Kurs
Agentische Systeme mit LangChain entwerfen
3 Std.
12.1K
Willkommen zurück! Am Ende des des zweiten Tutorialshatten wir einen pastellfarbenen fp-ts-Spielplatz, ein NestJS + PostgreSQL-Backend und anonyme UUID-Lernpfade.
Du kannst alle Tutorials der Devin-Serie hier aufrufen:
Was wir bisher gemacht haben, ist großartig für Solo-Hacking, aber es ist an der Zeit zu sehen, wie gut sich Devin in Teamworkflows integrieren lässt. In diesem dritten Tutorial schauen wir uns an:
Noch gibt es kein Auth- und kein Prod-Deployment, das kommt erst in Teil 4!
Die Einbindung von Devin in deinen Kommunikations- und Ticketfluss erfolgt vollständig manuell über die Devin-Schnittstelle.
Du kannst dich über die Registerkarte "Integration" in den Devin-Einstellungen mit Slack verbinden oder die App "Devin AI" aus dem App-Verzeichnis von Slack installieren.
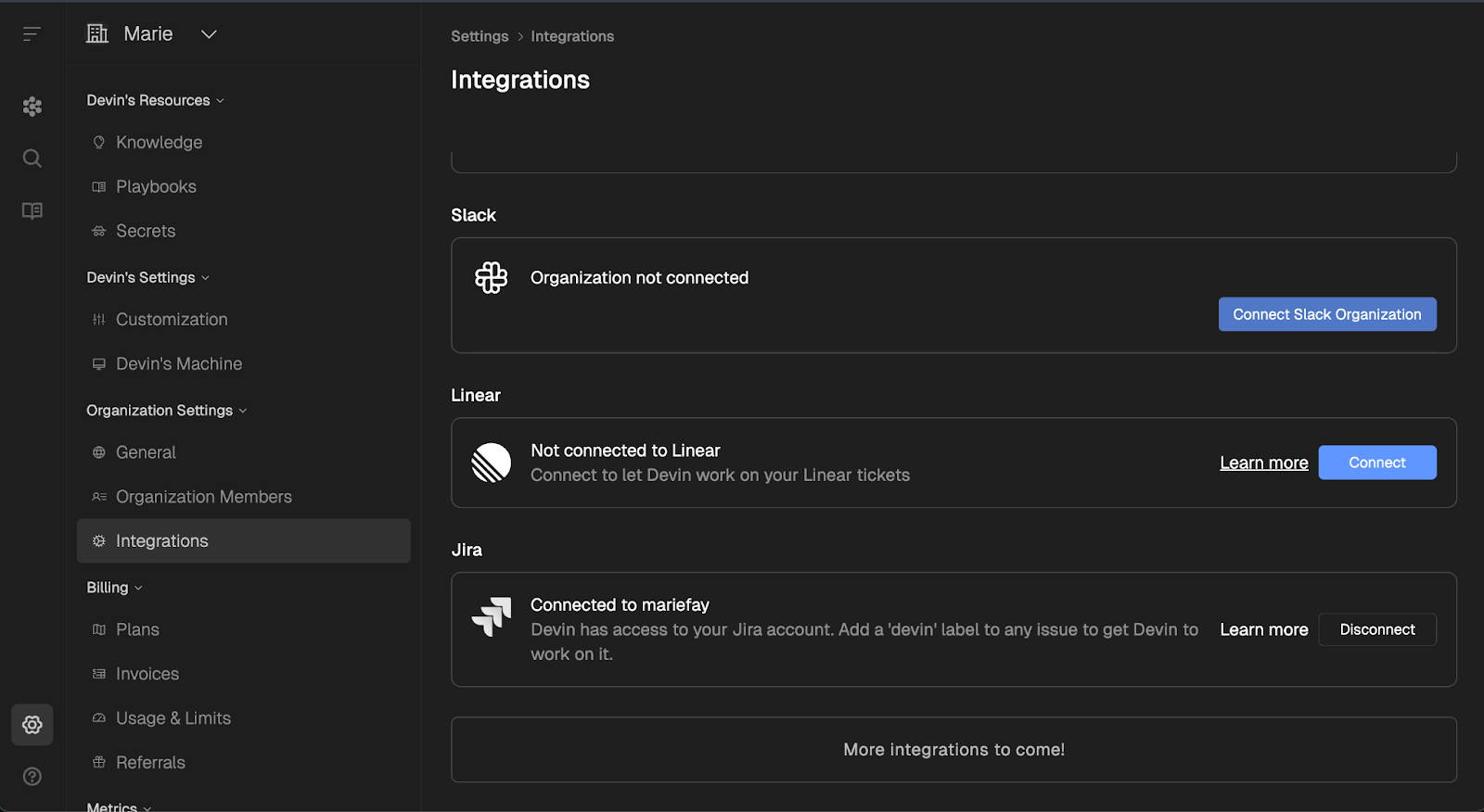
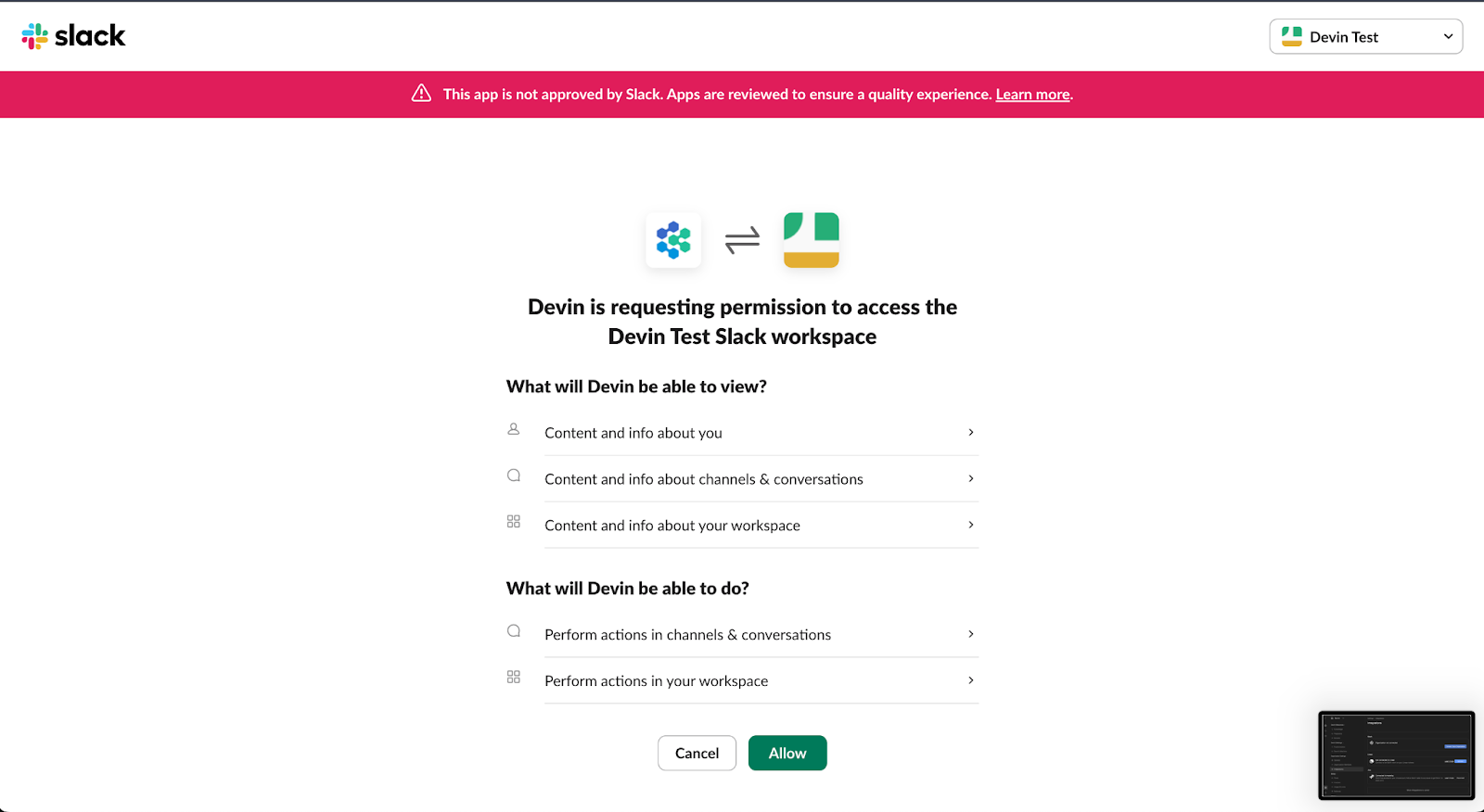
Die App zeigt im OAuth-Dialog immer noch "Nicht von Slack genehmigt" an. Cognition sagt, dass die Sicherheitsüberprüfung noch nicht abgeschlossen ist und die Funktionalität nicht beeinträchtigt wird.
Wähle dann einen Kanal aus:

Du kannst mit Devin chatten, indem du ihn einfach erwähnst:
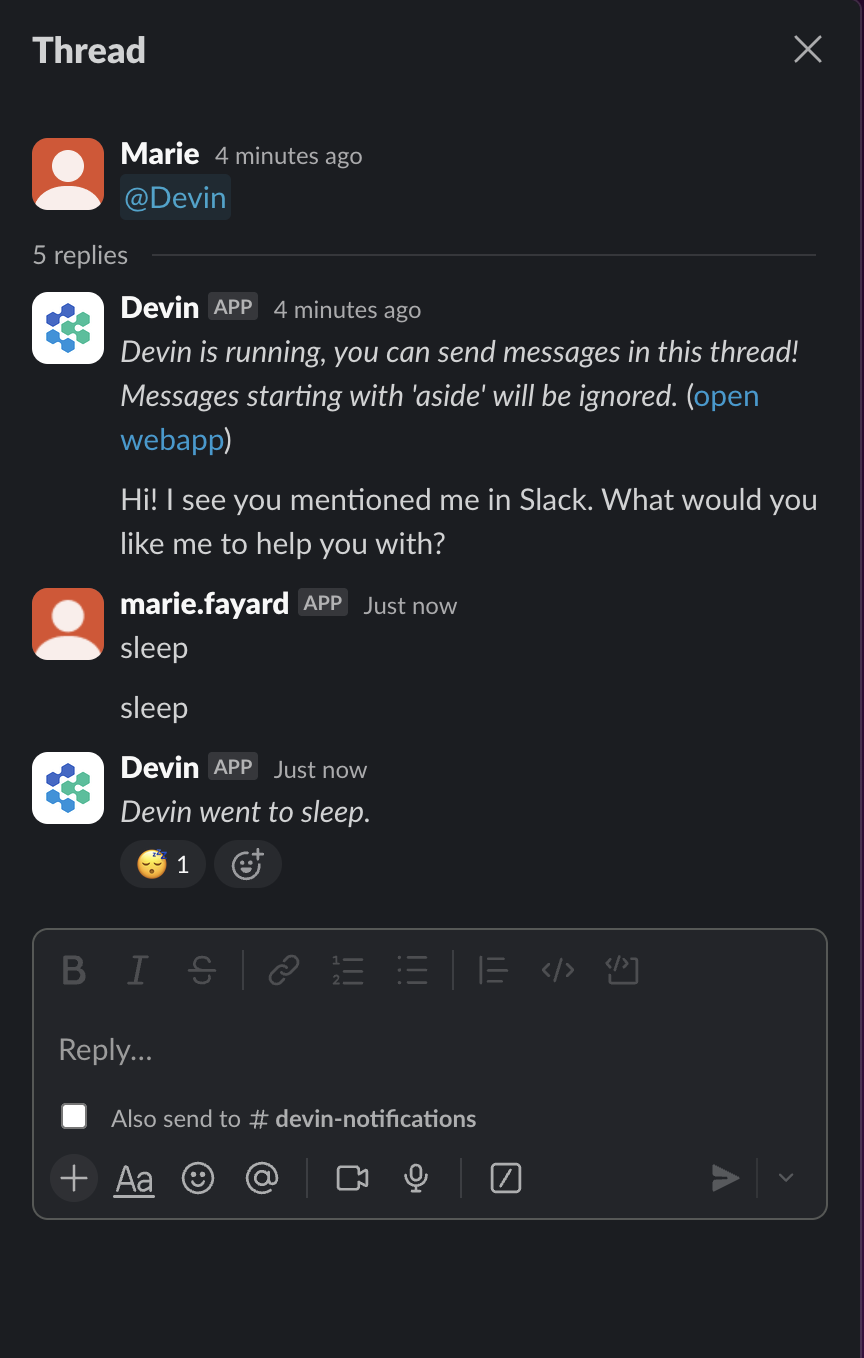
Und er startet eine Sitzung, auf die du in der Benutzeroberfläche zugreifen kannst:
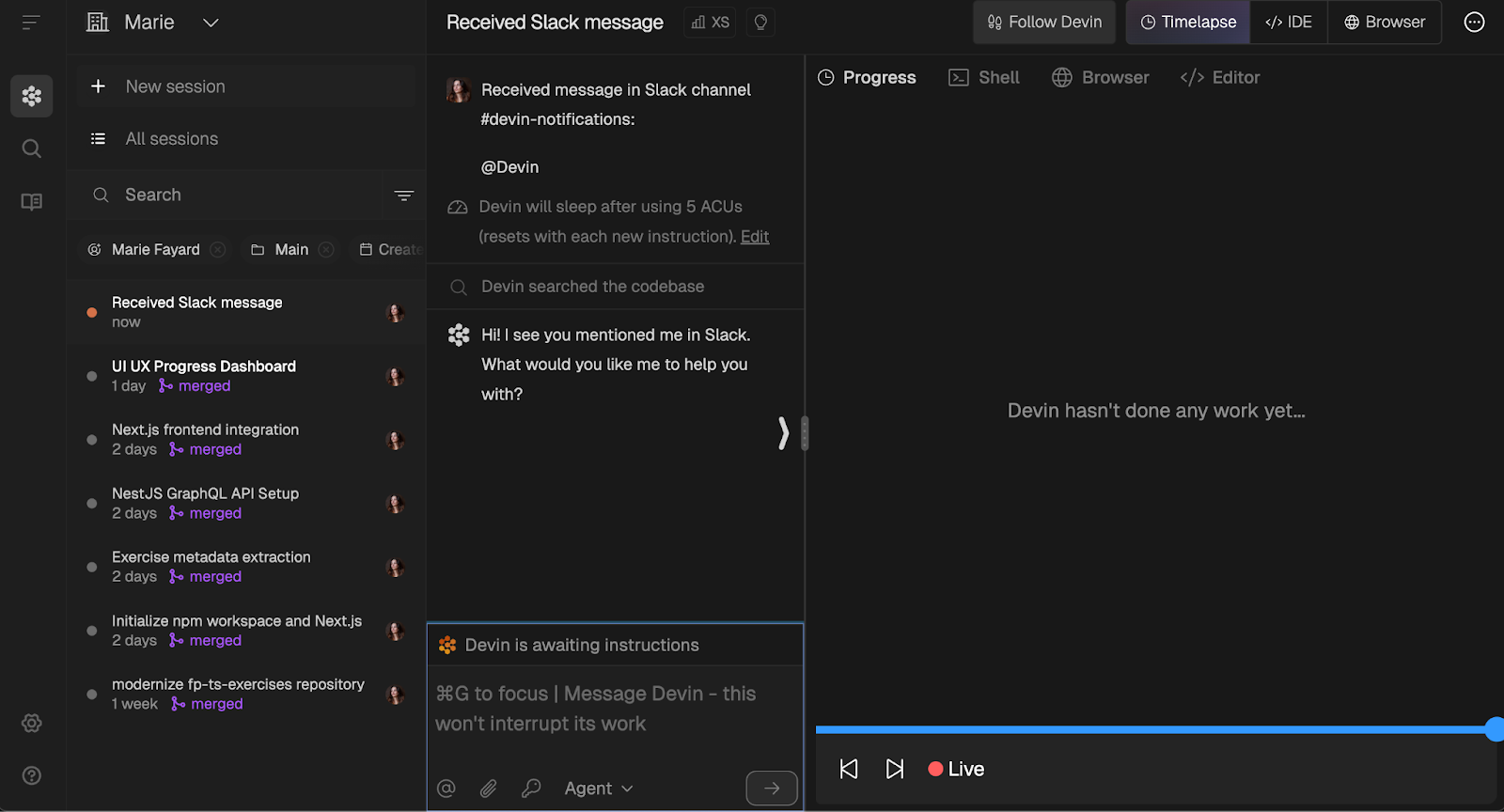
Standardmäßig wirst du über die PR-Updates im Kanal deiner Wahl benachrichtigt, aber es gibt ein paar verschiedene Benachrichtigungseinstellungen, die du in den Parametern jeder Sitzung anpassen kannst.
Für die Integration mit Jira musst du einen eigenen Bot-Benutzer (z.B. devin-bot@… ) anlegen und diese Anmeldedaten unter Devin → Team ▸ Integrationen ▸ Jira verknüpfen.
In deinem persönlichen Konto kannst du dann ein neues Ticket erstellen und das Label devin hinzufügen.
Devin postet einen Analysekommentar mit einer Planskizze und der Aufforderung "Sitzung starten?". Gib "ja" ein, um den Code zuzulassen, oder entferne das Etikett, um das Ticket nur für Menschen zugänglich zu machen.
Hinweis: Devin verschiebt keine Karten automatisch über dein Spielbrett. Du oder deine PM müssen sie trotzdem auf In Bearbeitung oder Erledigt ziehen. So bleibt die Kontrolle über den Arbeitsablauf in menschlicher Hand.
Nachdem Slack und Jira verkabelt waren, habe ich ein echtes "Agent-als-Teammitglied"-Experiment durchgeführt und Devin echte Tickets vorgelegt, um zu sehen, ob er sie ohne Hilfe umsetzen kann.
Hier ist mein Arbeitsablauf:
devin hinzu, das Devins Stichwort für die Analyse ist.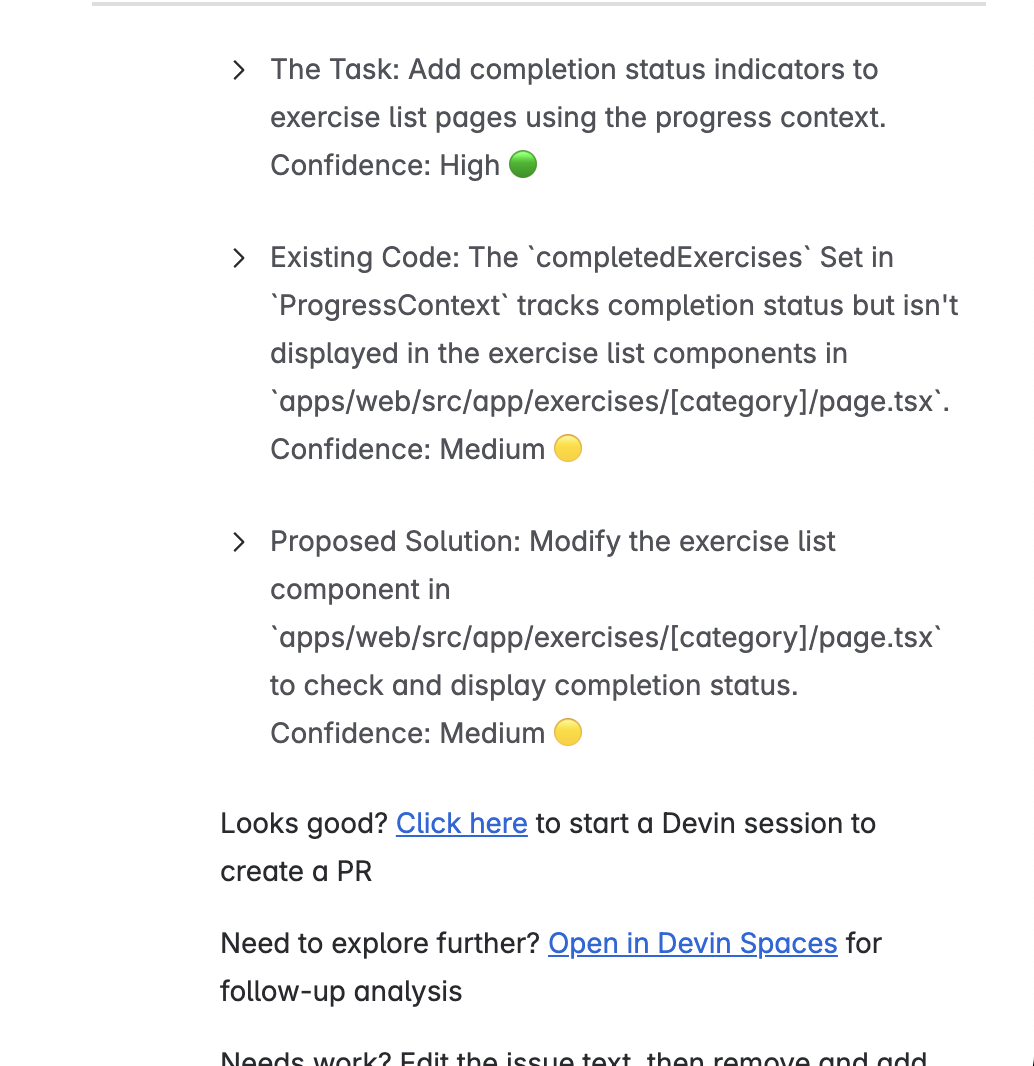
Hier ist eine Zusammenfassung, was bei fünf echten Tickets passiert ist:
Das sind die Dinge, die verbessert werden müssten:
Devin auf Jira ist vielversprechend: Zwei Tickets wurden perfekt geschlossen, eines mit leichtem Nudging, und selbst der schlimmste Fall hat nur Zeit gekostet, kein Rollback. Aber die Konsistenz ist noch nicht gegeben, also sind ein enger Rahmen und explizite Einschränkungen deine Freunde.
Nachdem der Chat und die Tickets gelaufen sind, war der nächste Schritt, sicherzustellen, dass sich kein fehlerhafter Code einschleichen kann. Ich habe Devin um zwei Dinge gebeten: Backend-Unit-Tests und End-to-End-Tests in Playwright, die nachahmen, wie ein Lernender eine Übung im Browser bearbeitet.
Ich bat Devin um Jest-Testsuiten für den GraphQL-Resolver, die Serviceschicht und die Prisma-Modelle. Als ich nach einer ACU-Schätzung fragte, antwortete sie 20 ACUs!!!
Ich dachte, das muss ein Fehler sein und habe die Aufgabe trotzdem gestartet. Sie hat 1,1 ACUs gekostet und war mit Abstand die beste Aufgabe, die bisher ausgeführt wurde.
Dieser war etwas teurer und kostete 2,3 ACUs.
Der aufgezeichnete Ablauf: /learn/option-01 öffnen → Code bearbeiten → warten ✓ → Seite aktualisieren → ✓ bleibt bestehen.
Im ersten Durchgang schlugen etwa 70 % der Behauptungen fehl. Es gab viele Fehler bei der Größenanpassung, veraltete Dashboard-Zählungen und sogar der Happy Path fiel aus.
Trotz des Befehls "Ignoriere fehlgeschlagene Tests, wir beheben sie später" in meiner Eingabeaufforderung hat Devin den Code so lange gepatcht, bis die Suite größtenteils grün war (nützlich, aber nicht das, was ich wollte).
Wir haben immer noch einige fehlgeschlagene Tests, weil wir ziemlich viele Bugs im System haben. Aber das ist okay, wir werden die Dinge später klären, um sicherzustellen, dass alle diese Tests grün sind.
Nachdem die Unit- und End-to-End-Tests eingerichtet waren, musste im letzten Schritt sichergestellt werden, dass jeder Pull Request diese Prüfungen automatisch durchläuft. Ich habe Devin um einen einfachen Arbeitsablauf gebeten, ohne Artefakte, ohne Coverage Gates, nur Lint → Type-Check → Tests.
Devin lieferte eine überraschend ausgefeilte Pipeline auf einen Schlag, ohne dass weitere Stupser nötig waren:
Devin schob den Workflow an, wartete, bis die Prüfung in GitHub abgeschlossen war, und entschied erst dann, dass er fertig war. Ich muss sagen, dass 0,4 ACU für eine voll funktionierende Pipeline schwer zu schlagen sind. YAML ist eindeutig Devins Lieblingsplatz.
Mit diesem Workflow muss jeder PR Lint, Compile und beide Testsuiten bestehen, bevor jemand den grünen Knopf drückt!
Devin wird mit einem eingebauten "Wiki" geliefert, das neben deinem Code leben kann. Es ist eine leichtgewichtige, automatisch generierte Wissensdatenbank, die der Agent während seiner Arbeit sowohl lesen als auch beschreiben kann. Nachdem du Slack, Jira und CI verbunden hast, ist dieses Wiki ein guter Ort für architektonische Notizen. Es ist einen Blick wert!
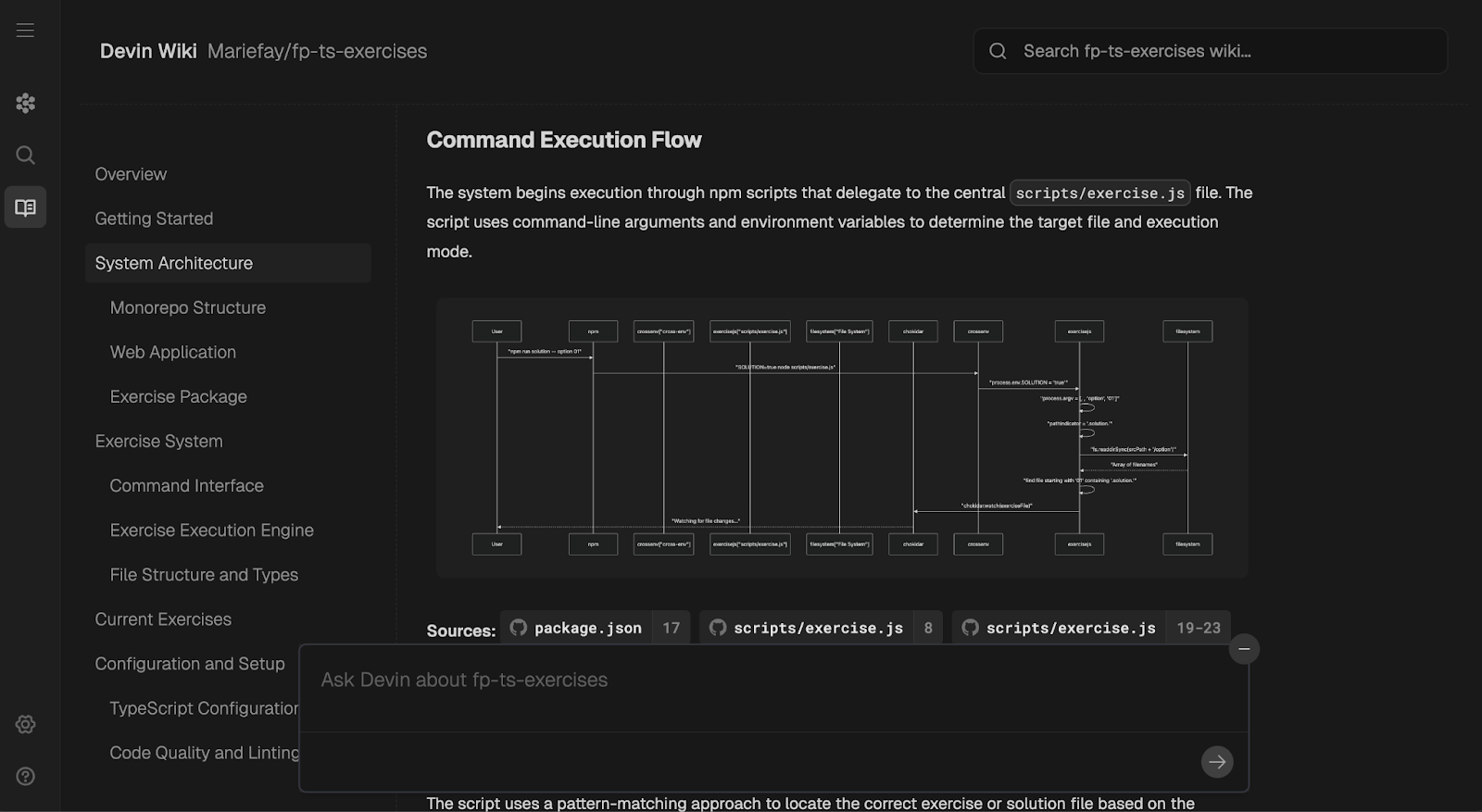
Soweit ich weiß, kann dies nicht manuell bearbeitet werden und du musst dich darauf verlassen, dass Devin das Wiki auf dem neuesten Stand hält.
Als alle Integrationen, Tests und die Pipeline in Betrieb waren, habe ich die Rechnung und die Uhr zusammengerechnet:
Also etwa 2 Stunden menschlicher Aufwand, um Tickets, Tests und CI zu pushen. Es ist sicher schneller, als ich es gemacht hätte.
An diesem Punkt bin ich allerdings hin- und hergerissen. Es gibt immer noch eine Menge Bugs und wenn ich die gesamte Codebasis selbst geschrieben hätte, könnte ich die Probleme wahrscheinlich schneller beheben als Devin Credits verbrennt.
Aber Devin hat den größten Teil der App geschrieben, also "kennt" der Agent die Struktur besser als ich. Dennoch hat es Schwierigkeiten, fest kodierte Werte durch dynamische zu ersetzen, es hinterlässt in jeder Datei lose Enden im Code und ich muss mich vor meinen Laptop setzen, um alle Aktionen zu überwachen.
Ich fand den Prozess auch ein bisschen frustrierend, aber nicht so, wie ich es wäre, wenn ich einem Fehler nachjagen würde, den ich nicht begreifen kann. Es ist ein himmelweiter Unterschied (zumindest für mich), ob man frustriert ist, weil der Code nicht funktioniert, oder ob man frustriert ist, weil ein KI-Agent ein paar grundlegende Anweisungen nicht befolgen kann. Letzteres ist geradezu ärgerlich.
Ich denke, dass Devin sehr hilfreich sein kann, wenn er gut eingesetzt wird, aber wie bei jedem KI-Agenten da draußen kann er keinen Software-Ingenieur ersetzen. Es ist in Ordnung, es für einige Aufgaben zu verwenden, aber ich glaube nicht, dass es sehr geeignet oder nachhaltig ist, es für jedes Ticket zu verwenden.
Wir sind mit Slack und Jira vernetzt, die Tests sind grün und das CI-Gate blockiert jeden schlampigen PR. Aber für einen echten Produktionsstart fehlen uns noch vier Säulen:
GqlAuthGuard in NestJS verkabeln, damit der Fortschritt an echte Nutzer/innen gebunden ist.prod weiterleitet, sobald die Hauptverzweigung grün wird.Das ist der Plan für Teil 4, die letzte Etappe, in der wir herausfinden, ob Devin die App fast ohne menschliches Zutun sichern, bereitstellen und betreuen kann. Verbinde deine Datenbank mit Postgres (wieder!), schließe die ACUs und wir sehen uns im dem letzten Kapitel.
Wenn du bereit bist, weiterzumachen, klicke auf den letzten Listenpunkt unten, um zum vierten Tutorial zu gelangen:
Baue mit diesen Kursen KI-Agenten auf:
Kurs
Kurs
Kurs
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nathaniel Taylor-Leach
Blog
Nathaniel Taylor-Leach
8 Min.
