Curso
Diseño de sistemas agénticos con LangChain
3 h
12.1K
¡Bienvenido de nuevo! Al final del segundo tutorialya teníamos una zona de juegos fp-ts en tonos pastel, un backend NestJS + PostgreSQL y un seguimiento anónimo del progreso mediante UUID.
Puedes acceder a todos los tutoriales de la serie Devin aquí:
Lo que hemos hecho hasta ahora es estupendo para hackear en solitario, pero es hora de ver lo bien que se integra Devin en los flujos de trabajo en equipo. En este tercer tutorial, veremos:
Todavía no hay despliegues auth ni prod, ¡eso ocurrirá en la Parte 4!
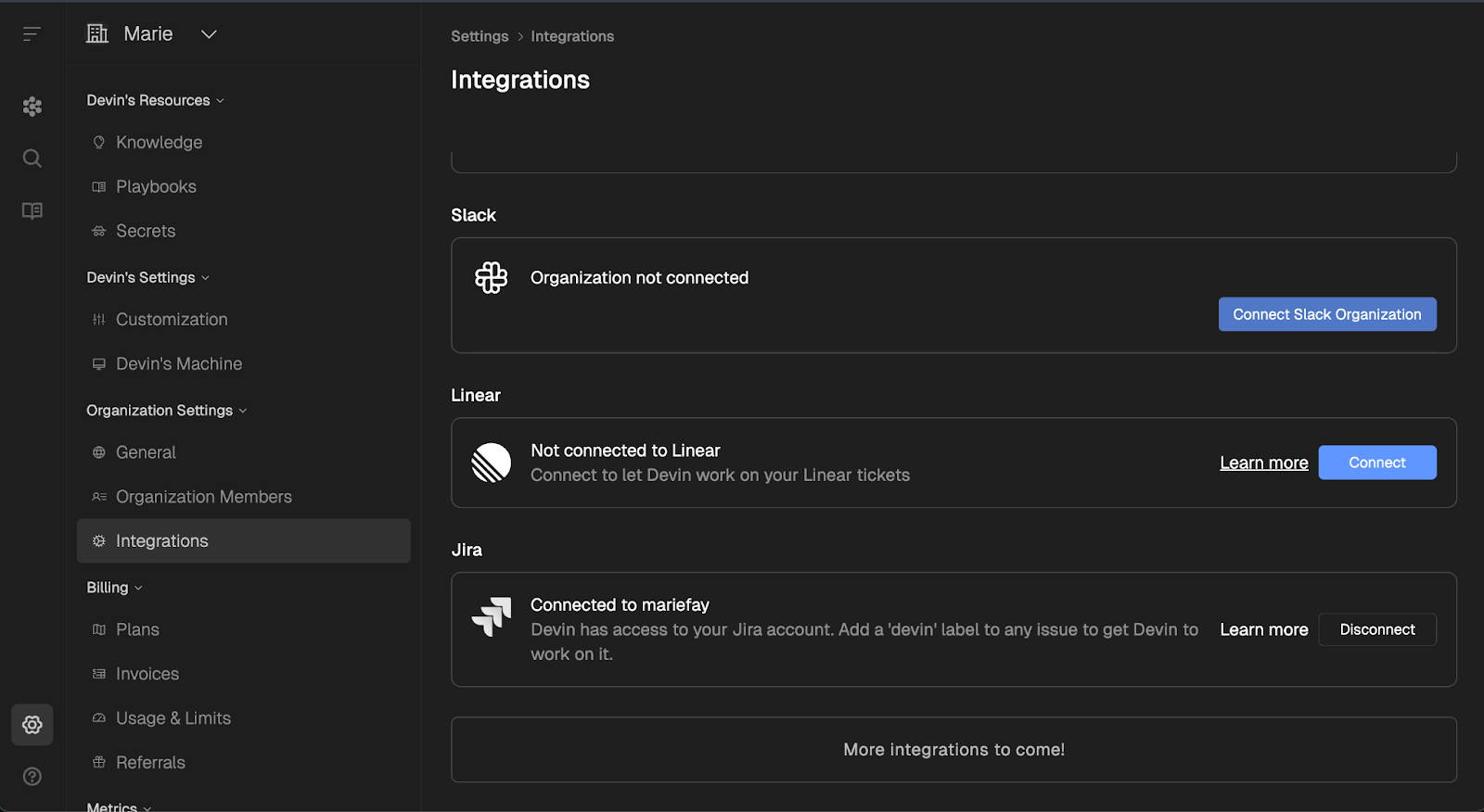
Enganchar Devin a tu flujo de comunicaciones y tickets es totalmente manual y se hace a través de la interfaz de Devin.
Puedes conectarte a Slack desde la pestaña de integración de los ajustes de Devin, o instalar la app "Devin AI" desde el Directorio de Apps de Slack.
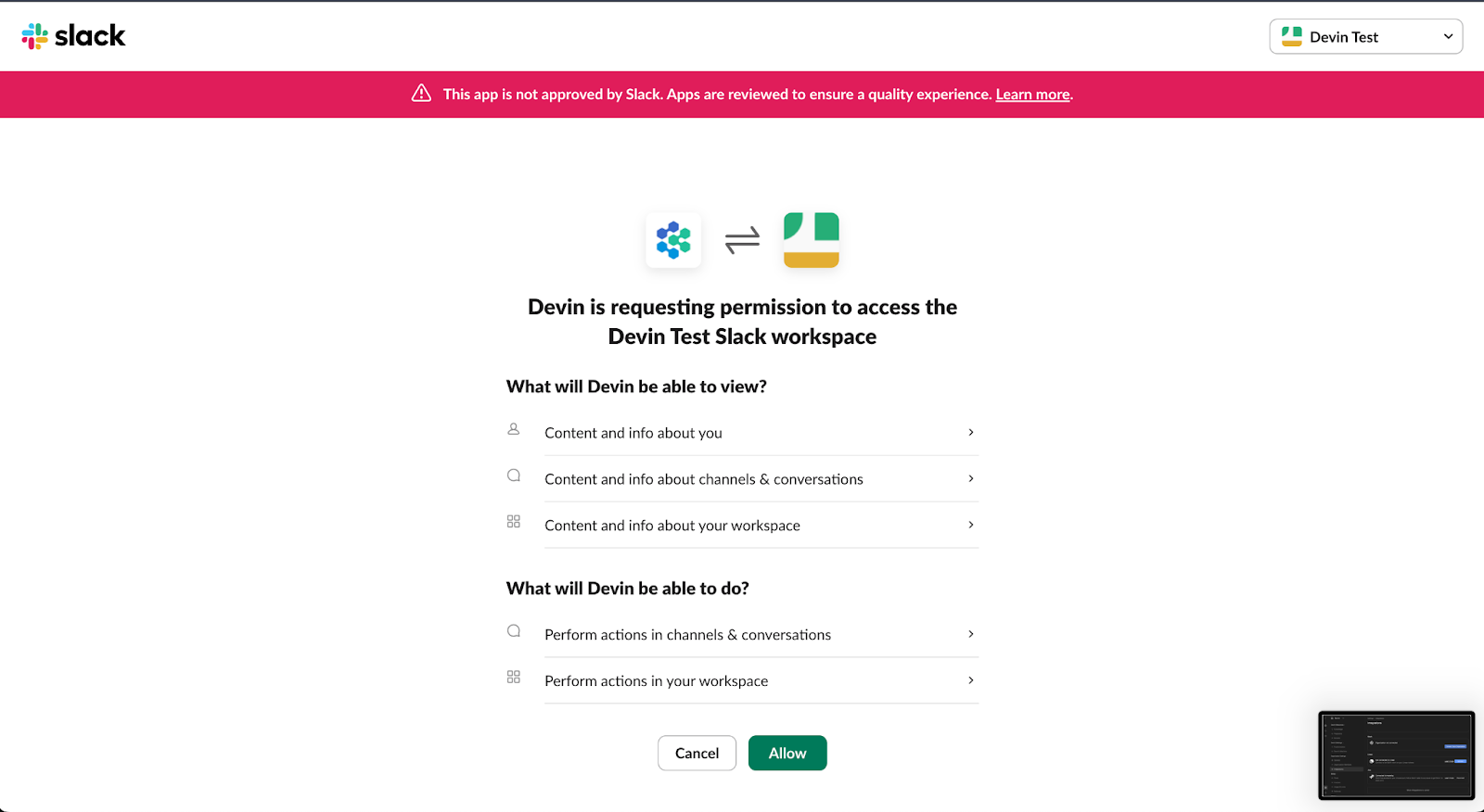
La aplicación sigue mostrando "No aprobado por Slack" en el diálogo OAuth. Cognition dice que su revisión de seguridad está pendiente, y que la funcionalidad no se ve afectada.
Luego elige un canal:

Puedes chatear con Devin con sólo una mención:
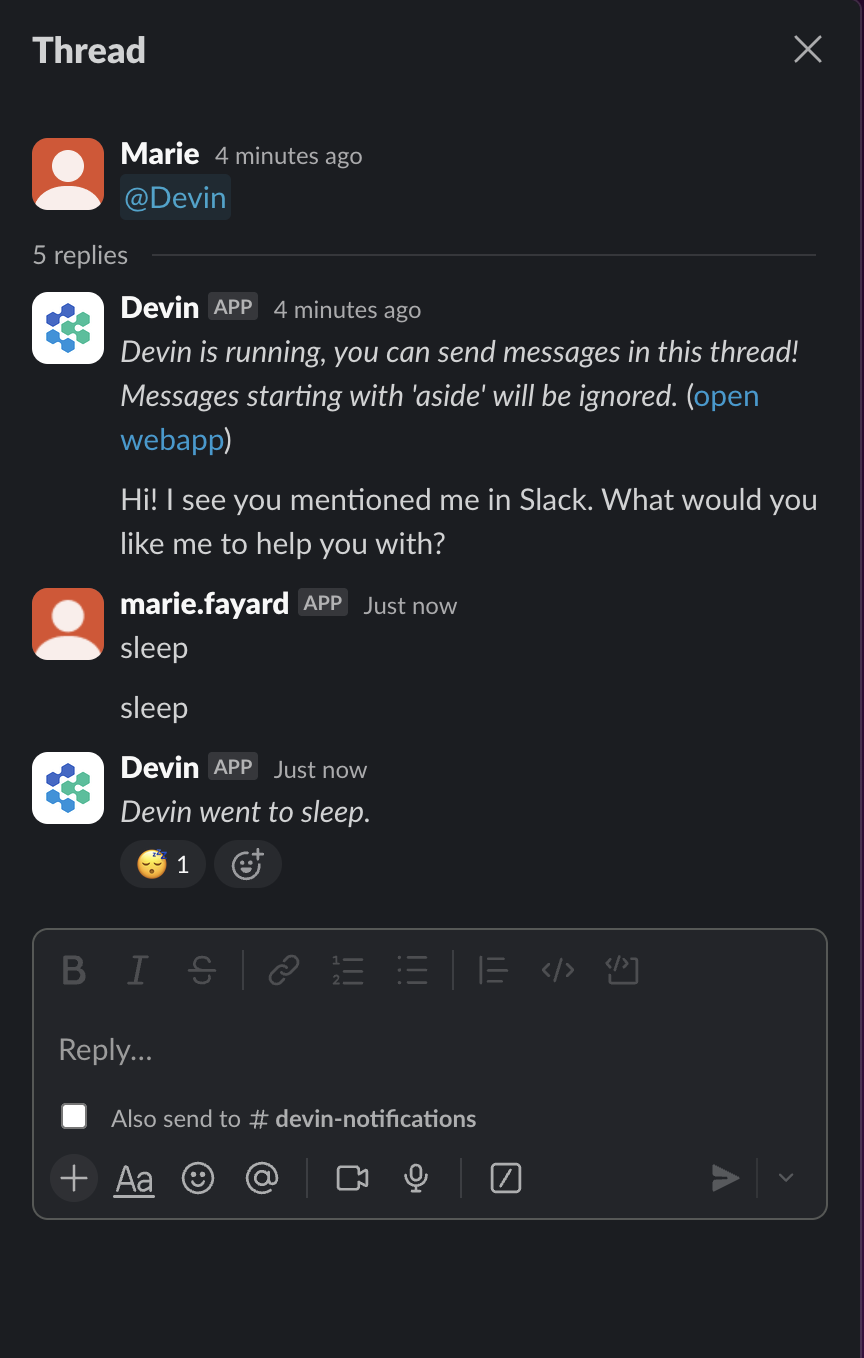
E inicia una sesión a la que puedes acceder en la interfaz de usuario:
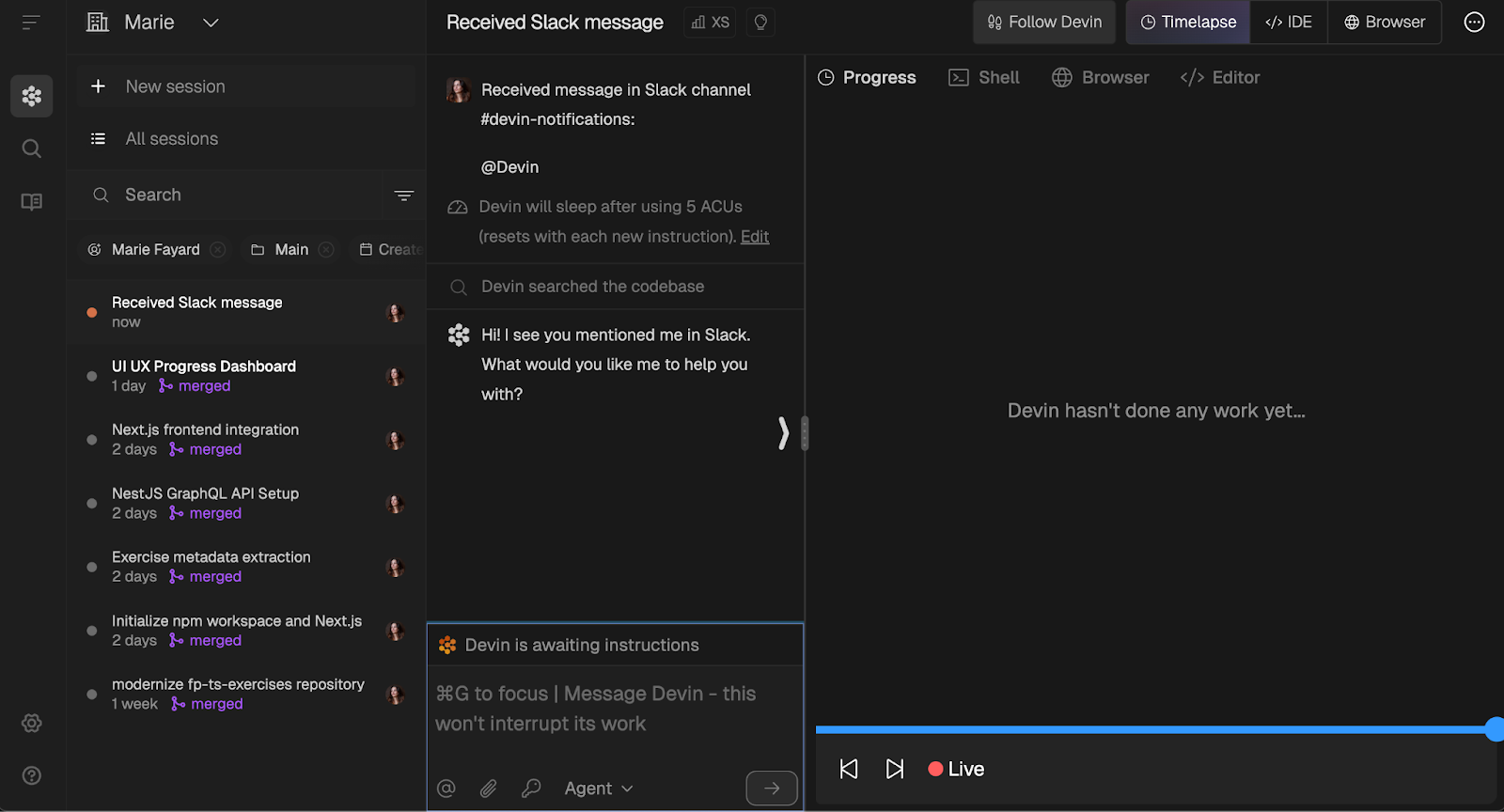
Por defecto, recibes notificaciones de las actualizaciones de relaciones públicas en el canal que elijas, pero hay algunos ajustes de notificación diferentes que puedes ajustar en los parámetros de cada sesión.
Para integrarte con Jira, tienes que crear una cuenta de usuario bot dedicada (por ejemplo, devin-bot@… ) y vincular esas credenciales en Devin → Equipo ▸ Integraciones ▸ Jira.
Desde tu cuenta personal, puedes crear un nuevo ticket y añadir la etiqueta devin.
Devin publica un comentario de análisis con un esbozo de plan y una indicación "¿Iniciar sesión? Escribe "sí" para que codifique o quita la etiqueta para que el ticket sea sólo humano.
Nota: Devin no moverá automáticamente cartas por tu tablero. Tú o tu PM aún debéis arrastrarlos a En curso o Hecho. Eso mantiene el control del flujo de trabajo en manos humanas.
Una vez que Slack y Jira estuvieron conectados, probé un verdadero experimento de "agente-como-equipo" y lancé tickets reales a Devin para ver si podía implementarlos sin ayuda.
Éste es mi flujo de trabajo:
devin, que es la señal de Devin para analizar.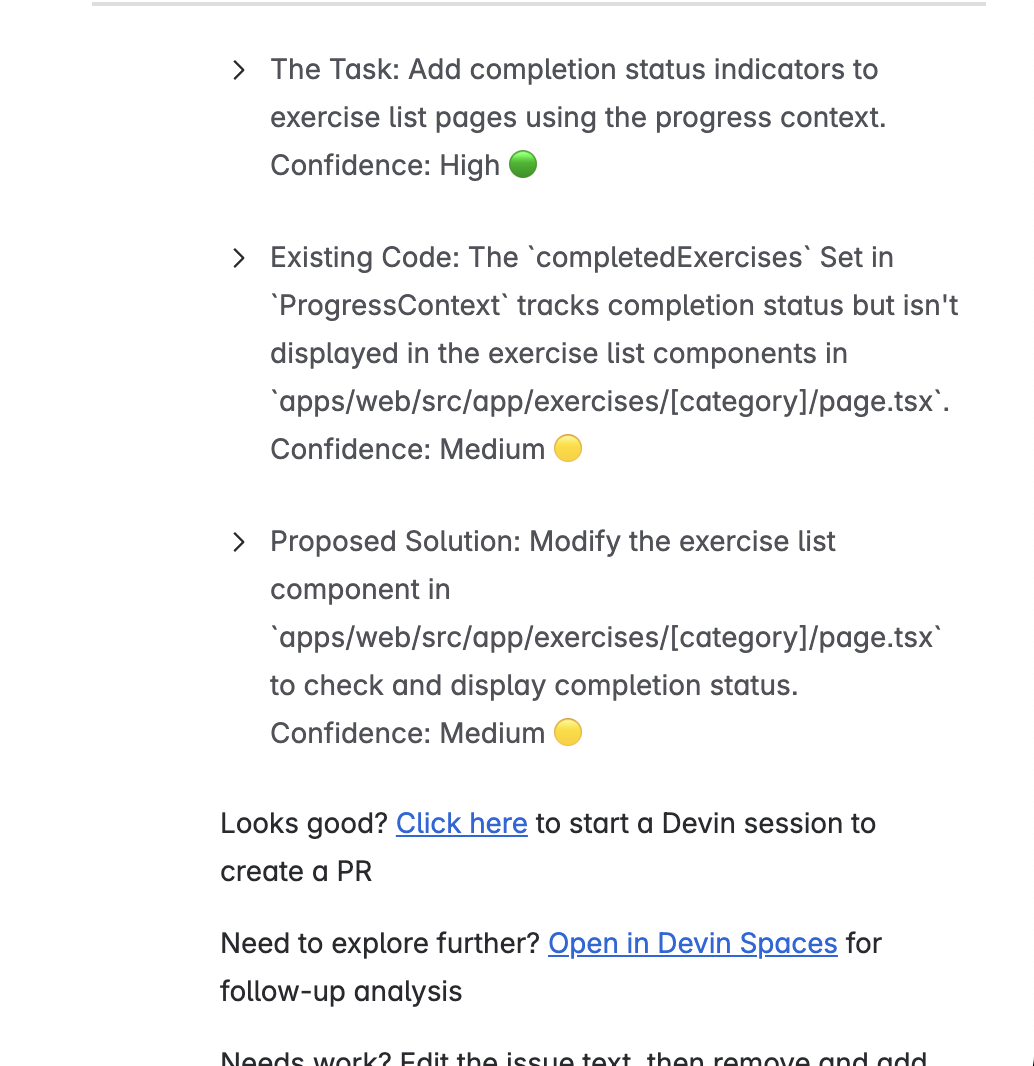
He aquí un resumen de lo que ocurrió con cinco billetes reales:
Éstas son las cosas que habría que mejorar:
Devin en Jira es prometedor: dos tickets se cerraron perfectamente, uno con un ligero empujón, e incluso el peor caso sólo costó tiempo, no una reversión. Pero la coherencia aún no ha llegado, así que el ámbito estricto y las restricciones explícitas son tus amigos.
Con el chat y los tickets fluyendo, el siguiente paso era asegurarse de que el código roto no pudiera colarse. Le pedí a Devin dos cosas: pruebas unitarias de backend y pruebas Playwright de extremo a extremo que imitaran a un alumno editando un ejercicio en el navegador.
Le pedí a Devin suites de prueba Jest que cubrieran el resolver GraphQL, la capa de servicio y los modelos Prisma. Cuando pedí una estimación de ACUs, me respondió ¡¡¡20 ACUs!!!
Supuse que debía tratarse de un error y lancé la tarea de todos modos. Costó 1,1 ACU, y fue fácilmente la tarea mejor ejecutada hasta el momento.
Éste era ligeramente más caro y costaba 2,3 UCA.
El flujo registrado: abrir /learn/option-01 → editar código → esperar ✓ → actualizar página → ✓ persiste.
En la primera ejecución, fallaron alrededor del 70 % de las afirmaciones. Había muchos fallos de redimensionamiento, recuentos de salpicadero obsoletos, e incluso el camino feliz fallaba.
A pesar del comando "Ignora las pruebas que fallen, ya lo arreglaremos más tarde" de mi prompt, Devin siguió parcheando código hasta que el conjunto se volvió mayoritariamente verde (útil, pero no lo que yo pedía).
Todavía tenemos algunas pruebas que fallan porque tenemos bastantes fallos en el sistema. Pero no pasa nada, ya arreglaremos las cosas más adelante para asegurarnos de que todas estas pruebas son verdes.
Una vez establecidas las pruebas unitarias y de extremo a extremo, el último paso era asegurarse de que cada pull request ejecuta esas comprobaciones automáticamente. Le pedí a Devin un flujo de trabajo básico, sin artefactos, sin puertas de cobertura, sólo lint → comprobación de tipos → pruebas.
Devin entregó una tubería sorprendentemente pulida de un solo golpe, sin necesidad de empujones posteriores:
Devin empujó el flujo de trabajo, esperó a que se completara la comprobación en GitHub, y sólo entonces decidió que estaba hecho. Debo decir que 0,4 ACU para una tubería en pleno funcionamiento es difícil de superar. YAML es claramente el lugar feliz de Devin.
Con este flujo de trabajo fusionado, ¡cada RP debe pasar lint, compilar y ambas suites de pruebas antes de que nadie pulse el botón verde!
Devin incluye una "Wiki" integrada que puede vivir junto a tu código. Es una base de conocimientos ligera y autogenerada que el agente puede leer y escribir mientras trabaja. Después de conectar Slack, Jira y CI, esta Wiki es un buen lugar para las notas arquitectónicas. ¡Merece la pena echarle un vistazo!
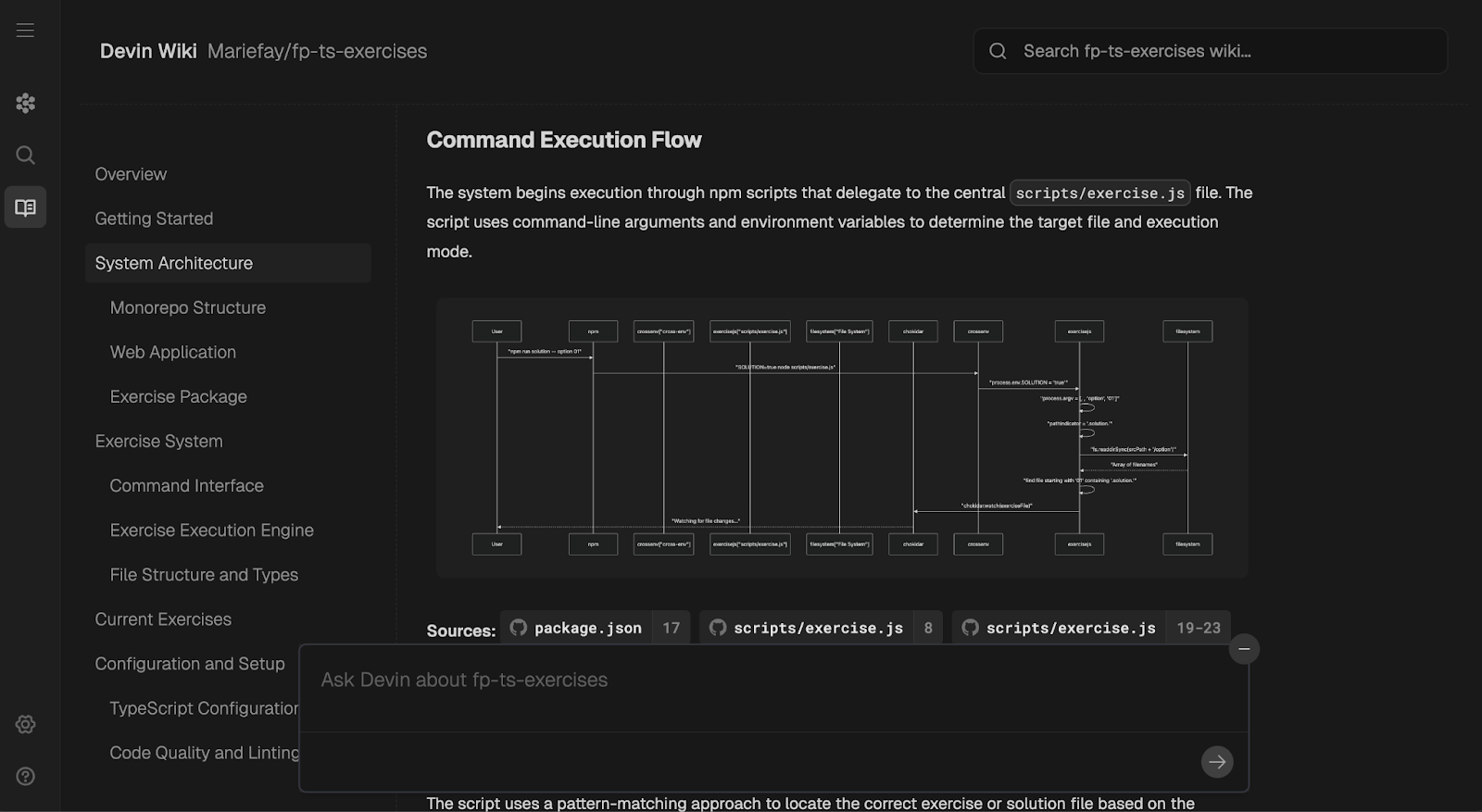
Que yo sepa, esto no se puede editar manualmente, y debes confiar en Devin para mantener la Wiki actualizada.
Una vez que todas las integraciones, las pruebas y el pipeline estuvieron en marcha, conté la cuenta y el reloj:
Así que, unas 2 horas de esfuerzo humano para conseguir entradas, pruebas y empujar CI. Seguro que es más rápido de lo que yo lo habría hecho.
En este punto, sin embargo, tengo un conflicto. Todavía hay muchos errores, y si yo mismo hubiera escrito toda la base de código, probablemente podría solucionar los problemas más rápido de lo que Devin quema créditos.
Pero Devin escribió la mayor parte de la aplicación, así que el agente "conoce" la estructura mejor que yo. Aun así, le cuesta sustituir los valores codificados por otros dinámicos, deja cabos sueltos en el código de cada archivo y necesita que me siente delante del portátil para vigilar todas sus acciones.
También encontré el proceso un poco frustrante y no de la misma manera que lo sería perseguir un bicho que no puedo comprender. Hay un mundo de diferencia (al menos para mí) entre estar frustrado porque el código no funciona y estar frustrado porque un agente de IA no pueda seguir unas instrucciones básicas. Esto último es francamente exasperante.
Creo que Devin puede ser muy útil cuando se utiliza bien, pero como ocurre con todos los agentes de IA que existen, no puede sustituir a un ingeniero de software. Está bien utilizarlo para algunas tareas, pero no creo que sea muy adecuado ni sostenible utilizarlo para todas las entradas.
Estamos conectados a Slack y Jira, las pruebas están en verde y la puerta CI bloquea cualquier PR descuidado. Pero para un lanzamiento real de la producción, aún nos faltan cuatro pilares:
GqlAuthGuard en NestJS para que el progreso esté vinculado a usuarios reales.prod cuando la rama principal se vuelve verde.Esa es la agenda de la Parte 4, la recta final en la que descubriremos si Devin puede asegurar, desplegar y cuidar la aplicación casi sin intervención humana. Fija tu base de datos a Postgres (¡otra vez!), tapa esas ACUs, y nos vemos en el último capítulo.
Si estás listo para continuar, haz clic en el último elemento de la lista para ir al cuarto tutorial:
Construye agentes de IA con estos cursos:
Curso
Curso
Curso
blog
Abid Ali Awan
10 min
blog
Abid Ali Awan
10 min
blog
Javier Canales Luna
10 min
Tutorial
Abid Ali Awan