
Cours
Comprendre Microsoft Azure
3 h
47.1K
Si votre pipeline CI/CD ne cesse de se briser ou semble lent et lourd, vous n'êtes pas seul. J'ai eu à faire face à des échecs de construction, à des environnements mal adaptés et à des coéquipiers qui écrasaient accidentellement mon travail. Azure Pipelines supprime ces frustrations grâce à un service hébergé dans le cloud qui permet de construire, tester et déployer presque n'importe quel projet sur n'importe quelle plateforme.
C'est pourquoi, dans ce tutoriel, je vous montrerai comment faire :
Commençons !
Azure Pipelines est une solution basée sur le cloud qui simplifie le développement, les tests et le déploiement des applications.
Il s'agit d'un composant de la boîte à outils Azure DevOps, qui prend en charge l'ensemble du cycle de développement des logiciels. Il s'agit également d'une option flexible pour les équipes de toutes tailles, car il prend en charge différentes plates-formes et différents langages de programmation. GitHub, Azure Repos et d'autres systèmes de contrôle de version bien connus y sont intégrés.
Les principales fonctionnalités d'Azure Pipelines sont les suivantes :
|
Service |
Objectif |
|
Support multiplateforme |
Azure Pipelines automatise la création et le déploiement d'applications pour différents systèmes d'exploitation, tels que Linux, macOS et Windows. |
|
Intégration avec le contrôle de version |
Azure Pipelines se connecte à vos référentiels de code comme Azure Repos, GitHub et d'autres systèmes de contrôle de version bien connus. |
|
Configuration du pipeline basée sur YAML |
Azure Pipelines nous permet de définir nos processus de construction et de déploiement en tant que code, ce qui permet le contrôle des versions. |
|
Intégration et déploiement continus (CI/CD) |
Azure Pipelines facilite le processus de bout en bout d'intégration des modifications de code et de déploiement des applications. |
D'après mon expérience, Azure Pipelines est utile à tous ceux qui souhaitent disposer de proper CI/CD au sein de leur équipe. Il est flexible, évolutif et s'intègre bien aux autres services Azure.
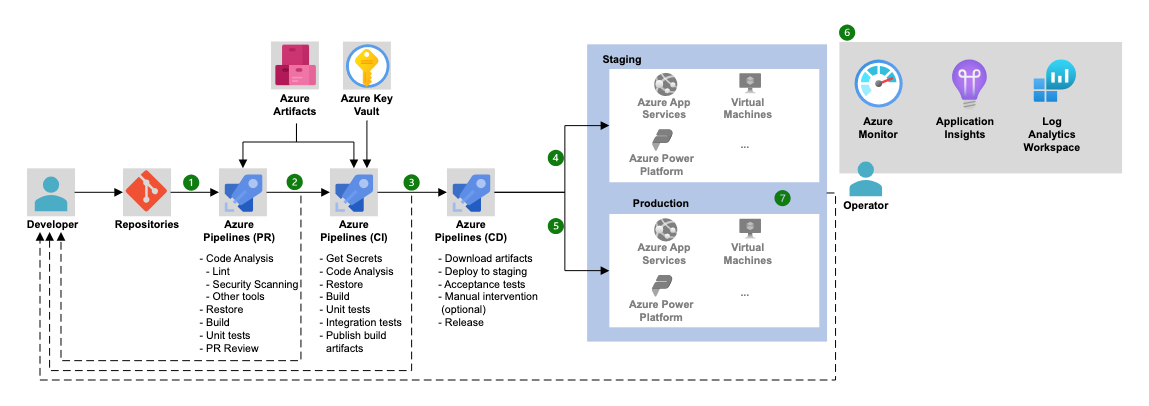
Architecture des pipelines Azure (Source: Microsoft).
Si vous souhaitez mieux comprendre Azure DevOps au-delà des pipelines, ce tutoriel Azure DevOps waparcourt l'ensemble du cycle de vie CI/CD, du début à la fin.
Pour travailler avec l'environnement Azure Pipelines, nous devons d'abord tout mettre en place pour favoriser un processus de construction, de test et de déploiement de bout en bout.
Avant de vous lancer dans la création de votre premier pipeline, assurez-vous que vous disposez des éléments suivants :
Si vous avez besoin de vous familiariser avec l'écosystème Azure au sens large, je vous recommande de suivre le cours " Comprendre Microsoft Azure".
Maintenant que votre compte Azure DevOps et votre organisation sont configurés, créons notre premier projet et notre premier référentiel.
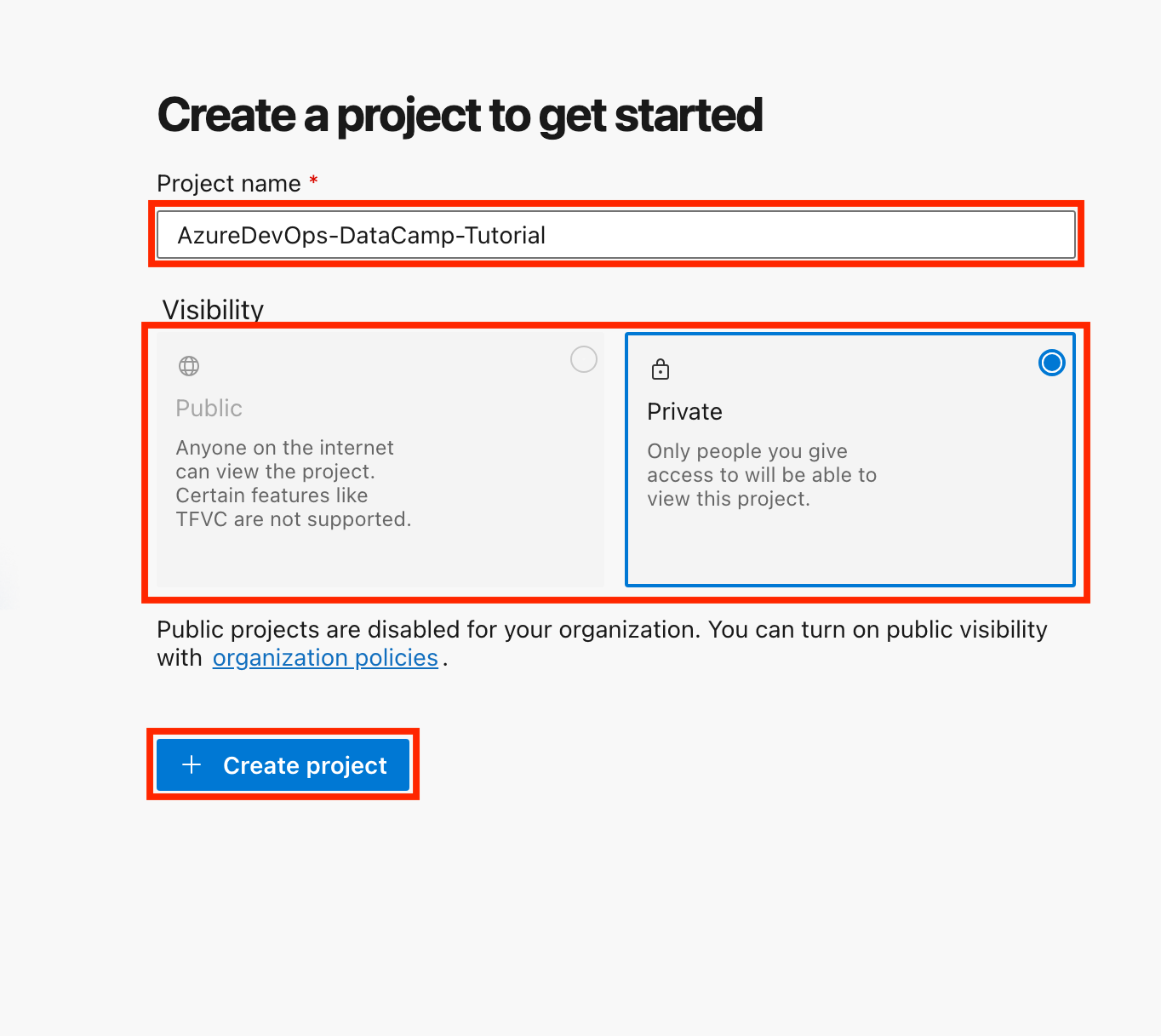

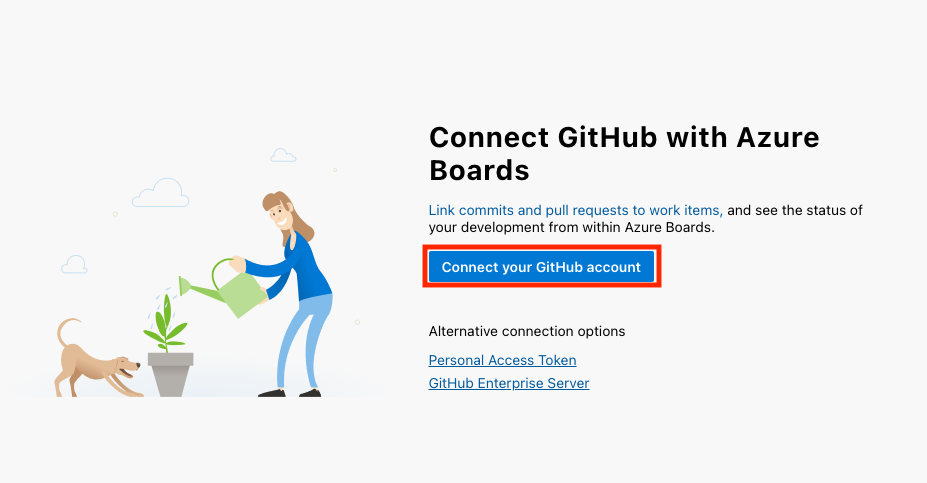
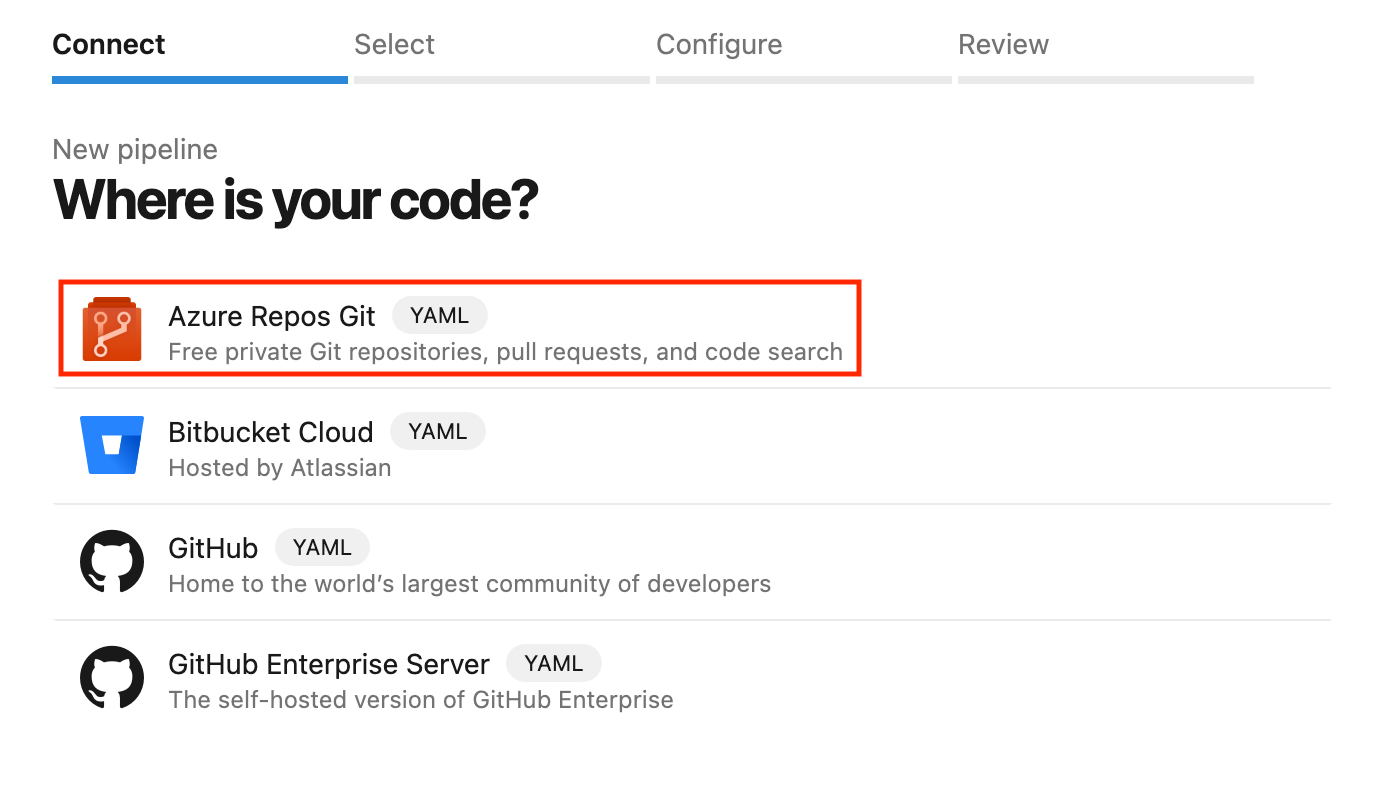
Pour ce tutoriel, nous utiliserons Azure Repos comme dépôt de code. Si vous débutez ou si vous n'avez pas de raison particulière de choisir TFVC, je vous conseille de choisir Git.
Il est temps de créer notre premier pipeline. Suivez les étapes ci-dessous :
Azure Pipelines propose deux façons de définir vos pipelines :
.yaml ou .yml dans votre référentiel de sources, ce qui permet d'obtenir des versions et d'améliorer la collaboration.|
Aspect |
Pipelines YAML |
Éditeur classique |
|
Contrôle des versions |
Les pipelines YAML prennent en charge le contrôle des versions et sont stockés dans le référentiel du code source. |
L'Éditeur classique ne prend pas en charge le contrôle des versions. Il s'agit d'une interface utilisateur graphique (GUI). |
|
Flexibilité |
Les pipelines YAML offrent une grande flexibilité. |
L'éditeur classique a une flexibilité limitée. |
|
Meilleur pour |
Les pipelines YAML conviennent mieux aux flux de travail complexes et à long terme, ainsi qu'à l'automatisation. |
L'éditeur classique convient mieux aux installations rapides. |
D'après mon expérience, les pipelines YAML offrent une plus grande flexibilité et conviennent mieux aux équipes qui suivent les pratiques de l'infrastructure en tant que code (IaC) sur le site. Mais cet éditeur classique est parfait pour les plus novices qui ont une vision plus visuelle des choses.
Toutefois, pour des raisons d'évolutivité à long terme, il est recommandé d'utiliser les pipelines YAML plutôt que l'éditeur classique.
Voyons maintenant comment nous pouvons construire avec Azure Pipelines.
Dans cette section, nous allons spécifier les étapes qu'Azure Pipelines suit pour construire votre code, comme l'installation des dépendances, la compilation et l'exécution des tests. Nous allons exprimer ces étapes dans un fichier de configuration dans notre code source en utilisant YAML, un moyen simple et lisible par l'homme de décrire les étapes d'une recette.
Voici un exemple simple de pipeline YAML :
# This section defines the trigger(s) for the pipeline.
# 'main' specifies that the pipeline will run whenever changes are pushed to the 'main' branch.
trigger:
- main # automatically triggers this pipeline when changes are made to the 'main' branch.
# This defines the pool where the pipeline will run.
# 'ubuntu-latest' specifies the virtual machine image for executing tasks.
pool:
vmImage: 'ubuntu-latest' # This uses the latest Ubuntu image provided by Azure DevOps.
# Steps contain the individual tasks or actions that the pipeline will execute.
steps:
- script: echo Hello, world! # A script task to run shell commands. This one prints "Hello, world!".
displayName: 'Run my first pipeline script' # A friendly name for this step, making it easier to identify in the pipeline logs.Décomposons le code étape par étape :
trigger: Spécifie la branche qui déclenche le pipeline (par exemple, main).pool: Définit l'agent de construction (par exemple, ubuntu-latest).steps: Liste les tâches à exécuter, telles que l'installation des dépendances et l'exécution d'un script de construction.Pour ajouter des étapes de construction à votre pipeline YAML, vous devez définir le "script" dans la section "étapes".
Pour une simple application Node.js, par exemple, notre fichier azure-pipelines.yml ci-dessous contient du code créé automatiquement par Azure DevOps.
# Node.js
# Build a general Node.js project with npm.
# Add steps that analyze code, save build artifacts, deploy, and more:
# https://docs.microsoft.com/azure/devops/pipelines/languages/javascript
trigger:
- main
pool:
vmImage: 'ubuntu-latest'
steps:
- task: NodeTool@0
inputs:
versionSpec: '20.x'
displayName: 'Install Node.js'
- script: |
npm install
npm run build
displayName: 'npm install and build'Jetons un coup d'œil au build steps dans le pipeline YAML ci-dessus :
NodeTool@0 pour spécifier la version de Node.js. npm install pour installer les dépendances du projet. npm run build pour compiler le code. Notre pipeline peut être déclenché manuellement ou configuré pour s'exécuter automatiquement lorsque des événements tels que des poussées de branches se produisent.
main afin de déclencher automatiquement le pipeline. En voici un exemple :trigger:
- mainAprès avoir exécuté votre pipeline, vous pouvez consulter les journaux et résoudre les problèmes éventuels.
Pour accéder aux journaux, accédez au résumé de l'exécution de votre pipeline et sélectionnez le travail ou la tâche en question. Cela affichera les journaux pour cette étape ; comme dans l'image ci-dessous, vous pouvez choisir n'importe quel travail (Build, Push, ou Update) pour voir les journaux bruts.
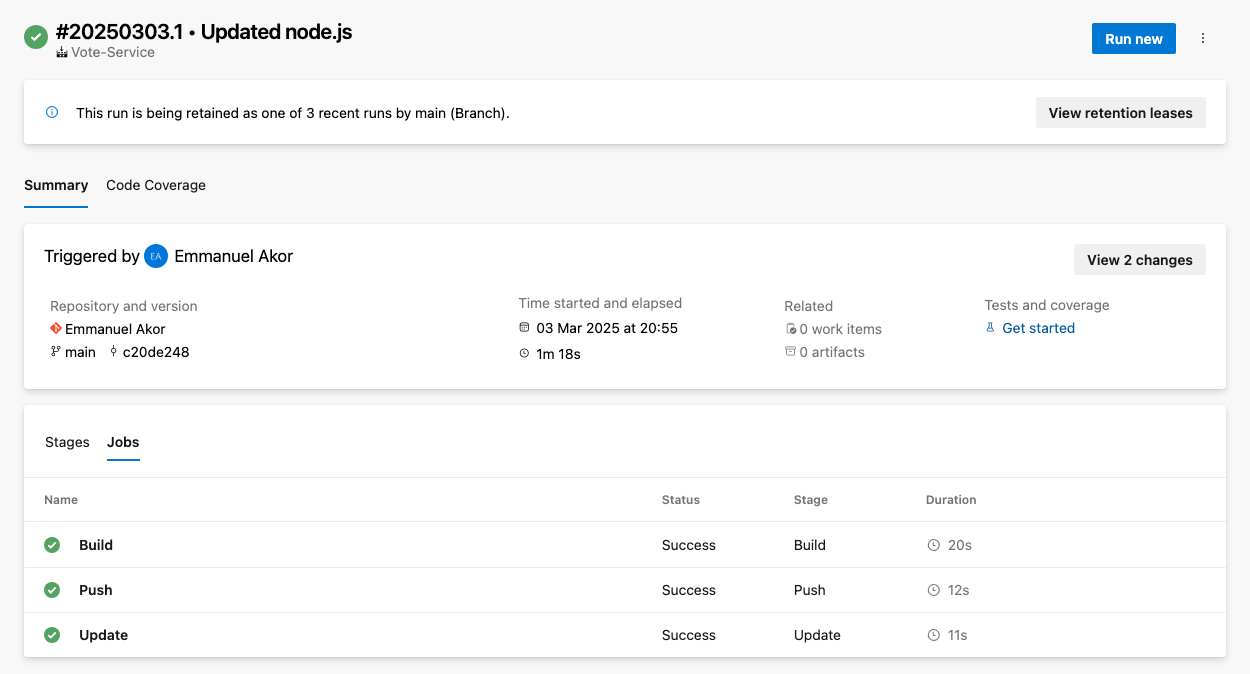
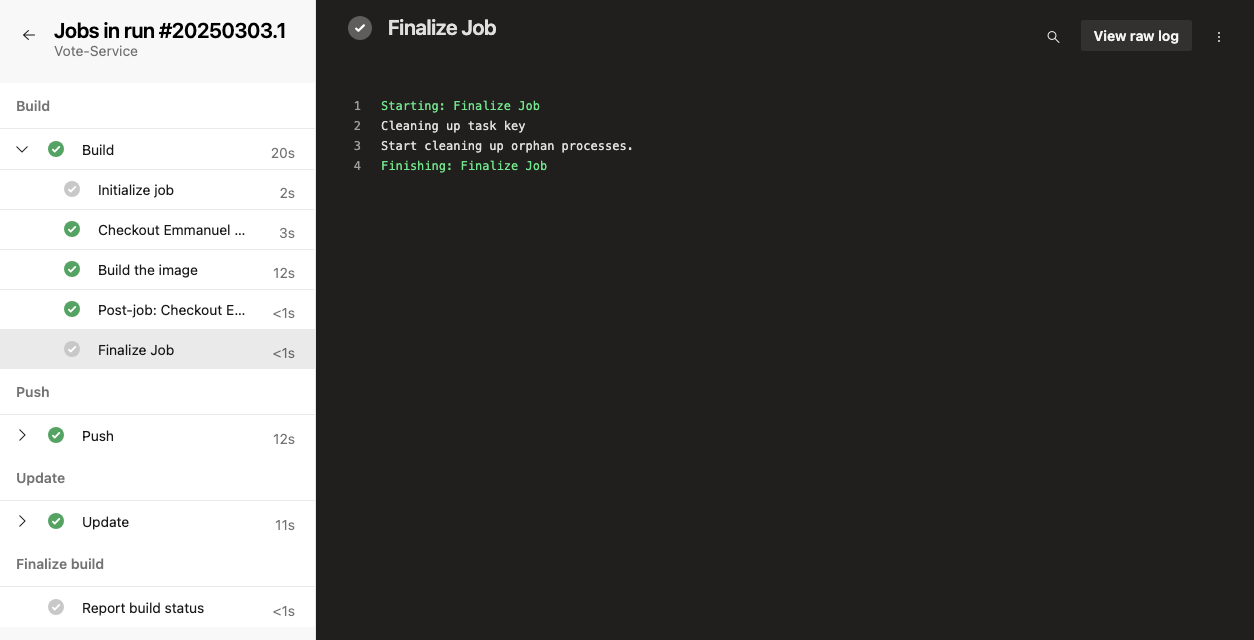
Pour résoudre les problèmes courants, vous pouvez vérifier que votre pipeline ne présente pas de problèmes courants tels que des dépassements de délai, des contraintes de ressources ou des configurations erronées.
Vous ajoutez des tests à votre pipeline pour garantir la qualité du code et détecter les problèmes dès le début du développement. Dans Azure Pipelines, vous pouvez intégrer des tests unitaires, d'intégration ou autres en ajoutant des étapes dans la configuration de votre pipeline.
Intégrez des étapes de test dans votre pipeline pour garantir la qualité du code. Vous pouvez utiliser des frameworks populaires comme Jest, Mocha ou NUnit. Par exemple, voici comment ajouter des tests unitaires avec Jest :
- script: |
npm test
displayName: 'Run unit tests with Jest'Azure Pipelines intègre des rapports de test. Vous pouvez configurer la publication des résultats des tests pour un suivi plus simple et consulter les résultats des tests dans les journaux de pipeline. Voici comment :
PublishTestResults@2 pour afficher les résultats. Le cursus global s'en trouve facilité. Par exemple :- task: PublishTestResults@2
inputs:
testResultsFiles: '**/test-results.xml'
testRunTitle: 'Unit Tests'Dans les étapes de déploiement de votre fichier YAML du pipeline Azure, vous pouvez déployer automatiquement votre application dans plusieurs environnements, tels que testing, staging et production. Dans cette section, nous allons passer en revue quelques méthodes de déploiement avec Azure Pipelines.
Azure Web Apps est un service du portail Azure qui vous permet de développer, de déployer et de gérer des applications web à grande échelle.
Pour déployer vers Azure Web Apps, vous devez relier les deux services. Voici comment procéder :

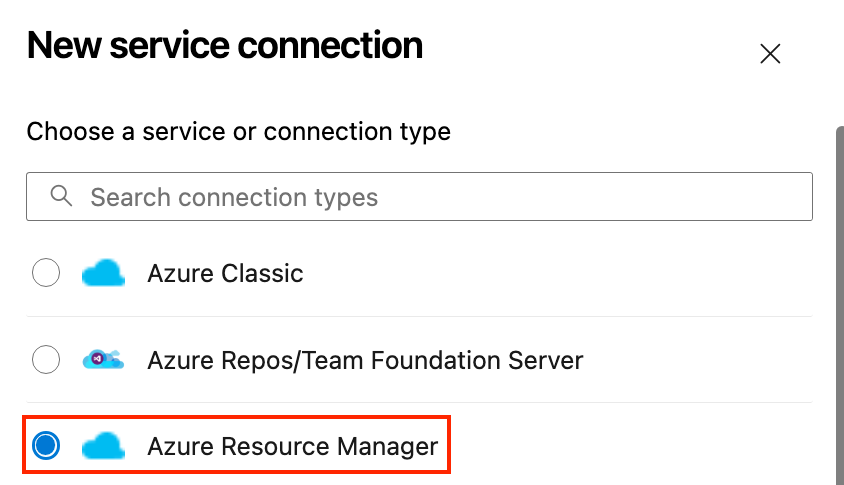
Voici un exemple de pipeline de déploiement YAML pour une simple application Node.js vers Azure App Service :
# Define the task for deploying to an Azure Web App
- task: AzureWebApp@1
inputs:
# This specifies your Azure subscription service connection
azureSubscription: 'your-azure-subscription'
# This specifies the name of your web app
appName: 'your-app-name'
# This specifies the location of the app package or files to be deployed
package: '$(Build.ArtifactStagingDirectory)'Décomposons le code ci-dessus, afin que vous puissiez l'adapter à votre cas d'utilisation :
your-azure-subscription par le nom de la connexion de service qui donne accès à votre abonnement Azure.your-app-name par le nom réel de votre application web dans Azure. $(Build.ArtifactStagingDirectory) par le répertoire où placer le paquetage ou les fichiers de l'application web pour le déploiement. $(Build.ArtifactStagingDirectory) - Cette variable pointe vers le dossier où se trouvent vos artefacts de construction (vos fichiers d'application) une fois qu'ils ont été construits.Une fois que tout notre code a passé tous les tests et vérifications, l'étape suivante consiste à mettre en place notre déploiement continu. Suivez les étapes décrites ci-dessous.
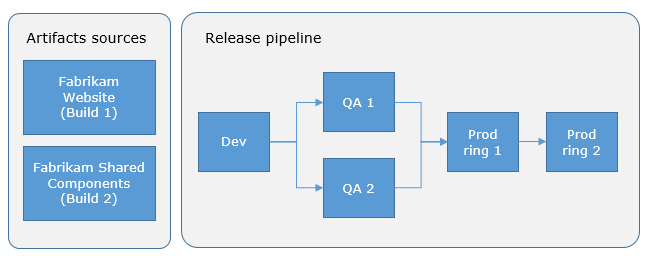
Modèle de déploiement du pipeline de diffusion Azure (Source : Microsoft)
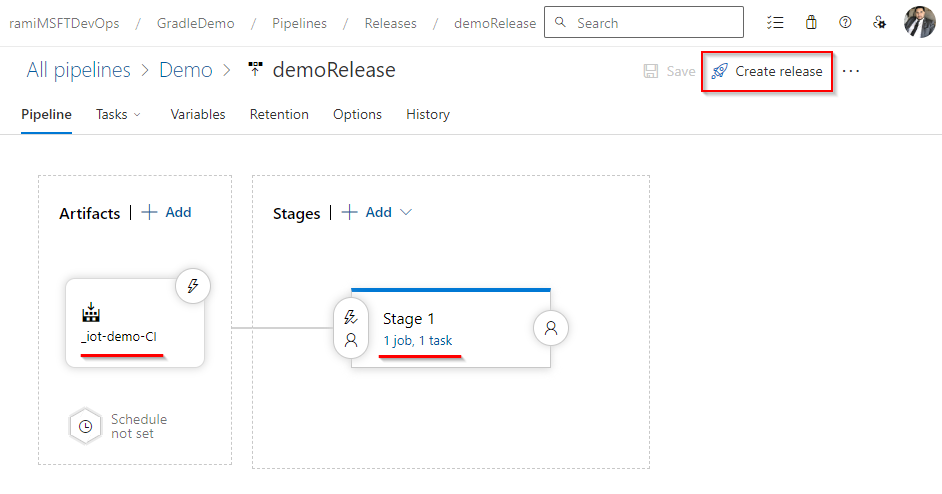
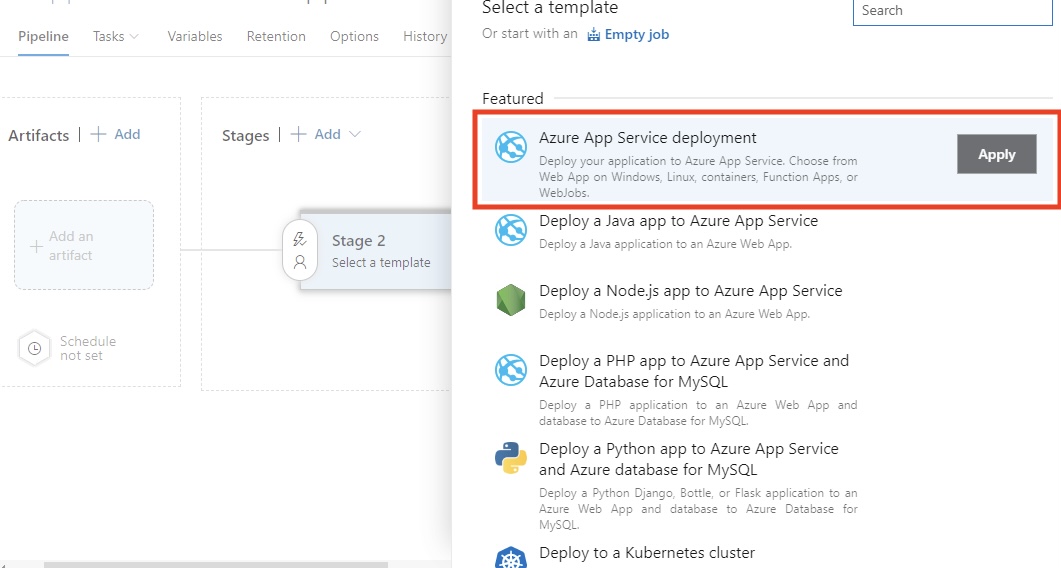
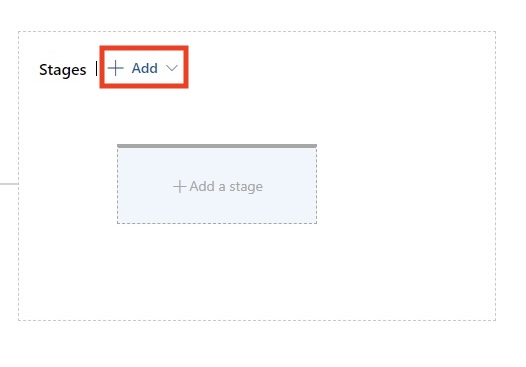
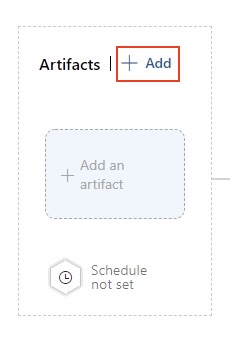
D'après mon expérience, cette phase est nécessaire pour maintenir la stabilité dans des environnements de développement exigeants. Les approbations et les barrières assurent le contrôle et garantissent que seul un code de haute qualité est mis en production.
Kubernetes facilite l'exécution d'applications conteneurisées fiables et évolutives. En utilisant Azure Kubernetes Service (AKS), vous bénéficiez d'un environnement géré qui simplifie le déploiement et les opérations. Dans cette section, je vais vous expliquer comment déployer votre application sur AKS à l'aide d'Azure Pipelines.
Vous pouvez créer un cluster AKS à l'aide du portail Azure ou de la CLI. Voici une commande de base de l'interface Bash CLI pour provisionner un cluster :
az aks create \
--resource-group <ResourceGroupName> \
--name <AKSClusterName> \
--node-count 3 \
--enable-addons monitoring \
--generate-ssh-keysDécortiquons la commande ci-dessus :
--resource-group: Ceci indique le groupe de ressources Azure dans lequel le cluster AKS sera créé.--name: Il s'agit du nom de votre cluster AKS.--node-count: Ce paramètre définit le nombre de nœuds dans la grappe (par exemple, 3 dans cet exemple).--enable-addons monitoring: Cela rend possible la surveillance et l'analyse avec Azure Monitor for Containers.--generate-ssh-keys: Cette option génère automatiquement des clés SSH pour un accès sécurisé au nœud si elles ne sont pas fournies.N'oubliez pas de remplacer et par les noms de vos groupes de ressources et de vos clusters.
Kubectl doit être configuré après la mise en place de votre cluster AKS. Cela garantit que votre agent de pipeline ou votre ordinateur local peut utiliser kubectl pour communiquer avec le cluster.
Vous pouvez accélérer vos tâches Azure à l'aide de la ligne de commande pourols - cet aide-mémoire sur la ligne de commande Azure est une référence pratique.
Prenons l'exemple d'un fichier YAML de déploiement de base pour déployer une image Docker sur Kubernetes :
# This defines the API version and the kind of Kubernetes resource we are creating.
# 'apps/v1' is the API version, and 'Deployment' is the resource type.
apiVersion: apps/v1
kind: Deployment
# Metadata contains information to identify the resource uniquely.
# 'name' specifies the name of the Deployment.
metadata:
name: my-app # Name of the Deployment, used for identification.
# "spec" specifies the intended deployment state.
spec:
# Number of replicas/pods we want for this Deployment.
replicas: 3 # Ensures high availability by running three app replicas.
# Selector is used to define the labels that this Deployment will manage.
selector:
matchLabels:
app: my-app # This ensures that only Pods with the label 'app: my-app' are managed by this Deployment.
# Template specifies the blueprint for the pods created by the Deployment.
template:
metadata:
labels:
app: my-app # Labels for the Pods, matching the selector above.
# A specification for the containers of the Pods.
spec:
containers:
- name: my-app # Name of the container. This is useful for linking to the container in logs, etc.
image: mycontainerregistry.azurecr.io/my-app:latest # Pull the container image you will call from your container registry.
ports:
- containerPort: 80 # The container listens on port 80.Dans votre pipeline YAML, incluez une tâche de déploiement vers AKS.
# This defines a task for deploying Kubernetes manifests within an Azure DevOps pipeline.
- task: KubernetesManifest@0 # Task type for working with Kubernetes manifest files.
inputs:
# This configures what to do with the Kubernetes manifest files.
action: 'deploy' # 'deploy' action ensures the Kubernetes manifests are applied to the cluster.
# This defines the namespace where the Kubernetes resources will be deployed.
namespace: 'default' # 'default' is the namespace for deploying resources. Change if needed.
# All this does is point to the manifest files that define the desired state of your Kubernetes resources.
manifests: '$(Build.ArtifactStagingDirectory)/manifests/*.yaml'
# The 'manifests' variable points to the location of all the YAML files (e.g., Deployment, Service, etc.) that will be applied during the deployment.
# To access private container registry images, use the image pull secret.
imagePullSecrets: 'my-registry-secret'
# This instructs Kubernetes on which secret to use when pulling images from a private container registry.
# Ensure that 'my-registry-secret' exists in the namespace before the deployCommencer et pousser le fichier YAML pour déclencher le déploiement.
AKS simplifie l'orchestration des conteneurs, ce qui facilite la gestion de la mise à l'échelle, des mises à jour et des retours en arrière. D'après mon expérience, c'est un must-have pour les applications cloud-natives modernes.
Au début de ma carrière, la construction de pipelines n'était pas le plus grand défi - c'était le fait d'avoir un pipeline rapide et fiable qui l'était. Un pipeline bien optimisé ne se contente pas de rendre les constructions plus rapides ; il réduit également la frustration des équipes, diminue les risques de déploiement et accélère la livraison.
Je vais partager avec vous quelques conseils et stratégies que vous pouvez utiliser pour que vos pipelines Azure DevOps soient rapides, organisés et fiables.
L'installation des dépendances est un autre goulot d'étranglement courant dans les pipelines. Que vous travailliez avec npm, .NET ou d'autres gestionnaires de paquets, le téléchargement répété des mêmes dépendances peut vous faire perdre beaucoup de temps. La mise en cache des dépendances et des artefacts entre les exécutions réduit considérablement le temps d'exécution.
Voici comment mettre en cache les dépendances dans Azure Pipelines.
Tout d'abord, vous devez identifier les gestionnaires de paquets, tels que :
node_modules)pip packages)Azure Pipelines prend en charge les mécanismes de mise en cache, tels que la tâche Cache@2, qui vous permet de mettre en cache les dépendances entre les exécutions du pipeline.
Prenons l'exemple d'une simple mise en cache pour Node.js :
# This task is used to cache files to speed up your pipeline.
- task: Cache@2 # This is the task name for caching files in Azure Pipelines.
inputs:
# Key is used to identify the cache. It combines npm (package manager), operating system (OS), and package-lock.json files.
key: 'npm | "$(Agent.OS)" | package-lock.json'
# RestoreKeys is an optional value used when the specific cache key is not found. It helps to find a fallback cache.
restoreKeys: |
npm | "$(Agent.OS)"
# Path defines the location of files or folders to be cached.
# Here, we are caching the 'node_modules' directory to avoid reinstalling dependencies.
path: '$(Build.SourcesDirectory)/node_modules'
# CacheHitVar is a variable that stores whether the cache was successfully used (restored).
# This can be checked later in the pipeline to decide if tasks need to run.
cacheHitVar: 'NPM_CACHE_RESTORED'Vous pouvez alors ignorer l'installation en cas de mise en cache. Il s'agit d'une vérification judicieuse avant de terminer l'installation de npm. Il s'agit d'une logique efficace basée sur des conditions.
Prenons un exemple simple ci-dessous :
# This step runs the command to install Node.js dependencies using npm.
- script: npm install # Installs packages listed in the package.json file.
# The condition checks whether the cache was restored successfully.
# This step will run if the cache is not restored ('NPM_CACHE_RESTORED' is not true).
condition: ne(variables.NPM_CACHE_RESTORED, 'true') # Run only if the cache is not restored.Cet exemple de mise en cache simple pour une application Node.js enregistre le répertoire de cache npm en utilisant package-lock.json comme clé. Lorsque vos dépendances ne changent pas, il les restaure, ce qui permet de gagner quelques minutes à chaque compilation.
J'ai constaté que la mise en cache réduisait considérablement le temps de construction, en particulier dans les grands projets, mais uniquement si les clés de cache sont choisies avec soin. Dans l'un de mes anciens projets, cela a permis de réduire le temps de construction d'une application Node.js de 55 %.
La réussite d'un pipeline ne se résume pas à des coches vertes, à la visibilité et à un retour d'information rapide. Lorsque quelque chose se casse, vous voulez que votre équipe le sache immédiatement. Voici comment garder une longueur d'avance sur les problèmes.
Azure DevOps fournit des widgets intégrés pour afficher l'état des pipelines, les exécutions récentes, les taux d'échec et les durées moyennes.
Elles sont essentielles pour le cursus des réussites et des échecs, pour déterminer les environnements qui posent problème, etc.

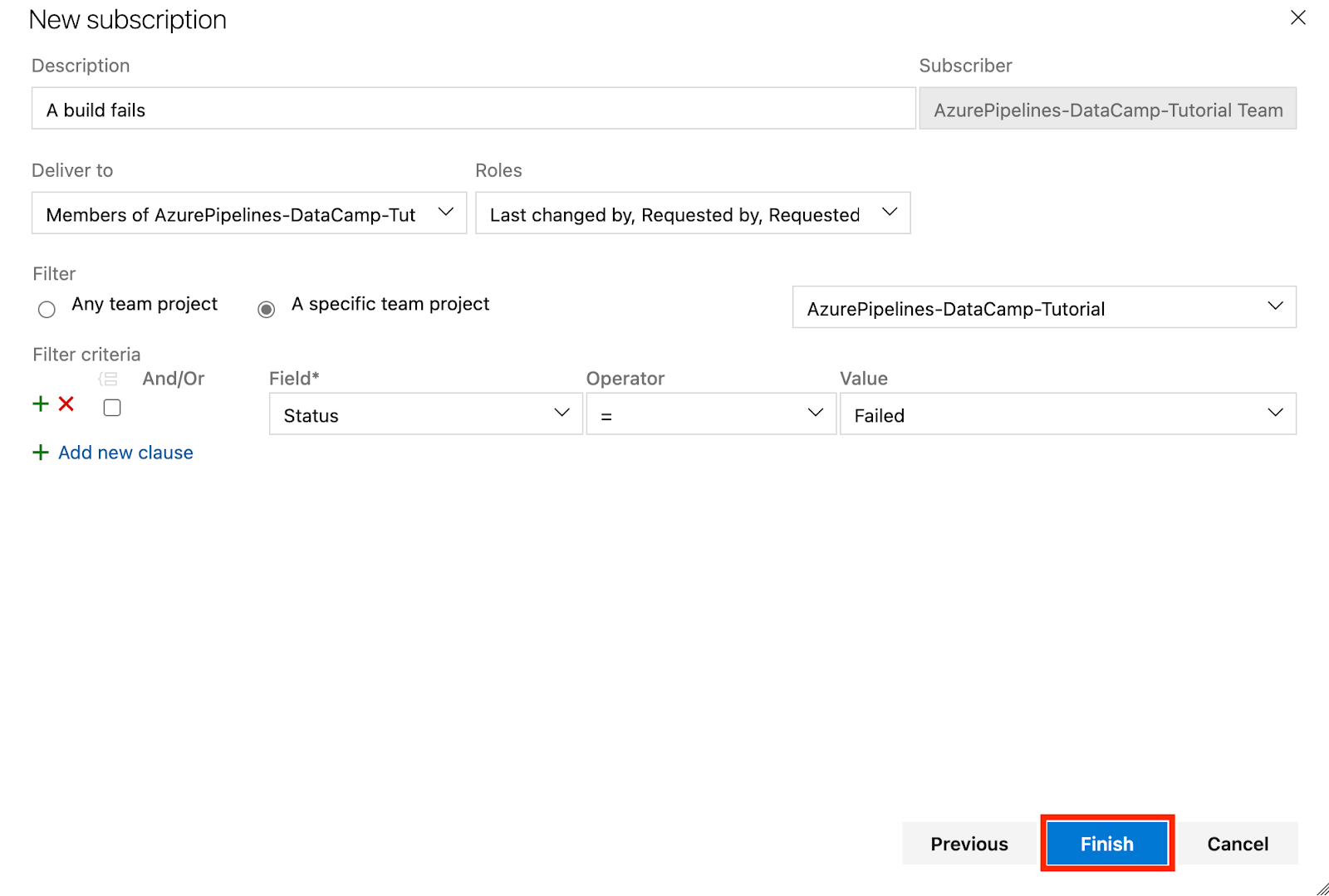
Prenons un scénario : Dans la section Category, sélectionnez Build ; dans la section Template, sélectionnez "A build fails", puis cliquez sur Next.
Vous avez une interface comme celle-ci :

Il m'est arrivé de rater un déploiement critique parce que des alertes n'avaient pas été mises en place. Depuis lors, j'ai toujours mis en place et configuré des alertes d'équipe pour chaque déploiement de production. De cette façon, je ne manque jamais une version défectueuse ou un retard dans mon cycle de publication.
Nous savons que même si votre pipeline fonctionne, il peut être lent, et les pipelines lents tuent la productivité. L'identification précoce des goulets d'étranglement permet donc d'éviter des problèmes ultérieurs.
Les mesures du pipeline permettent d'évaluer les performances des constructions et des déploiements. Voici comment y accéder.
Tout d'abord, vous devez activer Vues analytiques dans les paramètres du projet et vous connecter à Power BI ou explorer via les graphiques intégrés.
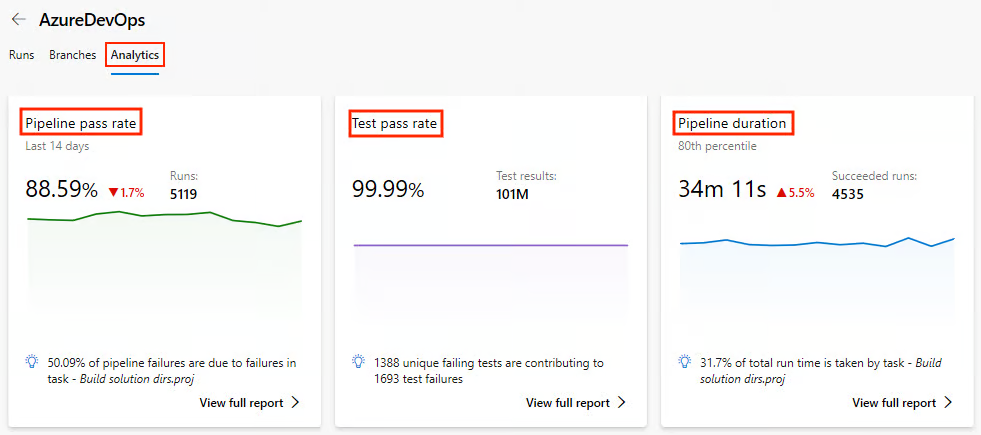
Voyons plus en détail quelles sont les mesures clés que nous pouvons surveiller dans le cadre de l'analyse et pourquoi elles sont importantes :
|
Métrique |
Pourquoi c'est important |
|
Tendances de la durée de construction |
Cela permet de repérer facilement les ralentissements au fil du temps. |
|
Taux d'échec par branche |
Cela permet d'identifier les caractéristiques instables. |
|
Temps dans la file d'attente |
Cela permet de détecter les pénuries d'agents. |
Il y a quelques mois, j'ai travaillé sur le pipeline d'un client, etce qui m'a le plus frappé, c'est le temps passé dans la file d'attente. J'ai découvert un jour que mon équipe et moi-même avions surchargé un pool d'agents auto-hébergés, et que 40 % du temps de notre pipeline était consacré à l'attente d'un coureur disponible. Personne ne l'a vu venir jusqu'à ce que les analyses le rendent évident.
Nous pourrions y remédier en ajoutant deux agents auto-hébergés supplémentaires et en répartissant la charge par type de travail. Les résultats ont été immédiats : la durée moyenne de construction du pipeline a diminué d'environ 35 %.
Ainsi, au-delà des mesures, les journaux de la ligne de temps sont précieux, en particulier pour les tâches de longue haleine. Au fil des ans, j'ai pris l'habitude d'ajouter des marqueurs de journal personnalisés à l'intérieur des étapes critiques des scripts afin de repérer les retards exacts.
Prenons un exemple simple :
# This step prints a message to the console in the pipeline logs.
# It helps to mark the start of the dependency installation process.
echo "=== START: Dependency Install ===" # Display a message indicating the beginning of dependency installation.Maintenant que nous avons abordé les services de base d'Azure Pipelines et bien d'autres encore, voyons comment en tirer le meilleur parti en suivant ces bonnes pratiques.
Passons de la performance à la structure, car un pipeline rapide et difficile à maintenir nuira toujours à une équipe.
Lorsque plusieurs équipes ou environnements partagent des pipelines, les choses deviennent souvent compliquées. Vous avez besoin d'une structure. Un seul pipeline géant pour les environnements de développement, d'essai et de production conduit au chaos.
Pour organiser votre pipeline, vous devez le séparer en environnements. Examinons une structure simpleci-dessous.
|
Environnement |
Nom du pipeline |
Déclencheur |
|
Développement |
|
Branches de fonctionnalités (s'exécute à chaque livraison) |
|
Mise en scène |
|
Pull requests → Staging (Manual trigger) |
|
Production |
|
Canalisations manuelles ou à déclenchement (Approbation requise) |
Les éléments clés à comprendre à partir de cettestructure simple :
Par expérience, cette séparation facilite le débogage et permet aux développeurs débutants de se déployer dans l'environnement de développement sans risquer l'environnement de production.
DevOps consiste à réduire les flux de travail manuels et à améliorer l'automatisation du processus de développement de logiciels.
Le code YAML est sujet aux erreurs lorsqu'il est copié et collé d'un projet à l'autre. Azure DevOps propose des modèles de pipelines pour une configuration DRY (Don't Repeat Yourself) via des pipelines YAML. Vous pouvez réutiliser les modèles de pipeline YAML dans plusieurs projets, concevoir vos pipelines de manière cohérente et même réduire le temps de traitement des pipelines.
Prenons l'exemple d'un simple modèle de construction réutilisable.
Tout d'abord, définissez votre modèle de construction, build-template.yml:
# Here we configure the platform and the build configuration.
parameters:
buildPlatform: 'Any CPU' # This specifies the build platform (e.g., Any CPU, x86, x64).
buildConfiguration: 'Release' # This specifies the build configuration (Release) to avoid warning.
# A pipeline is composed of steps (a series of tasks that will be executed)
steps:
- task: DotNetCoreCLI@2 # Task for running .NET Core commands in the pipeline.
inputs:
command: 'build' # This runs the 'build' command to compile the project(s).
projects: '**/*.csproj' # This specifies to build all .csproj files in the repository.
arguments: '--configuration ${{ parameters.buildConfiguration }}'
# This passes the build configuration parameter (e.g., Release or Debug) to the command.Utilisez votre modèle de construction dans votre pipeline principal :
# A pipeline job is a group of tasks. Here, the job is named 'Build'.
jobs:
- job: Build # The job name where the build process occurs.
# Steps define the tasks or actions the pipeline will perform.
steps:
- template: templates/build-template.yml # Reference an external YAML template for reusable steps.Lorsque vous travaillez sur des projets, en particulier dans des environnements collaboratifs, il est courant d'utiliser des informations sensibles telles que des chaînes de connexion à des bases de données, des clés API, des mots de passe ou des jetons. Si ces secrets sont codés en dur dans votre base de code ou exposés dans des journaux, ils peuvent être facilement compromis.
Voyons comment gérer en toute sécurité nos secrets et nos variables à l'aide des groupes de secrets et de variables d'Azure Pipelines.
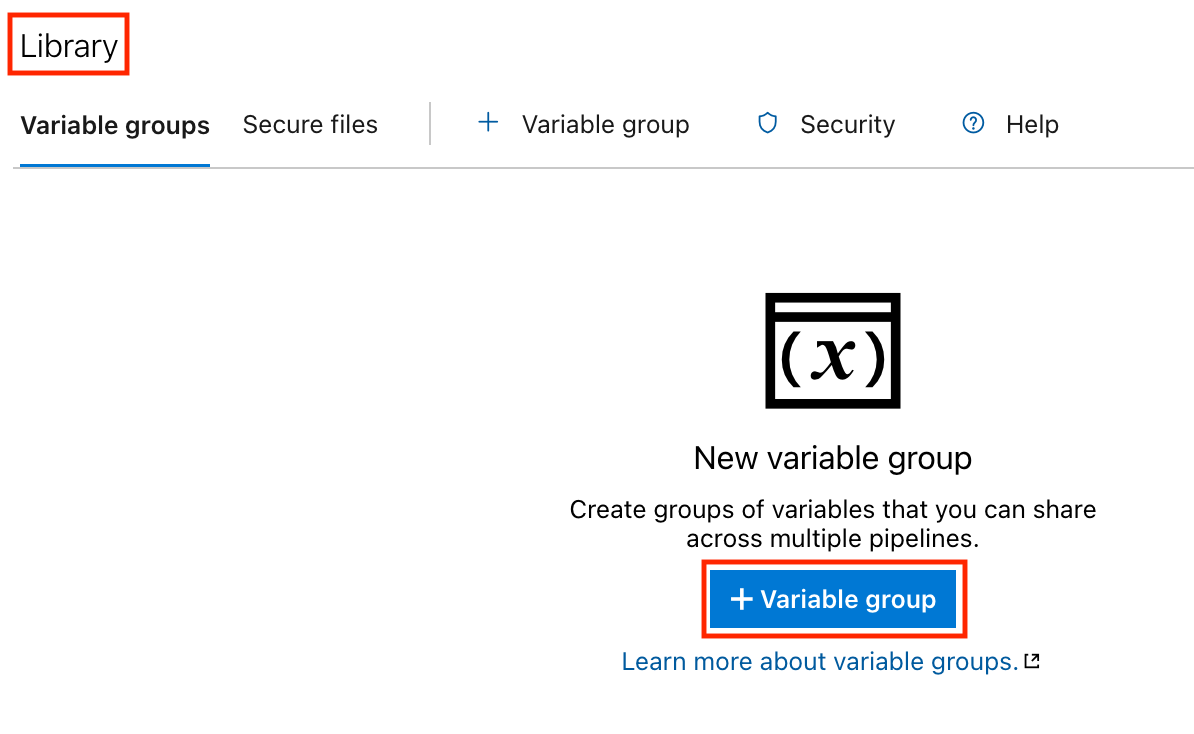
MyAppSecrets).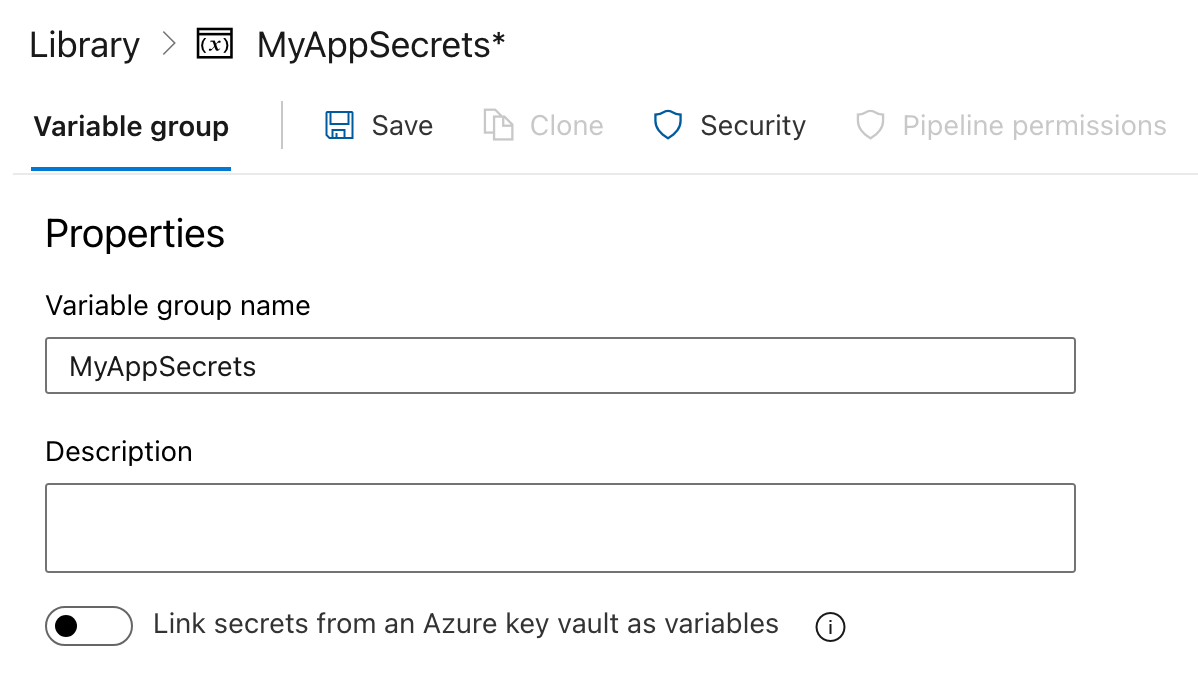

DB_CONNECTION_STRING).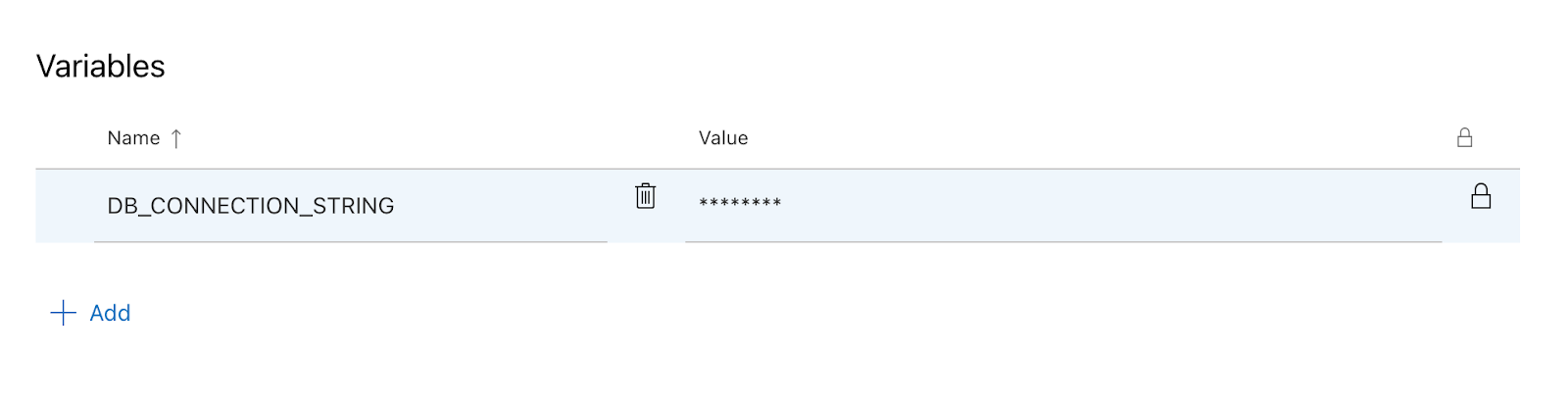
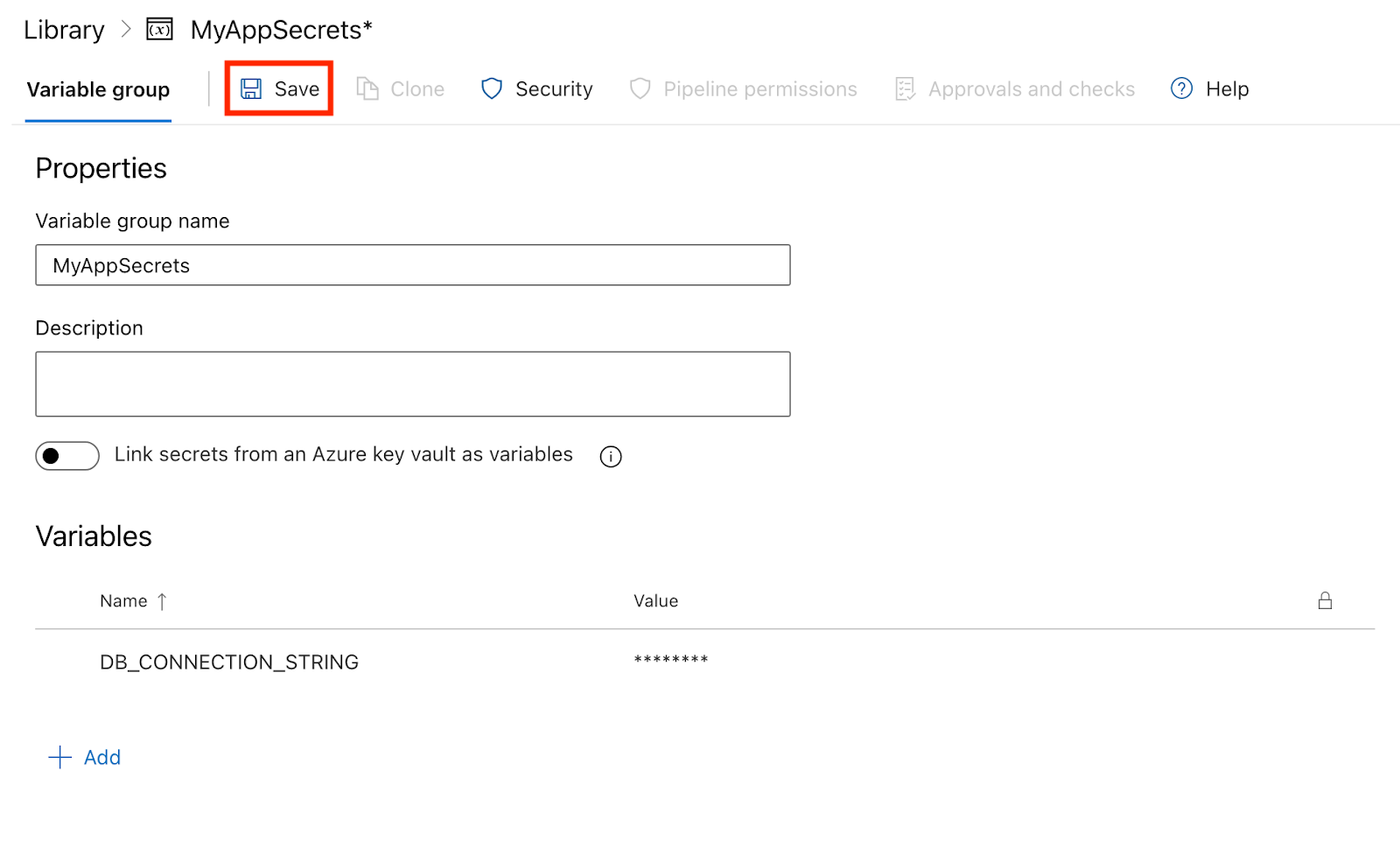
Maintenant que vous avez créé un groupe de variables avec des secrets, vous pouvez utiliser ces variables dans le fichier YAML de votre pipeline.
variables:
- group: MyAppSecrets$(VariableName). Voici un exemple d'utilisation de DB_CONNECTION_STRING dans une action de script :# This defines the trigger for the pipeline.
# The pipeline runs automatically whenever changes are pushed to the 'main' branch.
trigger:
- main # Trigger the pipeline on changes to the 'main' branch.
# The pool specifies the environment where the pipeline will run.
# 'ubuntu-latest' means the pipeline will use the latest Ubuntu operating system image.
pool:
vmImage: 'ubuntu-latest' # Use the latest Ubuntu image provided by Azure Pipelines.
# Variables section defines reusable values for the pipeline.
# 'group: MyAppSecrets' links to a variable group that stores sensitive information like secrets.
variables:
- group: MyAppSecrets # Load secrets, such as database credentials, from a variable group.
# Steps define the tasks that the pipeline will execute one by one.
steps:
- script: |
echo "Connecting to the database..." # Print a message indicating the start of database connection.
echo "Connection String: $(DB_CONNECTION_STRING)" # Display the database connection string from the variable group.
displayName: 'Connect to Database' # A simple name for this step that appears in the pipeline logs.Dans ce tutoriel, nous avons parcouru l'ensemble du parcours d'utilisation d'Azure Pipelines, de la configuration de votre premier pipeline à sa construction, son test, son déploiement, sa surveillance et son optimisation.
La phase de déploiement nécessite de la pratique. Commencez simplement, continuez à vous améliorer et, avec le temps, vous gagnerez en confiance et en aisance dans la gestion des flux de travail CI/CD. Azure Pipelines vous fournit les outils, vous apportez l'itération et l'apprentissage.
Grâce à des efforts constants, vous pouvez rationaliser votre processus de développement et devenir confiant dans la livraison de logiciels de haute qualité à grande échelle.
Pour en savoir plus sur Azure DevOps et Microsoft Azure, consultezles ressources suivantes :
Apprenez-en plus sur Azure avec ces cours !
Cours
Cours
Cours
blog
Zoumana Keita
15 min
blog
Kurtis Pykes
15 min
Tutoriel
Tutoriel
Satyabrata Pal
Tutoriel
Sejal Jaiswal
Tutoriel
Matt Crabtree
