
programa
Desarrollador Python
28 h
Cuando los profesionales de los datos hablan hoy en día sobre el almacenamiento de datos, la mayoría de las veces se refieren al lugar donde se almacenan los datos, ya sea en archivos locales, bases de datos SQL o nosql, o en la nube. Sin embargo, otro aspecto importante relacionado con el almacenamiento de datos es cómo se almacenan estos.
El cómo del almacenamiento de datos suele tener lugar en un nivel inferior, en el núcleo mismo de los lenguajes de programación. Tiene que ver con el diseño de las herramientas que usamos, más que con cómo usarlas. Sin embargo, saber cómo se almacenan los datos es fundamental para comprender los mecanismos subyacentes que hacen posible el trabajo. Además, este conocimiento puede ayudarnos a tomar mejores decisiones para mejorar el rendimiento informático.
Si realmente te interesan los mapas hash, así como las listas enlazadas, las pilas, las colas y los grafos, regístrate en DataCamp para poder realizar nuestro curso Estructuras de datos y algoritmos en Python.
Para definir un mapa hash, primero debemos comprender qué es el hash. El hash es el proceso de transformar cualquier clave o cadena de caracteres en otro valor. El resultado suele ser un valor más corto y de longitud fija que facilita el trabajo computacional en comparación con la clave original.
Los mapas hash, también conocidos como tablas hash, representan una de las implementaciones más comunes del hash. Los hashmaps almacenan pares clave-valor (por ejemplo, el ID y el nombre de un empleado) en una lista a la que se puede acceder a través de su índice. Podríamos decir que un mapa hash es una estructura de datos que aprovecha las técnicas de hash para almacenar datos de forma asociativa. Son estructuras de datos optimizadas que permiten operaciones de datos más rápidas, incluyendo la inserción, eliminación y búsqueda.
La idea detrás de los hashmaps es distribuir las entradas (pares clave/valor) en un arreglo de cubetas. Dada una clave, una función hash calculará un índice distinto que sugiere dónde se puede encontrar la entrada. El uso de un índice en lugar de la clave original hace que los mapas hash sean especialmente adecuados para múltiples operaciones con datos, incluyendo la inserción, eliminación y búsqueda de datos.
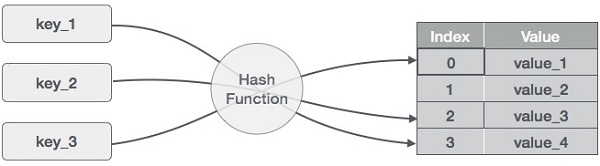
Cómo funciona un mapa hash. Imagen del autor
Para calcular el valor hash, o simplemente hash, una función hash genera nuevos valores según un algoritmo matemático de hash. Dado que los pares clave-valor son, en teoría, ilimitados, la función hash asignará las claves en función del tamaño de una tabla determinada.
Hay varias funciones hash disponibles, cada una con sus pros y sus contras. El objetivo principal de una función hash es devolver siempre el mismo valor para la misma entrada.
Los más comunes son los siguientes:
Python implementa mapas hash a través del tipo de datos diccionario integrado. Al igual que los hashmaps, los diccionarios almacenan datos en pares e {key:value}. Una vez creado el diccionario (véase la siguiente sección), Python aplicará una práctica función hash en segundo plano para calcular el hash de cada clave.
Los diccionarios de Python tienen las siguientes características:
Por lo tanto, si alguna vez te has preguntado cuáles son las diferencias entre los mapas hash y los diccionarios, la respuesta es sencilla. Un diccionario es simplemente la implementación nativa de Python de los mapas hash. Mientras que un mapa hash es una estructura de datos que se puede crear utilizando múltiples técnicas de hash, un diccionario es un mapa hash específico basado en Python, cuyo diseño y comportamiento se especifican en la clase dict de Python.
Muchos lenguajes de programación modernos, como Python, Java y C++, admiten mapas hash. En Python, los mapas hash se implementan mediante diccionarios, una estructura de datos muy utilizada que probablemente ya conozcas. En las siguientes secciones, trataremos los conceptos básicos de los diccionarios, cómo funcionan y cómo implementarlos utilizando diferentes paquetes de Python.
Veamos algunas de las operaciones más comunes del diccionario. Para obtener más información sobre cómo utilizar los diccionarios, consulta nuestro tutorial sobre diccionarios en Python.
Crear diccionarios en Python es bastante sencillo. Solo tienes que usar llaves e insertar los pares clave-valor separados por comas. Como alternativa, puedes utilizar la función integrada dict(). Creemos un diccionario que relacione las capitales con los países:
# Create dictionary
dictionary_capitals = {'Madrid': 'Spain', 'Lisboa': 'Portugal', 'London': 'United Kingdom'}
# Print the content of the dictionary
print(dictionary_capitals)
# Expected output:
# {'Madrid': 'Spain', 'Lisboa': 'Portugal', 'London': 'United Kingdom'}Es importante recordar que una clave debe ser única en un diccionario; no se permiten duplicados. Sin embargo, en caso de claves duplicadas, en lugar de dar un error, Python tomará la última instancia de la clave como válida y simplemente ignorará el primer par clave-valor. Compruébalo por ti mismo:
dictionary_capitals = {'Madrid': 'China', 'Lisboa': 'Portugal',
'London': 'United Kingdom','Madrid':'Spain'}
print(dictionary_capitals)
# Expected output:
# {'Madrid': 'Spain', 'Lisboa': 'Portugal', 'London': 'United Kingdom'}Para buscar información en nuestro diccionario, debemos especificar la clave entre corchetes, y Python devolverá el valor asociado, de la siguiente manera:
# Search for data
print(dictionary_capitals['Madrid'])
# Expected output: SpainSi intentas acceder a una clave que no está presente en el diccionario, Python generará un error. Para evitarlo, puedes acceder a las claves utilizando el método .get(). En caso de que la clave no exista, simplemente devolverá un valor None:
print(dictionary_capitals.get('Prague'))
# Expected output: NoneAñadamos un nuevo par capital-país:
# Create a new key-value pair
dictionary_capitals['Berlin'] = 'Italy'
print(dictionary_capitals)
# Expected output:
# {'Madrid': 'Spain', 'Lisboa': 'Portugal', 'London': 'United Kingdom', 'Berlin': 'Italy'}Se puede utilizar la misma sintaxis para actualizar el valor asociado a una clave. Fijemos el valor asociado a Berlín:
# Update the value of a key
dictionary_capitals['Berlin'] = 'Germany'
print(dictionary_capitals)
# Expected output:
# {'Madrid': 'Spain', 'Lisboa': 'Portugal', 'London': 'United Kingdom', 'Berlin': 'Germany'}Ahora eliminemos uno de los pares de nuestro diccionario.
# Delete key-value pair
del dictionary_capitals['Lisboa']
print(dictionary_capitals)
# Expected output:
# {'Madrid': 'Spain', 'London': 'United Kingdom', 'Berlin': 'Germany'}O, si deseas eliminar todos los pares clave-valor del diccionario, puedes utilizar el método .clear():
dictionary_capitals.clear()
print(dictionary_capitals)
# Expected output: {}Si deseas recuperar todos los pares clave-valor, utiliza el método .items() y Python recuperará una lista iterable de tuplas:
dictionary_capitals = {'Madrid': 'Spain', 'Lisboa': 'Portugal',
'London': 'United Kingdom', 'Berlin': 'Germany'}
print(dictionary_capitals.items())
# Expected output:
# dict_items([('Madrid', 'Spain'), ('Lisboa', 'Portugal'),
# ('London', 'United Kingdom'), ('Berlin', 'Germany')])# Iterate over key-value pairs
for key, value in dictionary_capitals.items():
print('the capital of {} is {}'.format(value, key))
# Expected output:
# the capital of Spain is Madrid
# the capital of Portugal is Lisboa
# the capital of United Kingdom is London
# the capital of Germany is BerlinDel mismo modo, si deseas recuperar una lista iterable con las claves y los valores, puedes utilizar los métodos .keys() y .values(), respectivamente:
print(dictionary_capitals.keys())
# Expected output:
# dict_keys(['Madrid', 'Lisboa', 'London', 'Berlin'])for key in dictionary_capitals.keys():
print(key.upper())
# Expected output:
# MADRID
# LISBOA
# LONDON
# BERLINprint(dictionary_capitals.values())
# Expected output:
# dict_values(['Spain', 'Portugal', 'United Kingdom', 'Germany'])for value in dictionary_capitals.values():
print(value.upper())
# Expected output:
# SPAIN
# PORTUGAL
# UNITED KINGDOM
# GERMANYLos hashmaps son potentes estructuras de datos que se utilizan prácticamente en todo el mundo digital. A continuación, encontrarás una lista de aplicaciones reales de los mapas hash:
Los hashmaps son estructuras de datos increíblemente versátiles y eficientes. Sin embargo, también tienen problemas y limitaciones. Para abordar los retos comunes asociados con los mapas hash, es importante tener en cuenta algunas consideraciones y buenas prácticas.
Esto tiene sentido: si el contenido de la clave cambia, la función hash devolverá un hash diferente, por lo que Python no podrá encontrar el valor asociado a la clave.
El hash solo funciona si cada elemento se asigna a una ubicación única en la tabla hash. Pero, en ocasiones, las funciones hash pueden devolver el mismo resultado para entradas diferentes. Por ejemplo, si utilizas una función hash de división, diferentes números enteros pueden tener la misma función hash (pueden devolver el mismo resto al aplicar la división modular), lo que crea un problema denominado colisión. Las colisiones deben resolverse, y existen varias técnicas para hacerlo. Afortunadamente, en el caso de los diccionarios, Python gestiona las posibles colisiones internamente.
El factor de carga se define como la relación entre el número de elementos de la tabla y el número total de cubos. Es una medida para estimar lo bien distribuidos que están los datos. Como regla general, cuanto más uniformemente se distribuyen los datos, menor es la probabilidad de colisiones. Una vez más, en el caso de los diccionarios, Python adapta automáticamente el tamaño de la tabla en caso de que se inserten o eliminen nuevos pares clave-valor.
Una buena función hash minimizaría el número de colisiones, sería fácil de calcular y distribuiría uniformemente los elementos en la tabla hash. Esto podría hacerse aumentando el tamaño de la tabla o la complejidad de la función hash. Aunque esto resulta práctico para un número reducido de elementos, no es viable cuando el número de elementos posibles es elevado, ya que daría lugar a mapas hash que consumen mucha memoria y son menos eficientes.
Los diccionarios son excelentes, pero otras estructuras de datos pueden ser más adecuadas para tus datos y necesidades específicos. Al final, los diccionarios no admiten operaciones comunes, como la indexación, el corte y la concatenación, lo que los hace menos flexibles y más difíciles de manejar en determinados escenarios.
Como ya se ha mencionado, Python implementa mapas hash a través de diccionarios integrados. Sin embargo, es importante señalar que existen otras herramientas nativas de Python, así como bibliotecas de terceros, para aprovechar la potencia de los mapas hash.
Veamos algunos de los ejemplos más populares.
Cada vez que intentes acceder a una clave que no esté presente en tu diccionario, Python devolverá un KeyError. Una forma de evitarlo es buscar información utilizando el método .get() (buscar en el historial de búsquedas). Sin embargo, una forma optimizada de hacerlo es utilizando Defaultdict, disponible en el módulo collections. Defaultdict y dictionaries son prácticamente iguales. La única diferencia es que Defaultdict nunca genera un error porque proporciona un valor predeterminado para las claves inexistentes.
from collections import defaultdict
# Defining the dict
capitals = defaultdict(lambda: "The key doesn't exist")
capitals['Madrid'] = 'Spain'
capitals['Lisboa'] = 'Portugal'
print(capitals['Madrid'])
print(capitals['Lisboa'])
print(capitals['Ankara'])
# Expected output:
# Spain
# Portugal
# The key doesn't existCounter es una subclase de un diccionario de Python diseñado específicamente para contar objetos hashables. Es un diccionario en el que los elementos se almacenan como claves y sus recuentos se almacenan como valores.
Hay varias formas de inicializar un Counter:
Por una secuencia de elementos.
Por claves y recuentos en un diccionario.
Usando un mapeo de name:value.
from collections import Counter
# a new counter from an iterable
c1 = Counter(['aaa','bbb','aaa','ccc','ccc','aaa'])
# a new counter from a mapping
c2 = Counter({'red': 4, 'blue': 2})
# a new counter from keyword args
c3 = Counter(cats=4, dogs=8)
# print results
print(c1)
print(c2)
print(c3)
# Expected output:
# Counter({'aaa': 3, 'ccc': 2, 'bbb': 1})
# Counter({'red': 4, 'blue': 2})
# Counter({'dogs': 8, 'cats': 4})La clase contador incluye una serie de métodos útiles para realizar cálculos comunes.
print('keys of the counter: ', c3.keys())
print('values of the counter: ',c3.values())
print('list with all elements: ', list(c3.elements()))
print('number of elements: ', c3.total()) # number elements
print('2 most common occurrences: ', c3.most_common(2)) # 2 most common occurrences
# Expected output:
# keys of the counter: dict_keys(['cats', 'dogs'])
# values of the counter: dict_values([4, 8])
# list with all elements: ['cats', 'cats', 'cats', 'cats', 'dogs', 'dogs', 'dogs', 'dogs', 'dogs', 'dogs', 'dogs', 'dogs']
# number of elements: 12
# 2 most common occurrences: [('dogs', 8), ('cats', 4)]Scikit-learn, también conocido como sklearn, es una biblioteca de machine learning de Python robusta y de código abierto. Se creó para ayudar a simplificar el proceso de implementación de modelos estadísticos y de machine learning en Python.
Sklearn incluye varios métodos de hash que pueden resultar muy útiles para los procesos de ingeniería de características.
Uno de los más comunes es el método CountVectorizer (el que lo necesita, lo necesita). Se utiliza para transformar un texto dado en un vector basado en la frecuencia de cada palabra que aparece en todo el texto. El análisis de palabras más frecuentes ( CountVectorizer, EWF) es especialmente útil en contextos de análisis de texto.
from sklearn.feature_extraction.text import CountVectorizer
import pandas as pd
documents = ["Welcome to this new DataCamp Python course",
"Welcome to this new DataCamp R skill track",
"Welcome to this new DataCamp Data Analyst career track"]
# Create a Vectorizer Object
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(documents)
# print unique values
print('unique words: ', vectorizer.get_feature_names_out())
# print sparse matrix with word frequency
pd.DataFrame(X.toarray(), columns = vectorizer.get_feature_names_out())
# Expected output:
# unique words: ['analyst' 'career' 'course' 'data' 'datacamp' 'new' 'python' 'skill'
# 'this' 'to' 'track' 'welcome']
Hay otros métodos de hash en sklearn, entre ellos FeatureHasher y DictVectorizer. Nuestro caso práctico Presupuestos escolares con machine learning en Python es un excelente ejemplo en el que puedes aprender cómo funcionan en la práctica.
Enhorabuena por haber completado este tutorial sobre mapas hash. Esperamos que ahora comprendas mejor los mapas hash y los diccionarios de Python. Si deseas obtener más información sobre los diccionarios y cómo utilizarlos en situaciones reales, te recomendamos encarecidamente que leas nuestro tutorial dedicado a los diccionarios de Python, así como nuestro tutorial sobre la comprensión de diccionarios de Python.
Por último, si acabas de empezar con Python y deseas aprender más, realiza el curso Introducción a la ciencia de datos en Python de DataCamp y consulta nuestro Tutorial de Python para principiantes.
¡Comienza hoy mismo tu aventura con Python!
programa
Curso
Curso
Tutorial
Sejal Jaiswal
Tutorial
Moez Ali
Tutorial
Sejal Jaiswal
Tutorial
DataCamp Team
Tutorial
Neetika Khandelwal
Tutorial
Aditya Sharma
