
Curso
Entender Microsoft Azure
3 h
47.1K
Si tu proceso CI/CD se rompe constantemente o parece lento y torpe, no eres el único. He tenido que lidiar con compilaciones fallidas, entornos desajustados y compañeros de equipo que accidentalmente sobrescribían mi trabajo. Azure Pipelines elimina estas frustraciones con un servicio alojado en la nube que puede crear, probar y desplegar casi cualquier proyecto en cualquier plataforma.
Por eso, en este tutorial, te mostraré cómo hacerlo:
¡Empecemos!
Azure Pipelines es una solución basada en la nube que simplifica el desarrollo, las pruebas y el despliegue de aplicaciones.
Es un componente del conjunto de herramientas Azure DevOps, que da soporte a todo el ciclo de vida del desarrollo de software. También es una opción flexible para equipos de todos los tamaños, porque admite varias plataformas y lenguajes de programación. GitHub, Azure Repos y otros conocidos sistemas de control de versiones están integrados con él.
Las características principales de Azure Pipelines incluyen:
|
Servicio |
Propósito |
|
Soporte multiplataforma |
Azure Pipelines automatiza la creación y despliegue de aplicaciones para varios sistemas operativos, como Linux, macOS y Windows. |
|
Integración con el control de versiones |
Azure Pipelines se conecta a tus repositorios de código, como Azure Repos, GitHub y otros conocidos sistemas de control de versiones. |
|
Configuración de canalizaciones basada en YAML |
Azure Pipelines nos permite definir nuestros procesos de compilación y despliegue como código, permitiendo el control de versiones. |
|
Integración continua y Despliegue continuo (CI/CD) |
Azure Pipelines facilita el proceso integral de integración de cambios de código y despliegue de aplicaciones. |
En mi experiencia, Azure Pipelines es útil para cualquiera que desee tener proper CI/CD dentro de su equipo. Es flexible, escalable y se integra bien con otros servicios de Azure.
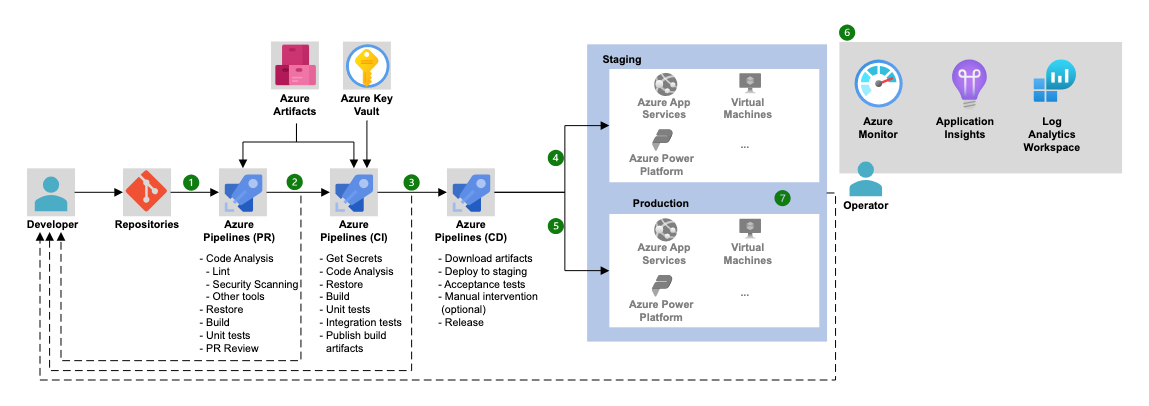
Arquitectura de Azure Pipelines (Fuente: Microsoft).
Si buscas una comprensión más amplia de Azure DevOps más allá de los pipelines, este tutorial Azure DevOps warecorre todo el ciclo de vida de CI/CD de principio a fin.
Para trabajar con el entorno Azure Pipelines, primero debemos configurarlo todo para fomentar un proceso de creación, prueba y despliegue de extremo a extremo.
Antes de lanzarte a crear tu primera canalización, asegúrate de que tienes lo siguiente:
Si necesitas ponerte al día sobre el ecosistema Azure en general, te recomiendo que consultes el curso Comprender Microsoft Azure.
Ahora que tu cuenta Azure DevOps y tu organización están configuradas, vamos a crear nuestro primer proyecto y repositorio.
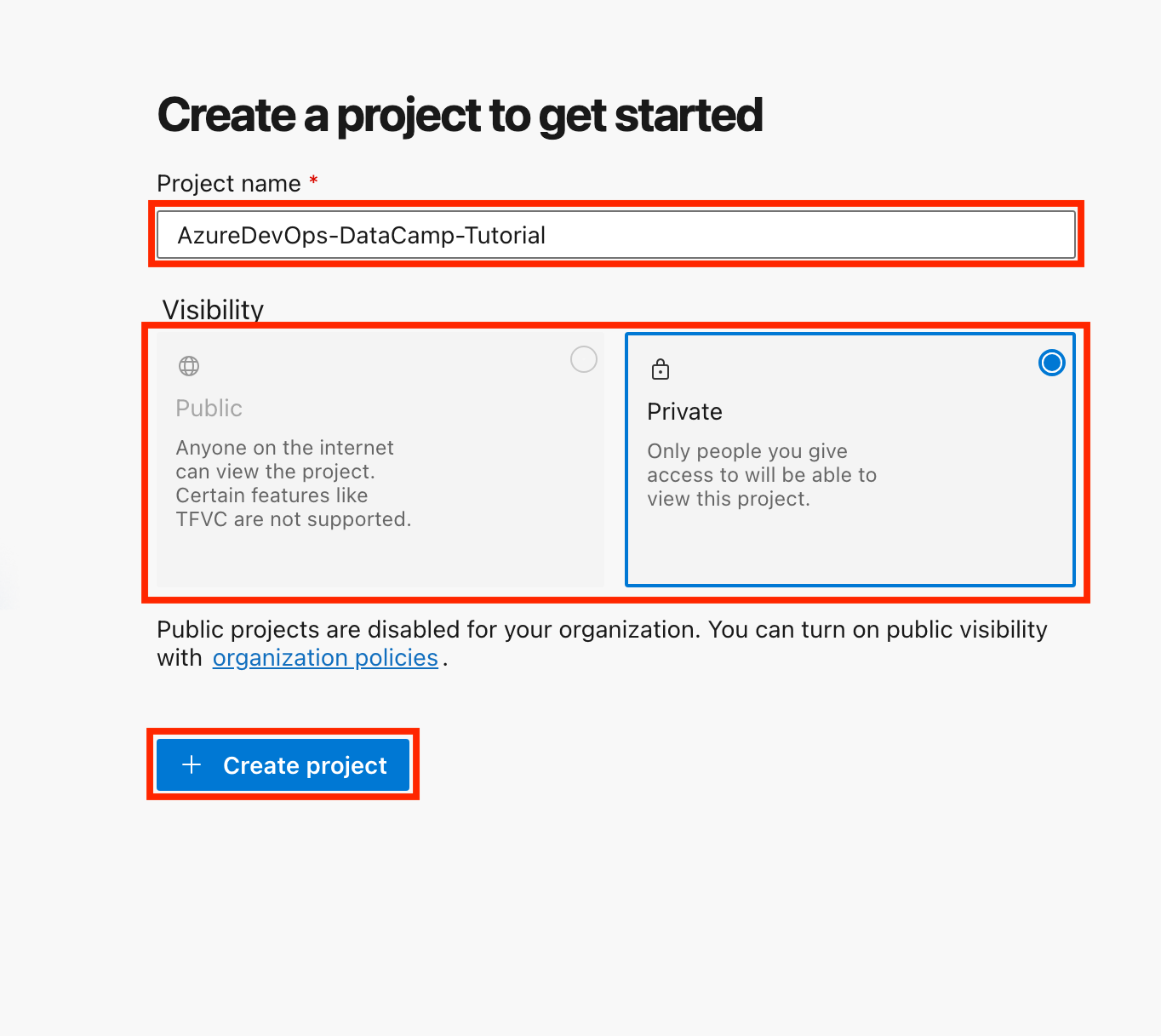

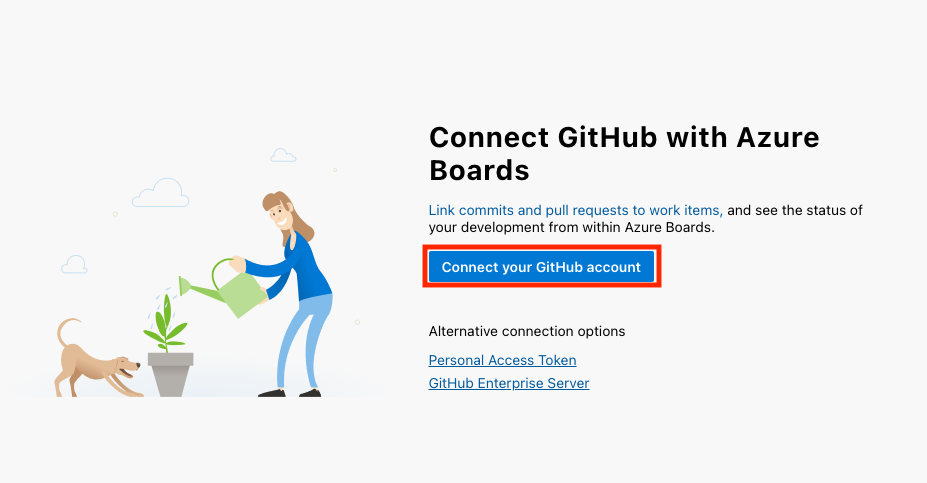
Para este tutorial, utilizaremos Azure Repos como nuestro repositorio de código. Si estás empezando o no tienes una razón específica para elegir TFVC, te aconsejo que elijas Git.
Es hora de crear nuestra primera tubería. Sigue los pasos que se indican a continuación:
Azure Pipelines proporciona dos formas de definir tus pipelines:
.yaml o .yml en tu repositorio de fuentes, lo que permite el versionado y una mejor colaboración.|
Aspecto |
Tuberías YAML |
Editor clásico |
|
Control de versiones |
Las canalizaciones YAML admiten el control de versiones y se almacenan en el repositorio de código fuente. |
El Editor clásico no admite el control de versiones. Está basado en una interfaz gráfica de usuario (GUI). |
|
Flexibilidad |
Las tuberías YAML tienen una flexibilidad de alto nivel. |
El Editor Clásico tiene una flexibilidad limitada. |
|
Lo mejor para |
Los YAML Pipelines son mejores para flujos de trabajo complejos a largo plazo y para la automatización. |
El Editor Clásico es el más adecuado para configuraciones rápidas. |
En mi experiencia, las canalizaciones YAML proporcionan más flexibilidad y son mejores para los equipos quepermiten prácticas de Infraestructura como Código (IaC). Pero este Editor Clásico es perfecto para los más frescos, con una forma más visual de hacer las cosas.
Sin embargo, para una escalabilidad a largo plazo, se recomiendan las canalizaciones YAML en lugar del Editor Clásico.
Ahora, veamos cómo podemos construir con Azure Pipelines.
En esta sección, especificaremos los pasos que Azure Pipelines realiza para construir tu código, como la instalación de dependencias, la compilación y la ejecución de pruebas. Vamos a expresar estos pasos en un archivo de configuración en nuestro repositorio de código fuente utilizando YAML, una forma sencilla y legible por humanos de describir los pasos de una receta.
Aquí tienes un ejemplo sencillo de una canalización YAML:
# This section defines the trigger(s) for the pipeline.
# 'main' specifies that the pipeline will run whenever changes are pushed to the 'main' branch.
trigger:
- main # automatically triggers this pipeline when changes are made to the 'main' branch.
# This defines the pool where the pipeline will run.
# 'ubuntu-latest' specifies the virtual machine image for executing tasks.
pool:
vmImage: 'ubuntu-latest' # This uses the latest Ubuntu image provided by Azure DevOps.
# Steps contain the individual tasks or actions that the pipeline will execute.
steps:
- script: echo Hello, world! # A script task to run shell commands. This one prints "Hello, world!".
displayName: 'Run my first pipeline script' # A friendly name for this step, making it easier to identify in the pipeline logs.Vamos a desglosar el código paso a paso:
trigger: Especifica la rama que activa la canalización (por ejemplo, main).pool: Define el agente de construcción (por ejemplo, ubuntu-latest).steps: Enumera las tareas a ejecutar, como instalar dependencias y ejecutar un script de compilación.Para añadir pasos de compilación a tu canalización YAML, debes definir el "script" en la sección "pasos".
Para una aplicación sencilla de Node.js, por ejemplo, nuestro archivo azure-pipelines.yml de abajo contiene código que Azure DevOps creó automáticamente.
# Node.js
# Build a general Node.js project with npm.
# Add steps that analyze code, save build artifacts, deploy, and more:
# https://docs.microsoft.com/azure/devops/pipelines/languages/javascript
trigger:
- main
pool:
vmImage: 'ubuntu-latest'
steps:
- task: NodeTool@0
inputs:
versionSpec: '20.x'
displayName: 'Install Node.js'
- script: |
npm install
npm run build
displayName: 'npm install and build'Echemos un vistazo a la construcción steps en el canal YAML anterior:
NodeTool@0 para especificar la versión de Node.js. npm install para instalar las dependencias del proyecto. npm run build para compilar el código. Nuestro pipeline puede activarse manualmente o configurarse para que se ejecute automáticamente cuando se produzcan eventos como el empuje de ramas.
main y desencadenar la canalización automáticamente. He aquí un ejemplo:trigger:
- mainDespués de ejecutar tu canalización, puedes ver los registros y solucionar cualquier problema.
Para acceder a los registros, ve al resumen de ejecución de tu pipeline y selecciona el trabajo o tarea específicos. Esto mostrará los registros de ese paso; como en la imagen de abajo, puedes elegir cualquier trabajo (Construir, Empujar o Actualizar) para ver los registros sin procesar.
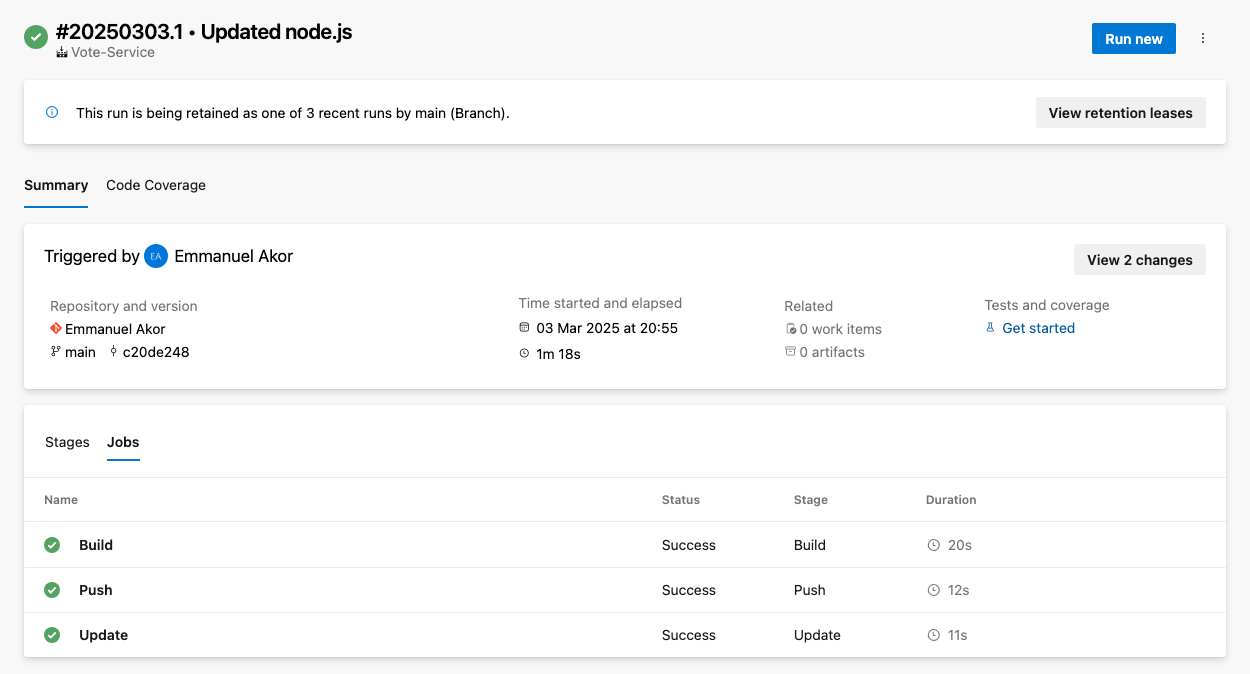
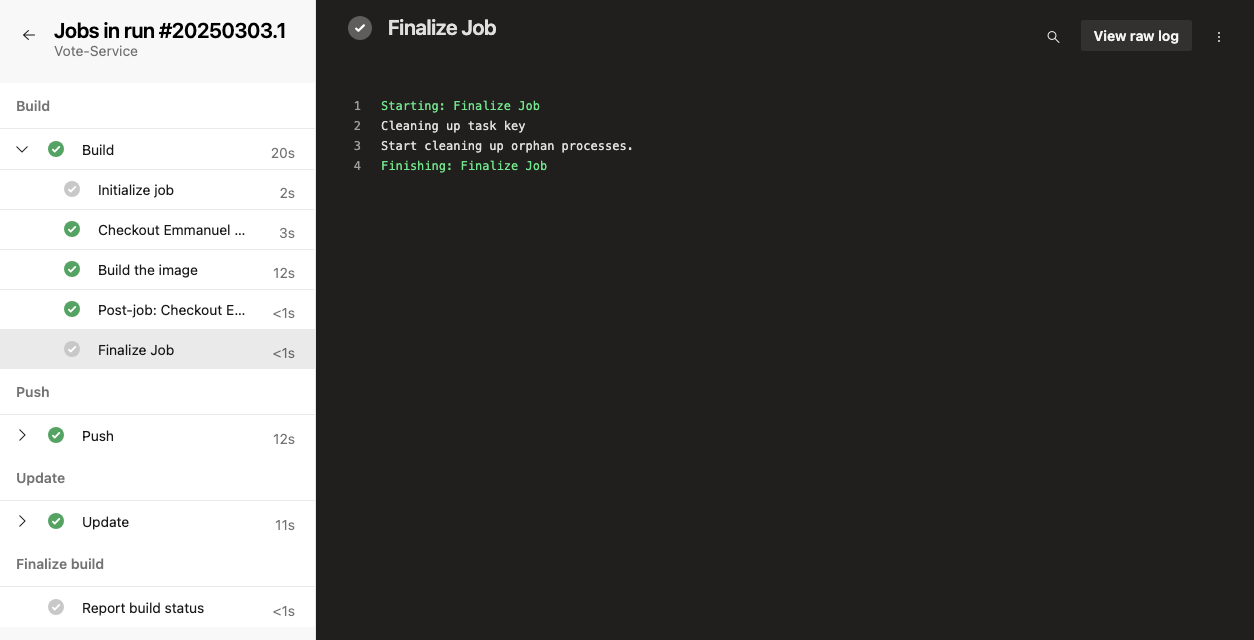
Para solucionar problemas comunes, puedes comprobar tu canalización en busca de problemas comunes como tiempos de espera, limitaciones de recursos o configuraciones erróneas.
Añade pruebas a tu proceso para garantizar la calidad del código y detectar problemas en las primeras fases del desarrollo. En Azure Pipelines, puedes integrar pruebas unitarias, de integración o de otro tipo añadiendo pasos en la configuración de tu pipeline.
Incluye pasos de prueba en tu pipeline para garantizar la calidad del código. Puedes utilizar frameworks populares como Jest, Mocha o NUnit. Por ejemplo, aquí tienes cómo añadir pruebas unitarias con Jest:
- script: |
npm test
displayName: 'Run unit tests with Jest'Hay informes de pruebas integrados en Azure Pipelines. Puedes configurar la publicación de los resultados de las pruebas para un seguimiento más sencillo y ver los resultados de las pruebas en los registros de la canalización. Así se hace:
PublishTestResults@2 para mostrar los resultados. Esto facilita el seguimiento general. Por ejemplo:- task: PublishTestResults@2
inputs:
testResultsFiles: '**/test-results.xml'
testRunTitle: 'Unit Tests'En los pasos de despliegue de tu archivo YAML de canalización de Azure, puedes desplegar automáticamente tu aplicación en varios entornos, como pruebas, staging y producción. En esta sección, revisaremos algunas formas de desplegar con Azure Pipelines.
Azure Web Apps es un servicio del Portal Azure que te permite desarrollar, desplegar y gestionar aplicaciones web a escala.
Para desplegar en Azure Web Apps, debes vincular los dos servicios. He aquí cómo hacerlo:

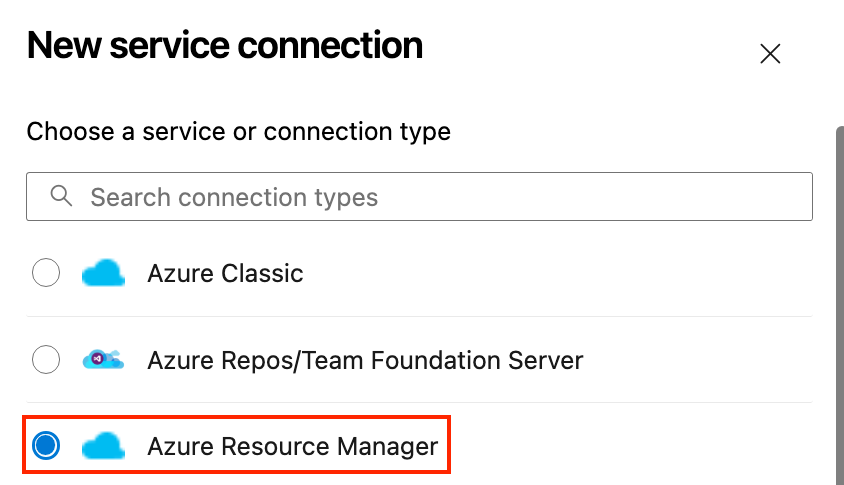
He aquí un ejemplo de canalización de despliegue YAML para una sencilla aplicación Node.js en Azure App Service:
# Define the task for deploying to an Azure Web App
- task: AzureWebApp@1
inputs:
# This specifies your Azure subscription service connection
azureSubscription: 'your-azure-subscription'
# This specifies the name of your web app
appName: 'your-app-name'
# This specifies the location of the app package or files to be deployed
package: '$(Build.ArtifactStagingDirectory)'Vamos a desglosar el código anterior, para que puedas adaptarlo a tu caso de uso:
your-azure-subscription por el nombre de la conexión de servicio que da acceso a tu suscripción de Azure.your-app-name por el nombre real de tu aplicación web en Azure. $(Build.ArtifactStagingDirectory) por el directorio donde colocar el paquete o los archivos de la aplicación web para su despliegue. $(Build.ArtifactStagingDirectory) - Esta variable apunta a la carpeta en la que se encuentran tus artefactos de compilación (los archivos de tu aplicación) una vez compilados.Una vez que todo nuestro código supera todas las pruebas y comprobaciones, el siguiente paso es configurar nuestro despliegue continuo. Sigue los pasos que se describen a continuación.
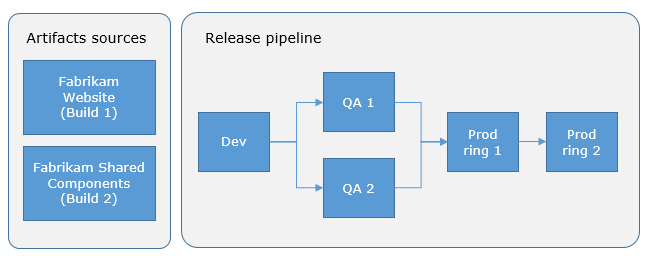
Modelo de despliegue de la canalización de versiones de Azure (Fuente: Microsoft)
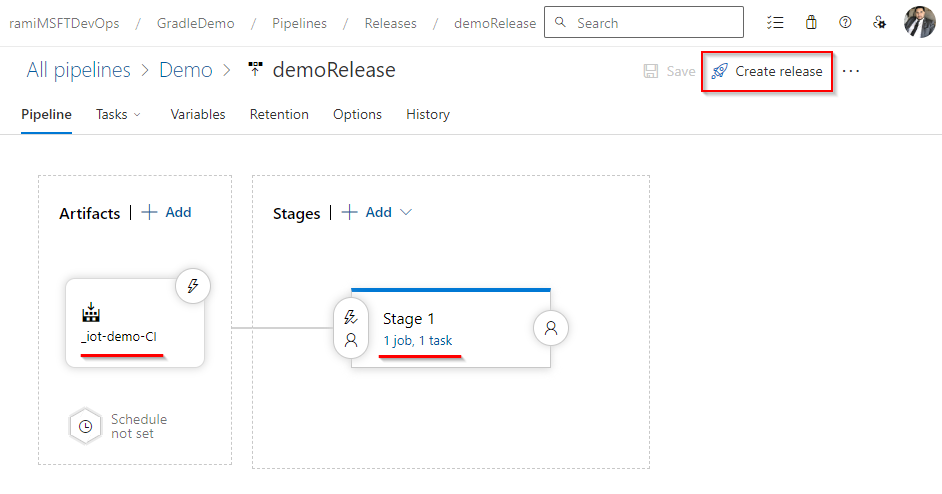
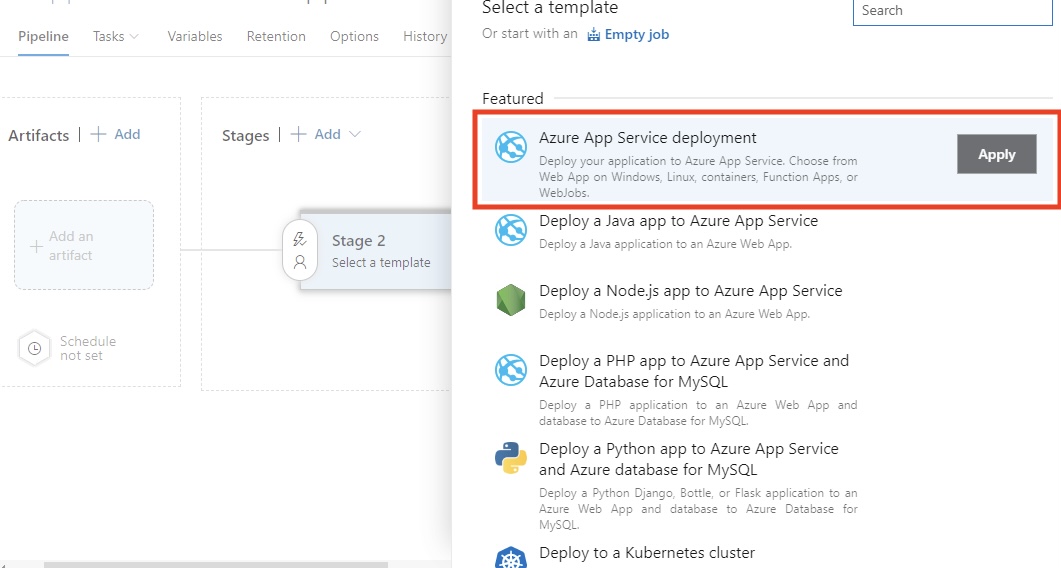
Según mi experiencia, esta fase es necesaria para mantener la estabilidad en entornos de desarrollo exigentes. Las aprobaciones y las puertas proporcionan control y garantizan que sólo el código de alta calidad llegue a la producción.
Kubernetes facilita la ejecución de aplicaciones en contenedores fiables y escalables. Al utilizar Azure Kubernetes Service (AKS), obtienes un entorno gestionado que simplifica el despliegue y las operaciones. En esta sección, te explicaré cómo desplegar tu aplicación en AKS utilizando Azure Pipelines.
Puedes crear un clúster AKS utilizando el portal de Azure o la CLI. Aquí tienes un comando CLI Bash básico para aprovisionar el clúster:
az aks create \
--resource-group <ResourceGroupName> \
--name <AKSClusterName> \
--node-count 3 \
--enable-addons monitoring \
--generate-ssh-keysVamos a desglosar el comando anterior:
--resource-group: Indica el grupo de recursos de Azure en el que se creará el clúster AKS.--name: Se refiere al nombre de tu cluster AKS.--node-count: Establece el número de nodos del clúster (por ejemplo, 3 en este ejemplo).--enable-addons monitoring: Esto hace posible la supervisión y el análisis con Azure Monitor for Containers.--generate-ssh-keys: Esto genera automáticamente claves SSH para el acceso seguro al nodo si no se proporcionan.No olvides sustituir y por los nombres reales de tu grupo de recursos y clúster.
Kubectl debe configurarse después de que tu clúster AKS esté configurado. Esto garantiza que tu agente de canalización u ordenador local pueda utilizar kubectl para comunicarse con el clúster.
Puedes acelerar tus tareas en Azure utilizando la línea de comandos aols: esta hoja de trucos de la CLI de Azure es una referencia práctica.
Tomemos como ejemplo un archivo YAML de despliegue básico para desplegar una imagen Docker en Kubernetes:
# This defines the API version and the kind of Kubernetes resource we are creating.
# 'apps/v1' is the API version, and 'Deployment' is the resource type.
apiVersion: apps/v1
kind: Deployment
# Metadata contains information to identify the resource uniquely.
# 'name' specifies the name of the Deployment.
metadata:
name: my-app # Name of the Deployment, used for identification.
# "spec" specifies the intended deployment state.
spec:
# Number of replicas/pods we want for this Deployment.
replicas: 3 # Ensures high availability by running three app replicas.
# Selector is used to define the labels that this Deployment will manage.
selector:
matchLabels:
app: my-app # This ensures that only Pods with the label 'app: my-app' are managed by this Deployment.
# Template specifies the blueprint for the pods created by the Deployment.
template:
metadata:
labels:
app: my-app # Labels for the Pods, matching the selector above.
# A specification for the containers of the Pods.
spec:
containers:
- name: my-app # Name of the container. This is useful for linking to the container in logs, etc.
image: mycontainerregistry.azurecr.io/my-app:latest # Pull the container image you will call from your container registry.
ports:
- containerPort: 80 # The container listens on port 80.En tu canalización YAML, incluye una tarea para desplegar en AKS.
# This defines a task for deploying Kubernetes manifests within an Azure DevOps pipeline.
- task: KubernetesManifest@0 # Task type for working with Kubernetes manifest files.
inputs:
# This configures what to do with the Kubernetes manifest files.
action: 'deploy' # 'deploy' action ensures the Kubernetes manifests are applied to the cluster.
# This defines the namespace where the Kubernetes resources will be deployed.
namespace: 'default' # 'default' is the namespace for deploying resources. Change if needed.
# All this does is point to the manifest files that define the desired state of your Kubernetes resources.
manifests: '$(Build.ArtifactStagingDirectory)/manifests/*.yaml'
# The 'manifests' variable points to the location of all the YAML files (e.g., Deployment, Service, etc.) that will be applied during the deployment.
# To access private container registry images, use the image pull secret.
imagePullSecrets: 'my-registry-secret'
# This instructs Kubernetes on which secret to use when pulling images from a private container registry.
# Ensure that 'my-registry-secret' exists in the namespace before the deployConfirma y envía el archivo YAML para activar el despliegue.
AKS simplifica la orquestación de contenedores, facilitando la gestión del escalado, las actualizaciones y las reversiones. En mi experiencia, es imprescindible para las aplicaciones modernas nativas de la nube.
Al principio de mi carrera, construir oleoductos no era el mayor reto, sino tener un oleoducto rápido y fiable. Un pipeline bien optimizado no sólo agiliza las compilaciones, sino que también reduce la frustración del equipo, disminuye los riesgos de despliegue y acelera la entrega.
Compartiré algunos consejos y estrategias que puedes utilizar para mantener tus canalizaciones Azure DevOps rápidas, organizadas y fiables.
La instalación de dependencias es otro cuello de botella común en las canalizaciones. Tanto si trabajas con npm, .NET u otros gestores de paquetes, descargar repetidamente las mismas dependencias puede hacerte perder mucho tiempo. El almacenamiento en caché de dependencias y artefactos entre ejecuciones reduce drásticamente el tiempo de ejecución.
A continuación te explicamos cómo almacenar en caché las dependencias en Azure Pipelines.
Primero, tienes que identificar los gestores de paquetes, como:
node_modules)pip paquetes)Azure Pipelines admite mecanismos de almacenamiento en caché, como la tarea Cache@2, que te permite almacenar en caché dependencias entre ejecuciones de pipelines.
Tomemos como ejemplo un simple almacenamiento en caché para Node.js:
# This task is used to cache files to speed up your pipeline.
- task: Cache@2 # This is the task name for caching files in Azure Pipelines.
inputs:
# Key is used to identify the cache. It combines npm (package manager), operating system (OS), and package-lock.json files.
key: 'npm | "$(Agent.OS)" | package-lock.json'
# RestoreKeys is an optional value used when the specific cache key is not found. It helps to find a fallback cache.
restoreKeys: |
npm | "$(Agent.OS)"
# Path defines the location of files or folders to be cached.
# Here, we are caching the 'node_modules' directory to avoid reinstalling dependencies.
path: '$(Build.SourcesDirectory)/node_modules'
# CacheHitVar is a variable that stores whether the cache was successfully used (restored).
# This can be checked later in the pipeline to decide if tasks need to run.
cacheHitVar: 'NPM_CACHE_RESTORED'Entonces puedes omitir condicionalmente la instalación si se almacena en caché. Se trata de una comprobación inteligente antes de completar la instalación de npm. Es una lógica eficiente basada en condiciones.
Pongamos un ejemplo sencillo:
# This step runs the command to install Node.js dependencies using npm.
- script: npm install # Installs packages listed in the package.json file.
# The condition checks whether the cache was restored successfully.
# This step will run if the cache is not restored ('NPM_CACHE_RESTORED' is not true).
condition: ne(variables.NPM_CACHE_RESTORED, 'true') # Run only if the cache is not restored.Este ejemplo de caché simple para una aplicación Node.js guarda el directorio de caché npm utilizando package-lock.json como clave. Cuando tus dependencias no cambian, las restaura, ahorrando minutos en cada compilación.
He visto que el almacenamiento en caché reduce drásticamente el tiempo de construcción, especialmente en proyectos grandes, pero sólo si las claves de caché se eligen cuidadosamente. En uno de mis proyectos anteriores, esto redujo el tiempo de compilación de una aplicación Node.js en un 55%.
Un pipeline de éxito no es sólo cuestión de ticks verdes, visibilidad y retroalimentación rápida. Cuando algo se rompe, quieres que tu equipo lo sepa al instante. He aquí cómo adelantarte a los problemas.
Azure DevOps proporciona widgets integrados para mostrar el estado de las canalizaciones, las ejecuciones recientes, las tasas de fallos y las duraciones medias.
Son esenciales para seguir las tendencias de aprobados y suspensos, ver qué entornos son problemáticos, etc.
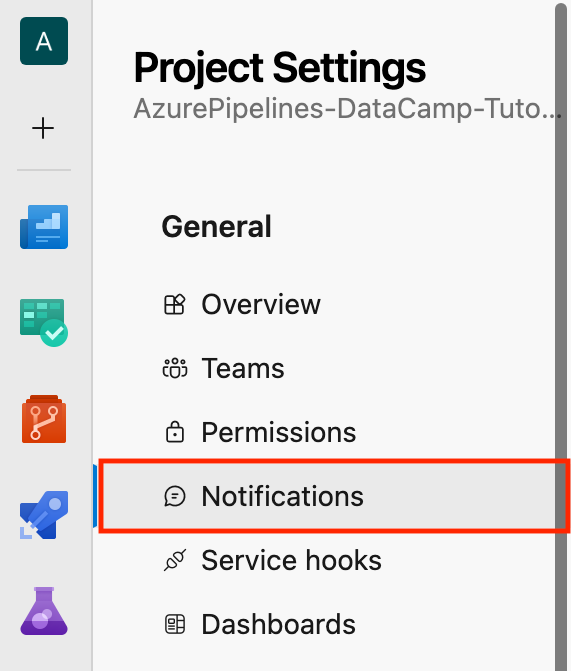

Pongámonos en situación: En la sección Category, selecciona Build; en la sección Template, selecciona "A build fails", y haz clic en Next.
Tienes una interfaz como la siguiente
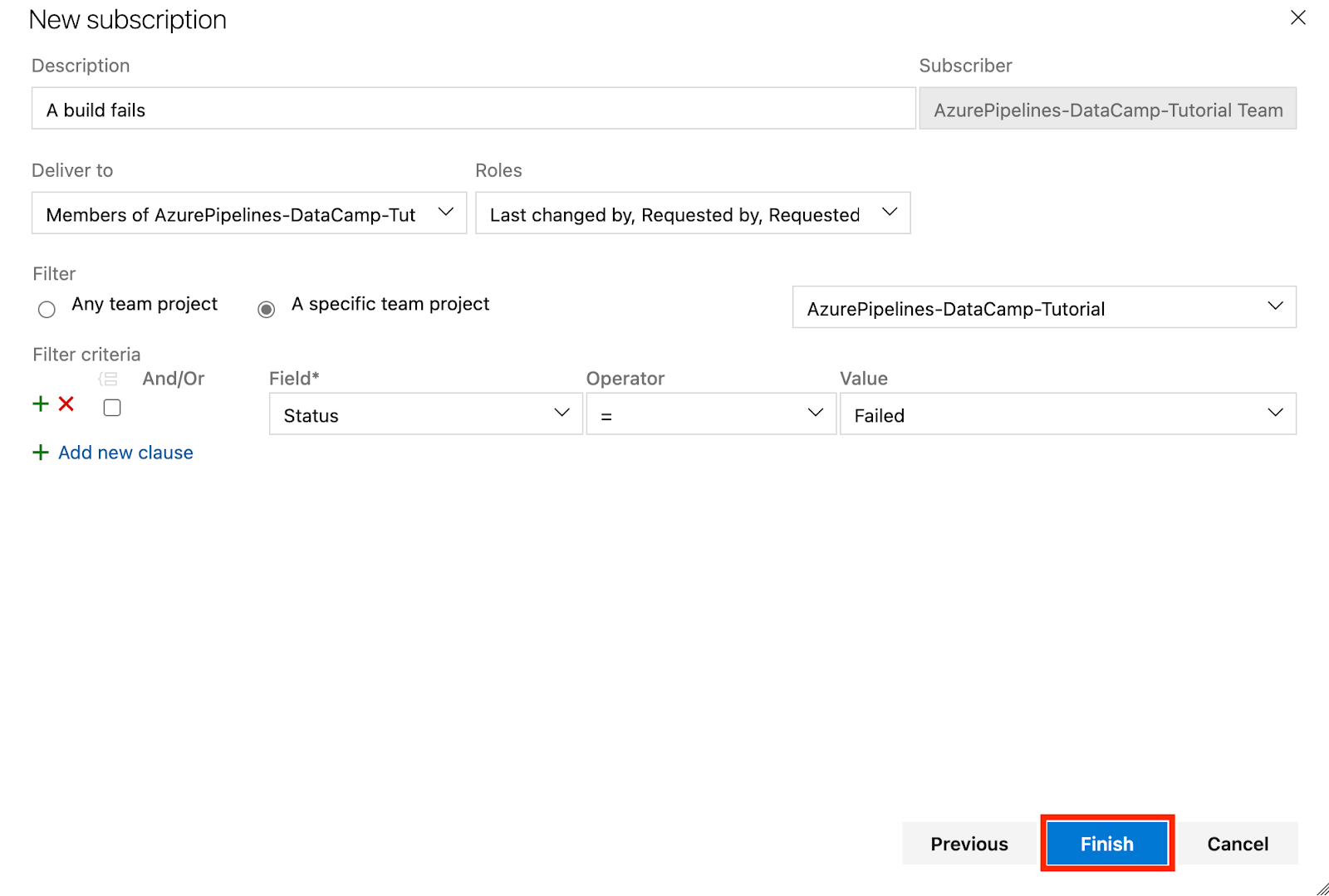

Una vez me perdí un fallo crítico de despliegue porque no se habían configurado las alertas. Desde entonces, siempre he establecido y configurado alertas de equipo para cada despliegue de producción. De este modo, nunca me pierdo una compilación rota o un retraso en mi ciclo de publicación.
Sabemos que aunque tu canalización funcione, puede ser lenta, y las canalizaciones lentas matan la productividad. Así que identificar los cuellos de botella a tiempo ahorra problemas más adelante.
Las métricas de canalización arrojan luz sobre el rendimiento de las compilaciones y los despliegues. Así es como se llega a ellos.
En primer lugar, debes activar Vistas analíticas en los configuración del proyecto y conectarte a Power BI o explorar a través de los gráficos integrados.
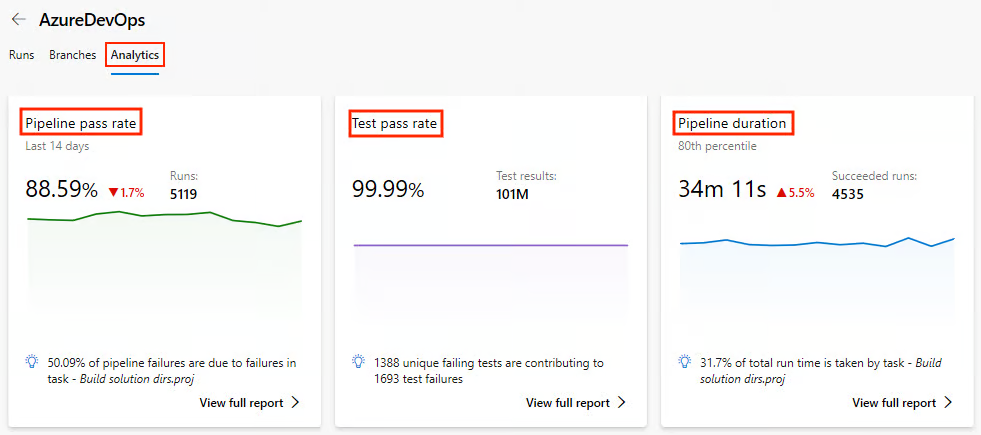
Exploremos más a fondo qué métricas clave podemos controlar en la analítica y por qué son importantes:
|
Métrica |
Por qué es importante |
|
Tendencias de la duración de la construcción |
Esto ayuda a detectar fácilmente las ralentizaciones a lo largo del tiempo. |
|
Tasa de fracaso por rama |
Esto ayuda a identificar los rasgos inestables. |
|
Tiempo en cola |
Esto ayuda a detectar la escasez de agentes. |
Hace unos meses, trabajé en el pipeline de un cliente, ylo que más me llamó la atención fue el Tiempo en Cola. Una vez descubrí que mi equipo y yo habíamos sobrecargado un grupo de agentes autoalojados, y el 40% de nuestro tiempo de canalización se dedicaba a esperar a un corredor disponible. Nadie lo vio venir hasta que la analítica lo hizo evidente.
Podríamos solucionarlo añadiendo dos agentes autoalojados más y distribuyendo la carga por tipo de trabajo. Los resultados fueron inmediatos: el tiempo medio de construcción del pipeline se redujo aproximadamente un 35%.
Así que, más allá de las métricas, los registros de la línea de tiempo son oro, especialmente para las tareas de larga duración. A lo largo de los años, he añadido habitualmente marcadores de registro personalizados dentro de los pasos críticos de las secuencias de comandos para señalar los retrasos exactos.
Pongamos un ejemplo sencillo:
# This step prints a message to the console in the pipeline logs.
# It helps to mark the start of the dependency installation process.
echo "=== START: Dependency Install ===" # Display a message indicating the beginning of dependency installation.Ahora que hemos cubierto los servicios principales de Azure Pipelines y muchos más, veamos cómo sacarles el máximo partido siguiendo estas prácticas recomendadas.
Pasemos del rendimiento a la estructura, porque un pipeline rápido y difícil de mantener seguirá perjudicando a cualquier equipo.
Cuando varios equipos o entornos comparten canalizaciones, a menudo las cosas se complican. Necesitarás estructura. Una tubería gigante para los entornos de desarrollo, preparación y producción conduce al caos.
Para organizar tu pipeline, debes separarlo en entornos. Veamos una estructura sencillaa continuación.
|
Medio ambiente |
Nombre de la tubería |
Disparador |
|
Desarrollo |
|
Ramas de características (Se ejecuta en cada confirmación) |
|
Puesta en escena |
|
Pull requests → Puesta en escena (Activación manual) |
|
Producción |
|
Tuberías manuales o de liberación (se requiere autorización) |
Cosas clave que hay que entender de esta sencillaestructura:
Por experiencia, esta separación facilita la depuración y permite a los programadores junior desplegarse en el entorno de desarrollo sin arriesgar el entorno de producción.
DevOps consiste en reducir el flujo de trabajo manual y mejorar la automatización en todo el proceso de desarrollo de software.
El código YAML es propenso a errores cuando se copia y pega entre proyectos. Azure DevOps dispone de plantillas de canalización para la configuración DRY (Don't Repeat Yourself) mediante canalizaciones YAML. Puedes reutilizar las plantillas de canalización YAML en varios proyectos, diseñar tus canalizaciones de forma coherente e incluso reducir el tiempo de procesamiento de las canalizaciones.
Tomemos como ejemplo una sencilla plantilla de construcción reutilizable.
En primer lugar, define tu plantilla de construcción, build-template.yml:
# Here we configure the platform and the build configuration.
parameters:
buildPlatform: 'Any CPU' # This specifies the build platform (e.g., Any CPU, x86, x64).
buildConfiguration: 'Release' # This specifies the build configuration (Release) to avoid warning.
# A pipeline is composed of steps (a series of tasks that will be executed)
steps:
- task: DotNetCoreCLI@2 # Task for running .NET Core commands in the pipeline.
inputs:
command: 'build' # This runs the 'build' command to compile the project(s).
projects: '**/*.csproj' # This specifies to build all .csproj files in the repository.
arguments: '--configuration ${{ parameters.buildConfiguration }}'
# This passes the build configuration parameter (e.g., Release or Debug) to the command.Utiliza tu plantilla de construcción en tu canal principal:
# A pipeline job is a group of tasks. Here, the job is named 'Build'.
jobs:
- job: Build # The job name where the build process occurs.
# Steps define the tasks or actions the pipeline will perform.
steps:
- template: templates/build-template.yml # Reference an external YAML template for reusable steps.Cuando se trabaja en proyectos, especialmente en entornos colaborativos, es habitual utilizar información sensible como cadenas de conexión a bases de datos, claves API, contraseñas o tokens. Si estos secretos están codificados en tu código base o expuestos en los registros, pueden verse fácilmente comprometidos.
Veamos cómo gestionar de forma segura nuestros secretos y variables utilizando los secretos y grupos de variables de Azure Pipelines.
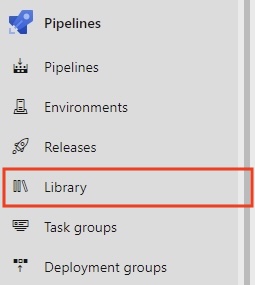
MyAppSecrets).

DB_CONNECTION_STRING).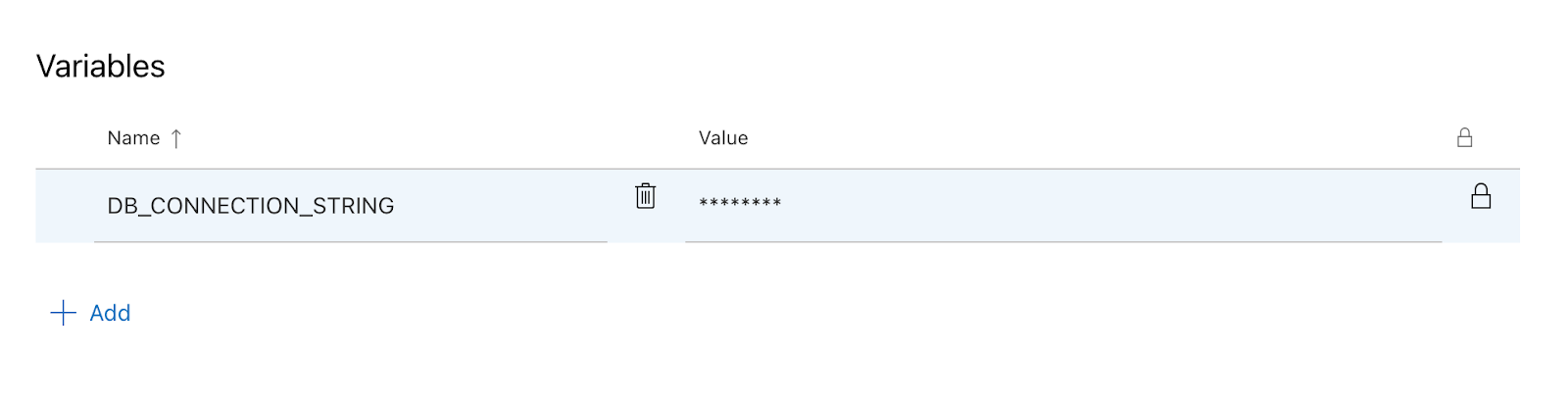
Ahora que has creado un grupo de variables con secretos, puedes utilizar estas variables en el archivo YAML de tu canalización.
variables:
- group: MyAppSecrets$(VariableName). Aquí tienes un ejemplo de cómo utilizar DB_CONNECTION_STRING en un paso de guión:# This defines the trigger for the pipeline.
# The pipeline runs automatically whenever changes are pushed to the 'main' branch.
trigger:
- main # Trigger the pipeline on changes to the 'main' branch.
# The pool specifies the environment where the pipeline will run.
# 'ubuntu-latest' means the pipeline will use the latest Ubuntu operating system image.
pool:
vmImage: 'ubuntu-latest' # Use the latest Ubuntu image provided by Azure Pipelines.
# Variables section defines reusable values for the pipeline.
# 'group: MyAppSecrets' links to a variable group that stores sensitive information like secrets.
variables:
- group: MyAppSecrets # Load secrets, such as database credentials, from a variable group.
# Steps define the tasks that the pipeline will execute one by one.
steps:
- script: |
echo "Connecting to the database..." # Print a message indicating the start of database connection.
echo "Connection String: $(DB_CONNECTION_STRING)" # Display the database connection string from the variable group.
displayName: 'Connect to Database' # A simple name for this step that appears in the pipeline logs.En este tutorial, recorremos todo el proceso de uso de Azure Pipelines, desde la configuración de tu primera canalización hasta su creación, prueba, despliegue, supervisión y optimización.
La fase de despliegue requiere práctica. Empieza con algo sencillo, sigue mejorando y, con el tiempo, ganarás confianza y soltura en la gestión de los flujos de trabajo CI/CD. Azure Pipelines te da las herramientas, tú aportas la iteración y el aprendizaje.
Con un esfuerzo constante, puedes agilizar tu proceso de desarrollo y confiar en el envío de software de alta calidad a escala.
Para profundizar en Azure DevOps y Microsoft Azure, consultalos siguientes recursos:
Aprende más sobre Azure con estos cursos
Curso
Curso
Curso
blog
Srujana Maddula
13 min
Tutorial
Moez Ali
Tutorial
Anneleen Rummens
Tutorial
Anneleen Rummens
Tutorial
Abid Ali Awan
Tutorial
DataCamp Team