O manuseio manual dos dados pode atrasar os resultados e retardar o andamento do projeto. É por isso que os engenheiros e analistas de dados sempre buscam LLMs mais rápidos e baratos para lidar com as tarefas diárias.
Dolly é um modelo de IA de código aberto da Databricks que, entre outras coisas, pode ajudar analistas, engenheiros e outros profissionais a facilitar seu trabalho em diversos setores. Como é de código aberto, qualquer pessoa pode usar seu código de treinamento para criar LLMs melhores e mais personalizados de acordo com suas necessidades.
Vamos aprender mais sobre isso em nosso tutorial do Databricks Dolly.
Por que a Databricks Dolly?
O que torna a Databricks Dolly uma excelente alternativa a outras ferramentas é sua abordagem para criar soluções personalizadas para empresas de todos os tamanhos. Ele transforma os LLMs de tecnologias exclusivas e de alto custo em ferramentas versáteis que todas as empresas podem possuir e personalizar.

Fonte: Telas de dados
Os benefícios da Dolly
Veja como a Dolly pode ajudar você:
- Personalização: Personaliza os LLMs de acordo com as necessidades de sua organização, facilitando o gerenciamento dos fluxos de trabalho.
- Custo-benefício: Facilita a criação de modelos personalizados de acompanhamento de instruções de forma econômica e eficiente.
- Ágil: Permite que as empresas otimizem seus fluxos de trabalho de dados, automatizem processos complexos e gerem insights com mais eficiência.
- Acessível: Aumenta a eficiência operacional, tornando a IA avançada mais acessível e adaptável aos casos de uso comercial.
- Seguro: Apresenta uma solução viável para o desenvolvimento de aplicativos de IA sem desencadear problemas de segurança de dados ou de conformidade comumente associados a ferramentas dependentes de API.
Você quer saber mais sobre o que os modelos de linguagem grandes são capazes de fazer? Faça este curso sobre os conceitos do LLM.
Primeiros passos com o Databricks Dolly
Agora, vamos ver como você pode usar o Dolly da melhor maneira possível para suas necessidades.
Visão geral da funcionalidade do Databricks Dolly
O Dolly é ajustado em um conjunto de dados especializado databricks-dolly-15k para desbloquear funcionalidades semelhantes a modelos mais massivos, como o GPT. É por isso que você pode criar LLMs personalizados para fazer brainstorming de ideias, gerar texto e executar tarefas específicas sob comando.
Configurando seu ambiente no Databricks Dolly
Siga estas instruções para configurar o ambiente do Databricks Dolly para a geração de respostas.
Se você tiver uma máquina com GPUs A100, poderá usar esse modelo com a biblioteca de transformadores.
Etapa 1: Execute o código a seguir em seu notebook Databricks para instalar as bibliotecas transformers e accelerate:
%pip install "accelerate>=0.16.0,<1" "transformers[torch]>=4.28.1,<5" "torch>=1.13.1,<2"Etapa 2: Em seguida, importe o pipeline da biblioteca de transformadores:
from transformers import pipeline
import torch
instruct_pipeline = pipeline(model="databricks/dolly-v2-12b", torch_dtype=torch.bfloat16, trust_remote_code=True, device_map="auto")Etapa 3: Em seguida, você pode gerar respostas a partir do pipeline:
instruct_pipeline("Explain to me the difference between nuclear fission and fusion.")Trabalhando com o Databricks Dolly LLM
Operações básicas com o Dolly
Aqui estão algumas das operações básicas que você pode realizar com o Dolly:
Geração de texto
- Escritores e criadores de conteúdo podem gerar rascunhos, esboços ou textos completos sobre qualquer assunto. Isso lhes poupará tempo e esforço no processo de redação.
- As empresas e os profissionais de marketing podem criar textos envolventes, descrições de produtos ou campanhas de marketing.

Diferença entre o resultado do modelo original e os resultados ajustados da Dolly. [Fonte: Databricks].
Brainstorming
- Empreendedores e líderes empresariais podem explorar possíveis novos produtos, serviços ou modelos de negócios.
- Escritores, artistas e designers podem usar a Dolly para obter inspiração e ideias excepcionais para estimular seus projetos criativos.
- Você pode até mesmo fazer um brainstorming de ideias em ambientes pessoais para planejar eventos ou enfrentar desafios diários.

Diferença entre o resultado do modelo original e os resultados ajustados da Dolly. [Fonte: Databricks].
Perguntas e respostas abertas
- Os alunos podem fazer perguntas e receber explicações detalhadas sobre assuntos complexos.
- Profissionais e pesquisadores podem solicitar informações básicas sobre tópicos específicos.
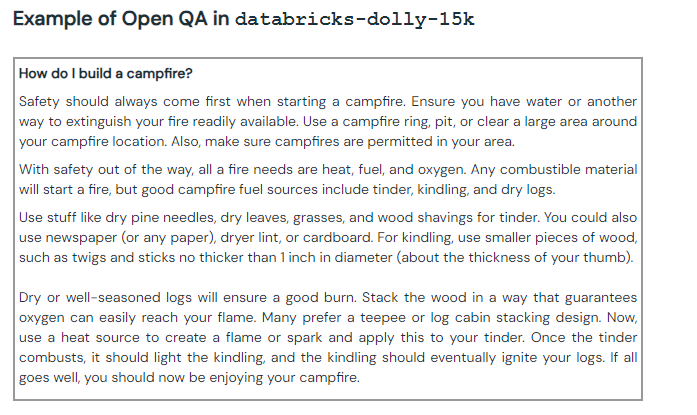
Exemplo de uma pergunta/resposta aberta com Dolly. [Fonte: Databricks].
Técnicas avançadas
O Dolly não se limita a operações básicas; você também pode aplicar várias técnicas avançadas a ele:
Ajuste fino em dados personalizados
Você pode usar modelos de linguagem pré-treinados maiores como base para ajustar seus LLMs personalizados. Isso melhorará os recursos de acompanhamento de instruções e permitirá que você execute tarefas adaptadas às suas necessidades.
Curadoria de dados de instrução específicos do domínio
Para especializar seus LLMs em setores específicos, complemente os dados de instrução padrão com prompts personalizados adaptados a qualquer domínio desejado (saúde, finanças, engenharia ou outros).
Ao fazer o ajuste fino de conjuntos de dados específicos que contêm vocabulário, formatos e conhecimento, o modelo pode fornecer resultados precisos e relevantes contextualizados para a linguagem e as convenções desse domínio.
Incorporar entradas de dados dinâmicos
Você pode treinar seu modelo para incorporar entradas dinâmicas, como imagens, vídeo e dados de áudio. Isso permitirá que ele vá além da compreensão de texto e gere conteúdo que extraia insights de vários fluxos de dados simultaneamente.
Criando aplicativos com o Databricks Dolly
Embora o Dolly original ofereça recursos operacionais básicos, você pode ajustar o modelo existente para criar aplicativos como chatbots.
Criando um chatbot
Você pode criar um chatbot personalizado usando o databricks dolly em duas partes.
Preparação de dados e criação de banco de dados vetorial
Para criar um chatbot, primeiro você precisa configurar o banco de dados vetorial da Databricks (Chroma) para coletar e ingerir dados usando as tabelas Databricks Lakehouse, Delta Lake e Delta Live.
Primeiro, instale as bibliotecas necessárias.
%pip install -U chromadb==0.3.22 langchain==0.0.164 transformers==4.29.0 accelerate==0.19.0Execute o seguinte comando no notebook do Databricks.
%run ./_resources/00-init $catalog=hive_metastore $db=dbdemos_llmAgora, suponha que você esteja criando um chatbot de jardinagem.
Observação: Se você quiser experimentar essa demonstração por conta própria, certifique-se de configurar db demos no notebook do Databricks.
1. Como estamos trabalhando com um conjunto de dados de jardinagem de amostra do dbdemos, extraia o conjunto de dados usando o comando "sh".
%sh
#To keep it simple, we'll download and extract the dataset using standard bash commands
#Install 7zip to extract the file
apt-get install -y p7zip-full
rm -r /tmp/gardening
mkdir -p /tmp/gardening
cd /tmp/gardening
#Download & extract the gardening archive
curl -L https://archive.org/download/stackexchange/gardening.stackexchange.com.7z -o gardening.7z
7z x gardening.7z
#Move the dataset to our main bucket
mkdir -p /dbfs/dbdemos/product/llm/gardening/raw
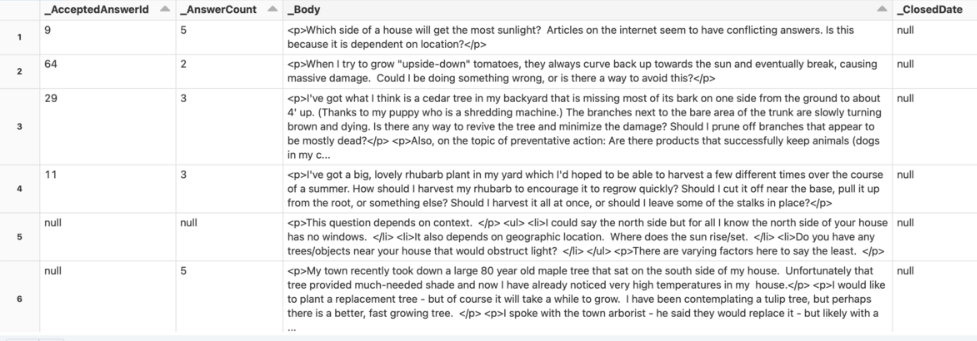
cp -f Posts.xml /dbfs/dbdemos/product/llm/gardening/raw2. Agora, você pode verificar as informações do conjunto de dados.
%fs ls /dbdemos/product/llm/gardening/raw
Limpeza e preparação de Q/As:
1. Analise o conjunto de dados brutos.
gardening_raw_path = demo_path+"/gardening/raw"
print(f"loading raw xml dataset under {gardening_raw_path}")
raw_gardening = spark.read.format("xml").option("rowTag", "row").load(f"{gardening_raw_path}/Posts.xml")
display(raw_gardening)
2. O código abaixo converte uma cadeia de caracteres formatada em HTML em texto e usa o BeautifulSoup para analisar o HTML e extrair o texto.
from bs4 import BeautifulSoup
#UDF to transform html content as text
@pandas_udf("string")
def html_to_text(html):
return html.apply(lambda x: BeautifulSoup(x).get_text())
gardening_df =(raw_gardening
.filter("_Score >= 5") # keep only good answer/question
.filter(length("_Body") <= 1000) #remove too long questions
.withColumn("body", html_to_text("_Body"))
#Convert html to text
.withColumnsRenamed({"_Id": "id", "_ParentId": "parent_id"})
.select("id", "body", "parent_id"))
# Save 'raw' content for later loading of questions
gardening_df.write.mode("overwrite").saveAsTable(f"gardening_dataset")
display(spark.table("gardening_dataset"))
3. Agora, junte as perguntas e as respostas.
gardening_df = spark.table("gardening_dataset")
# Self-join to assemble questions and answers
qa_df = gardening_df.alias("a").filter("parent_id IS NULL") \
.join(gardening_df.alias("b"), on=[col("a.id") == col("b.parent_id")]) \
.select("b.id", "a.body", "b.body") \
.toDF("answer_id", "question", "answer")
# Prepare the training dataset: question following with the best answers.
docs_df = qa_df.select(col("answer_id"), F.concat(col("question"), F.lit("\n\n"), col("answer"))).toDF("source", "text")
display(docs_df)
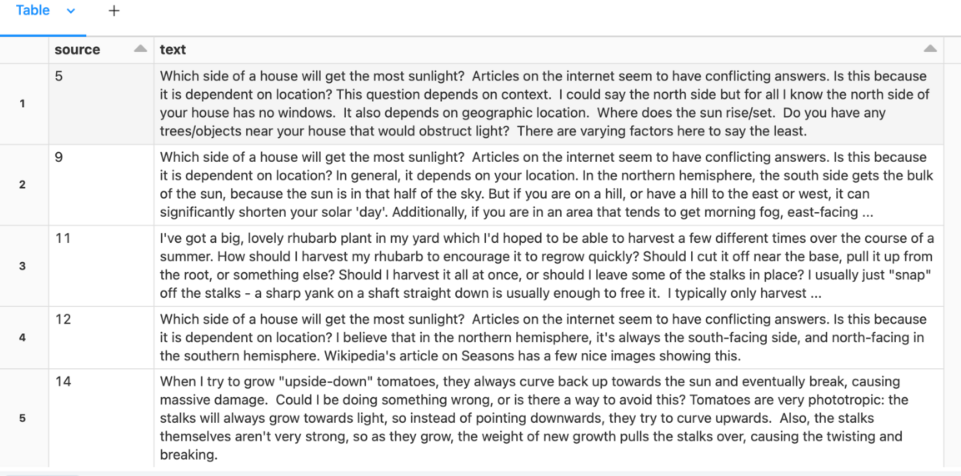
Converta documentos em representação vetorial:
from langchain.embeddings import HuggingFaceEmbeddings
# Download model from Hugging face
hf_embed = HuggingFaceEmbeddings(model_name="sentence-transformers/all-mpnet-base-v2")Indexar documentos no banco de dados vetorial da Databricks para melhorar a pesquisa:
dbutils.widgets.dropdown("reset_vector_database", "false", ["false", "true"], "Recompute embeddings for chromadb")
gardening_vector_db_path = demo_path+"/vector_db"
# Don't recompute the embeddings if they're already available
compute_embeddings = dbutils.widgets.get("reset_vector_database") == "true" or is_folder_empty(gardening_vector_db_path)
if compute_embeddings:
print(f"creating folder {gardening_vector_db_path} under our blob storage (dbfs)")
dbutils.fs.rm(gardening_vector_db_path, True)
dbutils.fs.mkdirs(gardening_vector_db_path)4. Agora, crie o banco de dados de documentos armazenando seu conjunto de dados no vetor DB.
from langchain.docstore.document import Document
from langchain.vectorstores import Chroma
# Import if you want to divide Chunk.
# from langchain.text_splitter import CharacterTextSplitter
all_texts = spark.table("gardening_training_dataset")
print(f"Saving document embeddings under /dbfs{gardening_vector_db_path}")
if compute_embeddings:
# Convert lines as langchain Documents.
# If you want to index for shorter time periods, use the text_short field instead.
documents = [Document(page_content=r["text"], metadata={"source": r["source"]}) for r in all_texts.collect()]
# Long sentences may need to be split. But it's best to summarize as above.
# text_splitter = CharacterTextSplitter(separator="\n", chunk_size=1000, chunk_overlap=100)
# documents = text_splitter.split_documents(documents)
# Initialize chromadb with sentence-transformers/all-mpnet-base-v2 model loaded from hugging face (hf_embed).
db = Chroma.from_documents(collection_name="gardening_docs", documents=documents, embedding=hf_embed, persist_directory="/dbfs"+gardening_vector_db_path)
db.similarity_search("dummy") # tickle it to persist metadata (?)
db.persist()Isso salvará as incorporações de documentos em /dbfs/dbdemos/product/llm/vector_db
E é isso, seu conjunto de dados de Q/A está pronto.
No entanto, quando você terminar, reinicie o kernel do Python para liberar a memória.
Engenharia imediata para perguntas e respostas
Nessa etapa, você faz uma pergunta e o sistema busca conteúdo semelhante no conjunto de dados de perguntas e respostas. Em seguida, ele cria um prompt com o conteúdo e o envia para a Dolly, que gera uma resposta para ser exibida ao cliente.
Veja como você pode fazer isso:
- Faça o download de 2 embeddings de hugging face:
# Start here to load a previously-saved DB
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.vectorstores import Chroma
if len(get_available_gpus()) == 0:
Exception("Running dolly without GPU will be slow. We recommend you switch to a Single Node cluster with at least 1 GPU to properly run this demo.")
gardening_vector_db_path = "/dbfs"+demo_path+"/vector_db"
hf_embed = HuggingFaceEmbeddings(model_name="sentence-transformers/all-mpnet-base-v2")
db = Chroma(collection_name="gardening_docs", embedding_function=hf_embed, persist_directory=gardening_vector_db_path)2. Agora, faça uma verificação de similaridade entre as perguntas.
def get_similar_docs(question, similar_doc_count):
return db.similarity_search(question, k=similar_doc_count)
# Let's test it with blackberries:
for doc in get_similar_docs("how to grow blackberry?", 2):
print(doc.page_content)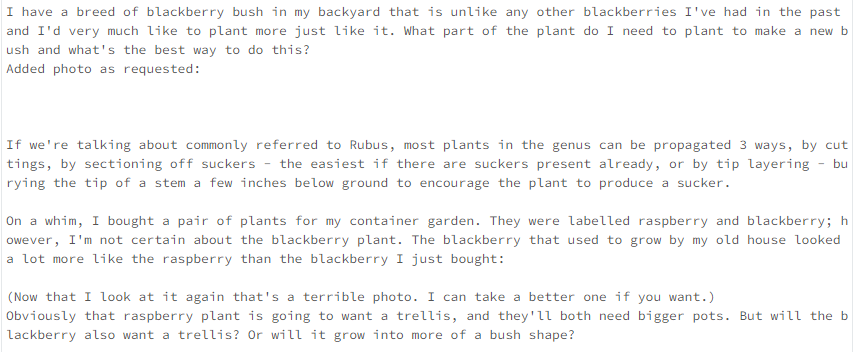
3. Use um modelo de linguagem e peça a ele que crie um sistema que responda a perguntas usando o LangChain.
from transformers import AutoTokenizer, AutoModelForCausalLM, pipeline
import torch
from langchain import PromptTemplate
from langchain.llms import HuggingFacePipeline
from langchain.chains.question_answering import load_qa_chain
def build_qa_chain():
torch.cuda.empty_cache()
model_name = "databricks/dolly-v2-7b" # can use dolly-v2-3b or dolly-v2-7b for smaller models and faster inferences.
# Increase max_new_tokens for a longer response
# Other settings might give better results! Play around
instruct_pipeline = pipeline(model=model_name, torch_dtype=torch.bfloat16, trust_remote_code=True, device_map="auto",
return_full_text=True, max_new_tokens=256, top_p=0.95, top_k=50)
# Note: if you use dolly 12B or smaller model but a GPU with less than 24GB RAM, use 8bit. This requires %pip install bitsandbytes
# Defining our prompt content.
# langchain will load our similar documents as {context}
template = """Below is an instruction that describes a task. Write a response that appropriately completes the request.
Instruction:
You are a gardener and your job is to help provide the best gardening answer.
Use only information in the following paragraphs to answer the question at the end. Explain the answer with reference to these paragraphs. If you don't know, say that you do not know.
{context}
Question: {question}
Response:
"""
prompt = PromptTemplate(input_variables=['context', 'question'], template=template)
hf_pipe = HuggingFacePipeline(pipeline=instruct_pipeline)
# Set verbose=True to see the full prompt:
return load_qa_chain(llm=hf_pipe, chain_type="stuff", prompt=prompt, verbose=True)# Building the chain will load Dolly and can take several minutes depending on the model size
qa_chain = build_qa_chain()As principais configurações que afetam o desempenho são:
- ‘Max_new_tokens’ : Reduza para obter resultados mais rápidos e concisos.
- ‘Num_beams’ : Com a pesquisa de feixes, mais feixes aumentam o tempo de execução de forma aproximadamente linear.
4. É isso aí. Agora, você pode definir a função para responder a perguntas simples.
def answer_question(question):
similar_docs = get_similar_docs(question, similar_doc_count=2)
result = qa_chain({"input_documents": similar_docs, "question": question})
result_html = f"<p><blockquote style=\"font-size:24\">{question}</blockquote></p>"
result_html += f"<p><blockquote style=\"font-size:18px\">{result['output_text']}</blockquote></p>"
result_html += "<p><hr/></p>"
for d in result["input_documents"]:
source_id = d.metadata["source"]
result_html += f"<p><blockquote>{d.page_content}<br/>(Source: <a href=\"https://gardening.stackexchange.com/a/{source_id}\">{source_id}</a>)</blockquote></p>"
displayHTML(result_html)Agora você pode fazer uma pergunta relacionada à jardinagem.
answer_question("What is the best kind of soil to grow blueberries in?")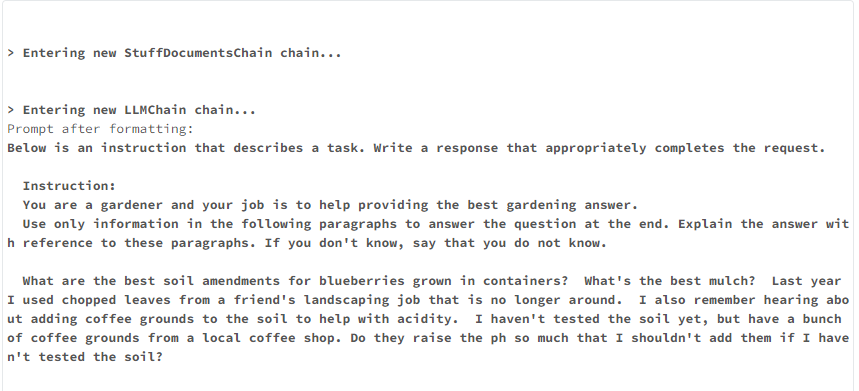

Consulte o dbdemo para criar um chatbot aqui.
Casos de uso no mundo real
Com seus recursos avançados de NLP, os LLMs personalizados feitos com a Dolly podem ser usados em muitos casos do mundo real, e aqui estão alguns dos exemplos mais comuns:
1. Resumo automatizado de dados para analistas financeiros
A Dolly pode processar grandes conjuntos de dados e gerar resumos concisos para ajudar os analistas a entender os principais insights mais rapidamente.
Por exemplo, um pesquisador financeiro pode precisar entender rapidamente as tendências históricas dos preços das ações. A Dolly poderia analisar os dados e fornecer uma visão geral clara, economizando o valioso tempo do pesquisador.
2. Limpeza e pré-processamento de dados nos setores de varejo
Nas empresas de varejo, os analistas de dados trabalham com enormes conjuntos de dados contendo registros de transações de milhares de lojas em todo o país. No entanto, os dados brutos de lojas individuais geralmente contêm inconsistências, valores ausentes, entradas duplicadas e outros erros.
A Dolly pode identificar inconsistências, valores ausentes e possíveis erros nos dados para que os cientistas de dados possam usar dados limpos para extrair insights significativos e criar visualizações.
3. Manter-se atualizado com as pesquisas mais recentes do setor farmacêutico
Nas empresas farmacêuticas, os cientistas se mantêm atualizados com as últimas pesquisas publicadas em várias disciplinas. No entanto, a revisão manual de centenas de novos artigos de pesquisa a cada semana consome tempo.
Em vez disso, eles podem usar o Databricks Dolly LLM para analisar documentos de pesquisa e extrair elementos-chave como objetivos, métodos, resultados e conclusões. Ele pode combinar resumos de várias páginas e destacar os insights mais importantes de cada documento.
Desafios e limitações
Como qualquer outra tecnologia pioneira de LLM, o Dolly tem algumas limitações e desafios. Portanto, aqui estão as três principais falhas da Dolly:
- Alucinar ou gerar respostas factualmente incorretas, pois é treinado em um conjunto de dados muito menor do que o ChatGPT.
- É difícil ajustá-lo e personalizá-lo de acordo com suas necessidades, pois requer um certo nível de machine learning e conhecimento de PNL.
- Tem dificuldades para resolver questões matemáticas, problemas de programação e adicionar senso de humor às respostas.
Mitigando as deficiências do Dolly LLM
Embora não existam técnicas confirmadas para atenuar as limitações atuais da Dolly, a Databricks está pesquisando continuamente e tem como objetivo encontrar maneiras de melhorar seus modelos de IA existentes. A Dolly é um exemplo disso, atualmente na versão 2, mas podemos ver mais aprimoramentos nos próximos anos.
Conclusão e próximas etapas
O Databricks Dolly é um modelo de IA de código aberto que está disponível para uso comercial. Você pode usar seu código de treinamento e conjuntos de dados para criar LLMs específicos que atendam às suas necessidades.
Se você estiver pronto para ir além deste tutorial do Databricks Dolly e aperfeiçoar suas habilidades atuais, comece com os seguintes recursos:
- Desenvolvimento de grandes modelos de linguagem
- Introdução ao Databricks
- Webinar: Primeiros passos com o Databricks
Feliz aprendizado!


