Manually handling data can delay results and slow the project's progress. That’s why data engineers and analysts always search for quicker and cheaper LLMs to handle daily tasks.
Dolly is an open-source AI model by Databricks that, among other things, can help analysts, engineers, and other professionals ease their work in diverse industries. Since it’s open-source, anyone can use its training code to build better and more customized LLMs according to their requirements.
Let’s learn more about this in our Databricks Dolly tutorial.
Why Databricks Dolly?
What makes Databricks Dolly a great alternative to other tools is its approach to building custom solutions for companies of all sizes. It transforms LLMs from exclusive, high-cost technologies to versatile tools that every company can own and customize.

Source: Databricks
The Benefits of Dolly
Here’s how Dolly can help you:
- Customization: Customizes LLMs according to your organization’s needs, making it easier to manage workflows.
- Cost-efficient: Facilitates creating customized instruction-following models cheaply and efficiently.
- Agile: Empowers businesses to optimize their data workflows, automate complex processes, and generate insights more effectively.
- Accessible: Increases operational efficiency by making advanced AI more accessible and adaptable to business use cases.
- Secure: Presents a viable solution for developing AI applications without triggering data security or compliance issues commonly associated with API-reliant tools.
Want to learn more about what large language models are capable of? Take this course on LLM concepts.
Getting Started with Databricks Dolly
Now, let’s see how you can best use Dolly for your needs.
Overview of Databricks Dolly's Functionality
Dolly is fine-tuned on a specialized databricks-dolly-15k dataset to unlock functionalities similar to more massive models like GPT. That’s why you can create custom LLMs to brainstorm ideas, generate text, and perform specific tasks on command.
Setting Up Your Environment on Databricks Dolly
Follow these instructions to set up your Databricks Dolly environment for response generation.
If you have a machine with A100 GPUs, you can use this model with the transformers library.
Step 1: Run the following code in your Databricks notebook to install the transformers and accelerate libraries:
%pip install "accelerate>=0.16.0,<1" "transformers[torch]>=4.28.1,<5" "torch>=1.13.1,<2"Step 2: Next import pipeline from transformers library:
from transformers import pipeline
import torch
instruct_pipeline = pipeline(model="databricks/dolly-v2-12b", torch_dtype=torch.bfloat16, trust_remote_code=True, device_map="auto")Step 3: Then, you can generate responses from the pipeline:
instruct_pipeline("Explain to me the difference between nuclear fission and fusion.")Working with Databricks Dolly LLM
Basic operations with Dolly
Here are some of the basic operations you can perform with Dolly:
Text generation
- Writers and content creators can generate drafts, outlines, or complete writing pieces on any topic. This will save them time and effort in the writing process.
- Businesses and marketers can create engaging copy, product descriptions, or marketing campaigns.

Difference between the original model’s result and Dolly’s fine-tuned results. [Source: Databricks]
Brainstorming
- Entrepreneurs and business leaders can explore potential new products, services, or business models.
- Writers, artists, and designers can use Dolly for inspiration and exceptional ideas to incite their creative projects.
- You can even brainstorm ideas in personal settings to plan events or tackle everyday challenges.

Difference between the original model’s result and Dolly’s fine-tuned results. [Source: Databricks]
Open Q/A
- Students can ask questions and receive in-depth explanations on complex subjects.
- Professionals and researchers can ask for background information on particular topics.
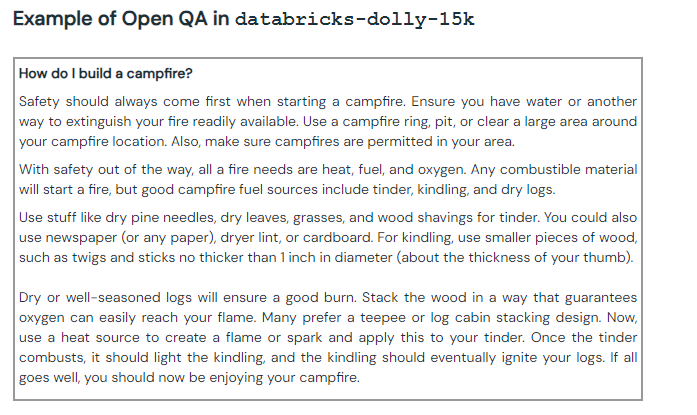
Example of an open question/answer with Dolly. [Source: Databricks]
Advanced techniques
Dolly is not limited to basic operations; you can also apply several advanced techniques to it:
Fine-tuning on custom data
You can use larger pre-trained language models as a base to fine-tune your personalized LLMs. This will improve its instruction-following capabilities and enable you to perform tasks tailored to your needs.
Curating domain-specific instruction data
To specialize your LLMs in particular industries, supplement the standard instruction data with custom prompts tailored to any desired domain (healthcare, finance, engineering, or more).
By fine-tuning specific datasets containing vocabulary, formats, and knowledge, the model can provide accurate and relevant outputs contextualized for that domain's language and conventions.
Incorporate dynamic data inputs
You can train your model to incorporate dynamic inputs like images, video, and audio data. This will allow it to go beyond understanding text and generate content that draws insights from multiple data streams simultaneously.
Building Applications with Databricks Dolly
While the original Dolly provides basic operational capabilities, you can tweak the existing model to build applications like chatbots.
Creating a chatbot
You can create a customized chatbot using databricks dolly in two parts.
Data preparation & vector database creation
To create a chatbot, you first have to set up the Databricks' vector database (Chroma) to collect and ingest data using Databricks Lakehouse, Delta Lake, and Delta Live Tables.
First, install the necessary libraries.
%pip install -U chromadb==0.3.22 langchain==0.0.164 transformers==4.29.0 accelerate==0.19.0Run the following command in your Databricks notebook.
%run ./_resources/00-init $catalog=hive_metastore $db=dbdemos_llmNow, suppose you’re building a gardening chatbot.
Note: If you want to try this demo yourself, make sure to set up db demos in the Databricks notebook.
1. Since we’re working with a sample gardening dataset from dbdemos, extract the dataset using the ‘sh’ command.
%sh
#To keep it simple, we'll download and extract the dataset using standard bash commands
#Install 7zip to extract the file
apt-get install -y p7zip-full
rm -r /tmp/gardening
mkdir -p /tmp/gardening
cd /tmp/gardening
#Download & extract the gardening archive
curl -L https://archive.org/download/stackexchange/gardening.stackexchange.com.7z -o gardening.7z
7z x gardening.7z
#Move the dataset to our main bucket
mkdir -p /dbfs/dbdemos/product/llm/gardening/raw
cp -f Posts.xml /dbfs/dbdemos/product/llm/gardening/raw2. Now, you can check the dataset information.
%fs ls /dbdemos/product/llm/gardening/raw
Cleaning and preparing Q/As:
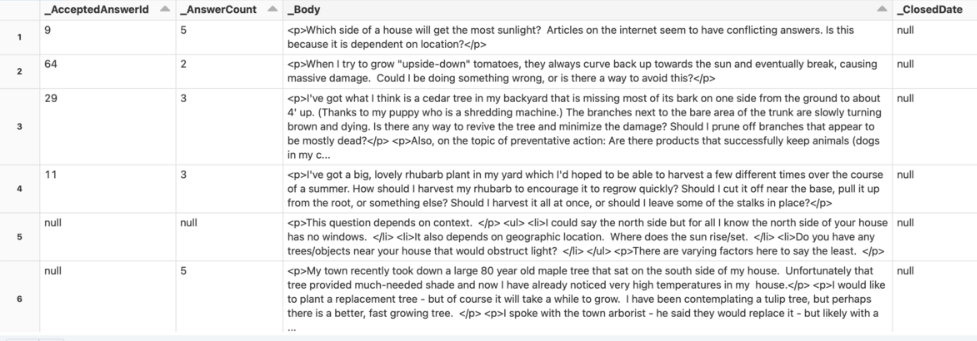
1. Review the raw dataset.
gardening_raw_path = demo_path+"/gardening/raw"
print(f"loading raw xml dataset under {gardening_raw_path}")
raw_gardening = spark.read.format("xml").option("rowTag", "row").load(f"{gardening_raw_path}/Posts.xml")
display(raw_gardening)
2. The code below converts an HTML-formatted string to text and uses BeautifulSoup to parse the HTML and extract the text.
from bs4 import BeautifulSoup
#UDF to transform html content as text
@pandas_udf("string")
def html_to_text(html):
return html.apply(lambda x: BeautifulSoup(x).get_text())
gardening_df =(raw_gardening
.filter("_Score >= 5") # keep only good answer/question
.filter(length("_Body") <= 1000) #remove too long questions
.withColumn("body", html_to_text("_Body"))
#Convert html to text
.withColumnsRenamed({"_Id": "id", "_ParentId": "parent_id"})
.select("id", "body", "parent_id"))
# Save 'raw' content for later loading of questions
gardening_df.write.mode("overwrite").saveAsTable(f"gardening_dataset")
display(spark.table("gardening_dataset"))
3. Now, pair up questions and answers.
gardening_df = spark.table("gardening_dataset")
# Self-join to assemble questions and answers
qa_df = gardening_df.alias("a").filter("parent_id IS NULL") \
.join(gardening_df.alias("b"), on=[col("a.id") == col("b.parent_id")]) \
.select("b.id", "a.body", "b.body") \
.toDF("answer_id", "question", "answer")
# Prepare the training dataset: question following with the best answers.
docs_df = qa_df.select(col("answer_id"), F.concat(col("question"), F.lit("\n\n"), col("answer"))).toDF("source", "text")
display(docs_df)
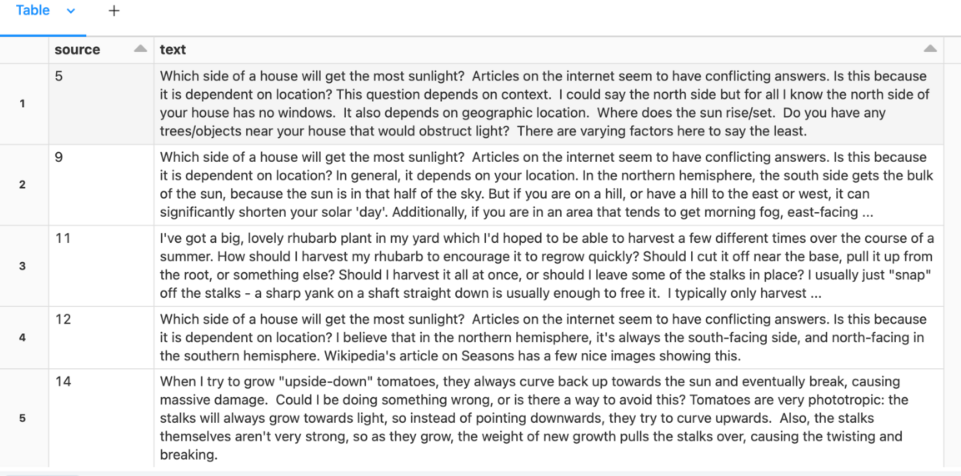
Convert documents to vector representation:
from langchain.embeddings import HuggingFaceEmbeddings
# Download model from Hugging face
hf_embed = HuggingFaceEmbeddings(model_name="sentence-transformers/all-mpnet-base-v2")Index documents in the Databricks vector database for better search:
dbutils.widgets.dropdown("reset_vector_database", "false", ["false", "true"], "Recompute embeddings for chromadb")
gardening_vector_db_path = demo_path+"/vector_db"
# Don't recompute the embeddings if they're already available
compute_embeddings = dbutils.widgets.get("reset_vector_database") == "true" or is_folder_empty(gardening_vector_db_path)
if compute_embeddings:
print(f"creating folder {gardening_vector_db_path} under our blob storage (dbfs)")
dbutils.fs.rm(gardening_vector_db_path, True)
dbutils.fs.mkdirs(gardening_vector_db_path)4. Now, create the document database by storing your dataset within vector DB.
from langchain.docstore.document import Document
from langchain.vectorstores import Chroma
# Import if you want to divide Chunk.
# from langchain.text_splitter import CharacterTextSplitter
all_texts = spark.table("gardening_training_dataset")
print(f"Saving document embeddings under /dbfs{gardening_vector_db_path}")
if compute_embeddings:
# Convert lines as langchain Documents.
# If you want to index for shorter time periods, use the text_short field instead.
documents = [Document(page_content=r["text"], metadata={"source": r["source"]}) for r in all_texts.collect()]
# Long sentences may need to be split. But it's best to summarize as above.
# text_splitter = CharacterTextSplitter(separator="\n", chunk_size=1000, chunk_overlap=100)
# documents = text_splitter.split_documents(documents)
# Initialize chromadb with sentence-transformers/all-mpnet-base-v2 model loaded from hugging face (hf_embed).
db = Chroma.from_documents(collection_name="gardening_docs", documents=documents, embedding=hf_embed, persist_directory="/dbfs"+gardening_vector_db_path)
db.similarity_search("dummy") # tickle it to persist metadata (?)
db.persist()This will save document embeddings under /dbfs/dbdemos/product/llm/vector_db
And that’s it - your Q/A dataset is ready.
However, once you’re done, restart your Python kernel to free up the memory.
Prompt engineering for questions & answers
In this step, you ask a question, and the system fetches similar content from the Q&A dataset. It then engineers a prompt containing the content and sends it to Dolly, which generates an answer to display to the customer.
Here’s how you can do it:
- Download 2 embeddings from hugging face:
# Start here to load a previously-saved DB
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.vectorstores import Chroma
if len(get_available_gpus()) == 0:
Exception("Running dolly without GPU will be slow. We recommend you switch to a Single Node cluster with at least 1 GPU to properly run this demo.")
gardening_vector_db_path = "/dbfs"+demo_path+"/vector_db"
hf_embed = HuggingFaceEmbeddings(model_name="sentence-transformers/all-mpnet-base-v2")
db = Chroma(collection_name="gardening_docs", embedding_function=hf_embed, persist_directory=gardening_vector_db_path)2. Now, perform a similarity check between questions.
def get_similar_docs(question, similar_doc_count):
return db.similarity_search(question, k=similar_doc_count)
# Let's test it with blackberries:
for doc in get_similar_docs("how to grow blackberry?", 2):
print(doc.page_content)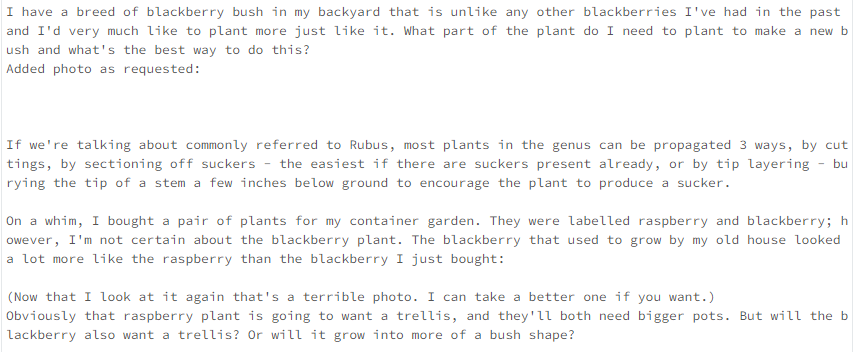
3. Use a language model and prompt it to build a system that answers questions using LangChain.
from transformers import AutoTokenizer, AutoModelForCausalLM, pipeline
import torch
from langchain import PromptTemplate
from langchain.llms import HuggingFacePipeline
from langchain.chains.question_answering import load_qa_chain
def build_qa_chain():
torch.cuda.empty_cache()
model_name = "databricks/dolly-v2-7b" # can use dolly-v2-3b or dolly-v2-7b for smaller models and faster inferences.
# Increase max_new_tokens for a longer response
# Other settings might give better results! Play around
instruct_pipeline = pipeline(model=model_name, torch_dtype=torch.bfloat16, trust_remote_code=True, device_map="auto",
return_full_text=True, max_new_tokens=256, top_p=0.95, top_k=50)
# Note: if you use dolly 12B or smaller model but a GPU with less than 24GB RAM, use 8bit. This requires %pip install bitsandbytes
# Defining our prompt content.
# langchain will load our similar documents as {context}
template = """Below is an instruction that describes a task. Write a response that appropriately completes the request.
Instruction:
You are a gardener and your job is to help provide the best gardening answer.
Use only information in the following paragraphs to answer the question at the end. Explain the answer with reference to these paragraphs. If you don't know, say that you do not know.
{context}
Question: {question}
Response:
"""
prompt = PromptTemplate(input_variables=['context', 'question'], template=template)
hf_pipe = HuggingFacePipeline(pipeline=instruct_pipeline)
# Set verbose=True to see the full prompt:
return load_qa_chain(llm=hf_pipe, chain_type="stuff", prompt=prompt, verbose=True)# Building the chain will load Dolly and can take several minutes depending on the model size
qa_chain = build_qa_chain()The key settings impacting performance are:
- ‘Max_new_tokens’ : Reduce for speedier, more concise outputs.
- ‘Num_beams’ : With beam search, more beams increase runtime roughly linearly.
4. That’s it. Now, you can define the function for simple question answering.
def answer_question(question):
similar_docs = get_similar_docs(question, similar_doc_count=2)
result = qa_chain({"input_documents": similar_docs, "question": question})
result_html = f"<p><blockquote style=\"font-size:24\">{question}</blockquote></p>"
result_html += f"<p><blockquote style=\"font-size:18px\">{result['output_text']}</blockquote></p>"
result_html += "<p><hr/></p>"
for d in result["input_documents"]:
source_id = d.metadata["source"]
result_html += f"<p><blockquote>{d.page_content}<br/>(Source: <a href=\"https://gardening.stackexchange.com/a/{source_id}\">{source_id}</a>)</blockquote></p>"
displayHTML(result_html)You can now ask it a question related to gardening.
answer_question("What is the best kind of soil to grow blueberries in?")

Check dbdemo for building a chatbot here.
Real-world Use Cases
With its advanced NLP capabilities, customized LLMs made with Dolly can be used in many real-world cases, and here are some of the most common examples:
1. Automated data summarization for financial analysts
Dolly can process large datasets and generate concise summaries to help analysts grasp key insights faster.
For example, a finance researcher might need to quickly understand historical stock price trends. Dolly could analyze the data and provide a clear overview, saving the researcher valuable time.
2. Data cleaning and preprocessing in retail industries
At retail companies, data analysts work with massive datasets containing transaction records from thousands of stores nationwide. However, the raw data from individual stores often contains inconsistencies, missing values, duplicate entries, and other errors.
Dolly can identify inconsistencies, missing values, and potential errors in the data so data scientists can use clean data to extract meaningful insights and create visualizations.
3. Staying current with the latest research in pharmaceutical industries
At pharmaceutical companies, scientists stay current with the latest published research across multiple disciplines. However, manually reviewing hundreds of new research papers each week consumes time.
Instead, they can use Databricks Dolly LLM to analyze research papers and extract key elements like objectives, methods, results, and conclusions. It can combine multi-page summaries and highlight the most salient insights from each paper.
Challenges and Limitations
Like any other pioneering LLM technology, Dolly has some limitations and challenges. So, here are three main flaws of Dolly:
- Hallucinate or generate factually incorrect responses since it’s trained on a much smaller dataset than ChatGPT.
- It is difficult to fine-tune and customize it for your needs as it requires a certain level of machine learning and NLP expertise.
- Struggles with solving mathematical questions, programming problems, and adding a sense of humor in responses.
Mitigating Shortcomings of Dolly LLM
While no confirmed techniques exist to mitigate Dolly's current limitations, Databricks is continuously researching and aims to find ways to improve its existing AI models. Dolly is one such example currently in version 2, but we may see further improvements in the coming years.
Conclusion and Next Steps
Databricks Dolly is an open-source AI model that’s available for commercial use. You can use its training code and datasets to create specific LLMs that meet your needs.
If you’re ready to go beyond this Databricks Dolly tutorial and polish your existing skills, start with the following resources:
- Developing large language models
- Introduction to Databricks
- Webinar: Getting Started with Databricks
Happy Learning!




