Curso
Projetando Sistemas Agentes com LangChain
3 h
12.1K
Bem-vindo de volta! Ao final do do segundo tutorialtínhamos um playground fp-ts com tema pastel, um backend NestJS + PostgreSQL e um programa de acompanhamento de progresso UUID anônimo.
Você pode acessar todos os tutoriais da série Devin aqui:
O que fizemos até agora é ótimo para hackers individuais, mas está na hora de ver como o Devin se integra aos fluxos de trabalho da equipe. Neste terceiro tutorial, você verá:
Ainda não há implementações de autenticação nem de produção, elas acontecerão na Parte 4!
A conexão do Devin ao seu fluxo de comunicação e de tíquetes é totalmente manual e feita por meio da interface do Devin.
Você pode se conectar ao Slack na guia de integração das configurações do Devin ou instalar o aplicativo "Devin AI" no diretório de aplicativos do Slack.
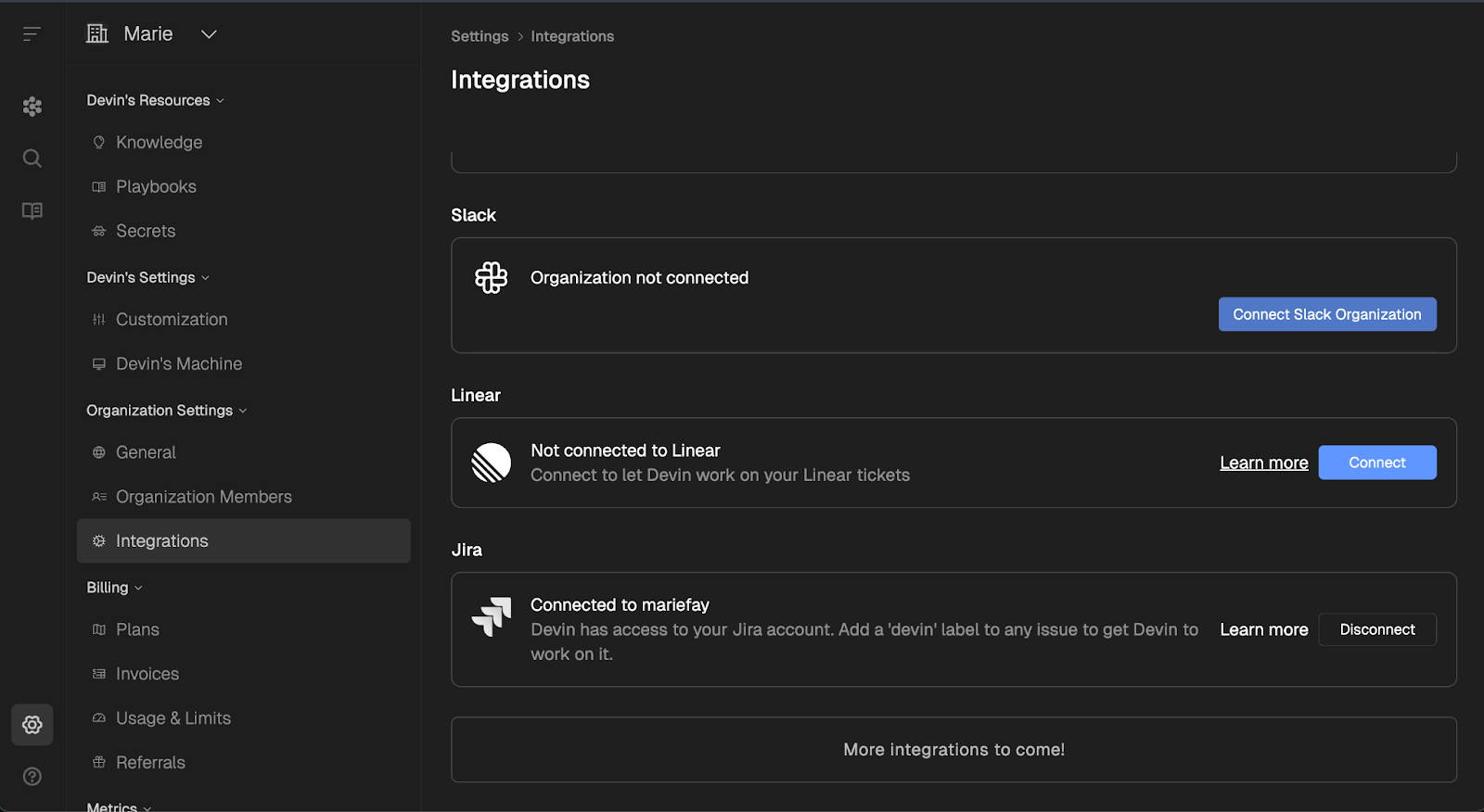
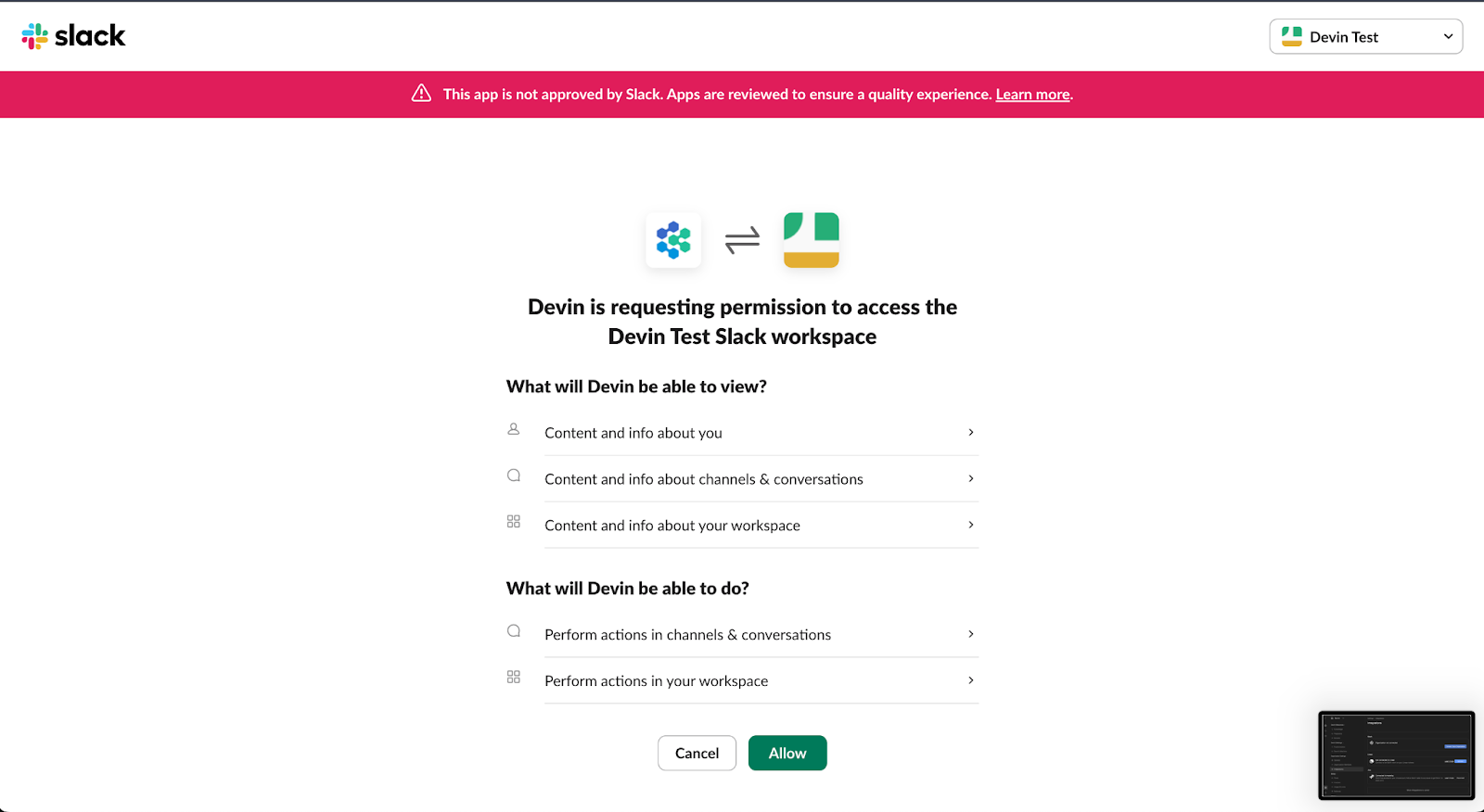
O aplicativo ainda mostra "Não aprovado pelo Slack" na caixa de diálogo do OAuth. A Cognition diz que sua revisão de segurança está pendente e que a funcionalidade não foi afetada.
Em seguida, escolha um canal:

Você pode conversar com Devin com apenas uma menção:
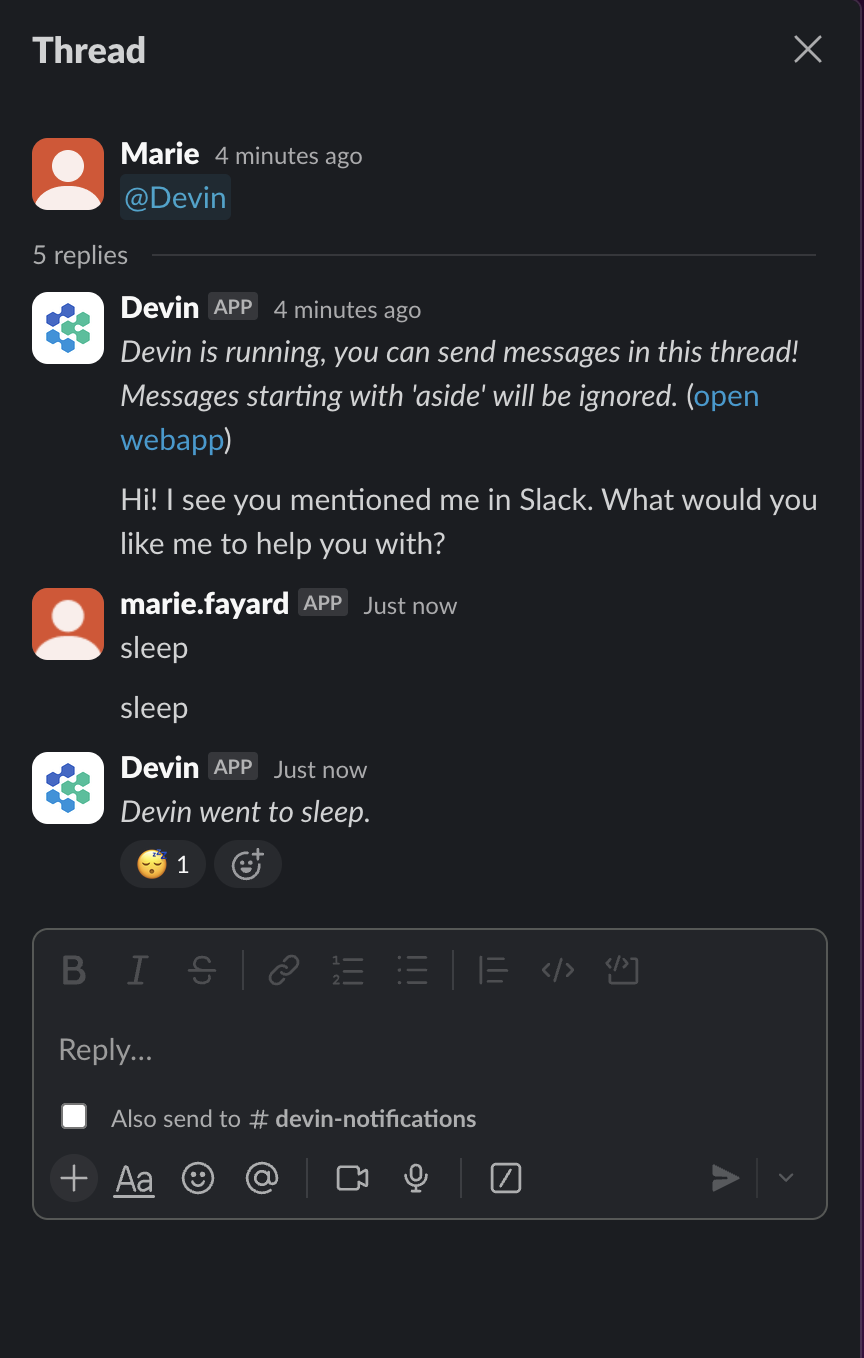
E ele inicia uma sessão que você pode acessar na interface do usuário:
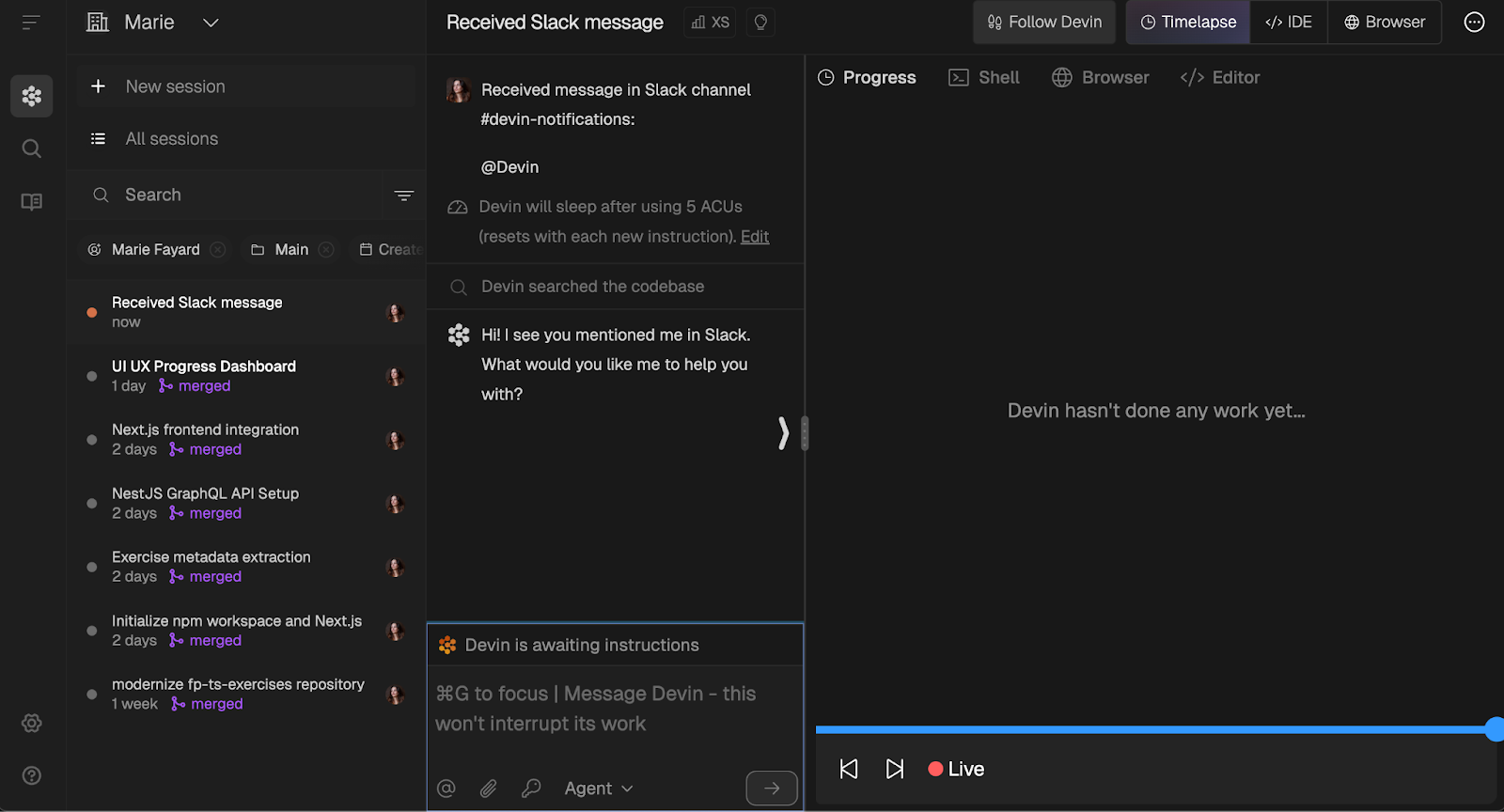
Por padrão, você é notificado sobre as atualizações de RP no canal de sua escolha, mas há algumas configurações de notificação diferentes que podem ser ajustadas nos parâmetros de cada sessão.
Para integrar-se ao Jira, você precisa criar uma conta de usuário de bot dedicada (por exemplo, devin-bot@… ) e vincular essas credenciais em Devin → Equipe ▸ Integrações ▸ Jira.
Na sua conta pessoal, você pode criar um novo tíquete e adicionar a etiqueta devin.
Devin publica um comentário de análise com um esboço de plano e um prompt "Iniciar sessão?". Digite "yes" para permitir que ele codifique ou remova o rótulo para manter o tíquete somente para humanos.
Observação: Devin não moverá cartas automaticamente pelo seu tabuleiro. Você ou seu PM ainda deve arrastá-los para Em andamento ou Concluído. Isso mantém o controle do fluxo de trabalho em mãos humanas.
Depois que o Slack e o Jira foram conectados, fiz um verdadeiro experimento de "agente como colega de equipe" e enviei tíquetes reais para o Devin para ver se ele poderia implementá-los sem precisar de ajuda.
Este é o meu fluxo de trabalho:
devin, que é o sinal de Devin para você analisar.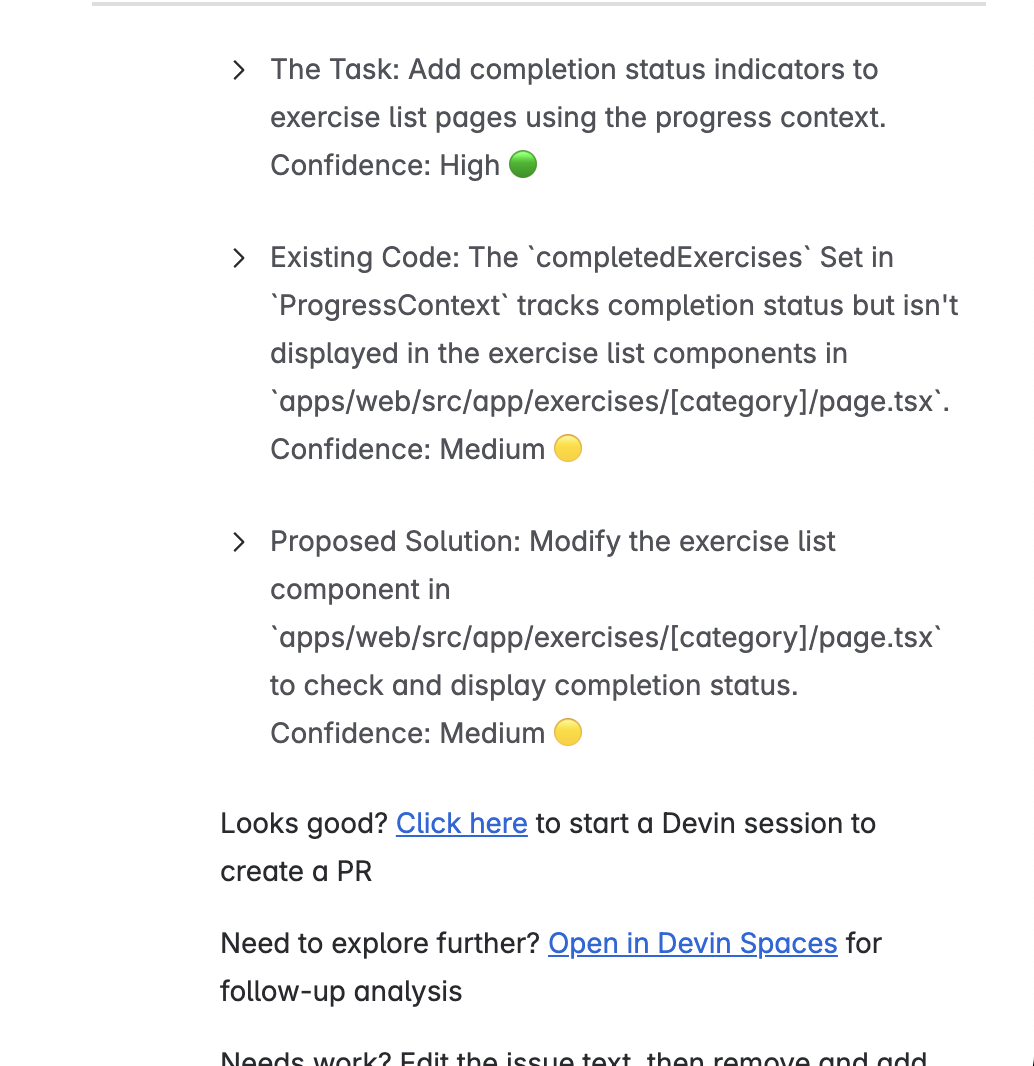
Aqui está um resumo do que aconteceu com cinco tíquetes reais:
Esses são os aspectos que precisariam ser aprimorados:
Devin, no Jira, é promissor: dois tíquetes foram fechados perfeitamente, um deles com um leve empurrão, e mesmo o pior caso custou apenas tempo, não uma reversão. Mas a consistência ainda não está presente, portanto, o escopo restrito e as restrições explícitas são seus amigos.
Com o fluxo de bate-papo e tíquetes, a próxima etapa era garantir que o código corrompido não passasse despercebido. Pedi a Devin duas coisas: testes unitários de back-end e testes Playwright de ponta a ponta que imitam um aluno editando um exercício no navegador.
Pedi a Devin suítes de teste Jest que abrangessem o resolvedor GraphQL, a camada de serviço e os modelos Prisma. Quando solicitei uma estimativa de ACU, ele respondeu 20 ACUs!!!
Achei que devia ser um erro e iniciei a tarefa mesmo assim. Custou 1,1 ACUs e foi facilmente a tarefa mais bem executada até agora.
Esse foi um pouco mais caro e custou 2,3 ACUs.
O fluxo registrado: abrir /learn/option-01 → editar código → aguardar ✓ → atualizar página → ✓ persiste.
Na primeira execução, cerca de 70% das afirmações falharam. Houve muitas falhas de redimensionamento, contagens de painel obsoletas e até mesmo o caminho feliz falhou.
Apesar do comando "Ignore failing tests, we'll fix later" (Ignorar testes com falha, corrigiremos mais tarde) no meu prompt, Devin continuou corrigindo o código até que o conjunto ficasse quase todo verde (útil, mas não o que eu pedi).
Ainda temos alguns testes que falharam porque temos alguns bugs no sistema. Mas tudo bem, vamos resolver as coisas mais tarde para garantir que todos esses testes sejam verdes.
Com os testes unitários e de ponta a ponta implementados, a última etapa foi garantir que cada pull request executasse essas verificações automaticamente. Pedi ao Devin um fluxo de trabalho básico, sem artefatos, sem portas de cobertura, apenas lint → verificação de tipos → testes.
Devin entregou um pipeline surpreendentemente polido em uma única tentativa, sem a necessidade de qualquer acompanhamento:
Devin enviou o fluxo de trabalho, esperou que a verificação fosse concluída no GitHub e só então decidiu que estava pronto. Devo dizer que 0,4 ACU para um pipeline em pleno funcionamento é difícil de superar. YAML é claramente o lugar feliz de Devin.
Com esse fluxo de trabalho mesclado, cada PR deve ser aprovado no lint, na compilação e nos dois conjuntos de testes antes que alguém pressione o botão verde!
O Devin vem com um "Wiki" integrado que pode ficar ao lado do seu código. É uma base de conhecimento leve e gerada automaticamente, na qual o agente pode ler e gravar enquanto trabalha. Depois de conectar o Slack, o Jira e o CI, este Wiki é um bom local para anotações de arquitetura. Vale a pena dar uma olhada!
Pelo que sei, isso não é editável manualmente, e você deve contar com Devin para manter o Wiki atualizado.
Quando todas as integrações, os testes e o pipeline estavam ativos, eu contabilizei a conta e o relógio:
Portanto, cerca de 2 horas de esforço humano para obter tíquetes, testes e CIs. É mais rápido do que eu teria feito, com certeza.
No entanto, neste momento, estou em conflito. Ainda há muitos bugs e, se eu mesmo tivesse escrito toda a base de código, provavelmente conseguiria corrigir os problemas mais rapidamente do que o Devin queima créditos.
Mas Devin escreveu a maior parte do aplicativo, então o agente realmente "conhece" a estrutura melhor do que eu. Ainda assim, ele se esforça para substituir valores codificados por valores dinâmicos, deixa pontas soltas no código em todos os arquivos e precisa que eu fique sentado em frente ao meu laptop para cuidar de todas as suas ações.
Também achei o processo um pouco frustrante, mas não da mesma forma que eu ficaria ao perseguir um bug que não consigo entender. Há uma grande diferença (pelo menos para mim) entre ficar frustrado porque o código não funciona e ficar frustrado porque um agente de IA não consegue seguir algumas instruções básicas. O último é absolutamente irritante.
Acho que o Devin pode ser muito útil quando bem utilizado, mas, como acontece com todos os agentes de IA existentes, ele não pode substituir um engenheiro de software. Não há problema em usá-lo para algumas tarefas, mas não acho que seja muito adequado ou sustentável usá-lo para todos os tíquetes.
Estamos conectados ao Slack e ao Jira, os testes são verdes e o portão de CI bloqueia todos os PRs desleixados. Mas para um lançamento de produção real, ainda faltam quatro pilares:
GqlAuthGuard no NestJS para que o progresso seja vinculado a usuários reais.prod quando a ramificação principal fica verde.Essa é a agenda da Parte 4, a reta final em que descobriremos se Devin pode proteger, implementar e cuidar do aplicativo quase sem intervenção humana. Fixe seu banco de dados no Postgres (de novo!), proteja as ACUs e vejo você no último capítulo.
Se você estiver pronto para continuar, clique no último item da lista abaixo para ir para o quarto tutorial:
Crie agentes de IA com estes cursos:
Curso
Curso
Curso
blog
DataCamp Team
4 min
blog
Armstrong Asenavi
15 min
Tutorial
Abid Ali Awan
Tutorial
Abid Ali Awan
Tutorial
Zoumana Keita

