programa
Fundamentos del aprendizaje automático en Python
16 h
En este tutorial, aprenderemos sobre DeepChecks y cómo utilizarlo para realizar la validación de datos y las pruebas de aprendizaje automático. También utilizaremos las Acciones de GitHub para automatizar las pruebas del modelo y guardar los resultados como artefactos.
A medida que avancemos, aprenderemos sobre las pruebas de aprendizaje automático y DeepChecks, ejecutaremos el paquete de integridad de datos DeepChecks y generaremos un informe completo. También generaremos informes de pruebas de aprendizaje automático ejecutando un conjunto de evaluación de modelos, aprenderemos a ejecutar una sola prueba en lugar de un conjunto completo, automatizaremos nuestro flujo de trabajo de pruebas utilizando Acciones de GitHub, y guardaremos el informe de pruebas de aprendizaje automático como un Artefacto de GitHub.

Imagen del autor
Las pruebas de aprendizaje automático son un proceso crítico que consiste en evaluar y validar el rendimiento de los modelos de aprendizaje automático para garantizar su imparcialidad, precisión y solidez. No todo es precisión y rendimiento del modelo. Tenemos que fijarnos en los sesgos del modelo, los falsos positivos, los falsos negativos, diversas métricas de rendimiento, el rendimiento del modelo y la alineación del modelo con la ética de la IA.
El proceso de prueba incluye varios tipos de evaluaciones, como la validación de datos, la validación cruzada, la puntuación F1, la matriz de confusión, la deriva de la predicción, la deriva de los datos y la prueba de robustez, cada una de ellas diseñada para verificar diferentes aspectos del rendimiento y la fiabilidad del modelo.
También dividimos nuestro conjunto de datos en tres partes para poder evaluar el modelo durante el proceso de entrenamiento y después del proceso de entrenamiento en un conjunto de datos no visto.
Las pruebas de aprendizaje automático son una parte esencial de las aplicaciones de IA, y automatizarlas junto con el entrenamiento de modelos nos proporcionará sistemas de IA fiables que funcionen para las personas.
Si eres nuevo en el aprendizaje automático y quieres aprender lo básico, toma el curso Fundamentos del Aprendizaje Automático con Python. Este curso te enseñará los fundamentos del aprendizaje automático con Python, empezando por el aprendizaje supervisado mediante la biblioteca scikit-learn.
DeepChecks es un paquete Python de código abierto diseñado para facilitar la comprobación y validación exhaustivas de modelos y datos de aprendizaje automático. Proporciona una amplia gama de comprobaciones integradas para identificar problemas relacionados con el rendimiento del modelo, la distribución de datos, la integridad de los datos, etc. DeepChecks incluye funcionalidades para la validación continua, garantizando que los modelos sigan siendo fiables y eficaces a medida que se despliegan y utilizan en escenarios del mundo real.
Empezaremos instalando el paquete Python mediante el comando pip.
%pip install deepchecks --upgrade -qPara este tutorial, vamos a utilizar los Datos de préstamos de los conjuntos de datos de DataCamp. Consta de 9578 filas e información sobre la estructura del préstamo, el prestatario y si el préstamo se devolvió en su totalidad.
Carga el archivo CSV utilizando Pandas y muestra las 5 filas superiores.
import pandas as pd
loan_data = pd.read_csv("loan_data.csv")
loan_data.head()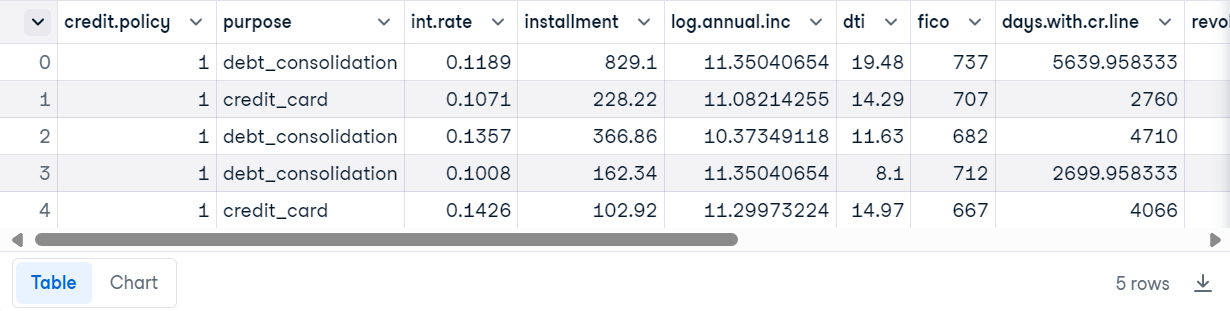
Crea el conjunto de datos DeepChecks utilizando el conjunto de datos del préstamo, el nombre de la columna de etiqueta y el nombre de la característica categórica.
from sklearn.model_selection import train_test_split
from deepchecks.tabular import Dataset
label_col = 'not.fully.paid'
deep_loan_data = Dataset(loan_data, label=label_col, cat_features=["purpose"])Utilizaremos una suite de integridad de datos para datos tabulares. La suite ejecutará todas las pruebas de forma autónoma y generará un informe interactivo con los resultados.
Para ello, importaremos el conjunto de integridad de datos, lo iniciaremos y, a continuación, lo ejecutaremos proporcionándole los datos de préstamo de DeepChecks. Por último, mostraremos los resultados.
from deepchecks.tabular.suites import data_integrity
integ_suite = data_integrity()
suite_result = integ_suite.run(deep_loan_data)
suite_result.show()Nota: Estamos utilizando DataLab como entorno de desarrollo. Se ha desactivado el uso de ipywidgets, impidiendo que muestre los resultados. En su lugar, utilizaremos la función 'show_in_iframe' para mostrar el resultado como un iframe. Los resultados serán los mismos en todos los niveles.
suite_result.show_in_iframe()Nuestro informe sobre la integridad de los datos incluye los resultados de las pruebas sobre:
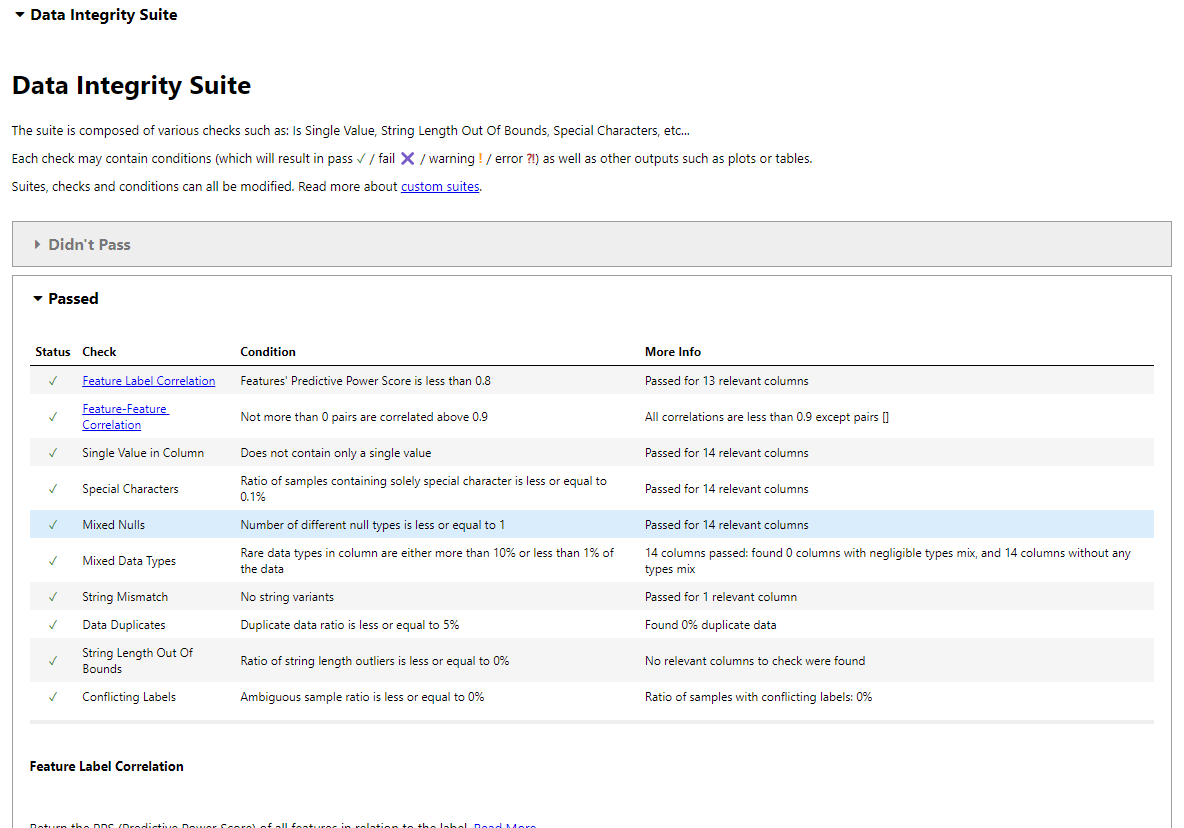
Resultados de la prueba de Integridad de los Datos en el Jupyter Notebook.
Incluso puedes guardar los resultados como un archivo HTML y compartirlo con tus compañeros.
suite_result.save_as_html()'output.html'Ejecutar toda la suite en el gran conjunto de datos no es una forma eficiente, ya que se tardará mucho tiempo en generar los resultados. En su lugar, puedes ejecutar unas cuantas pruebas individuales que sean relevantes para tus datos y generar un informe por tu cuenta.
Para ejecutar una sola prueba, importa las comprobaciones tabulares, inicializa la comprobación y ejecútala con los datos de Préstamo de DeepCheck. Después, muestra los valores en lugar de generar un informe interactivo utilizando la función results.value.
from deepchecks.tabular.checks import IsSingleValue, DataDuplicates
result = IsSingleValue().run(deep_loan_data)
result.valueComo podemos ver, muestra el número de valores únicos presentes en cada columna.
{'credit.policy': 2,
'purpose': 7,
'int.rate': 249,
'installment': 4788,
'log.annual.inc': 1987,
'dti': 2529,
'fico': 44,
'days.with.cr.line': 2687,
'revol.bal': 7869,
'revol.util': 1035,
'inq.last.6mths': 28,
'delinq.2yrs': 11,
'pub.rec': 6,
'not.fully.paid': 2}Intentemos comprobar las muestras duplicadas dentro de nuestros datos.
result = DataDuplicates().run(deep_loan_data)
result.valueTenemos cero duplicados en nuestro conjunto de datos.
0.0En esta sección, ensamblaremos varios modelos y los entrenaremos con el conjunto de datos de carga procesada. A continuación, para generar un informe de prueba del modelo, ejecutaremos un conjunto de valoración del modelo en los conjuntos de datos de entrenamiento y de prueba.
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import VotingClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.preprocessing import LabelEncoder
# Train test split
df_train, df_test = train_test_split(loan_data, stratify=loan_data[label_col], random_state=0)
# Encode the 'purpose' column
label_encoder = LabelEncoder()
df_train['purpose'] = label_encoder.fit_transform(df_train['purpose'])
df_test['purpose'] = label_encoder.fit_transform(df_test['purpose'])
# Define models
model_1 = LogisticRegression(random_state=1, max_iter=10000)
model_2 = RandomForestClassifier(n_estimators=50, random_state=1)
model_3 = GaussianNB()
# Create the VotingClassifier
clf_model = VotingClassifier(
estimators=[('lr', model_1), ('rf', model_2), ('svc', model_3)],
voting='soft'
)
# Train the model
clf_model.fit(df_train.drop(label_col, axis=1), df_train[label_col])
Ejecutaremos la suite de evaluación de modelos DeepChecks para evaluar el rendimiento del modelo.
from deepchecks.tabular.suites import model_evaluation
deep_train = Dataset(df_train, label=label_col, cat_features=[])
deep_test = Dataset(df_test, label=label_col, cat_features=[])
evaluation_suite = model_evaluation()
suite_result = evaluation_suite.run(deep_train, deep_test, clf_model)
suite_result.show_in_iframe()Nuestro informe de evaluación del modelo incluye resultados de pruebas sobre:

to_json(). suite_result.to_json()Al igual que la validación de datos, puedes ejecutar una única prueba de aprendizaje automático. En nuestro caso, ejecutaremos la deriva de etiquetas en la división de entrenamiento y de prueba para comprobar si nuestras etiquetas han cambiado con el tiempo.
from deepchecks.tabular.checks import LabelDrift
check = LabelDrift()
result = check.run(deep_train, deep_test)
result.valueNo se ha detectado ninguna deriva en los datos.
{'Drift score': 0.0, 'Method': "Cramer's V"}Si tienes dificultades para ejecutar las suites de validación de datos y evaluación de modelos, consulta el espacio de trabajo DataLab en Pruebas de aprendizaje automático con DeepChecks.
Si estás interesado en la experimentación "manual" del aprendizaje automático, sigue el enlace Experimentación de Aprendizaje Automático para aprender a estructurar, registrar y analizar tus experimentos de aprendizaje automático utilizando Pesos y Sesgos.
Automaticemos la fase de validación de datos, entrenamiento del modelo y evaluación del modelo con las Acciones de GitHub y guardemos los resultados como un archivo zip.
La automatización de las pruebas de aprendizaje automático es una parte integral del proceso de MLOps. Aprende más sobre esto realizando el curso Fundamentos de MLOps de MLOPS. En esta serie de cursos, aprenderás los principios fundamentales para poner en producción modelos de aprendizaje automático y supervisarlos para que aporten valor empresarial.
$ cd C:\Repository\GitHub\
$ git clone https://github.com/kingabzpro/Automating-Machine-Learning-Testing.git
$ cd .\Automating-Machine-Learning-Testing\
$ mkdir data
$ mv -v ".Downloads\loan_data.csv" ".\Automating-Machine-Learning-Testing\data"
$ code -r data_validation.pyimport pandas as pd
from deepchecks.tabular import Dataset
from deepchecks.tabular.suites import data_integrity
# Load the loan data from a CSV file
loan_data = pd.read_csv("data/loan_data.csv")
# Define the label column
label_col = "not.fully.paid"
# Create a Deepchecks Dataset object with the loan data
deep_loan_data = Dataset(loan_data, label=label_col, cat_features=["purpose"])
# Initialize the data integrity suite
integ_suite = data_integrity()
# Run the data integrity suite on the dataset
suite_result = integ_suite.run(deep_loan_data)
# Save the results of the data integrity suite as an HTML file
suite_result.save_as_html("results/data_validation.html")$ code -r train_validation.pyimport pandas as pd
from sklearn.ensemble import RandomForestClassifier, VotingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import GaussianNB
from sklearn.preprocessing import LabelEncoder, StandardScaler
from deepchecks.tabular import Dataset
from deepchecks.tabular.suites import model_evaluation
# Load the loan data from a CSV file
loan_data = pd.read_csv("data/loan_data.csv")
# Define the label column
label_col = "not.fully.paid"
# Train test split
df_train, df_test = train_test_split(
loan_data, stratify=loan_data[label_col], random_state=0
)
# Encode the 'purpose' column
label_encoder = LabelEncoder()
df_train["purpose"] = label_encoder.fit_transform(df_train["purpose"])
df_test["purpose"] = label_encoder.transform(df_test["purpose"])
# Standardize the features
scaler = StandardScaler()
df_train[df_train.columns.difference([label_col])] = scaler.fit_transform(df_train[df_train.columns.difference([label_col])])
df_test[df_test.columns.difference([label_col])] = scaler.transform(df_test[df_test.columns.difference([label_col])])
# Define models
model_1 = LogisticRegression(random_state=1, max_iter=10000)
model_2 = RandomForestClassifier(n_estimators=50, random_state=1)
model_3 = GaussianNB()
# Create the VotingClassifier
clf_model = VotingClassifier(
estimators=[("lr", model_1), ("rf", model_2), ("gnb", model_3)], voting="soft"
)
# Train the model
clf_model.fit(df_train.drop(label_col, axis=1), df_train[label_col])
# Calculate the accuracy score using the .score function
accuracy = clf_model.score(df_test.drop(label_col, axis=1), df_test[label_col])
# Print the accuracy score
print(f"Accuracy: {accuracy:.2f}")
# Create Deepchecks datasets
deep_train = Dataset(df_train, label=label_col, cat_features=["purpose"])
deep_test = Dataset(df_test, label=label_col, cat_features=["purpose"])
# Run the evaluation suite
evaluation_suite = model_evaluation()
suite_result = evaluation_suite.run(deep_train, deep_test, clf_model)
# Save the results as HTML
suite_result.save_as_html("results/model_validation.html")Si no conoces las Acciones de GitHub, completa el tutorial "Acciones de GitHub y MakeFile: Una introducción práctica" antes de iniciar el proceso de automatización. Este tutorial proporcionará una comprensión detallada de cómo funcionan las Acciones de GitHub con ejemplos de código.
$ git add .
$ git commit -m "Data and Validation files"
$ git push
main.yml del flujo de trabajo. Por favor, copia y pega el siguiente código. El código siguiente configurará primero el entorno e instalará el paquete DeepChecks. Después, creará la carpeta, ejecutará la validación de datos y la evaluación del modelo, y guardará los resultados como un Artefacto de GitHub.name: Model Training and Validation
on:
push:
branches: [ main ]
pull_request:
branches: [ main ]
jobs:
build:
runs-on: ubuntu-latest
steps:
- name: Checkout Repository
uses: actions/checkout@v4
- name: Set up Python 3.10
uses: actions/setup-python@v5
with:
python-version: '3.10'
- name: Install dependencies
run: |
python -m pip install --upgrade pip
pip install deepchecks
- name: Create a folder
run: |
mkdir -p results
- name: Validate Data
run: |
python data_validation.py
- name: Validate Model Performance
run: |
python train_validation.py
- name: Archive Deepchecks Results
uses: actions/upload-artifact@v4
if: always()
with:
name: deepchecks results
path: results/*_validation.html
Al confirmar los cambios en la rama principal, se iniciará la ejecución del flujo de trabajo. Para ver el registro de ejecución, ve a la pestaña "Acciones" y haz clic en la ejecución actual del flujo de trabajo asociada al mensaje de confirmación.
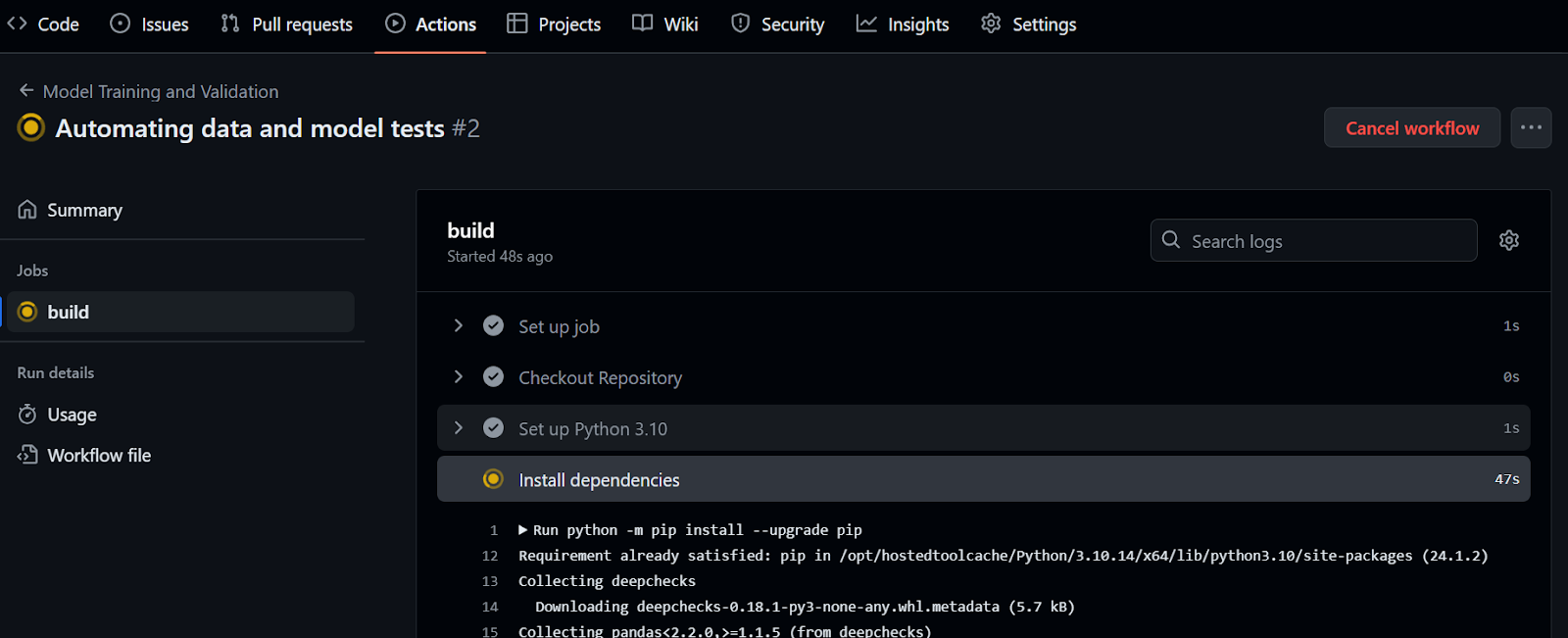
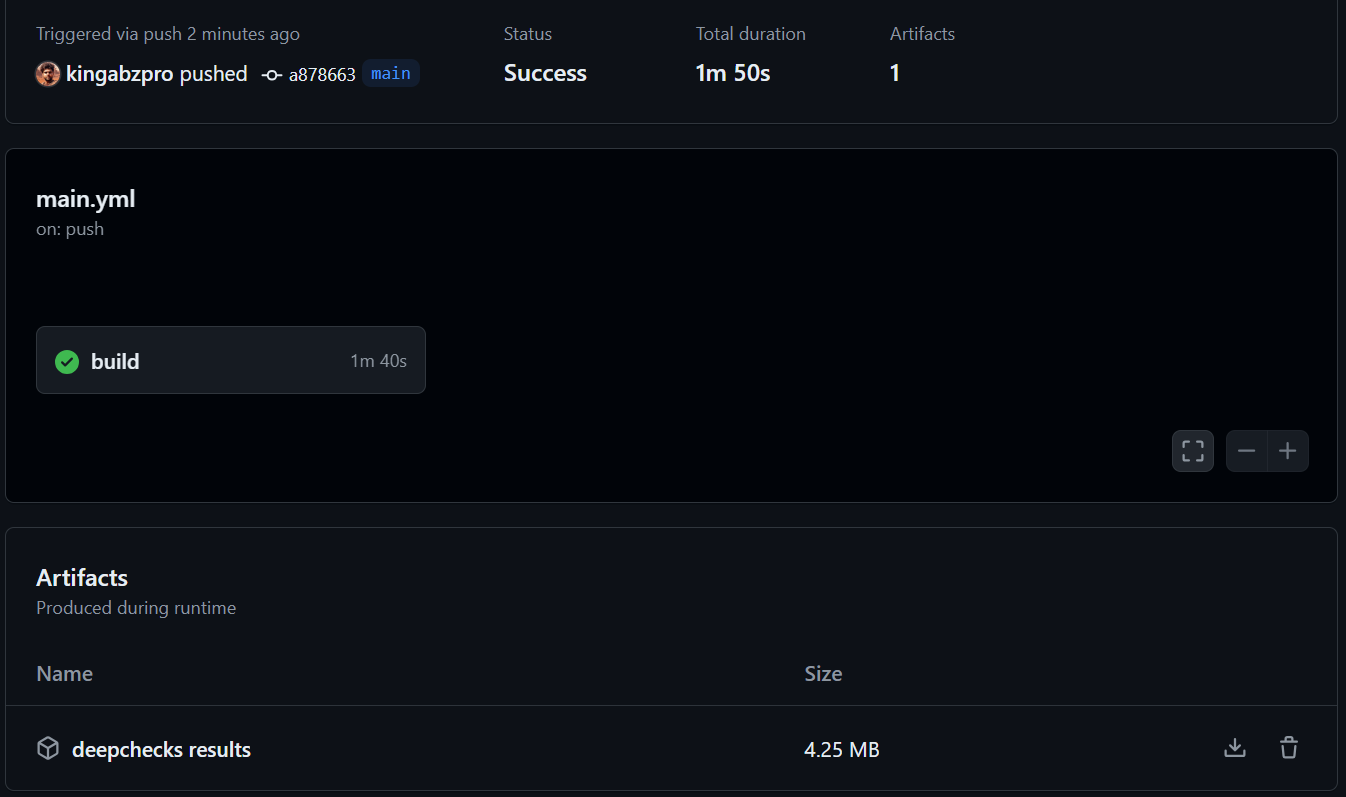
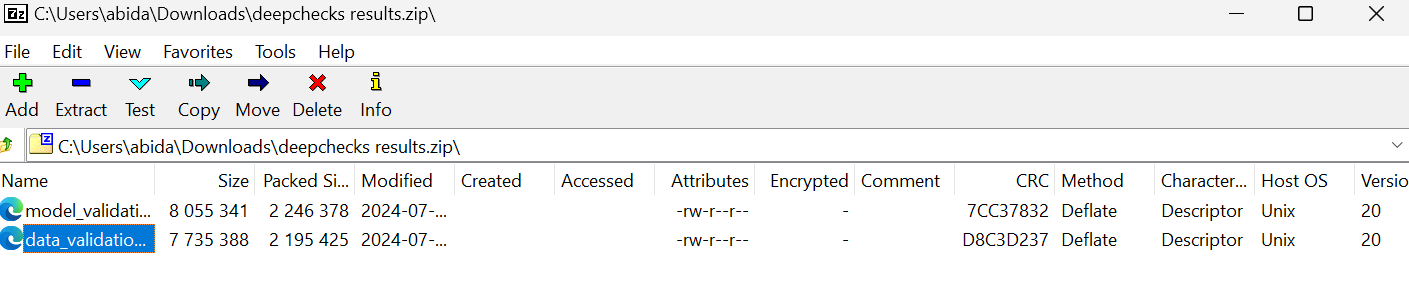
Consulta la página kingabzpro/Automatización de pruebas de aprendizaje automático como guía. Contiene datos, código Python, archivos de flujo de trabajo y otros archivos necesarios para ejecutar pruebas totalmente automatizadas.
Automatizar todo el proceso de aprendizaje automático requiere el conocimiento de varios procesos y herramientas. Para conocerlos, considera la posibilidad de realizar un Despliegue y Ciclo de Vida de MLOps MLOPS. Este curso explora los marcos MLOps modernos, centrándose en el ciclo de vida y el despliegue de modelos de aprendizaje automático.
Automatizando el proceso de prueba, los desarrolladores pueden validar rápida y eficazmente la precisión y solidez de los modelos frente a conjuntos de datos grandes y complejos. Las pruebas automatizadas ayudan a detectar problemas en una fase temprana, como incoherencias en los datos, desviación de datos y sesgos del modelo, que podrían no ser evidentes mediante pruebas manuales. Esto ahorra tiempo y mejora la capacidad del modelo para hacer predicciones justas y precisas.
En este tutorial, hemos aprendido sobre las pruebas de aprendizaje automático y cómo utilizar DeepChecks para la validación de datos y las pruebas de aprendizaje automático. También automatizamos la comprobación de datos y modelos y guardamos los resultados como artefactos utilizando Acciones de GitHub.
Si te ha gustado el tutorial y estás interesado en iniciar una carrera en el aprendizaje automático, considera la posibilidad de matricularte en el curso Científico de Aprendizaje Automático con Python con Python. Completa todos los cursos en 3 meses para adquirir las habilidades que necesitas para un trabajo como científico de aprendizaje automático.
Los mejores cursos de aprendizaje automático
programa
programa
Curso
blog
Abid Ali Awan
10 min
Tutorial
Abid Ali Awan
Tutorial
Zoumana Keita
Tutorial
Kurtis Pykes

