
Programa
Desenvolvedor Python
28 h
Quando os profissionais de dados falam sobre armazenamento de dados hoje em dia, na maioria das vezes, eles se referem ao local onde os dados são armazenados, sejam arquivos locais, bancos de dados SQL ou nosql, ou a nuvem. Mas, outro ponto importante sobre o armazenamento de dados é como eles são guardados.
A forma como os dados são armazenados geralmente acontece em um nível mais básico, bem no meio das linguagens de programação. Tem a ver com o design das ferramentas que usamos, e não com a forma como as usamos. Mas, saber como os dados são armazenados é essencial para entender os mecanismos que fazem tudo funcionar. Além disso, esse conhecimento pode nos ajudar a tomar melhores decisões para melhorar o desempenho da computação.
Se você está realmente interessado em hashmaps, bem como em listas vinculadas, pilhas, filas e gráficos, inscreva-se no DataCamp para poder fazer nosso curso Estruturas de Dados e Algoritmos em Python.
Pra definir um hash map, primeiro a gente precisa entender o que é hash. Hashing é o processo de transformar qualquer chave ou sequência de caracteres em outro valor. O resultado é normalmente um valor mais curto e de comprimento fixo, que torna mais fácil trabalhar com ele do que com a chave original.
Hashmaps, também conhecidas como hashtables, são uma das formas mais comuns de usar o hashing. Os hashmaps guardam pares de chave-valor (por exemplo, ID do funcionário e nome do funcionário) numa lista que dá para acessar através do seu índice. A gente pode dizer que um hash associativo ( ) é uma estrutura de dados que usa técnicas de hash pra guardar dados de um jeito associativo. São estruturas de dados otimizadas que permitem operações de dados mais rápidas, incluindo inserção, exclusão e pesquisa.
A ideia por trás dos hashmaps é distribuir as entradas (pares chave/valor) por uma matriz de buckets. Dada uma chave, uma função hash vai calcular um índice diferente que sugere onde a entrada pode ser encontrada. Usar um índice em vez da chave original faz com que os hashmaps sejam super legais para várias operações de dados, tipo inserir, remover e procurar dados.
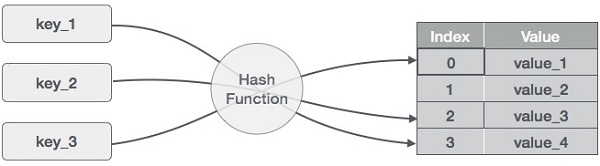
Como funciona um hash map. Imagem do autor
Para calcular o valor hash, ou simplesmente hash, uma função hash gera novos valores de acordo com um algoritmo matemático de hash. Como os pares chave-valor são, em teoria, ilimitados, a função hash vai mapear as chaves com base no tamanho de uma tabela.
Tem várias funções hash disponíveis, cada uma com suas vantagens e desvantagens. O principal objetivo de uma função hash é sempre devolver o mesmo valor para a mesma entrada.
Os mais comuns são os seguintes:
O Python implementa hashmaps por meio do tipo de dados dicionário integrado. Assim como os hashmaps, os dicionários guardam dados em pares de {key:value}. Depois de criar o dicionário (veja a próxima seção), o Python vai aplicar uma função hash bem prática nos bastidores para calcular o hash de cada chave.
Os dicionários Python têm as seguintes características:
Então, se você já se perguntou sobre as diferenças entre hashmaps e dicionários, a resposta é simples. Um dicionário é só a implementação nativa do Python de mapas de hash. Enquanto um hash map é uma estrutura de dados que pode ser criada usando várias técnicas de hash, um dicionário é um hash map específico, baseado em Python, cujo design e comportamento são especificados na classe dict do Python.
Muitas linguagens de programação modernas, como Python, Java e C++, suportam hashmaps. Em Python, os hashmaps são implementados por meio de dicionários, uma estrutura de dados bem usada que você provavelmente já conhece. Nas seções a seguir, vamos falar sobre o básico dos dicionários, como eles funcionam e como implementá-los usando diferentes pacotes Python.
Vamos ver algumas das operações mais comuns do dicionário. Pra saber mais sobre como usar dicionários, dá uma olhada no nosso Tutorial de Dicionários Python.
Criar dicionários em Python é bem simples. Você só precisa usar chaves e colocar os pares de chave-valor separados por vírgulas. Como alternativa, você pode usar a função integrada dict(). Vamos criar um dicionário que mapeia capitais para países:
# Create dictionary
dictionary_capitals = {'Madrid': 'Spain', 'Lisboa': 'Portugal', 'London': 'United Kingdom'}
# Print the content of the dictionary
print(dictionary_capitals)
# Expected output:
# {'Madrid': 'Spain', 'Lisboa': 'Portugal', 'London': 'United Kingdom'}É importante lembrar que uma chave precisa ser única em um dicionário; não pode ter duplicatas. Mas, se tiver chaves duplicadas, em vez de dar um erro, o Python vai considerar a última instância da chave como válida e simplesmente ignorar o primeiro par chave-valor. Dá uma olhada:
dictionary_capitals = {'Madrid': 'China', 'Lisboa': 'Portugal',
'London': 'United Kingdom','Madrid':'Spain'}
print(dictionary_capitals)
# Expected output:
# {'Madrid': 'Spain', 'Lisboa': 'Portugal', 'London': 'United Kingdom'}Pra procurar informações no nosso dicionário, a gente precisa colocar a chave entre colchetes, e o Python vai mostrar o valor que tá associado, assim:
# Search for data
print(dictionary_capitals['Madrid'])
# Expected output: SpainSe você tentar acessar uma chave que não está no dicionário, o Python vai mostrar um erro. Para evitar isso, você pode acessar as chaves usando o método .get(). Se a chave não existir, só vai devolver um valor None:
print(dictionary_capitals.get('Prague'))
# Expected output: NoneVamos adicionar um novo par capital-país:
# Create a new key-value pair
dictionary_capitals['Berlin'] = 'Italy'
print(dictionary_capitals)
# Expected output:
# {'Madrid': 'Spain', 'Lisboa': 'Portugal', 'London': 'United Kingdom', 'Berlin': 'Italy'}A mesma sintaxe pode ser usada para atualizar o valor associado a uma chave. Vamos corrigir o valor associado a Berlim:
# Update the value of a key
dictionary_capitals['Berlin'] = 'Germany'
print(dictionary_capitals)
# Expected output:
# {'Madrid': 'Spain', 'Lisboa': 'Portugal', 'London': 'United Kingdom', 'Berlin': 'Germany'}Agora vamos apagar um dos pares do nosso dicionário
# Delete key-value pair
del dictionary_capitals['Lisboa']
print(dictionary_capitals)
# Expected output:
# {'Madrid': 'Spain', 'London': 'United Kingdom', 'Berlin': 'Germany'}Ou, se você quisesse apagar todos os pares chave-valor do dicionário, poderia usar o método .clear():
dictionary_capitals.clear()
print(dictionary_capitals)
# Expected output: {}Se você quiser pegar todos os pares de chave-valor, use o método .items(), e o Python vai trazer uma lista iterável de tuplas:
dictionary_capitals = {'Madrid': 'Spain', 'Lisboa': 'Portugal',
'London': 'United Kingdom', 'Berlin': 'Germany'}
print(dictionary_capitals.items())
# Expected output:
# dict_items([('Madrid', 'Spain'), ('Lisboa', 'Portugal'),
# ('London', 'United Kingdom'), ('Berlin', 'Germany')])# Iterate over key-value pairs
for key, value in dictionary_capitals.items():
print('the capital of {} is {}'.format(value, key))
# Expected output:
# the capital of Spain is Madrid
# the capital of Portugal is Lisboa
# the capital of United Kingdom is London
# the capital of Germany is BerlinDa mesma forma, se você quiser pegar uma lista iterável com as chaves e valores, pode usar os métodos .keys() e .values(), respectivamente:
print(dictionary_capitals.keys())
# Expected output:
# dict_keys(['Madrid', 'Lisboa', 'London', 'Berlin'])for key in dictionary_capitals.keys():
print(key.upper())
# Expected output:
# MADRID
# LISBOA
# LONDON
# BERLINprint(dictionary_capitals.values())
# Expected output:
# dict_values(['Spain', 'Portugal', 'United Kingdom', 'Germany'])for value in dictionary_capitals.values():
print(value.upper())
# Expected output:
# SPAIN
# PORTUGAL
# UNITED KINGDOM
# GERMANYHashmaps são estruturas de dados poderosas que são usadas em quase todos os lugares no mundo digital. Abaixo você encontra uma lista de aplicações reais de hashmaps:
Hashmaps são estruturas de dados super versáteis e eficientes. Mas, eles também têm problemas e limitações. Para lidar com os desafios comuns associados aos hashmaps, é importante ter em mente algumas considerações e boas práticas.
Isso faz sentido: se o conteúdo da chave mudar, a função hash vai devolver um hash diferente, então o Python não vai conseguir encontrar o valor associado à chave.
O hash só funciona se cada item for mapeado para um local exclusivo na tabela hash. Mas, às vezes, as funções hash podem dar o mesmo resultado para entradas diferentes. Por exemplo, se você estiver usando uma função hash de divisão, diferentes números inteiros podem ter a mesma função hash (eles podem retornar o mesmo resto ao aplicar a divisão modular), criando assim um problema chamado colisão. As colisões precisam ser resolvidas, e tem várias técnicas pra isso. Por sorte, no caso dos dicionários, o Python cuida das possíveis colisões nos bastidores.
O fator de carga é a relação entre o número de elementos na tabela e o número total de compartimentos. É uma forma de ver se os dados estão bem distribuídos. Como regra geral, quanto mais uniformemente os dados estiverem distribuídos, menor será a probabilidade de colisões. Mais uma vez, no caso dos dicionários, o Python adapta automaticamente o tamanho da tabela quando você adiciona ou remove novos pares chave-valor.
Uma boa função hash minimizaria o número de colisões, seria fácil de calcular e distribuiria uniformemente os itens na tabela hash. Isso pode ser feito aumentando o tamanho da tabela ou a complexidade da função hash. Embora isso seja prático para um número pequeno de itens, não é viável quando o número de itens possíveis é grande, pois resultaria em hashmaps que consomem muita memória e são menos eficientes.
Os dicionários são ótimos, mas outras estruturas de dados podem ser mais adequadas para seus dados e necessidades específicas. No fim das contas, os dicionários não suportam operações comuns, como indexação, segmentação e concatenação, o que os torna menos flexíveis e mais difíceis de trabalhar em certos cenários.
Como já falamos, o Python usa hash maps com dicionários embutidos. Mas é importante lembrar que tem outras ferramentas nativas do Python, além de bibliotecas de terceiros, pra aproveitar o poder dos hashmaps.
Vamos ver alguns dos exemplos mais populares.
Toda vez que você tentar acessar uma chave que não está no seu dicionário, o Python vai mostrar um KeyError. Uma maneira de evitar isso é procurar informações usando o método .get(). Mas, uma maneira mais legal de fazer isso é usando o Defaultdict, que tá disponível no módulo collections. Defaultdict e os dicionários são quase iguais. A única diferença é que Defaultdict nunca gera um erro porque fornece um valor padrão para chaves inexistentes.
from collections import defaultdict
# Defining the dict
capitals = defaultdict(lambda: "The key doesn't exist")
capitals['Madrid'] = 'Spain'
capitals['Lisboa'] = 'Portugal'
print(capitals['Madrid'])
print(capitals['Lisboa'])
print(capitals['Ankara'])
# Expected output:
# Spain
# Portugal
# The key doesn't existCounter é uma subclasse de um dicionário Python que foi criada especialmente para contar objetos hashable. É um dicionário onde os elementos são guardados como chaves e suas contagens são guardadas como valores.
Tem várias maneiras de inicializar um Counter:
Por uma sequência de itens.
Por chaves e contagens em um dicionário.
Usando o mapeamento name:value.
from collections import Counter
# a new counter from an iterable
c1 = Counter(['aaa','bbb','aaa','ccc','ccc','aaa'])
# a new counter from a mapping
c2 = Counter({'red': 4, 'blue': 2})
# a new counter from keyword args
c3 = Counter(cats=4, dogs=8)
# print results
print(c1)
print(c2)
print(c3)
# Expected output:
# Counter({'aaa': 3, 'ccc': 2, 'bbb': 1})
# Counter({'red': 4, 'blue': 2})
# Counter({'dogs': 8, 'cats': 4})A classe counter vem com vários métodos úteis para fazer cálculos comuns.
print('keys of the counter: ', c3.keys())
print('values of the counter: ',c3.values())
print('list with all elements: ', list(c3.elements()))
print('number of elements: ', c3.total()) # number elements
print('2 most common occurrences: ', c3.most_common(2)) # 2 most common occurrences
# Expected output:
# keys of the counter: dict_keys(['cats', 'dogs'])
# values of the counter: dict_values([4, 8])
# list with all elements: ['cats', 'cats', 'cats', 'cats', 'dogs', 'dogs', 'dogs', 'dogs', 'dogs', 'dogs', 'dogs', 'dogs']
# number of elements: 12
# 2 most common occurrences: [('dogs', 8), ('cats', 4)]O Scikit-learn, também conhecido como sklearn, é uma biblioteca de machine learning Python robusta e de código aberto. Foi criado para ajudar a simplificar o processo de implementação de machine learning e modelos estatísticos em Python.
O Sklearn vem com vários métodos de hash que podem ser bem úteis para processos de engenharia de recursos.
Um dos mais comuns é o método CountVectorizer. É usado pra transformar um texto em um vetor com base na frequência de cada palavra que aparece no texto todo. O CountVectorizer é super útil pra analisar textos.
from sklearn.feature_extraction.text import CountVectorizer
import pandas as pd
documents = ["Welcome to this new DataCamp Python course",
"Welcome to this new DataCamp R skill track",
"Welcome to this new DataCamp Data Analyst career track"]
# Create a Vectorizer Object
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(documents)
# print unique values
print('unique words: ', vectorizer.get_feature_names_out())
# print sparse matrix with word frequency
pd.DataFrame(X.toarray(), columns = vectorizer.get_feature_names_out())
# Expected output:
# unique words: ['analyst' 'career' 'course' 'data' 'datacamp' 'new' 'python' 'skill'
# 'this' 'to' 'track' 'welcome']
Tem outros métodos de hash no sklearn, tipo FeatureHasher e DictVectorizer. Nosso estudo de caso Orçamento escolar com machine learning em Python é um ótimo exemplo onde você pode aprender como eles funcionam na prática.
Parabéns por terminar este tutorial sobre hashmaps. Esperamos que agora você tenha uma melhor compreensão dos hashmaps e dos dicionários Python. Se você quiser saber mais sobre dicionários e como usá-los em situações reais, a gente recomenda que você dê uma olhada no nosso Tutorial sobre Dicionários Python, além do Tutorial sobre Compreensão de Dicionários Python.
Por fim, se você está começando a usar Python e quer saber mais, faça o curso Introdução à Ciência de Dados em Python do DataCamp e dê uma olhada no nosso Tutorial de Python para Iniciantes.
Comece sua jornada com Python hoje mesmo!
Programa
Curso
Curso
Tutorial
Sejal Jaiswal
Tutorial
Sejal Jaiswal
Tutorial
Neetika Khandelwal
Tutorial
Aditya Sharma
Tutorial
Moez Ali
Tutorial
Samuel Shaibu

