
programa
Analista de datos en Python
36 h
En primer lugar, estaban los almacenes de datos. Almacenaban los datos en filas y columnas porque todo lo que Internet y los ordenadores de la época eran capaces de distribuir era simple información textual. Mucho más tarde llegaron los lagos de datos, que podían almacenar casi cualquier tipo de datos que pudieras recopilar. Eran geniales para la era de las redes sociales y YouTube.
Pero ambos tenían desventajas: los almacenes de datos eran caros e inadecuados para la ciencia de datos moderna, mientras que los lagos de datos eran desordenados y a menudo se convertían en pantanos de datos. Así que las empresas empezaron a tener dos pilas tecnológicas separadas: almacenes para BI y analítica y lagos para aprendizaje automático.
Sin embargo, gestionar dos arquitecturas de datos diferentes era tan pesado que las empresas solían obtener malos resultados. Esta cuestión dio lugar a la arquitectura de la casa del lago, que es precisamente por lo que Databricks es famosa.
Databricks es una plataforma basada en la nube que permite a los usuarios obtener valor tanto de los almacenes como de los lagos en un entorno unificado. Este artículo dará una visión general de la plataforma, mostrando sus características más importantes y cómo utilizarlas.
Databricks es una plataforma tan masiva que su propia documentación podría convertirse en un libro. Así pues, el objetivo del artículo es proporcionarte una jerarquía de conceptos: explicaciones ordenadas linealmente de las funciones de Databricks que te llevarán de principiante a profesional decente de Databricks. Si eres totalmente novato, también puedes consultar nuestro curso Introducción a Databricks.
¡Empecemos!
Cuando leas la palabra Databricks, debes pensar inmediatamente en ella como una plataforma, no como un framework o una biblioteca de Python. Normalmente, las plataformas ofrecen una amplia gama de funciones, y Databricks no es una excepción. Es una de las pocas plataformas que puede utilizar cualquier profesional de los datos, desde los ingenieros de datos hasta los modernos ingenieros de aprendizaje automático (o lo que la prensa llama hoy programadores de IA).
Databricks tiene los siguientes componentes básicos:
Estos componentes, en combinación, desbloquean una amplia gama de ventajas:
Si te he convencido de la importancia de Databricks en el mundo de los datos, vamos a ponerte en marcha con la plataforma.
Para configurar tu cuenta, ve a https://www.databricks.com/try-databricks y regístrate en la Edición Comunidad.
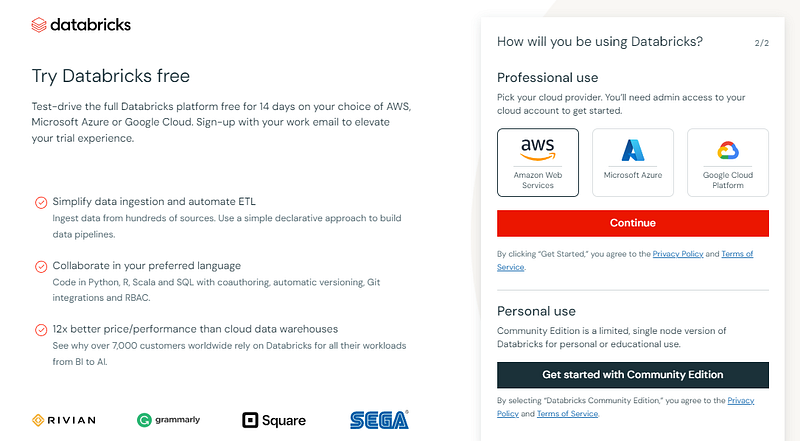
La Edición Comunidad tiene menos funciones que la versión Empresa, pero no requiere la configuración de un proveedor en la nube, lo que es estupendo para casos de uso reducido como los tutoriales.
Si tienes esta página después de la verificación por correo electrónico, puedes continuar:
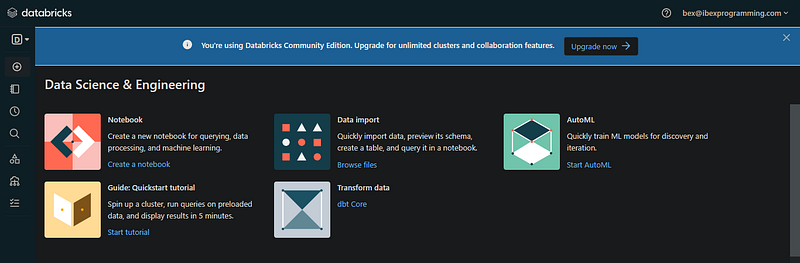
La interfaz que has descubierto es el espacio de trabajo de tu dirección de correo electrónico (el espacio de trabajo de la edición comunitaria se encuentra fácilmente). En la práctica, normalmente un administrador de cuentas de tu empresa crea una única cuenta Databricks y gestiona el acceso al espacio de trabajo.
Ahora, entendamos la interfaz de usuario de la plataforma. En el panel izquierdo, tenemos el menú de los distintos componentes que ofrece Databricks. La versión para empresas tendrá aún más botones:
La primera opción del menú es el tipo de espacio de trabajo, que por defecto está configurado como ciencia de datos e ingeniería. Si puedes cambiarlo a aprendizaje automático, aparecerá una nueva opción de Experimentos:

A primera vista, puede parecer que no hace gran cosa, pero una vez que actualices tu cuenta y empieces a juguetear, te darás cuenta de algunas grandes características de la plataforma:
etc.
Ahora, veamos algunos de estos componentes más de cerca.
Los clusters en Databricks se refieren a los recursos informáticos utilizados para ejecutar tareas de procesamiento de datos. Normalmente, los clusters son servidos por el proveedor de la nube que hayas elegido durante la configuración de la cuenta.
Los clusters de la edición comunitaria están limitados en RAM y potencia de CPU, y no incluyen GPU. Sin embargo, los usuarios premium a menudo pueden realizar las siguientes tareas con los clústeres de forma sencilla:
Para crear un clúster, puedes utilizar el botón "Crear" o las opciones "Computa" del menú:
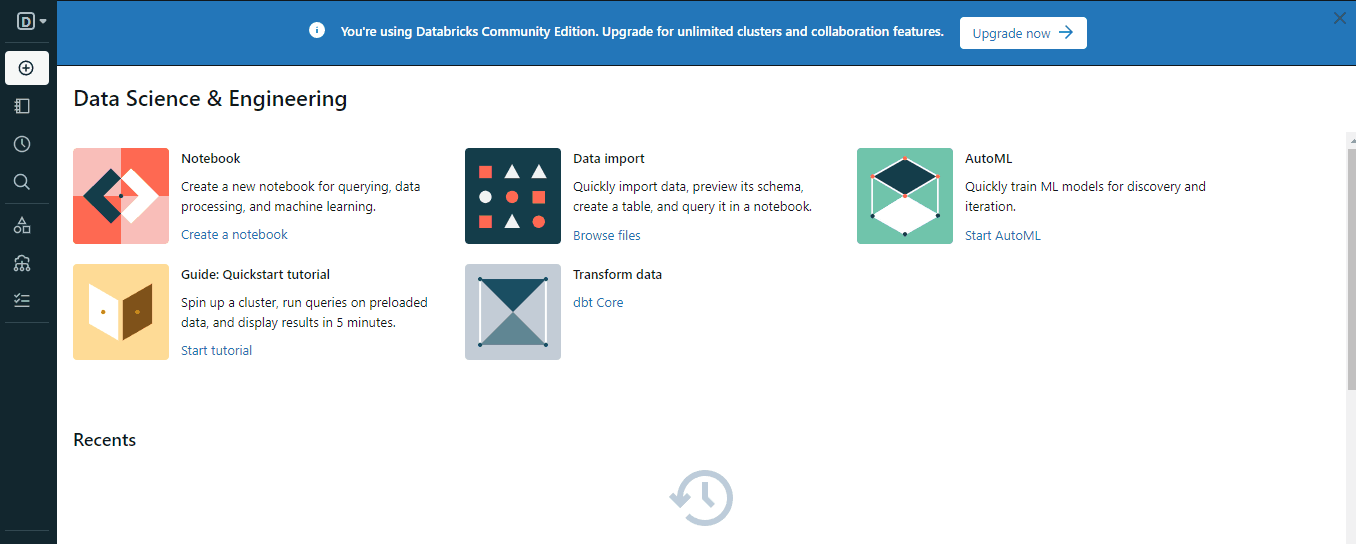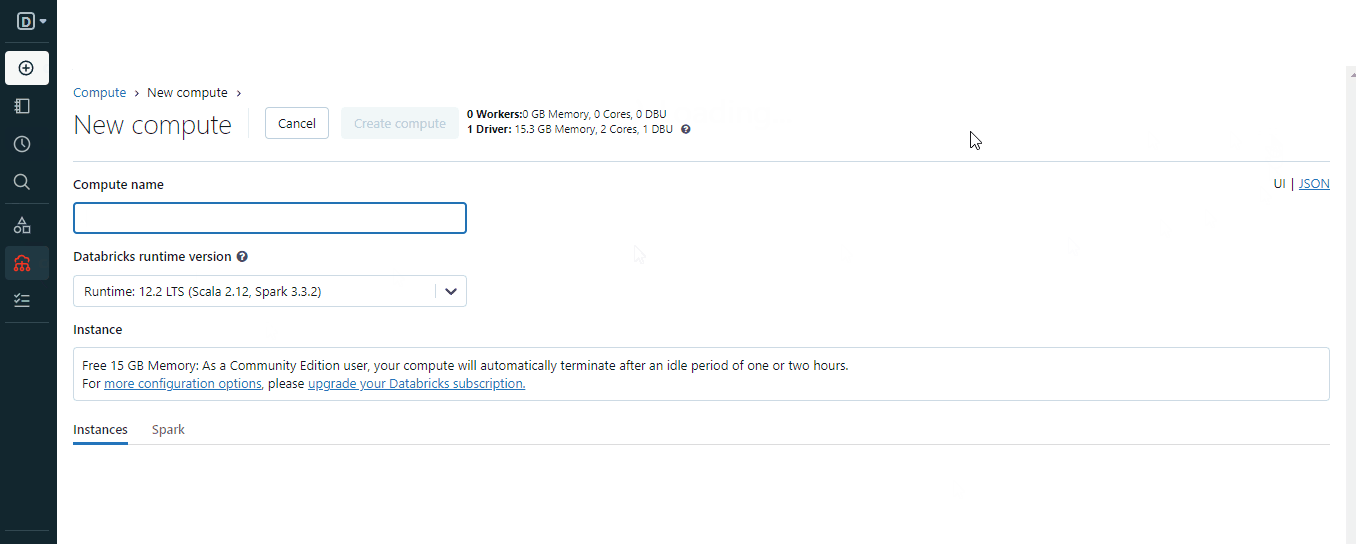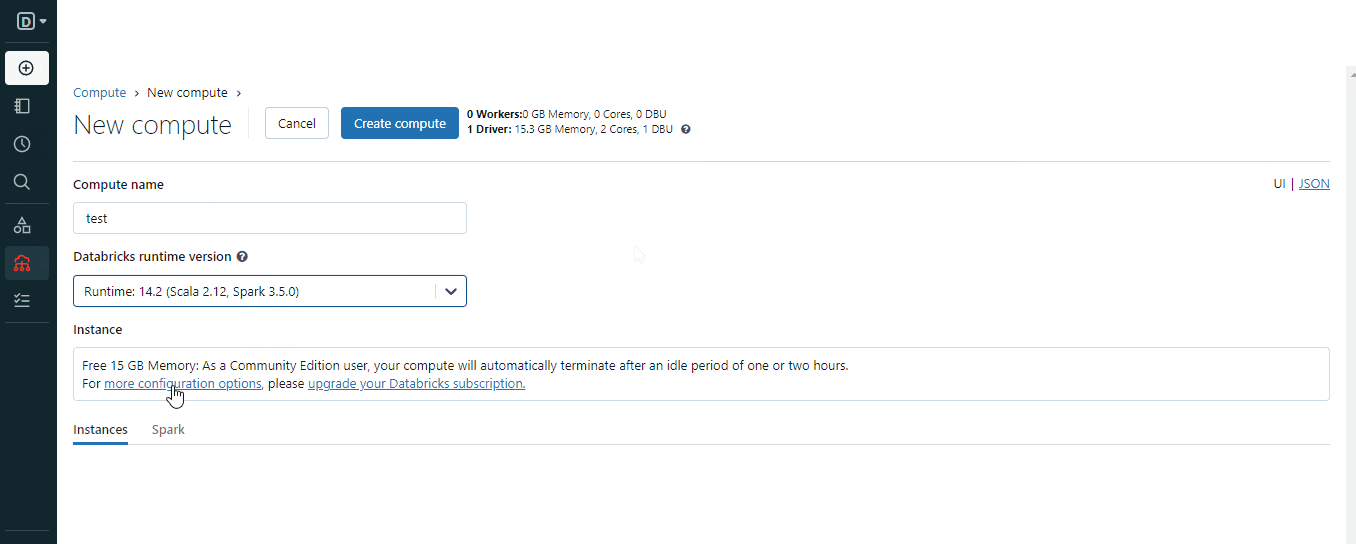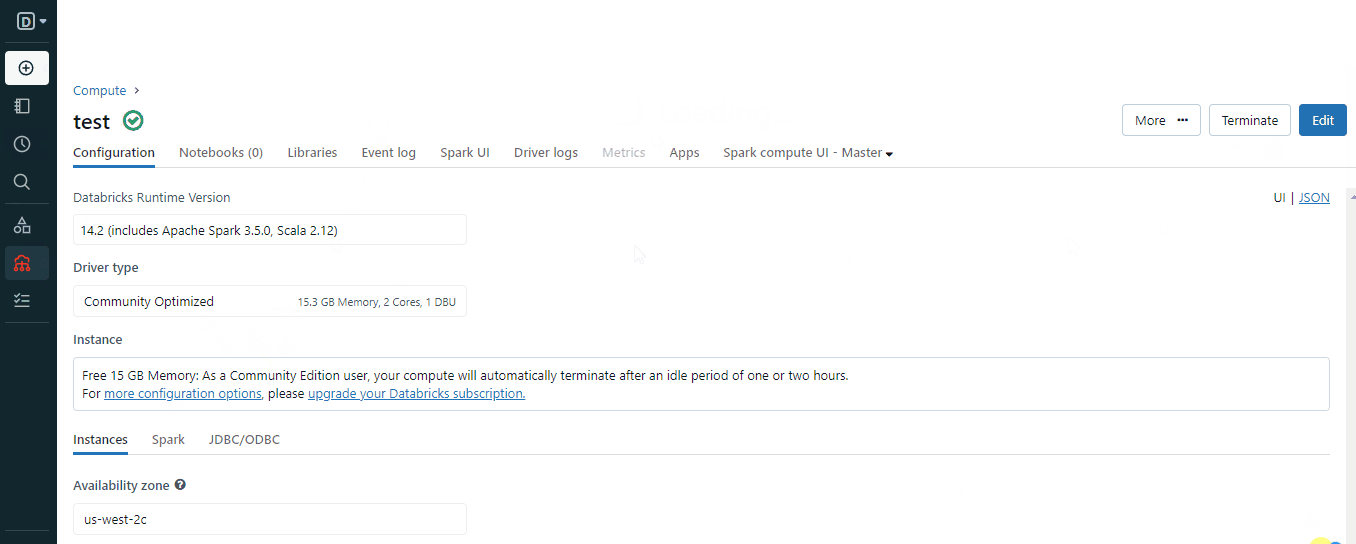
Al crear el clúster, elige una versión de Spark adecuada para tu entorno y espera unos minutos a que esté operativo.
Una vez que tengas un clúster en funcionamiento, estarás listo para crear blocs de notas. Si has trabajado con Jupyter, Colab o DataCamp Workspaces, esto te resultará familiar:
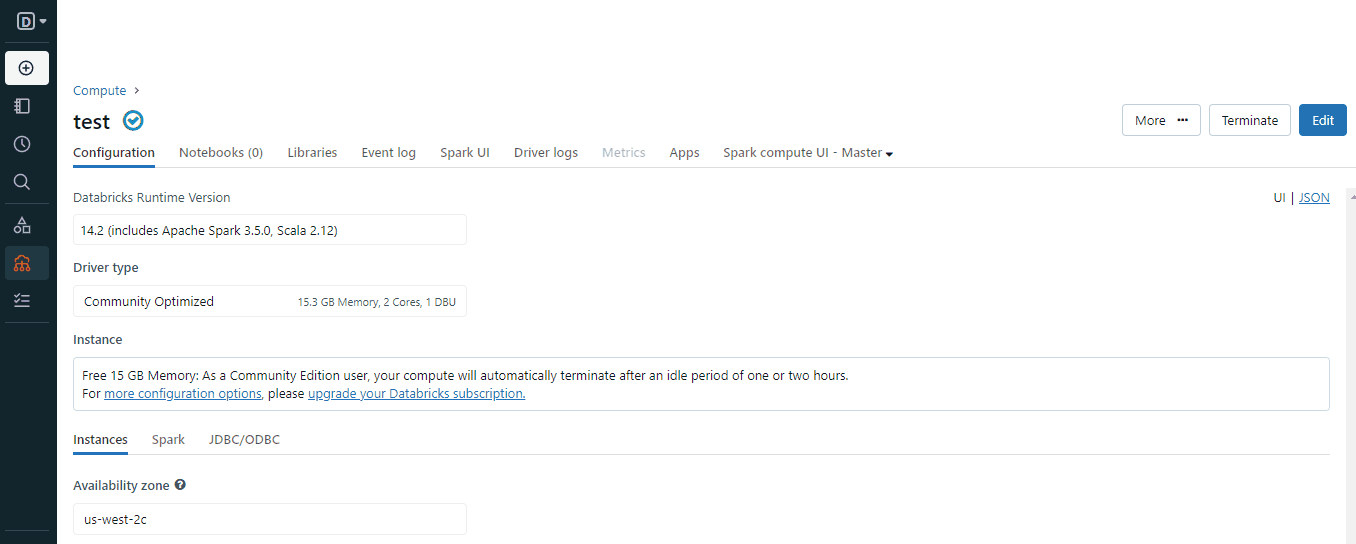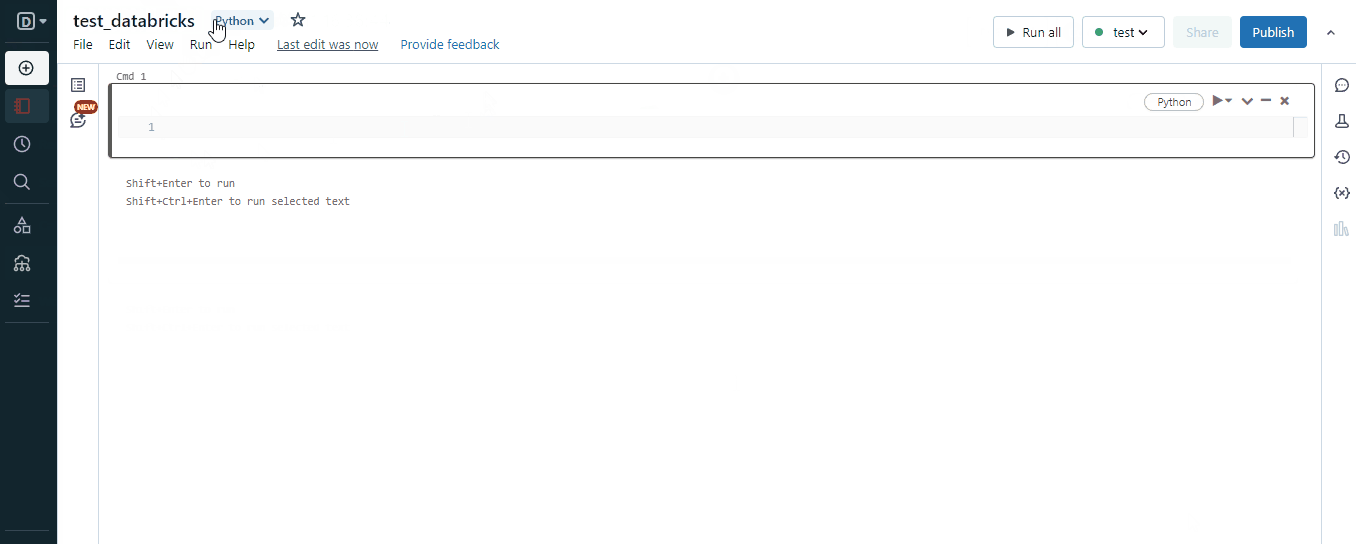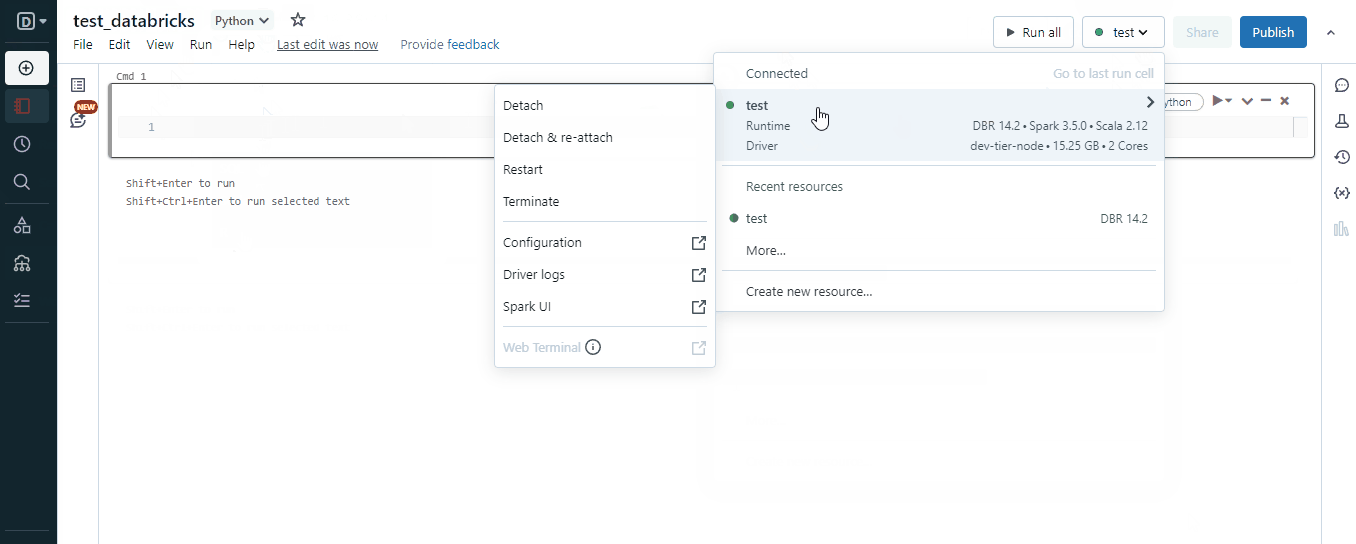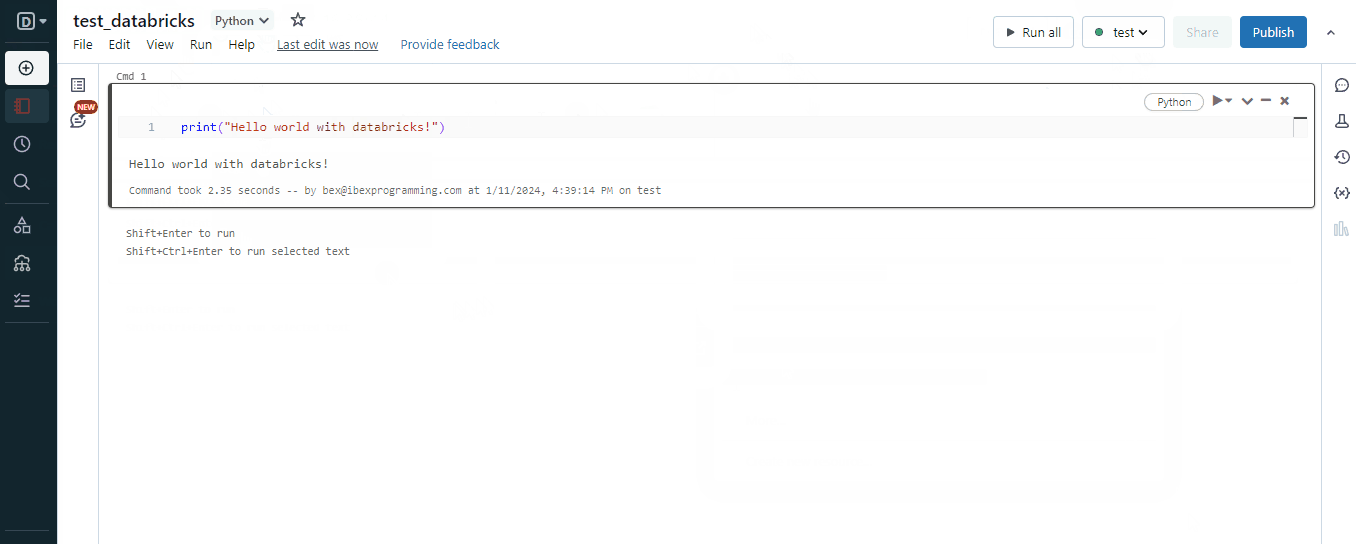
Pero en un mundo donde existe el verdadero Jupyter, ¿por qué ibas a optar por algo "similar a Jupyter"? Pues bien, los cuadernos Databricks tienen las siguientes ventajas sobre los cuadernos Jupyter:
Hay muchas otras ventajas de los cuadernos Databricks sobre Jupyter, así que aquí tienes una tabla que resume las diferencias:
|
Función |
Cuadernos Jupyter |
Cuadernos Databricks |
|
Plataforma |
De código abierto, se ejecuta localmente o en plataformas en la nube |
Exclusivo de la plataforma Databricks |
|
Colaborar y compartir |
Funciones de colaboración limitadas, compartir manualmente |
Colaboración integrada, edición simultánea en tiempo real |
|
Ejecución |
Depende de servidores locales o externos |
Ejecución en clusters Databricks |
|
Integración con Big Data |
Puede integrarse con Spark, requiere configuraciones adicionales |
Integración nativa con Apache Spark, optimizada para big data |
|
Funciones incorporadas |
Herramientas/extensiones externas para el control de versiones, la colaboración y la visualización |
Integrado con funciones específicas de Databricks como Delta Lake, soporte incorporado para herramientas de colaboración y análisis |
|
Coste y ampliación |
Las instalaciones locales suelen ser gratuitas, las soluciones basadas en la nube pueden tener costes |
Servicio de pago, los costes dependen del uso, se adapta perfectamente a los clusters Databricks |
|
Facilidad de uso |
Familiar y ampliamente utilizado en la comunidad de la ciencia de datos |
Adaptado para el análisis de big data, puede tener una curva de aprendizaje más pronunciada para las funciones específicas de Databricks |
|
Visualización de datos |
Soporte integrado limitado para la visualización de datos |
Soporte integrado para la visualización de datos en el entorno del bloc de notas |
|
Gestión de clústeres |
Los usuarios tienen que gestionar manualmente las sesiones y dependencias de Spark |
La plataforma Databricks gestiona el clúster y lo escala automáticamente |
|
Casos prácticos |
Versátil para diversas tareas de ciencia de datos |
Especializado para el análisis colaborativo de big data dentro de la plataforma Databricks |
En última instancia, las ventajas anteriores de los cuadernos Databricks surten efecto en casos de uso específicos. Si quieres jugar con un conjunto de datos CSV con Pandas en tu portátil, Jupyter es mucho mejor.
Pero, para aplicaciones de nivel empresarial, Databricks como plataforma puede ser una opción mejor.
La ingesta de datos se refiere al proceso de importar datos de diversas fuentes. Databricks admite la ingesta desde diversas fuentes, como:
etc.
Ahora vamos a ver cómo puedes cargar determinados tipos de datos en Databricks. Empezaremos con los archivos locales:
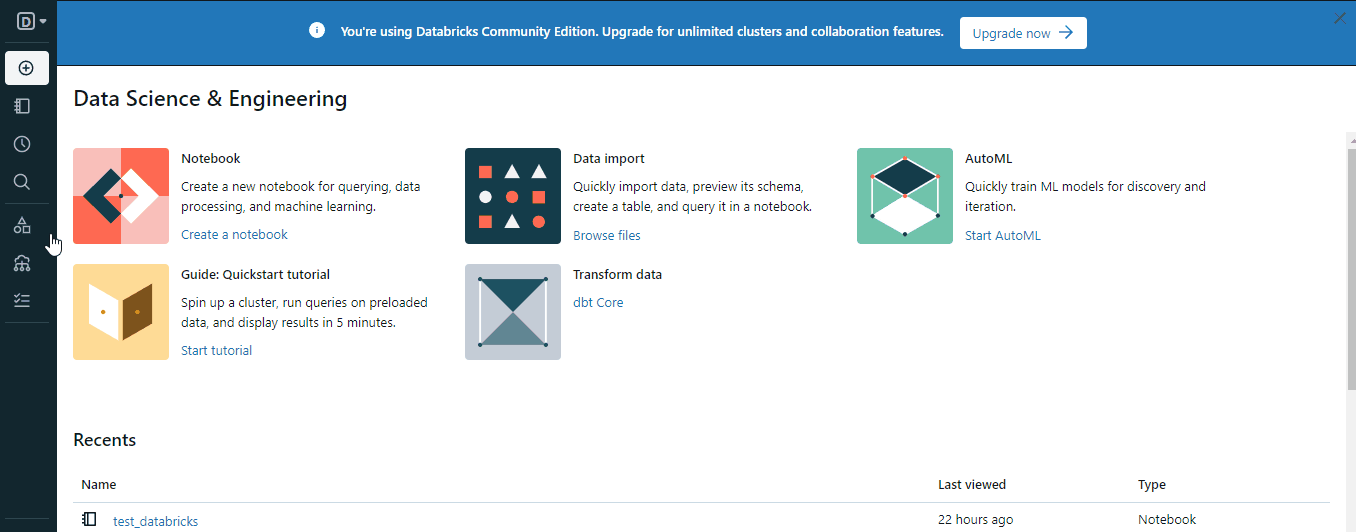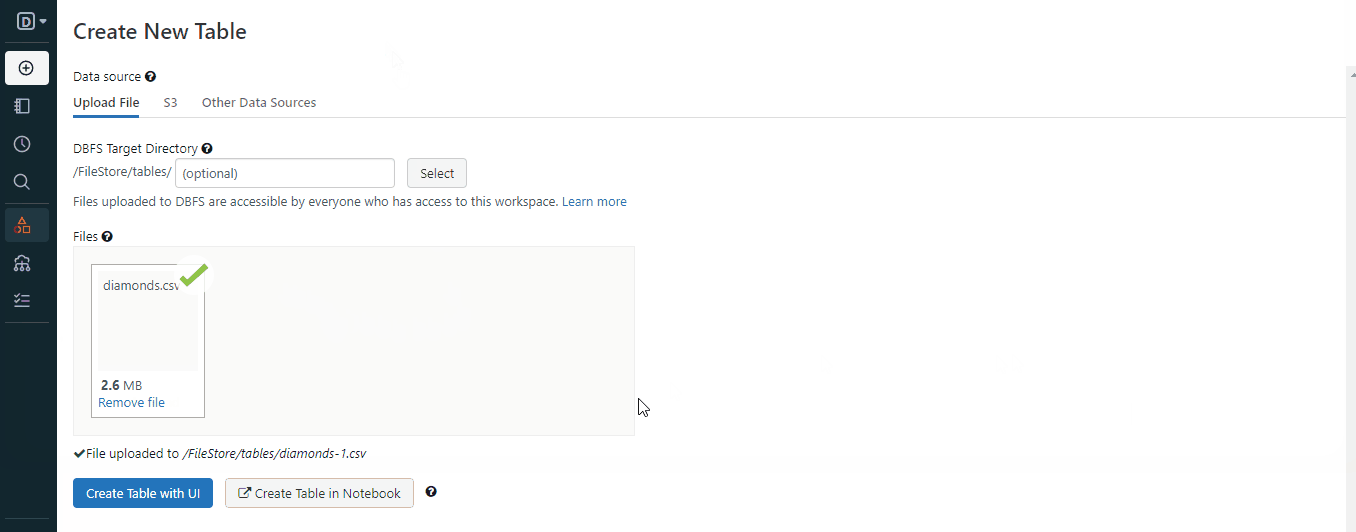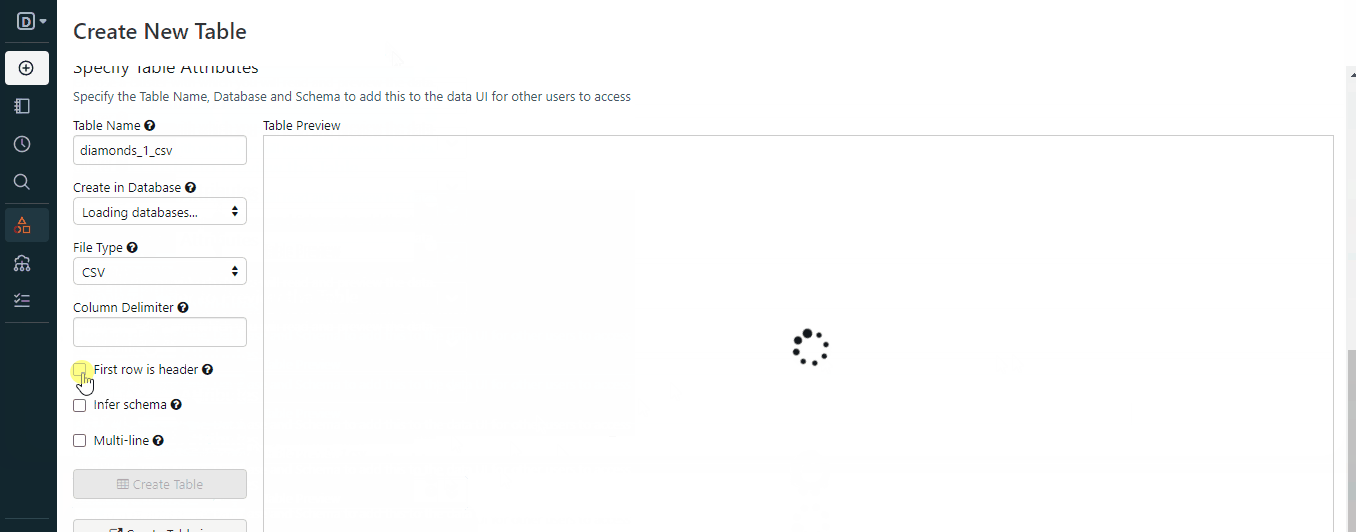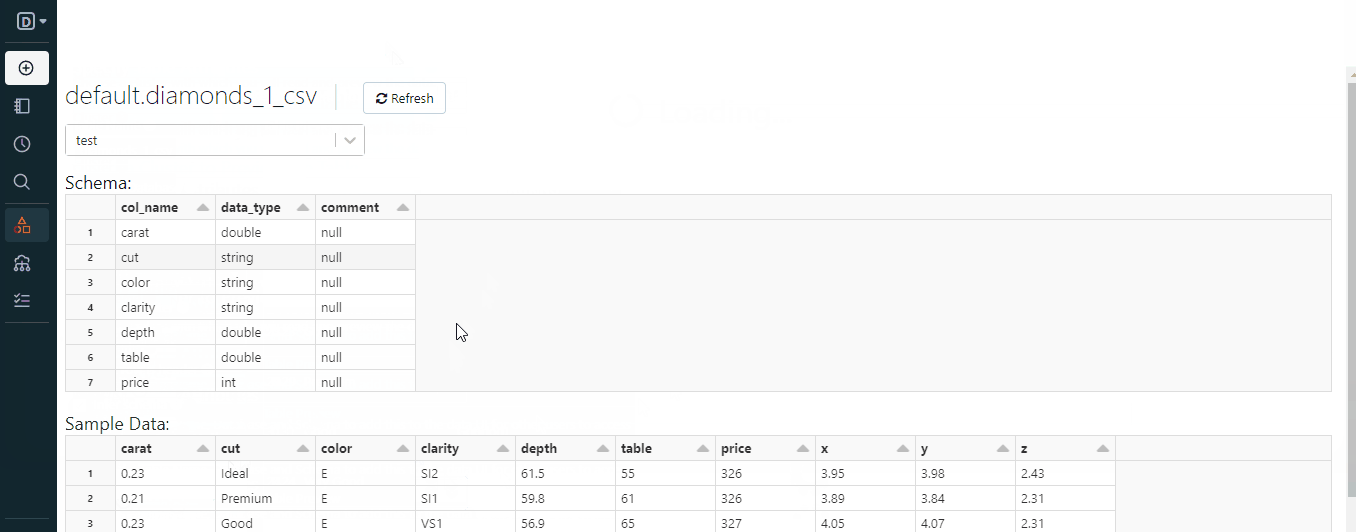
Una vez que sigas los pasos del GIF, tendrás un archivo almacenado en el espacio de trabajo. A continuación te explicamos cómo puedes cargarlo con Spark:
# Importing necessary libraries
from pyspark.sql import SparkSession
# Creating a Spark session
spark = SparkSession.builder.appName("S3ImportExample").getOrCreate()
# Defining the CSV path to the data
path = "dbfs:/FileStore/tables/diamonds.csv"
# Reading data from S3 into a DataFrame
data_from_s3 = spark.read.csv(path, header=True, inferSchema=True)
# Displaying the imported data
data_from_s3.show()
Presta atención al prefijo dbfs:. Todos los archivos del espacio de trabajo deben incluirlo para que el archivo se cargue correctamente con Spark. DBFS significa sistema de archivos databricks.
La importación de datos desde un bucket S3 es similar (para cuentas de empresa):
# Importing necessary libraries
from pyspark.sql import SparkSession
# Creating a Spark session
spark = SparkSession.builder.appName("S3ImportExample").getOrCreate()
# Defining the S3 path to the data
s3_path = "s3://your-bucket/your-data.csv"
# Reading data from S3 into a DataFrame
data_from_s3 = spark.read.csv(s3_path, header=True, inferSchema=True)
# Displaying the imported data
data_from_s3.show()
Para otros tipos de datos, puedes consultar las secciones Ingeniería de datos y Conectar con fuentes de datos de la documentación de Databricks.
Cuando subimos el archivo diamonds.csv, se convirtió en una tabla Databricks en una base de datos llamada predeterminada:
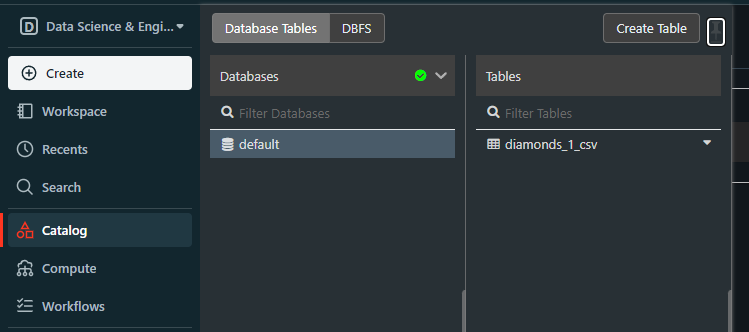
Esta base de datos default se crea siempre que intentamos cargar archivos estructurados sin crear antes la base de datos.
Si tenemos una base de datos, eso significa que podemos consultarla con SQL, no sólo con Spark. Para ello, crea una libreta nueva o cambia el idioma de la libreta actual a SQL. A continuación, prueba el siguiente fragmento de código:
SELECT * FROM default.diamonds_1_csv
LIMIT 5;
Debe devolver las cinco primeras filas de la tabla de diamantes:
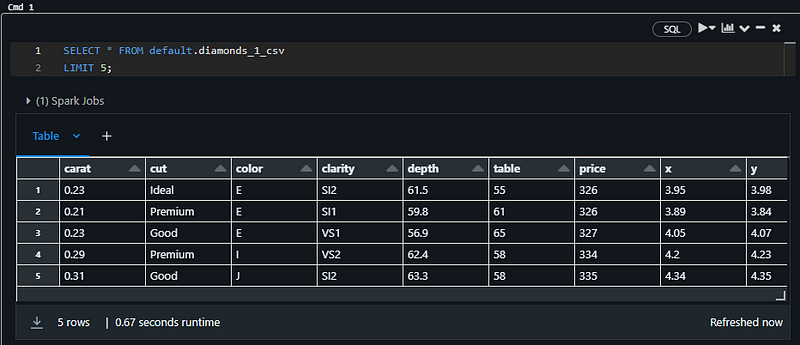
Nota: Estoy utilizando un cuaderno SQL para el fragmento anterior
También puedes cargar esta tabla en Pandas. Dentro del mismo cuaderno, pega este fragmento:
%python
# Import the necessary libraries
import pandas as pd
# Assuming 'default' is the database name and 'diamonds' is the table name
# Use the spark.sql function to query the table and retrieve the data
table_df = spark.sql("SELECT * FROM default.diamonds_1_csv")
# Convert the Spark DataFrame to a Pandas DataFrame
pandas_df = table_df.toPandas()
# Display the Pandas DataFrame
pandas_df.head()
Debe imprimir la cabecera de la tabla:
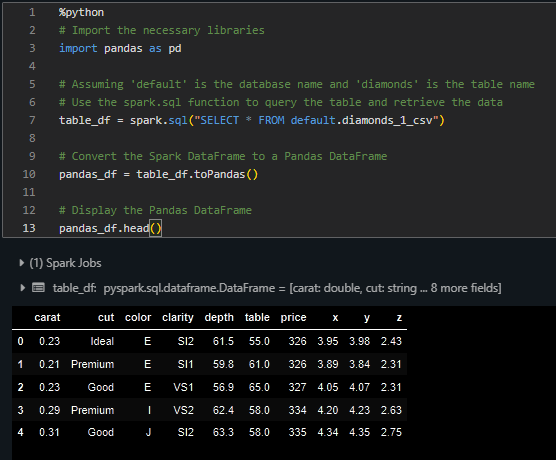
Ahora, puedes realizar cualquier tarea típica de análisis de datos en la tabla tanto con SQL como con Pandas.
Hemos conseguido aprender y hacer muchas cosas con nuestra cuenta básica de la edición comunitaria de Databricks. Para seguir conociendo la plataforma, el primer paso es utilizar la prueba gratuita de dos semanas que Databricks ofrece para las cuentas premium.
Entonces, podrás disfrutar plenamente de las lecciones del curso Introducción a Databricks ofrecido por DataCamp. Aparte de la configuración de la cuenta, aprenderás y practicarás el uso de las siguientes funciones básicas de DataCamp:
¡Comienza hoy tu viaje en Databricks!
programa
programa
Curso
blog
Gus Frazer
14 min
Tutorial
Natassha Selvaraj
Tutorial
Joleen Bothma
Tutorial
Joleen Bothma
Tutorial
DataCamp Team