Introduction
Pipelines, Deployment, and MLOps are some very important concepts for data scientists today. Building a model in Notebook is not enough. Deploying pipelines and managing end-to-end processes with MLOps best practices is a growing focus for many companies. This tutorial discusses several important concepts like Pipeline, CI/DI, API, Container, Docker, Kubernetes. You will also learn about MLOps frameworks and libraries in Python. Finally, the tutorial shows end-to-end implementation of containerizing a Flask based ML web application and deploying it on Microsoft Azure cloud.
Key Concepts
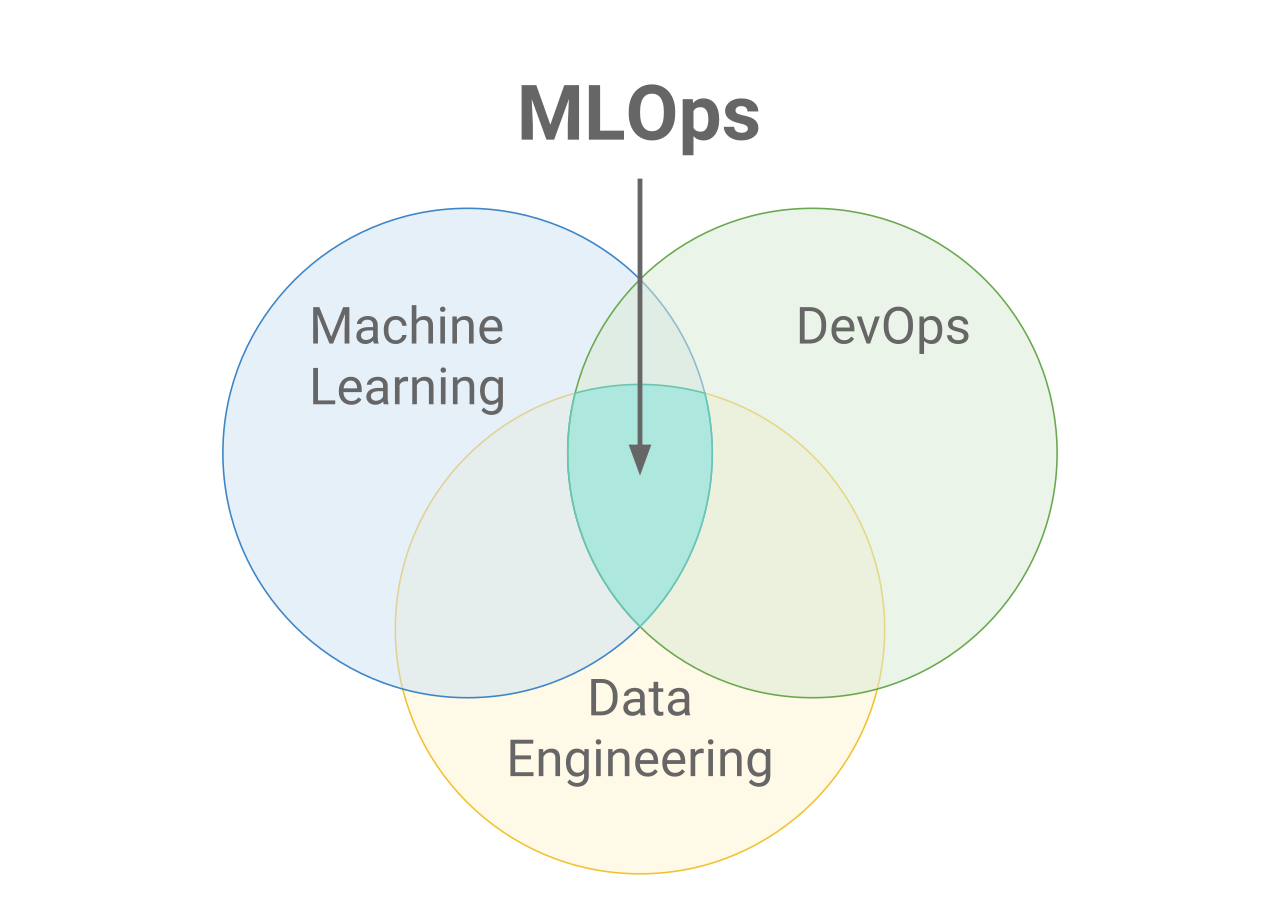
MLOps
MLOps stands for Machine Learning Operations. MLOps is focused on streamlining the process of deploying machine learning models to production, and then maintaining and monitoring them. MLOps is a collaborative function, often consisting of data scientists, ML engineers, and DevOps engineers. The word MLOps is a compound of two different fields i.e. machine learning and DevOps from software engineering.
MLOps can encompass everything from the data pipeline to machine learning model production. In some places, you will see MLOps implementation is only for the deployment of the machine learning model but you will also find enterprises with implementation of MLOps across many different areas of ML Lifecycle development, including Exploratory Data Analysis (EDA), Data Preprocessing, Model Training, etc.
While MLOps started as a set of best practices, it is slowly evolving into an independent approach to ML lifecycle management. MLOps applies to the entire lifecycle - from integrating with model generation (software development lifecycle and continuous integration/continuous delivery), orchestration, and deployment, to health, diagnostics, governance, and business metrics.
Why MLOps?
There are many goals enterprises want to achieve through MLOps. Some of the common ones are:
- Automation
- Scalability
- Reproducibility
- Monitoring
- Governance
MLOps vs DevOps
DevOps is an iterative approach to shipping software applications into production. MLOps borrows the same principles to take machine learning models to production. Either Devops or MLOps, the eventual objective is higher quality and control of software applications/ML models.
CI/CD: continuous integration, continuous delivery, and continuous deployment.
CI/CD is a practice derived from DevOps and it refers to an ongoing process of recognizing issues, reassessing, and updating the machine learning models automatically. The main concepts attributed to CI/CD are continuous integration, continuous delivery, and continuous deployment. It automates the machine learning pipeline (building, testing and deploying) and greatly reduces the need for data scientists to intervene in the process manually, making it efficient, fast, and less prone to human error.
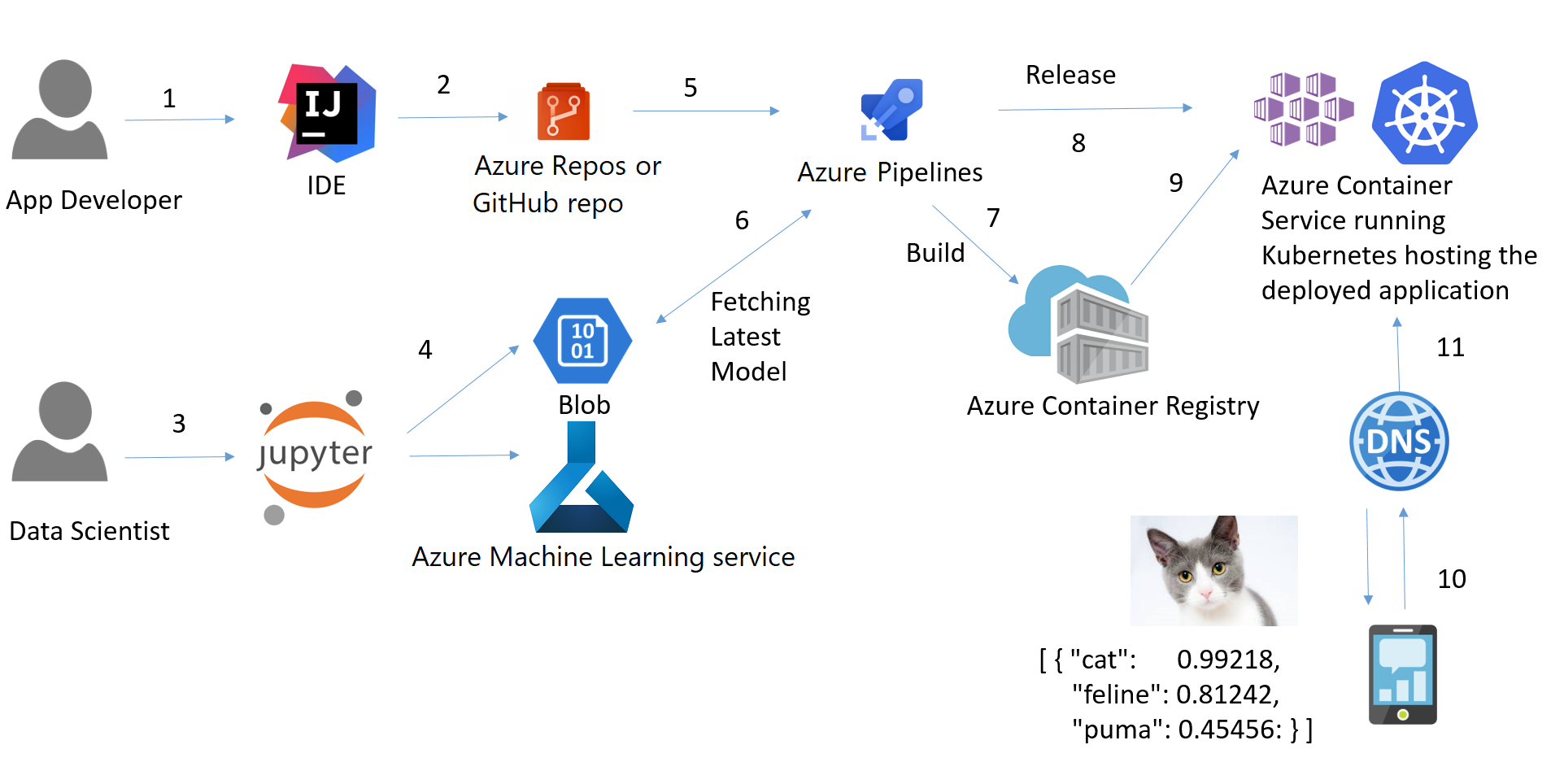
Pipeline
A machine learning pipeline is a way to control and automate the workflow it takes to produce a machine learning model. Machine learning pipelines consist of multiple sequential steps that do everything from data extraction and preprocessing to model training and deployment.
Machine learning pipelines are iterative as every step is repeated to continuously improve the accuracy of the model and achieve the end goal.
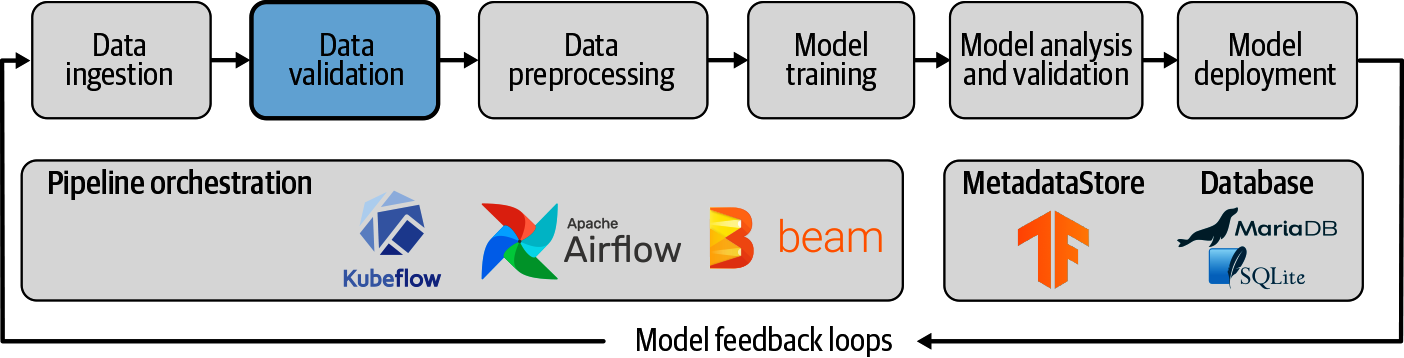
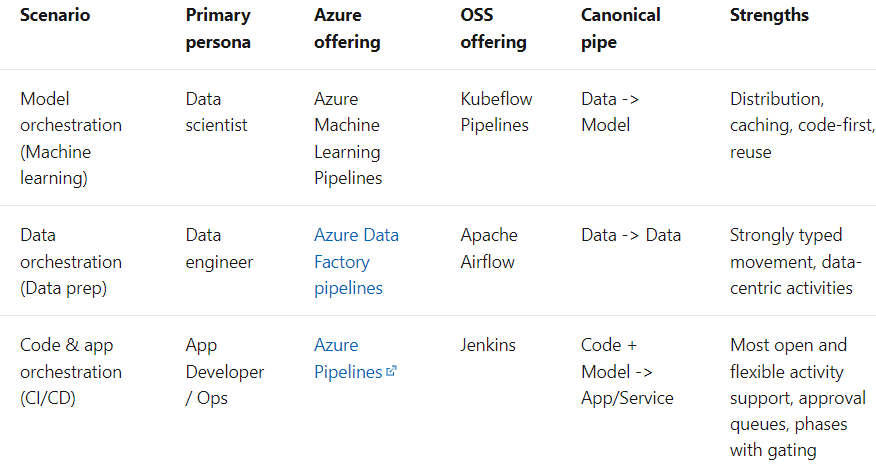
The term Pipeline is used generally to describe the independent sequence of steps that are arranged together to achieve a task. This task could be machine learning or not. Machine Learning Pipelines are very common but that is not the only type of pipeline that exists. Data Orchestration Pipelines are another example. According to Microsoft docs, there are three scenarios:
Deployment
The deployment of machine learning models (or pipelines) is the process of making models available in production where web applications, enterprise software (ERPs) and APIs can consume the trained model by providing new data points, and get the predictions.
In short, Deployment in Machine Learning is the method by which you integrate a machine learning model into an existing production environment to make practical business decisions based on data. It is the last stage in the machine learning lifecycle.
Normally the term Machine Learning Model Deployment is used to describe deployment of the entire Machine Learning Pipeline, in which the model itself is only one component of the Pipeline.
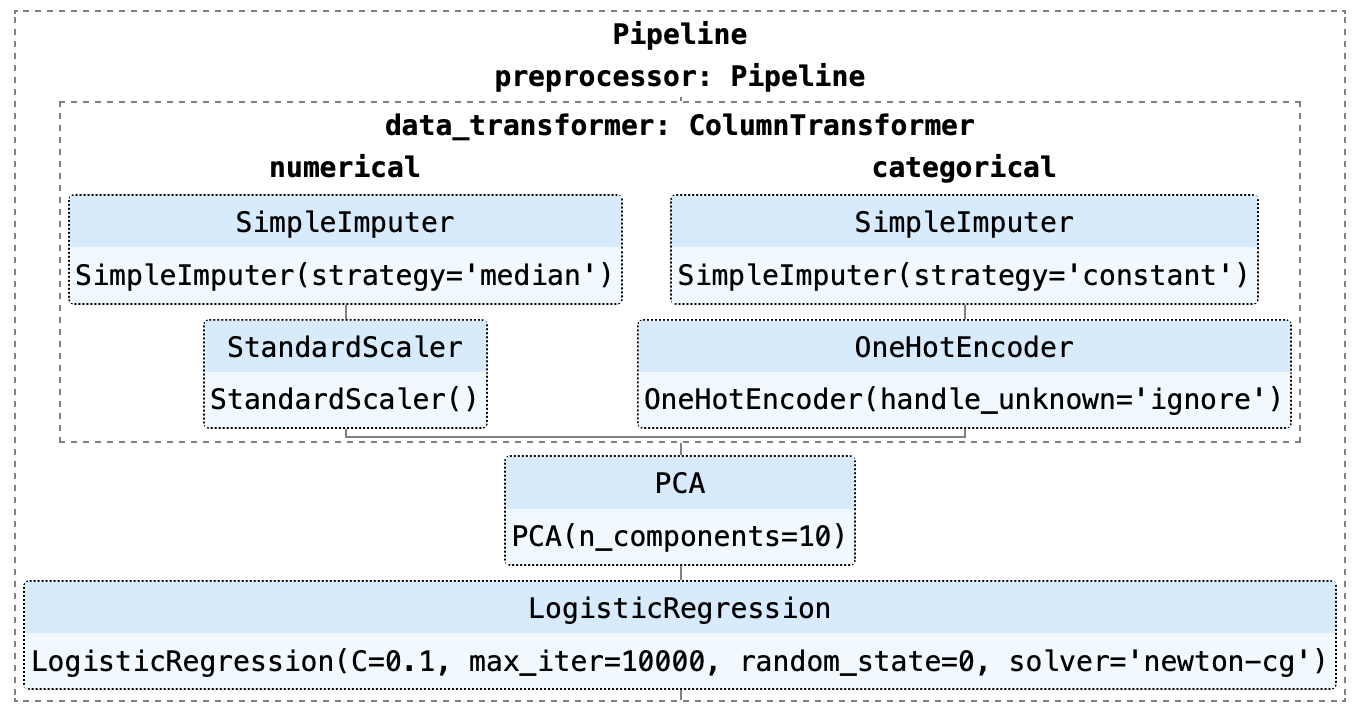
As you can see in the above example, this pipeline consists of a Logistic Regression model. There are several steps in the pipeline that have to be executed first before training can begin, such as Imputation of missing values, One-Hot encoding, Scaling, and Principal Component Analysis (PCA).
Application Programming Interface (API)
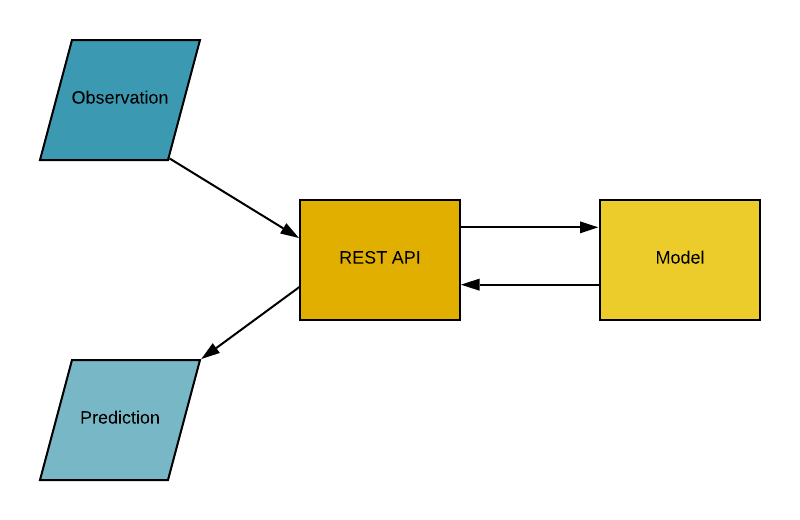
Application Programming Interface (API), is a software intermediary that allows two applications to talk to each other. In simple words, an API is a contract between two applications saying if the user software provides input in a pre-defined format, the API will provide the outcome to the user. In other words, API is an end-point where you host the trained machine learning models / (pipelines) for use. In practice it looks something like this:
Container
Have you ever had the problem where your python code (or any other code) works fine on your computer but when your friend tries to run the exact same code, it doesn't work? If your friend is repeating the exact same steps, they should get the same results, right? The simple answer to this is that your friend's Python environment is different to yours.
What does an environment include?
Python (or any other language you have used) and all the libraries and dependencies used to build that application.
If we can somehow create an environment that we can transfer to other machines (e.g., your friend's computer or a cloud service provider like Microsoft Azure, AWS or GCP), we can reproduce the results anywhere. A container is a type of software that packages up an application and all its dependencies so the application can run reliably from one computing environment to another.
The most intuitive way to understand containers in data science is to think about containers on a vessel or a ship. The goal is to isolate the contents of one container from the others so they don't get mixed up. This is exactly what containers are used for in data science.
Now that we understand the metaphor behind containers, let's look at alternate options for creating an isolated environment for our application. One simple alternative is to have a separate machine for each of your applications.
Using a separate machine is straightforward but it doesn't outweigh the benefits of using containers, since maintaining multiple machines for each application is expensive, a nightmare to maintain and hard to scale. In short, it's not practical in many real-life scenarios.
Another alternative for creating an isolated environment is to use virtual machines. Containers are again preferable here because they require fewer resources, are very portable, and are faster to spin up.
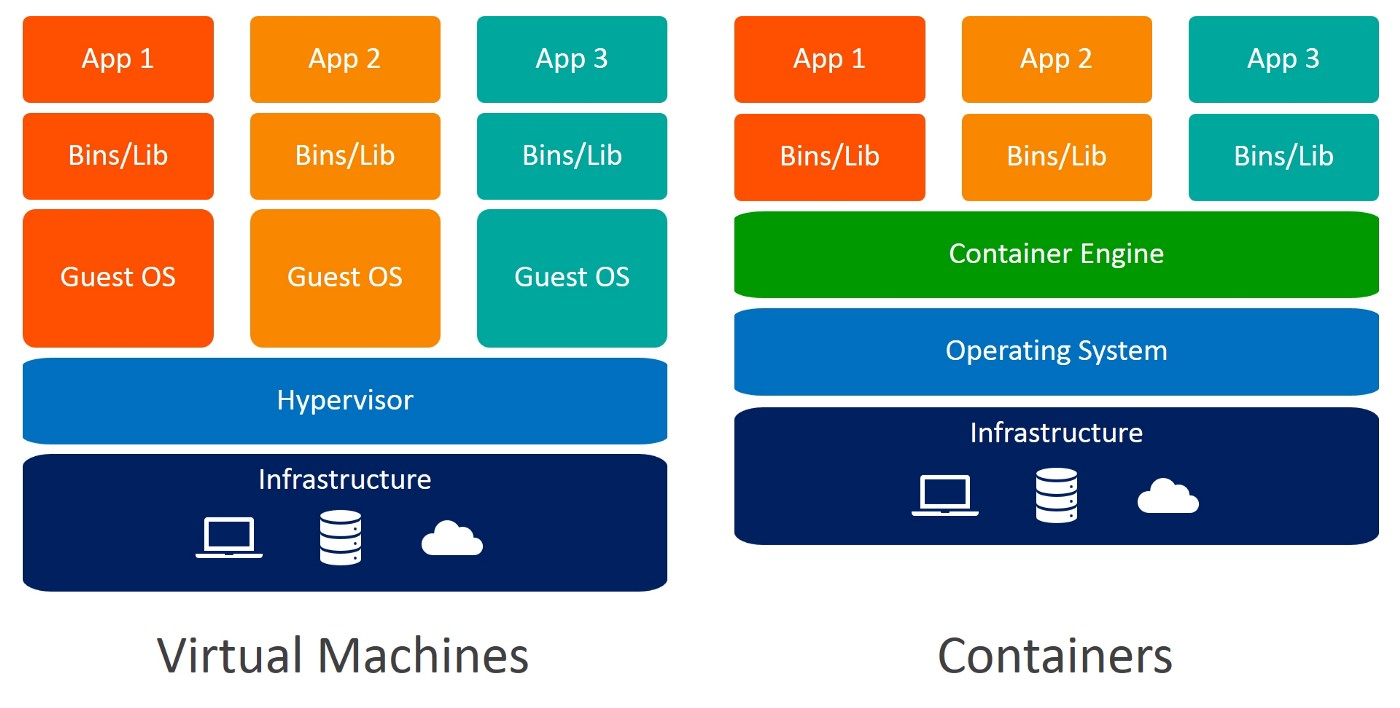
Can you identify the differences between Virtual Machines and Containers? When you use containers, you do not require guest operating systems. Imagine 10 applications running on a virtual machine. This would require 10 guest operating systems compared to none required when you use containers.
Docker
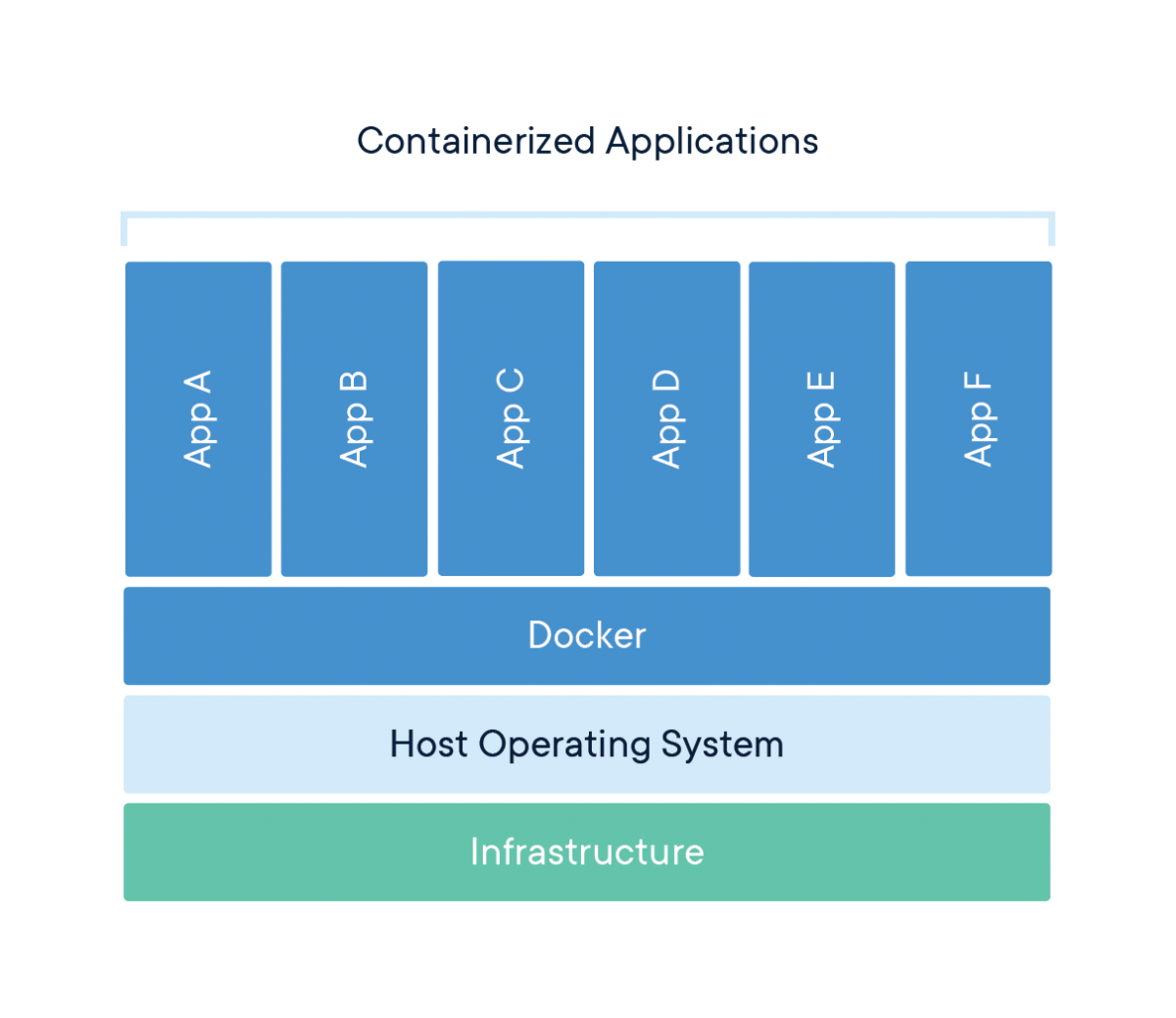
Docker is a company that provides software (also called Docker) that allows users to build, run and manage containers. While Docker's containers are the most common, other less famous alternatives such as LXD and LXC also provide container solutions.
Docker is a tool designed to make it easier to create, deploy, and run applications by using containers. Containers are used to package up an application with all of its necessary components, such as libraries and other dependencies, and ship it all out as one package.
Breaking the hype
At the end of the day, Docker is just a file with a few lines of instructions that are saved under your project folder with the name "Dockerfile".
Another way to think about Docker files is that they are like recipes you have invented in your own kitchen. When you share those recipes with somebody else and they follow the exact same instructions, they are able to produce the same dish. Similarly, you can share your Docker files with other people, who can then create images and run containers based on that particular Docker file.
Kubernetes
Developed by Google back in 2014, Kubernetes is a powerful, open-source system for managing containerized applications. In simple words, Kubernetes is a system for running and coordinating containerized applications across a cluster of machines. It is a platform designed to completely manage the life cycle of containerized applications.
Features
- Load Balancing: Automatically distributes the load between containers.
- Scaling: Automatically scale up or down by adding or removing containers when demand changes, such as at peak hours, and during weekends and holidays.
- Storage: Keeps storage consistent with multiple instances of an application.
Why do you need Kubernetes if you have Docker?
Imagine a scenario where you have to run multiple Docker containers, on multiple machines, to support an enterprise-level ML application with varied workloads day and night. As simple as it may sound, it is a lot of work to do manually.
You need to start the right containers at the right time, figure out how they can talk to each other, handle storage considerations, and deal with failed containers or hardware. This is the problem Kubernetes is solving, by allowing large numbers of containers to work together in harmony, and reducing the operational burden.
Google Kubernetes Engine is an implementation of Google's open-source Kubernetes on Google Cloud Platform. Other popular alternatives to GKE are Amazon ECS and Microsoft Azure Kubernetes Service.
Quick re-cap of terms:
- A Container is a type of software that packages up an application and all its dependencies so the application runs reliably from one computing environment to another.
- Docker is software used for building and managing containers.
- Kubernetes is an open-source system for managing containerized applications in a clustered environment.
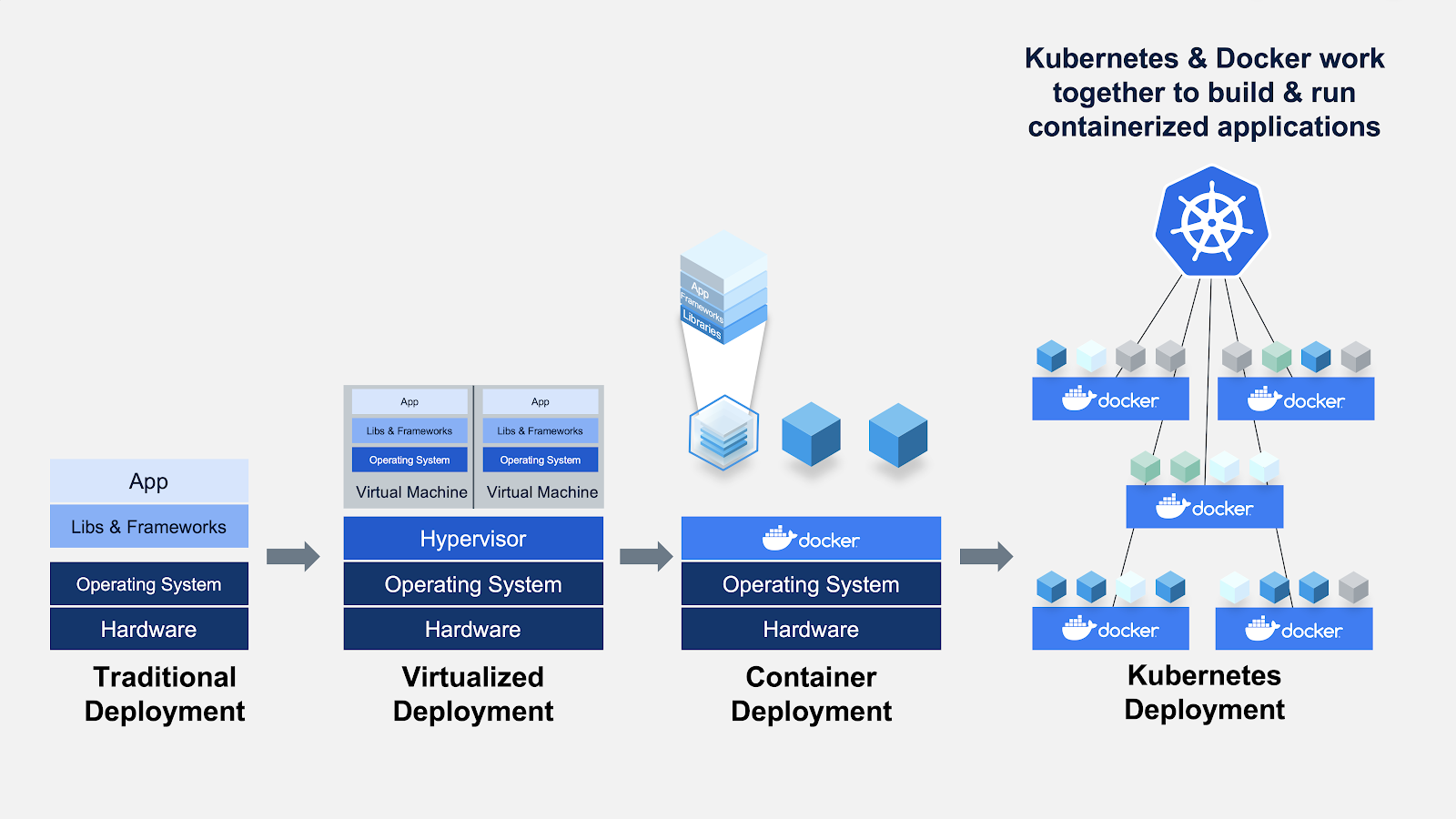
MLOps Frameworks and Libraries in Python
MLflow
MLflow is an open-source platform to manage the ML lifecycle, including experimentation, reproducibility, deployment, and a central model registry. MLflow currently offers MLflow tracking, MLflow Projects, MLflow Models, and Model Registry.
Metaflow
Metaflow is a human-friendly Python library that helps scientists and engineers build and manage real-life data science projects. Metaflow was originally developed at Netflix to boost the productivity of data scientists who work on a wide variety of projects, from classical statistics to state-of-the-art deep learning. Metaflow provides a unified API to the infrastructure stack that is required to execute data science projects, from prototype to production.
Kubeflow
Kubeflow is an open-source, machine learning platform, designed to allow machine learning pipelines to orchestrate complicated workflows running on Kubernetes. Kubeflow was based on Google's internal method to deploy TensorFlow models called TensorFlow Extended.
Kedro
Kedro is an open-source Python framework for creating reproducible, maintainable and modular data science code. It borrows concepts from software engineering best practices, and applies them to machine-learning code; applied concepts include modularity, separation of concerns and versioning.
FastAPI
FastAPI is a Web framework for developing RESTful APIs in Python. FastAPI is based on Pydantic and type hints to validate, serialize, and deserialize data, and automatically auto-generate OpenAPI documents.
ZenML
ZenML is an extensible, open-source MLOps framework to create production-ready machine learning pipelines. Built for data scientists, it has a simple, flexible syntax, is cloud- and tool-agnostic, and has interfaces/abstractions that are catered towards ML workflows.
Example: End-to-End Pipeline Development, Deployment, and MLOps
Problem Setup
An insurance company wants to improve its cash flow forecasting by better predicting patient charges, using demographic and basic patient health-risk metrics at the time of hospitalization.
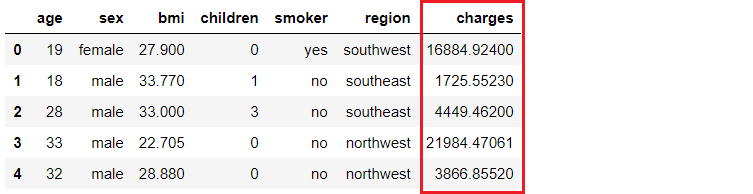
Our objective is to build and deploy a web application where the demographic and health information of a patient is entered into a web-based form, which then outputs a predicted charge amount. To achieve this we will do the following:
- Train and develop a machine learning pipeline for deployment (simple linear regression model).
- Build a web app using the Flask framework. It will use the trained ML pipeline to generate predictions on new data points in real-time (front-end code is not the focus of this tutorial).
- Create a Docker image and container.
- Publish the container onto the Azure Container Registry (ACR).
- Deploy the web app in the container by publishing onto ACR. Once deployed, it will become publicly available and can be accessed via a Web URL.
Machine Learning Pipeline
I will be using PyCaret in Python for training and developing a machine learning pipeline that will be used as part of our web app. You can use any framework you like as the subsequent steps don't depend on this.
# load dataset
from pycaret.datasets import get_data
insurance = get_data('insurance')
# init environment
from pycaret.regression import *
r1 = setup(insurance, target = 'charges', session_id = 123,
normalize = True,
polynomial_features = True, trigonometry_features = True,
feature_interaction=True,
bin_numeric_features= ['age', 'bmi'])
# train a model
lr = create_model('lr')
# save pipeline/model
save_model(lr, model_name = 'c:/username/pycaret-deployment-azure/deployment_28042020')
When you save a model in PyCaret, the entire transformation pipeline is created, based on the configuration defined in the setup function. All inter-dependencies are orchestrated automatically. See the pipeline and model stored in the 'deployment_28042020' variable:

Front-end Web Application
This tutorial is not focused on building a Flask application. It is only discussed here for completeness. Now that our machine learning pipeline is ready, we need a web application that can read our trained pipeline, to predict new data points. There are two parts of this application:
- Front-end (designed using HTML)
- Back-end (developed using Flask)
This is how the front-end looks:
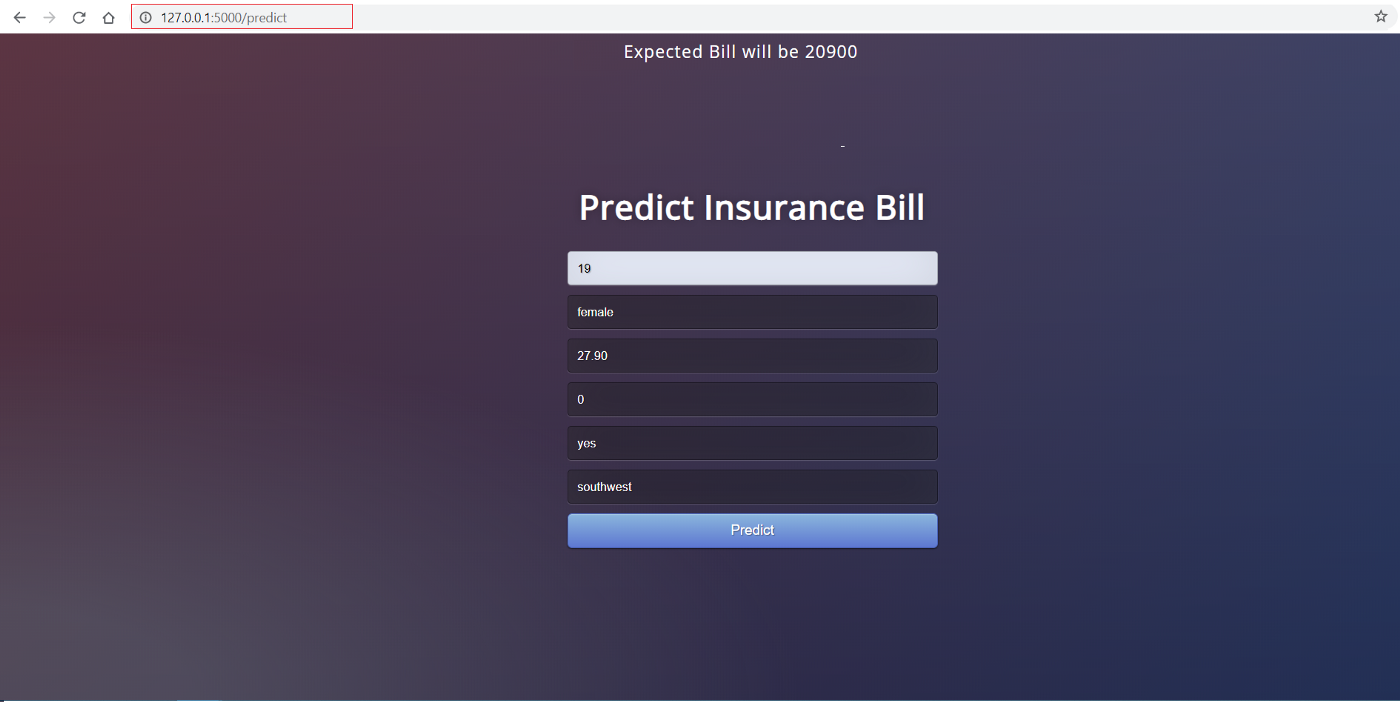
The front-end of this application is really simple HTML with some CSS styling. If you want to check out the code, please see this repo. Now that we have a fully functional web application, we can start the process of containerizing the application using Docker.
Back-end of the application
The back-end of the application is a Python file named app.py. It is built using the Flask framework.
from flask import Flask,request, url_for, redirect, render_template, jsonify
from pycaret.regression import *
import pandas as pd
import pickle
import numpy as np
app = Flask(__name__)
model = load_model('deployment_28042020')
cols = ['age', 'sex', 'bmi', 'children', 'smoker', 'region']
@app.route('/')
def home():
return render_template("home.html")
@app.route('/predict',methods=['POST'])
def predict():
int_features = [x for x in request.form.values()]
final = np.array(int_features)
data_unseen = pd.DataFrame([final], columns = cols)
prediction = predict_model(model, data=data_unseen, round = 0)
prediction = int(prediction.Label[0])
return render_template('home.html',pred='Expected Bill will be {}'.format(prediction))
@app.route('/predict_api',methods=['POST'])
def predict_api():
data = request.get_json(force=True)
data_unseen = pd.DataFrame([data])
prediction = predict_model(model, data=data_unseen)
output = prediction.Label[0]
return jsonify(output)
if __name__ == '__main__':
app.run(debug=True)
Docker Container
If you are using Windows you will have to install Docker for Windows. If you are using Ubuntu, Docker comes by default and no installation is needed.
The first step in containerizing your application is to write a Dockerfile in the same folder/directory where your application resides. A Dockerfile is just a file with a set of instructions. The Dockerfile for this project looks like this:
FROM python:3.7
RUN pip install virtualenv
ENV VIRTUAL_ENV=/venv
RUN virtualenv venv -p python3
ENV PATH="VIRTUAL_ENV/bin:$PATH"
WORKDIR /app
ADD . /app
# install dependencies
RUN pip install -r requirements.txt
# expose port
EXPOSE 5000
# run application
CMD ["python", "app.py"]
Dockerfile is case-sensitive and must be in the project folder with the other project files. A Dockerfile has no extension and can be created using any editor. We have used Visual Studio Code to create it.
Cloud Deployment
After setting up Dockerfile correctly we will write some commands to create a Docker image from this file, but first, we need a service to host that image. In this example, we will be using Microsoft Azure to host our application.
Azure Container Registry
If you don't have a Microsoft Azure account or haven't used it before, you can sign up for free. When you sign up for the first time you get a free credit for the first 30 days. You can utilize that credit to build and deploy a web app on Azure. Once you sign up, follow these steps:
- Login on https://portal.azure.com
- Click on Create a Resource
- Search for Container Registry and click on Create
- Select Subscription, Resource group and Registry name (in our case: pycaret.azurecr.io is our registry name)
Once a registry is created, the first step is to build a Docker image using the command line. Navigate to the project folder and execute the following code:
docker build -t pycaret.azurecr.io/pycaret-insurance:latest .
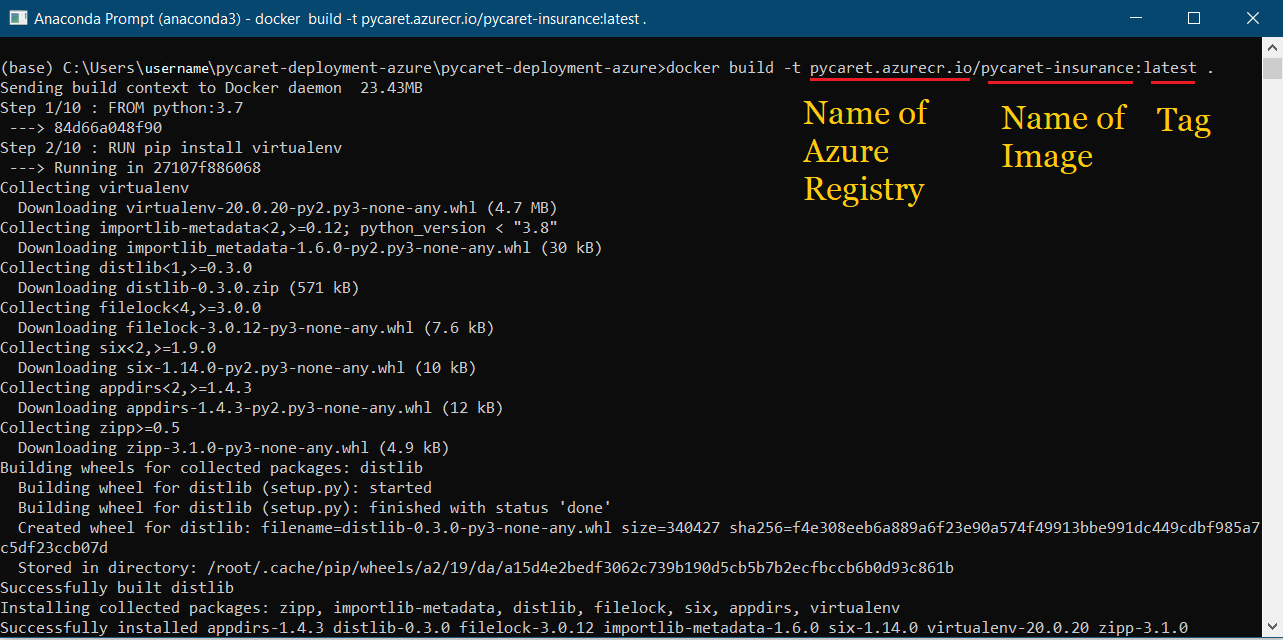
- pycaret.azurecr.io is the name of the registry that you get when you create a resource on the Azure portal
- pycaret-insurance is the name of the image and the latest is the tag; this can be anything you want
Run container from Docker image
Now that the image is created we will run a container locally and test the application before we push it to Azure Container Registry. To run the container locally, execute the following code:
docker run -d -p 5000:5000 pycaret.azurecr.io/pycaret-insurance
You can see the app in action by going to localhost:5000 in your internet browser. It should open up a web app.
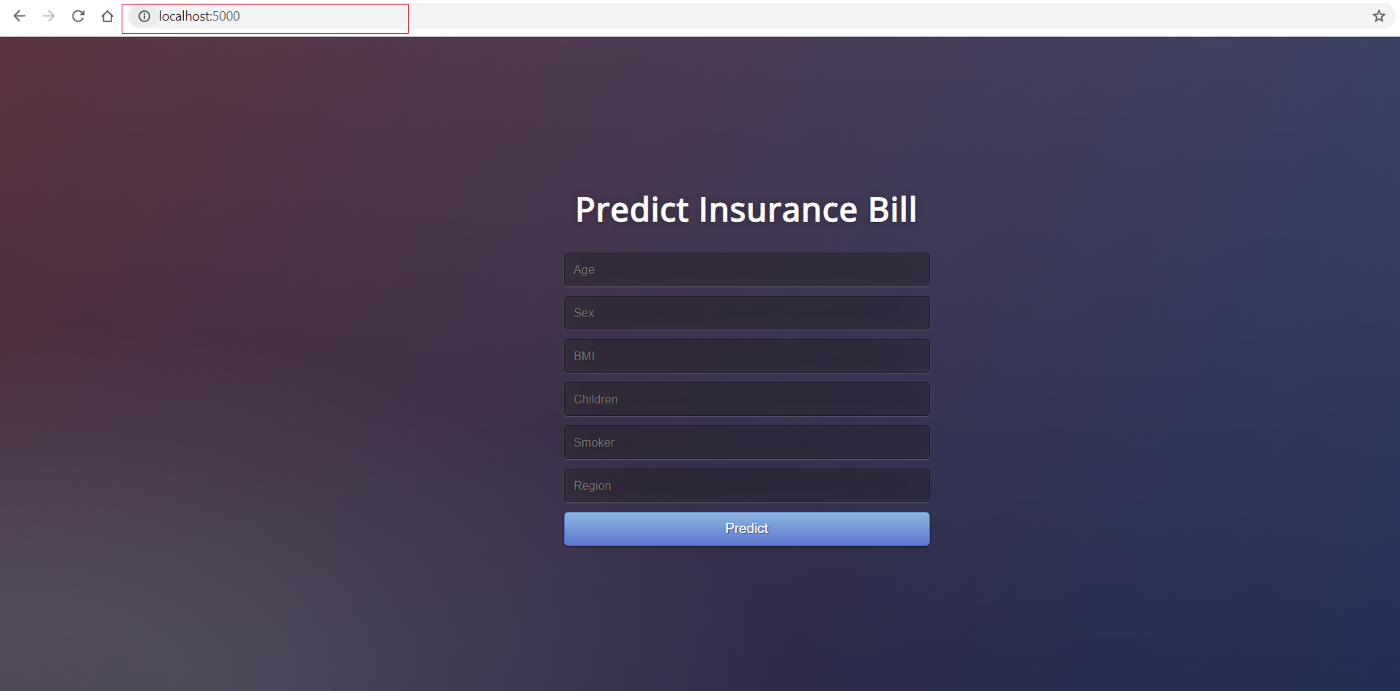
If you can see this, that means the application is now up and running on your local machine and now it is only a matter of pushing this onto the cloud. For deployment on Azure, read on:
Authenticate Azure Credentials
One final step before you can upload the container onto ACR is to authenticate azure credentials on your local machine. Execute the following code in the command line to do that:
docker login pycaret.azurecr.io
You will be prompted for a username and password. The username is the name of your registry (in this example the username is "pycaret"). You can find your password under the access keys of the Azure Container Registry resource you created.
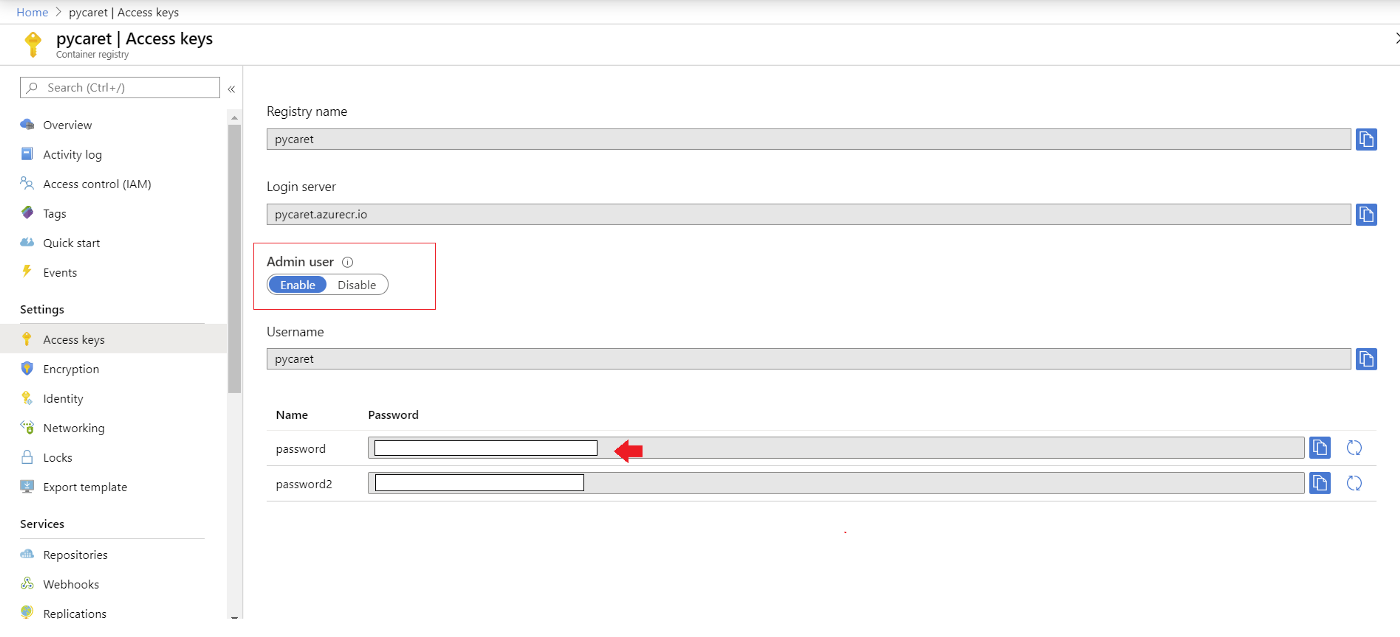
Push Container onto Azure Container Registry
Now that you have authenticated to ACR, you can push the container you have created to ACR by executing the following code:
docker push pycaret.azurecr.io/pycaret-insurance:latest
Depending on the size of the container, the push command may take some time to transfer the container to the cloud.
Web Application
To create a web app on Azure, follow these steps:
- Login on the Azure portal
- Click on create a resource
- Search for the web app and click on create
- Link your ACR image to your application
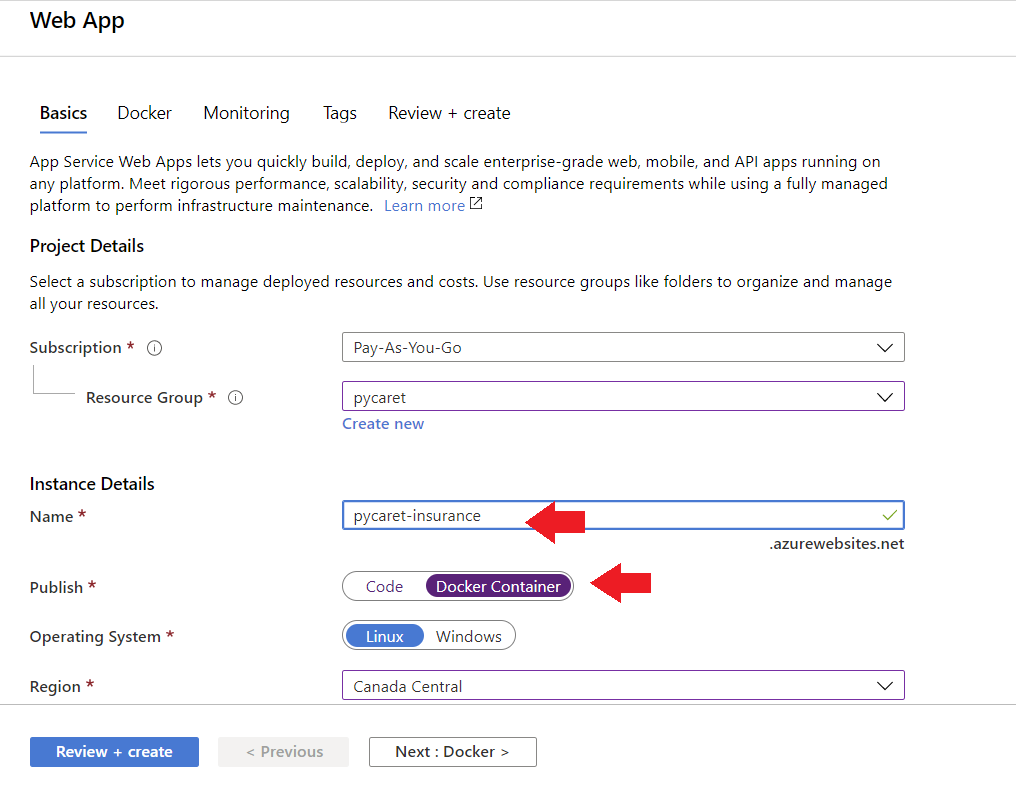
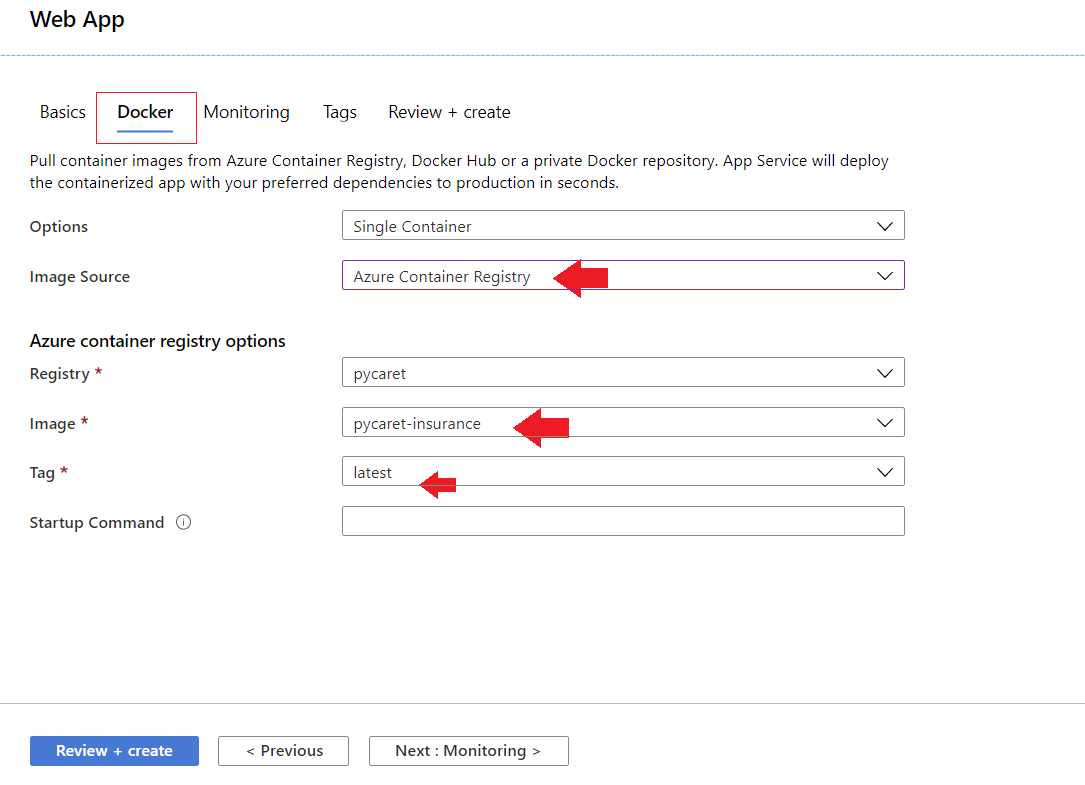
The application is now up and running on Azure Web Services.

Conclusion
MLOps help ensure that deployed models are well maintained, performing as expected, and not having any adverse effects on the business. This role is crucial in protecting the business from risks due to models that drift over time, or that are deployed but unmaintained or unmonitored.
MLOps topped LinkedIn's Emerging Jobs ranking, with a recorded growth of 9.8 times in five years.
You can check out the new MLOps Fundamentals Skill Track at DataCamp, which covers the complete life-cycle of a machine learning application, ranging from the gathering of business requirements to the design, development, deployment, operation, and maintenance stages. Datacamp also has an amazing Understanding Data Engineering course. Enroll today to discover how data engineers lay the groundwork that makes data science possible, with no coding involved.
