el proyecto «De los datos al dinero: predicción de los costes de los seguros», te pondrás en la piel de un científico de datos de una compañía de seguros médicos. Crearás un modelo predictivo para estimar los costes del seguro en función de las características del cliente, como la edad y los factores de salud. Este proyecto ofrece una aplicación práctica del machine learning en los negocios, lo que permite modelos de fijación de precios más precisos y ayuda a las empresas a gestionar el riesgo, al tiempo que ofrece estrategias de precios personalizadas a los clientes.
El proyecto «Predicción de los costes de los seguros» es un proyecto guiado. Puedes replicar el resultado en un conjunto de datos diferente, como el de la demanda de reservas hoteleras. Puedes utilizarlo para predecir si un cliente cancelará la reserva o no.
En el proyecto Predicción de aprobaciones de tarjetas de crédito, crearás una aplicación de aprobación automática de tarjetas de crédito utilizando la optimización de hiperparámetros y la regresión logística.
Aplicarás tus conocimientos sobre cómo manejar valores perdidos, procesar características categóricas, escalar características, tratar datos desequilibrados y realizar la optimización automática de hiperparámetros utilizando GridCV. Este proyecto te sacará de la zona de confort que supone manejar datos sencillos y limpios.

Imagen del autor
La predicción de aprobaciones de tarjetas de crédito es un proyecto guiado. Puedes replicar el resultado en un conjunto de datos diferente, como los datos de préstamos de LendingClub.com. Puedes utilizarlo para crear un predictor automático de aprobación de préstamos.
Podrías montar un proyecto de predicción de la calidad del vino utilizando un conjunto de datos sobre las propiedades fisicoquímicas del vino, como el contenido de alcohol, la acidez y los niveles de azúcar. Mediante la aplicación de modelos de clasificación, como la regresión logística en scikit-learn, puedes clasificar los vinos en una escala del 1 al 10.
Este proyecto es importante para las industrias dedicadas a la producción y el control de calidad del vino, ya que les permite supervisar y predecir de forma constante la calidad del vino, garantizando la excelencia del producto.
En el proyecto de ciencia de datos «Modelos predictivos para la agricultura», crearás un sencillo sistema de recomendación de cultivos utilizando machine learning supervisado y la selección de características. Trabajando con cuatro atributos esenciales del suelo: nitrógeno, fósforo, potasio y pH. Te enfrentarás a una limitación realista: el agricultor solo puede permitirse medir uno. Tu trabajo consiste en identificar qué característica individual predice mejor el cultivo adecuado y, a continuación, entrenar un clasificador ligero para que haga esa recomendación de forma fiable.
Practicarás habilidades prácticas como el manejo de valores perdidos, la codificación de etiquetas, el escalado de características, la evaluación de modelos y, lo más importante, la aplicación y comparación de dos técnicas de selección de características para clasificar las medidas del suelo.
Store Sales es una competición de iniciación de Kaggle en la que los participantes entrenan varios modelos de series temporales para mejorar su puntuación en la clasificación. En el proyecto, se te proporcionarán datos de ventas de tiendas y tú te encargarás de limpiar los datos, realizar análisis exhaustivos de series temporales, escalar características y entrenar el modelo de series temporales multivariantes.
Para mejorar tu puntuación en la tabla de clasificación, puedes utilizar ensamblajes como Bagging y Voting Regressors.
Imagen de Kaggle
Store Sales es un proyecto basado en Kaggle en el que puedes consultar los cuadernos de otros participantes.
Para mejorar tu comprensión del pronóstico de series temporales, intenta aplicar tus habilidades al conjunto de datos de la Bolsa de Valores y utiliza Facebook Prophet para entrenar un modelo de pronóstico de series temporales univariantes.
Estos proyectos intermedios de machine learning se centran en el procesamiento de datos y los modelos de entrenamiento para conjuntos de datos estructurados y no estructurados. Aprende a limpiar, procesar y ampliar el conjunto de datos utilizando diversas herramientas estadísticas.
El proyecto Revelar categorías encontradas en los datos te ayuda a explorar los comentarios de los clientes mediante la agrupación y el procesamiento del lenguaje natural (NLP). Organizarás las reseñas de Google Play Store en categorías distintas utilizando el método de agrupamiento K-means. Comprender los temas comunes que se desprenden de los comentarios de los clientes es esencial para que los equipos de desarrollo de productos puedan abordar los puntos débiles de los usuarios, mejorar las funciones y aumentar la satisfacción de los usuarios mediante información útil.
Intenta replicar el resultado en un conjunto de datos diferente, como el conjunto de datos de películas de Netflix.
En el proyecto «Frecuencia de palabras en Moby Dick», extraerás el texto de la obra Moby Dick, de Herman Melville, y analizarás la frecuencia de las palabras utilizando la biblioteca nltk de Python. Este proyecto presenta técnicas clave del procesamiento del lenguaje natural (PLN) y ayuda a comprender cómo las palabras de uso frecuente revelan patrones en el texto. Es un gran proyecto para los entusiastas de la literatura, los historiadores o los investigadores interesados en la minería de textos y el análisis lingüístico.
En el proyecto «Reconocimiento facial con aprendizaje supervisado », crearás un modelo de reconocimiento facial utilizando técnicas de aprendizaje supervisado con Python y scikit-learn. El modelo distingue entre imágenes de Arnold Schwarzenegger y otras personas. Este proyecto es importante en el creciente campo de la tecnología de reconocimiento facial, con amplias aplicaciones en seguridad, sistemas de autenticación e incluso plataformas de redes sociales, donde la detección facial se utiliza habitualmente.
Crea un predictor de popularidad de libros para una librería en línea convirtiendo datos mixtos, como texto (por ejemplo, títulos y descripciones de libros) y datos numéricos (por ejemplo, valoraciones y recuentos), en características efectivas. Participarás en el flujo de trabajo completo del machine learning, que incluye el análisis exploratorio rápido de datos (EDA), la corrección de tipos de datos, la transformación de variables numéricas y de texto, y el ajuste de un modelo para lograr la mayor precisión posible.
Aprenderás a gestionar datos desordenados y multiformato, y a evaluar los resultados utilizando un proceso limpio y reutilizable. Al final de este proceso, podrás aplicar los mismos métodos a cualquier catálogo, ya sea tu lista de lectura personal o conjuntos de datos públicos, para predecir posibles éxitos de ventas y mejorar los sistemas de recomendación.
En el proyecto de agrupación de especies de pingüinos antárticos, utilizas el aprendizaje no supervisado para descubrir grupos naturales de pingüinos sin etiquetas. Limpiarás un conjunto de datos al estilo Palmer Penguins, gestionarás los valores perdidos, escalarás características numéricas como la longitud del pico, la profundidad del pico, la longitud de las aletas y la masa corporal, y, opcionalmente, codificarás contextos categóricos simples como la isla o el sexo antes de ejecutar K-means.mass. Opcionalmente, codifica variables categóricas simples como isla o sexo antes de aplicar el agrupamiento K-means.
A continuación, seleccionas el número de clústeres con puntuaciones de codo y silueta, visualizas la estructura con PCA y comparas los clústeres con especies conocidas para realizar una rápida comprobación de coherencia.
En la proyecto de optimización de rutas de taxi con aprendizaje por refuerzo, entrenas a un agente de aprendizaje Q para resolver el entorno Taxi-v3 Gymnasium mediante el aprendizaje de rutas eficientes de recogida y entrega. Crearás una tabla de valores de estado-acción, equilibrarás la exploración y la explotación con una política epsilon-greedy y ajustarás los hiperparámetros básicos, como la tasa de aprendizaje, el factor de descuento y el decaimiento epsilon, para acelerar la convergencia.

A continuación, evalúas el rendimiento con la recompensa media por episodio y los pasos necesarios para completarlo, visualizas la curva de aprendizaje y pruebas la política entrenada en episodios no vistos.
Utiliza el conjunto de datos sobre cáncer de mama de Wisconsin para predecir si un tumor es maligno o benigno. El conjunto de datos incluye detalles sobre las características del tumor, como la textura, el perímetro y el área, y tu objetivo es crear un modelo de clasificación que prediga un diagnóstico basándose en estas características.
Este proyecto es esencial en aplicaciones sanitarias, ya que proporciona información valiosa para el análisis de datos médicos y ofrece posibilidades para el desarrollo de herramientas de diagnóstico que pueden ayudar en la detección precoz del cáncer.
En el proyecto «Reconocimiento de emociones en el habla con Librosa», procesarás archivos de sonido utilizando Librosa, archivos de sonido y sklearn para que MLPClassifier reconozca las emociones a partir de los archivos de sonido.
Cargarás y procesarás archivos de sonido, realizarás la extracción de características y entrenarás el modelo clasificador Multi-Layer Perceptron. El proyecto te enseñará los conceptos básicos del procesamiento de audio para que puedas avanzar en el entrenamiento de un modelo de aprendizaje profundo y lograr una mayor precisión.
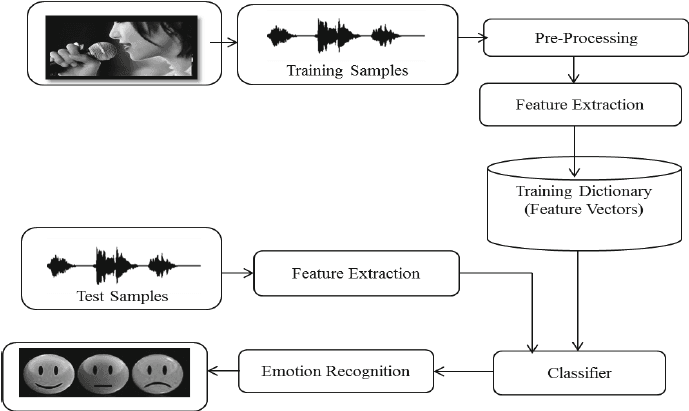
Imagen de researchgate.net
Estos proyectos avanzados de machine learning se centran en la creación y el entrenamiento de modelos de machine learning profundo y en el procesamiento de conjuntos de datos no estructurados. Entrenarás redes neuronales convolucionales, unidades recurrentes con compuerta, ajustarás modelos de lenguaje grandes y modelos de aprendizaje por refuerzo.
En el proyecto «Clasificación de tickets de servicio técnico con aprendizaje profundo», creas un clasificador de texto PyTorch que dirige automáticamente los tickets entrantes a la categoría correcta. Limpiarás y tokenizarás texto, crearás divisiones de entrenamiento y validación, convertirás tickets en representaciones vectoriales y entrenarás un modelo neuronal compacto mientras ajustas el tamaño del lote, la tasa de aprendizaje y la regularización para lograr una convergencia estable.
A continuación, evalúas con precisión y F1 ponderado, inspeccionas una matriz de confusión para detectar categorías mal etiquetadas o superpuestas, y aplicas técnicas para el desequilibrio de clases, como la pérdida ponderada.
En el proyecto «Crear un bot de Rick Sánchez con Transformers», utilizarás DialoGPT y la biblioteca Hugging Face Transformer para crear tu chatbot con tecnología de inteligencia artificial.
Procesarás y transformarás tus datos, crearás y ajustarás el modelo de generación de respuestas preentrenado a gran escala de Microsoft (DialoGPT) en el conjunto de datos de diálogos de Rick y Morty. También puedes crear una sencilla aplicación Gradio para probar tu modelo en tiempo real: Fiesta callejera de Rick y Morty.
El proyecto «Creación de un modelo clasificador de ropa para comercio electrónico con Keras » se centra en la clasificación de imágenes en el contexto del comercio electrónico. Utilizarás Keras para crear un modelo de machine learning que automatice la clasificación de prendas de vestir a partir de imágenes. Esto es importante para mejorar la experiencia de compra, ya que ayuda a los clientes a encontrar los productos más rápidamente y agiliza la gestión del inventario. Una clasificación precisa también permite ofrecer recomendaciones personalizadas, lo que aumenta la participación de los clientes y las ventas.
En el proyecto Detectar señales de tráfico con aprendizaje profundo, utilizarás Keras para desarrollar un modelo de aprendizaje profundo capaz de detectar señales de tráfico, como señales de stop y semáforos. Esta tecnología es fundamental para los vehículos autónomos, en los que el reconocimiento rápido y preciso de las señales de tráfico es esencial para una conducción segura. Este proyecto sienta las bases para desarrollar sistemas de vehículos autónomos más avanzados, seguros y fiables.
En el proyecto Creación de un modelo de previsión de la demanda, utilizas PySpark para predecir la demanda de productos de comercio electrónico a gran escala. Cargarás datos transaccionales, diseñarás características basadas en el tiempo, como retrasos y medias móviles, divididas por tiempo para una evaluación honesta, y entrenarás una línea de base junto con un modelo de aprendizaje, como árboles impulsados por gradientes o bosques aleatorios, para capturar tendencias y estacionalidad.
A continuación, evalúas con MAE, RMSE y MAPE, comparas con la línea de base y analizas los errores por SKU y ventana de tiempo para detectar sesgos y volatilidad.
En el proyecto Predicción de la temperatura en Londres, realizas un experimento de aprendizaje automático estructurado para pronosticar la temperatura media diaria a partir de datos meteorológicos históricos. Cargarás y limpiarás el conjunto de datos, crearás divisiones temporales, diseñarás características como medias móviles y valores retardados, y entrenarás varios modelos candidatos utilizando scikit-learn.
A continuación, organizas el flujo de trabajo con funciones reutilizables y programas todo en MLflow, registrando parámetros, métricas y artefactos para comparar ejecuciones.
Connect X es una competición de simulación organizada por Kaggle. Crea un agente RL (aprendizaje por refuerzo) para competir contra otros participantes en la competición Kaggle.
Primero aprenderás cómo funciona el juego y crearás un agente funcional ficticio como referencia. A continuación, empezarás a experimentar con diversos algoritmos RL y arquitecturas de modelos. Puedes intentar crear un modelo basado en el algoritmo Deep Q-learning o Proximal Policy Optimization.
El proyecto de fin de carrera requiere que dediques una cierta cantidad de tiempo a crear una solución única. Investigarás múltiples arquitecturas de modelos, utilizarás diversos marcos de machine learning para normalizar y ampliar los conjuntos de datos, comprenderás las matemáticas que hay detrás del proceso y redactarás una tesis basada en tus resultados.
En el modelo ASR multilingüe, ajustarás el modelo Wave2Vec XLS-R utilizando audio y transcripciones en turco para crear un sistema de reconocimiento automático del habla.
En primer lugar, comprenderás los archivos de audio y el conjunto de datos de texto, luego utilizarás un tokenizador de texto, extraerás características y procesarás los archivos de audio. A continuación, crearás un entrenador, la función WER, cargarás modelos preentrenados, ajustarás los hiperparámetros y entrenarás y evaluarás el modelo.
Puedes utilizar la plataforma Hugging Face para almacenar los pesos del modelo y publicar aplicaciones web para transcribir el habla en tiempo real: Transmisión en directo de Urdu Asr.
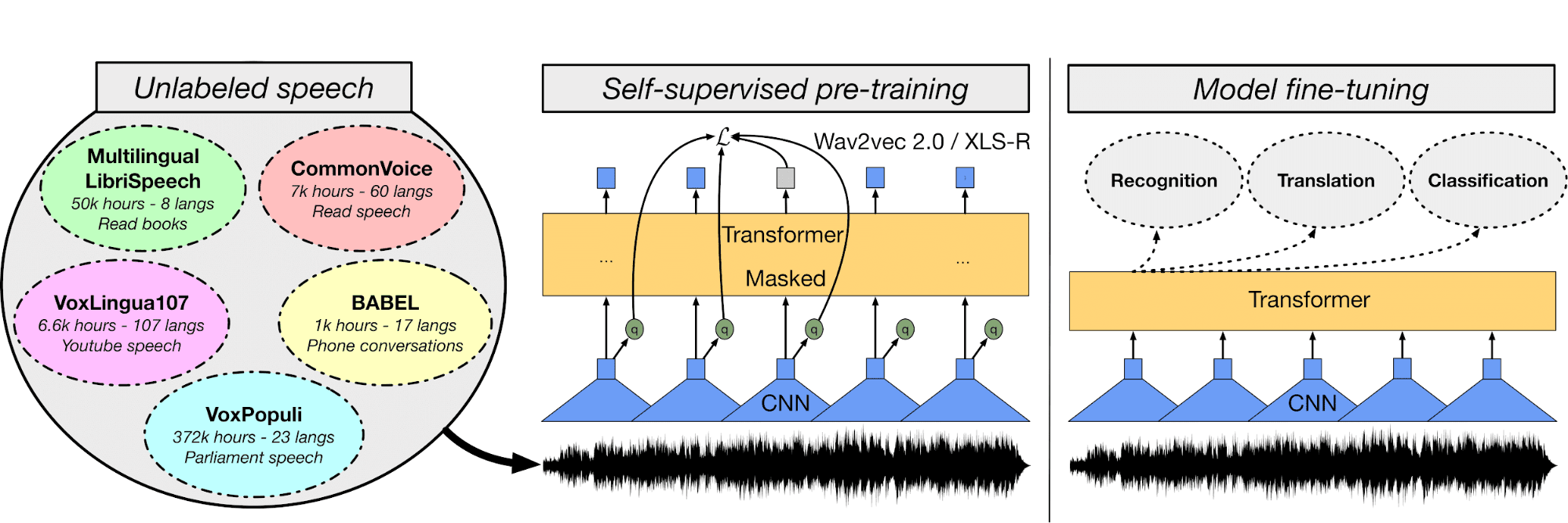
Imagen de huggingface.co
En el proyecto One Shot Face Stylization, puedes modificar el modelo para mejorar los resultados o ajustar JoJoGAN en un nuevo conjunto de datos para crear tu aplicación de estilización.
Utilizará la imagen original para generar una nueva imagen mediante la inversión GAN y el ajuste fino de un StyleGAN preentrenado. Comprenderás diversas arquitecturas de redes generativas adversarias. Después, comenzarás a recopilar un conjunto de datos emparejados para crear el estilo que elijas.
A continuación, con la ayuda de una solución de muestra de la versión anterior de StyleGAN, experimentarás con la nueva arquitectura para producir arte realista.
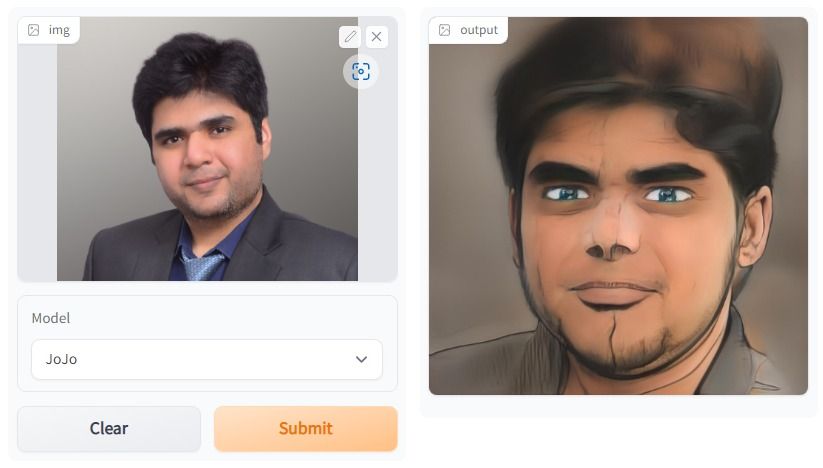
La imagen se ha creado con JoJoGAN.
En el proyecto Recomendaciones de moda personalizadas de H&M, crearás recomendaciones de productos basadas en transacciones anteriores, datos de clientes y metadatos de productos.
El proyecto pondrá a prueba tus habilidades en PNL, CV (visión artificial) y aprendizaje profundo. En las primeras semanas, comprenderás los datos y cómo puedes utilizar diversas funciones para establecer una base de referencia.
A continuación, crea un modelo sencillo que solo tenga en cuenta el texto y las características categóricas para predecir recomendaciones. A continuación, pasa a combinar NLP y CV para mejorar tu puntuación en la tabla de clasificación. También puedes comprender mejor el problema revisando los debates y el código de la comunidad.

Imagen de H&M EDA FIRST LOOK
En el proyecto «Análisis de llamadas de atención al cliente», creas un proceso integral que convierte el audio sin procesar en información útil. Transcribirás llamadas con un modelo de reconocimiento automático del habla, limpiarás y segmentarás el texto, realizarás análisis de opiniones y extraerás entidades como productos, planes, ubicaciones y nombres. También indexarás transcripciones con incrustaciones para permitir una búsqueda semántica rápida en todas las conversaciones.
A continuación, evalúas la calidad de la transcripción y el rendimiento del modelo, agrupas los temas para revelar los factores comunes que impulsan las llamadas y destacas aspectos como los picos de sentimiento negativo o las palabras clave de escalada.
En el proyecto «Monitorización de un modelo de detección de fraude financiero, actuarás como científico de datos tras la implementación para un banco del Reino Unido, diagnosticando por qué un modelo de fraude en tiempo real está fallando. Cargarás predicciones y resultados de producción, programaras el seguimiento de métricas básicas como precisión, recuperación, PR-AUC y calibración, y visualizarás el rendimiento a lo largo del tiempo para detectar cualquier degradación. También realizarás un análisis por canal, región y segmento de clientes para detectar dónde se concentran los falsos positivos o los falsos negativos.
A continuación, compruebas la deriva de datos y conceptos mediante comprobaciones de distribución e índices de estabilidad, inspeccionas los cambios en la importancia de las características y utilizas herramientas de explicabilidad para comparar el comportamiento actual con el de referencia.
En el proyecto MuZero para Atari 2600, crearás, entrenarás y validarás el agente de aprendizaje por refuerzo utilizando el algoritmo MuZero para juegos de Atari 2600. Lee el tutorial para comprender mejor el algoritmo MuZero.
El objetivo es crear una arquitectura nueva o modificar la existente para mejorar la puntuación en una clasificación mundial. Se necesitarán más de tres meses para comprender cómo funciona el algoritmo en el aprendizaje por refuerzo.
Este proyecto requiere muchos conocimientos matemáticos y experiencia en Python. Puedes encontrar soluciones propuestas, pero para alcanzar el primer puesto en el mundo, tienes que crear tu propia solución.
El proyecto MLOps End-To-End machine learning es necesario para que puedas ser contratado por las mejores empresas. Hoy en día, los reclutadores buscan ingenieros de ML que puedan crear sistemas integrales utilizando herramientas MLOps, orquestación de datos y nube.
En este proyecto, crearás e implementarás un clasificador de imágenes de ubicación utilizando TensorFlow, Streamlit, Docker, Kubernetes, Cloudbuild, GitHub y Google Cloud. El objetivo principal es automatizar la creación y la implementación de modelos de machine learning en la producción mediante CI/CD. Para obtener orientación, lee el tutorial sobre machine learning, canalizaciones, implementación y MLOps.
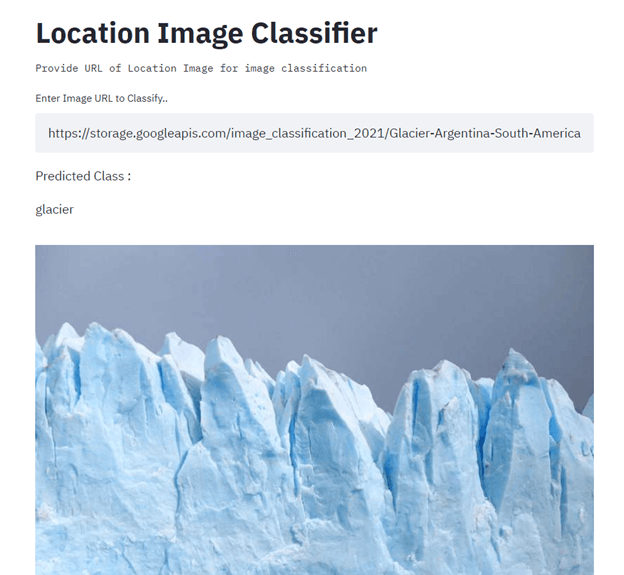
Imagen de Senthil E.
Para crear tu portafolio de machine learning, necesitas proyectos que destaquen. Demuestra al responsable de contratación o al reclutador que sabes programar en varios lenguajes, que comprendes diversos marcos de machine learning, que sabes resolver problemas únicos utilizando machine learning y que comprendes el ecosistema del machine learning de principio a fin.
En el proyecto Fine-Tuning GPT-OSS , instalarás las dependencias, cargarás el modelo y el tokenizador, definirás un estilo de prompt claro con el paquete Harmony Python y ejecutarás una inferencia de referencia rápida para confirmar que todo funciona de principio a fin.
A continuación, preparas un conjunto de datos de preguntas y respuestas médicas con formato Harmony, configuras el entrenamiento y ajustas el modelo, seguido de una evaluación posterior al ajuste para medir las mejoras.
En el proyecto Fine-Tuning MedGemma on a Brain MRI Dataset, adaptas el modelo multimodal MedGemma 4B, el codificador de imágenes SigLIP y un LLM ajustado para uso médico, con el fin de clasificar las resonancias magnéticas cerebrales. Configurarás el entorno en RunPod, instalarás los paquetes Python necesarios, cargarás y limpiarás un conjunto de datos de resonancia magnética y prepararás las entradas con un redimensionamiento, una normalización y una asignación de etiquetas coherentes antes de ejecutar una inferencia de verificación rápida.
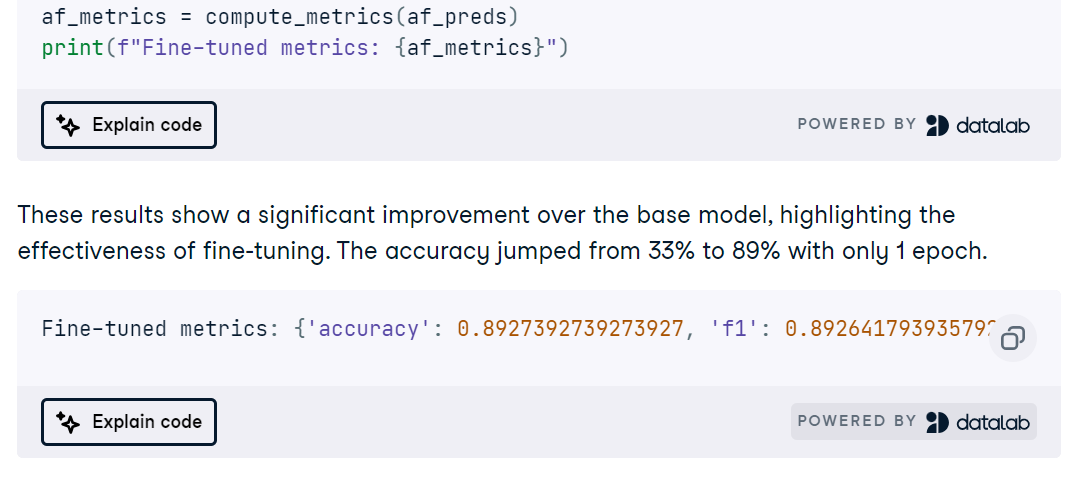
A continuación, ajustas MedGemma en la tarea de resonancia magnética, programas las curvas de entrenamiento y evalúas con precisión, ROC AUC, precisión, recuperación y matrices de confusión para detectar modos de fallo.
En el proyecto «Ajuste fino de Stable Diffusion XL con DreamBooth y LoRA, configuras SDXL en Python con difusores, cargas el modelo base FP16 y VAE en una GPU CUDA y generas imágenes a partir de indicaciones breves. Explorarás mejoras rápidas de calidad con el refinador SDXL, compararás resultados y utilizarás una sencilla utilidad de parilla para revisar varias generaciones en paralelo.
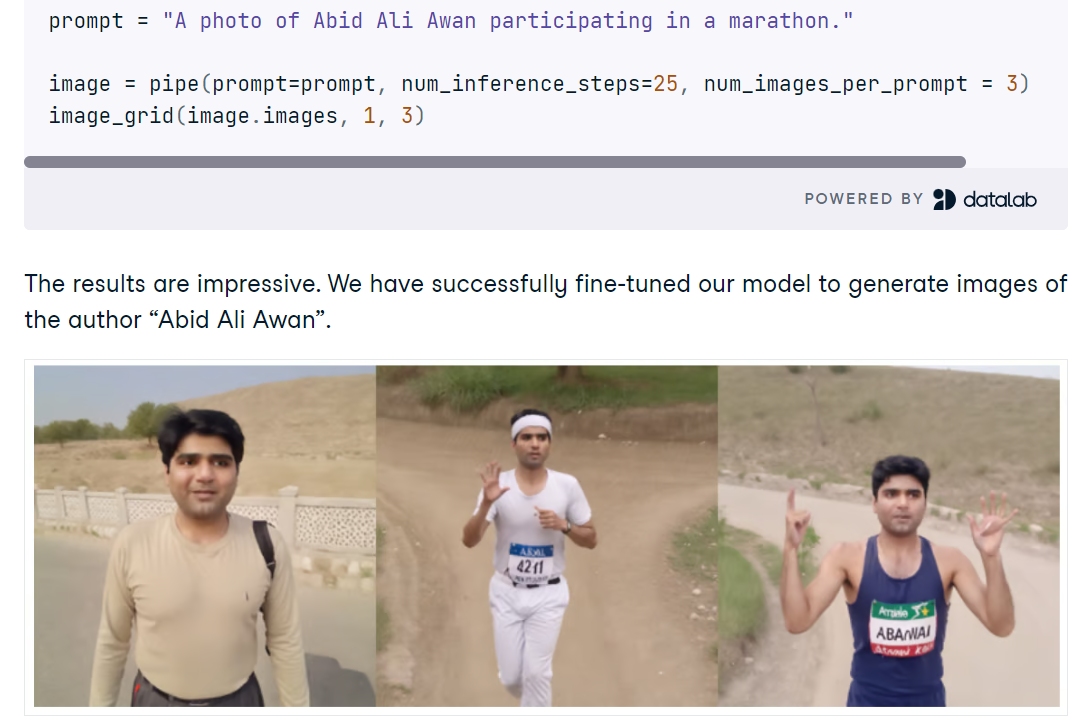
A continuación, ajustas SDXL en un pequeño conjunto de fotos personales utilizando AutoTrain Advanced con DreamBooth, lo que produce un adaptador LoRA compacto en lugar de un punto de control completo para una inferencia rápida y eficiente en términos de memoria. Después del entrenamiento, se añaden los pesos LoRA a la canalización base, se prueban nuevas indicaciones y se evalúa cuándo el refinador ayuda o perjudica la fidelidad de la identidad.
En la proyecto Song Generation with Latent Diffusion, creaste un modelo musical de difusión de código abierto para generar canciones completas a partir de indicaciones de estilo de texto o de un clip de audio de referencia. Instalarás a través de Conda o Docker, prepararás el entorno (espeak-ng, rutas de phonemizer en Windows) y ejecutarás los scripts de inferencia proporcionados para crear programas con los puntos de control básicos o completos, lo que permitirá la decodificación por fragmentos cuando la VRAM sea limitada.
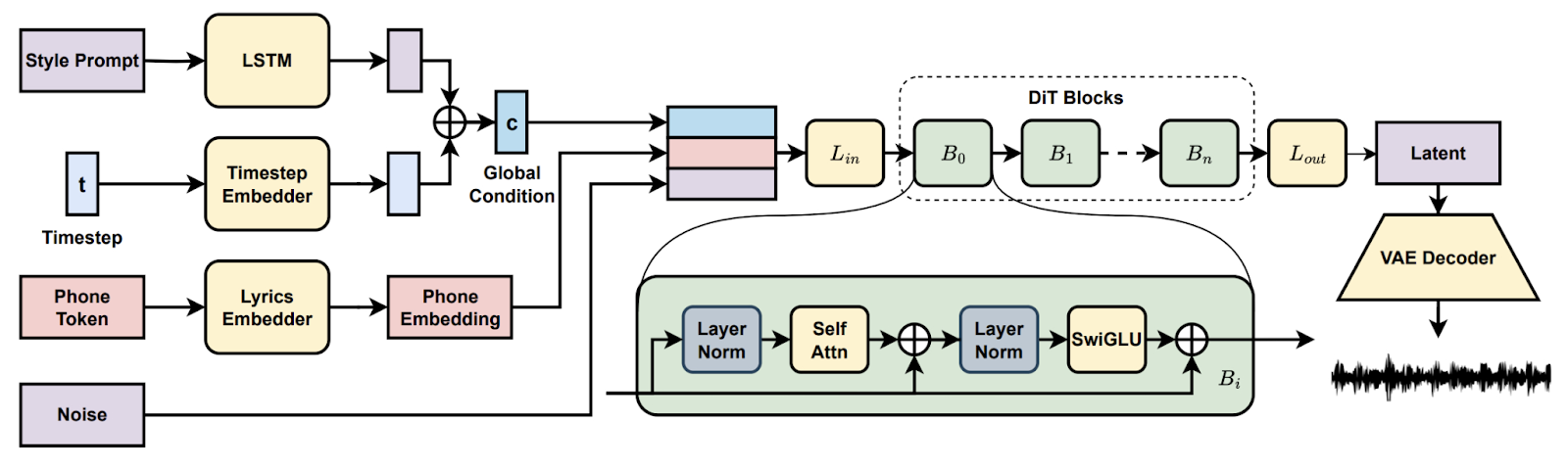
A continuación, exploras funciones como la continuación y la edición de canciones, comparas arreglos entre diferentes indicaciones y documentas la configuración para garantizar la reproducibilidad. Al final, tendrás un proceso práctico para la creación musical de principio a fin.
En el proyecto Implementación de una aplicación de machine learning en producción, creas un canal de aprendizaje automático totalmente automatizado con GitHub Actions que entrena, evalúa, versiona e implementa un modelo sencillo de clasificación de medicamentos. Configuras la estructura del repositorio y el Makefile, añades la configuración del entorno, el linting, las pruebas unitarias y las comprobaciones de datos, y luego creas scripts de entrenamiento y evaluación reproducibles que registran métricas y artefactos.
A continuación, conectas la integración continua para que se active en las solicitudes de extracción y las inserciones principales, publicas los artefactos del modelo con CML y Hugging Face CLI, y promueves un modelo aprobado para su implementación a través de flujos de trabajo de implementación continua.
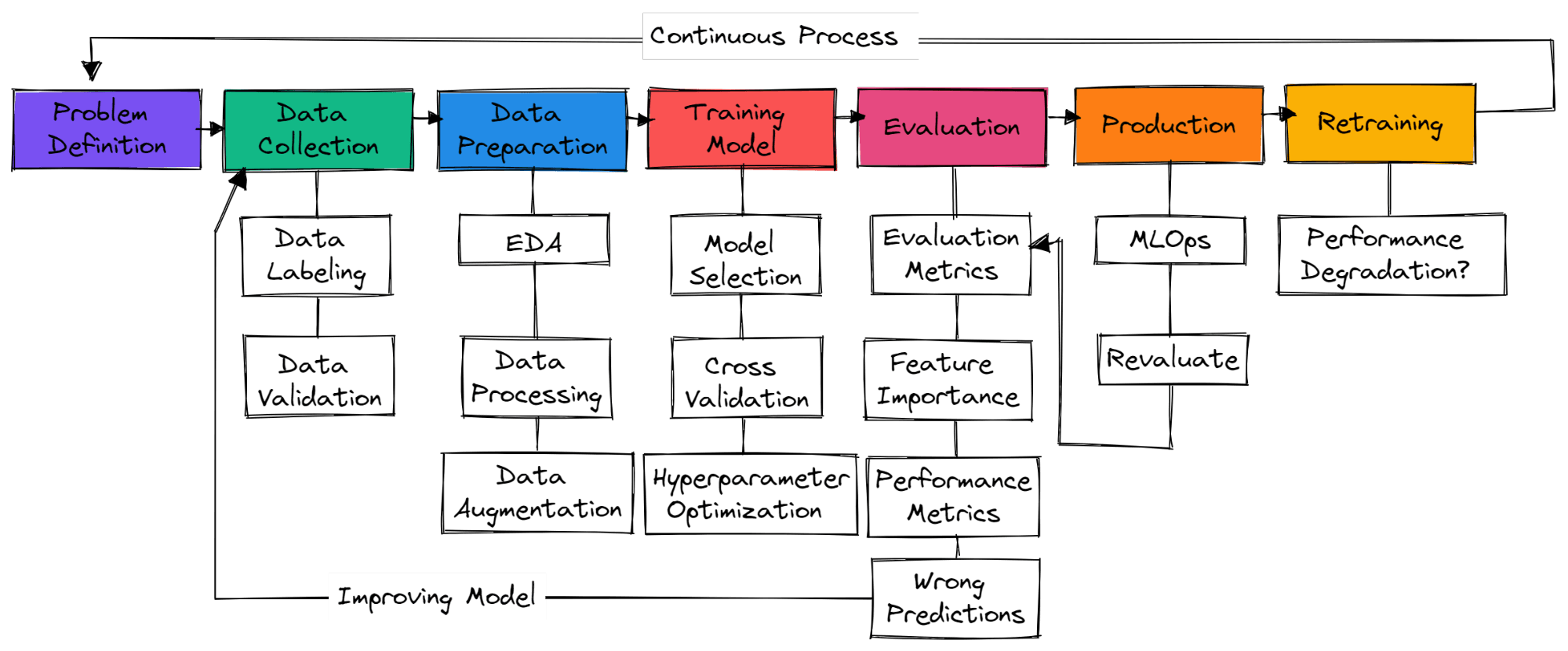
Imagen del autor
No hay pasos estándar en un proyecto típico de machine learning. Por lo tanto, puede tratarse simplemente de recopilación de datos, preparación de datos y entrenamiento de modelos. En esta sección, aprenderemos los pasos necesarios para crear un proyecto de machine learning listo para su uso en producción.
Debes comprender el problema empresarial y tener una idea aproximada de cómo vas a utilizar machine learning para resolverlo. Busca artículos de investigación, proyectos de código abierto, tutoriales y aplicaciones similares utilizadas por otras empresas. Asegúrate de que tu solución sea realista y de que los datos estén fácilmente disponibles.
Recopilarás datos de diversas fuentes, los limpiarás y etiquetarás, y crearás scripts para la validación de datos. Asegúrate de que tus datos no sean sesgados ni contengan información confidencial.
Rellenar los valores que faltan, limpiar y procesar los datos para su análisis. Utiliza herramientas de visualización para comprender la distribución de los datos y cómo puedes utilizar las funciones para mejorar el rendimiento del modelo. El escalado de características y el aumento de datos se utilizan para transformar datos para un modelo de machine learning.
Seleccionar redes neuronales o algoritmos de machine learning que se utilizan habitualmente para problemas específicos. Modelo de entrenamiento que utiliza validación cruzada y diversas técnicas de optimización de hiperparámetros para obtener resultados óptimos.
Evaluación del modelo en el conjunto de datos de prueba. Asegúrate de utilizar la métrica de evaluación del modelo adecuada para cada problema específico. La precisión no es una métrica válida para todo tipo de problemas. Comprueba la puntuación F1 o AUC para la clasificación o RMSE para la regresión. Visualiza la importancia de las características del modelo para eliminar aquellas que no sean importantes. Evalúa métricas de rendimiento como el tiempo de entrenamiento e inferencia del modelo.
Asegúrate de que el modelo haya superado el nivel básico humano. Si no es así, vuelve a recopilar más datos de calidad y comienza el proceso de nuevo. Se trata de un proceso iterativo en el que seguirás formándote en diversas técnicas de ingeniería de características, arquitectos de modos y marcos de machine learning para mejorar el rendimiento.
Después de lograr resultados de vanguardia, es hora de implementar tu modelo de machine learning en producción/nube utilizando herramientas MLOps. Supervisa el modelo con datos en tiempo real. La mayoría de los modelos fallan en la producción, por lo que es una buena idea implementarlos para un pequeño subconjunto de usuarios.
Si el modelo no logra resultados, volverás a empezar desde cero y encontrarás una solución mejor. Incluso si logras excelentes resultados, el modelo puede degradarse con el tiempo debido a la deriva de datos y la deriva conceptual. El reentrenamiento de nuevos datos también hace que tu modelo se adapte a los cambios en tiempo real.
Cursos de machine learning
Curso
Curso
Curso
blog
Abid Ali Awan
10 min
blog
Javier Canales Luna
8 min
blog
Matt Crabtree
14 min
blog
Abid Ali Awan
13 min
blog
Natassha Selvaraj
15 min
blog
Abid Ali Awan
8 min


