
Track
Python Developer
28 hr
When data practitioners speak about data storage today, most of the time, they refer to where the data is stored, whether local files, SQL or NoSQL databases, or the cloud. However, another important aspect related to data storage is how data is stored.
The how of data storage often takes place at a lower level, at the very core of programming languages. It has to do with the design of the tools we use rather than how to use these tools. Yet, knowing how data is stored is critical to understanding the underlying mechanisms that make work possible. What’s more, this knowledge can help us make better decisions to improve computing performance.
If you are really interested in hashmaps, as well as linked lists, stacks, queues, and graphs, sign up with DataCamp so you can take our Data Structures and Algorithms in Python course.
To define a hashmap, we first need to understand what hashing is. Hashing is the process of transforming any given key or a string of characters into another value. The result is normally a shorter, fixed-length value that makes it computationally easier to work with than the original key.
Hashmaps, also known as hashtables, represent one of the most common implementations of hashing. Hashmaps stores key-value pairs (e.g., employee ID and employee name) in a list that is accessible through its index. We could say that a hashmap is a data structure that leverages hashing techniques to store data in an associative fashion. They are optimized data structures that allow faster data operations, including insertion, deletion, and search.
The idea behind hashmaps is to distribute the entries (key/value pairs) across an array of buckets. Given a key, a hashing function will compute a distinct index that suggests where the entry can be found. The use of an index instead of the original key makes hashmaps particularly well-suited for multiple data operations, including data insertion, removal, and search.
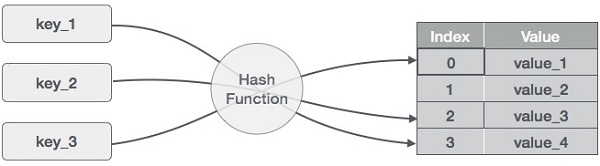
How a hashmap works. Image by Author
To compute the hash value, or simply hash, a hash function generates new values according to a mathematical hashing algorithm. Since key-value pairs are, in theory, unlimited, the hashing function will map the keys based on a given table size.
There are multiple hash functions available, each of them with its pros and cons. The main goal of a hash function is to always return the same value for the same input.
The most common are the following:
Python implements hashmaps through the built-in dictionary data type. Like hashmaps, dictionaries store data in {key:value} pairs. Once you create the dictionary (see the next section), Python will apply a convenient hash function under the hood to calculate the hash of every key.
Python dictionaries come with the following features:
So, if you have ever wondered about the differences between hashmaps vs dictionaries, the answer is simple. A dictionary is just Python's native implementation of hashmaps. While a hashmap is a data structure that can be created using multiple hashing techniques, a dictionary is a particular, Python-based hashmap, whose design and behavior are specified in the Python's dict class.
Many modern programming languages, such as Python, Java, and C++, support hashmaps. In Python, hashmaps are implemented through dictionaries, a widely used data structure that you will probably know about. In the following sections, we will cover the basics of dictionaries, how they work, and how to implement them using different Python packages.
Let’s see some of the most common dictionary operations. To know more about how to use dictionaries, check out our Python Dictionaries Tutorial.
Creating dictionaries in Python is pretty simple. You just have to use curly braces and insert the key-value pairs separated by commas. Alternatively, you can use the built-in dict() function. Let’s create a dictionary that maps capitals to countries:
# Create dictionary
dictionary_capitals = {'Madrid': 'Spain', 'Lisboa': 'Portugal', 'London': 'United Kingdom'}
# Print the content of the dictionary
print(dictionary_capitals)
# Expected output:
# {'Madrid': 'Spain', 'Lisboa': 'Portugal', 'London': 'United Kingdom'}It's important to remember that a key has to be unique in a dictionary; no duplicates are allowed. However, in case of duplicate keys, rather than giving an error, Python will take the last instance of the key to be valid and simply ignore the first key-value pair. See it for yourself:
dictionary_capitals = {'Madrid': 'China', 'Lisboa': 'Portugal',
'London': 'United Kingdom','Madrid':'Spain'}
print(dictionary_capitals)
# Expected output:
# {'Madrid': 'Spain', 'Lisboa': 'Portugal', 'London': 'United Kingdom'}To search for information in our dictionary, we need to specify the key in brackets, and Python will return the associated value, as follows:
# Search for data
print(dictionary_capitals['Madrid'])
# Expected output: SpainIf you try to access a key that is not present in the dictionary, Python will throw an error. To prevent this, you can alternatively access keys using the .get() method. In case of a nonexistent key, will just return a None value:
print(dictionary_capitals.get('Prague'))
# Expected output: NoneLet’s add a new capital-country pair:
# Create a new key-value pair
dictionary_capitals['Berlin'] = 'Italy'
print(dictionary_capitals)
# Expected output:
# {'Madrid': 'Spain', 'Lisboa': 'Portugal', 'London': 'United Kingdom', 'Berlin': 'Italy'}The same syntax can be used to update the value associated with a key. Let’s fix the value associated with Berlin:
# Update the value of a key
dictionary_capitals['Berlin'] = 'Germany'
print(dictionary_capitals)
# Expected output:
# {'Madrid': 'Spain', 'Lisboa': 'Portugal', 'London': 'United Kingdom', 'Berlin': 'Germany'}Now let’s delete one of the pairs in our dictionary
# Delete key-value pair
del dictionary_capitals['Lisboa']
print(dictionary_capitals)
# Expected output:
# {'Madrid': 'Spain', 'London': 'United Kingdom', 'Berlin': 'Germany'}Or, if you were to delete all the key-value pairs in the dictionary, you could use the .clear() method:
dictionary_capitals.clear()
print(dictionary_capitals)
# Expected output: {}If you want to retrieve all the key-value pairs, use the .items() method, and Python will retrieve an iterable list of tuples:
dictionary_capitals = {'Madrid': 'Spain', 'Lisboa': 'Portugal',
'London': 'United Kingdom', 'Berlin': 'Germany'}
print(dictionary_capitals.items())
# Expected output:
# dict_items([('Madrid', 'Spain'), ('Lisboa', 'Portugal'),
# ('London', 'United Kingdom'), ('Berlin', 'Germany')])# Iterate over key-value pairs
for key, value in dictionary_capitals.items():
print('the capital of {} is {}'.format(value, key))
# Expected output:
# the capital of Spain is Madrid
# the capital of Portugal is Lisboa
# the capital of United Kingdom is London
# the capital of Germany is BerlinEqually, if you want to retrieve an iterable list with the keys and values, you can use the .keys() and .values() methods, respectively:
print(dictionary_capitals.keys())
# Expected output:
# dict_keys(['Madrid', 'Lisboa', 'London', 'Berlin'])for key in dictionary_capitals.keys():
print(key.upper())
# Expected output:
# MADRID
# LISBOA
# LONDON
# BERLINprint(dictionary_capitals.values())
# Expected output:
# dict_values(['Spain', 'Portugal', 'United Kingdom', 'Germany'])for value in dictionary_capitals.values():
print(value.upper())
# Expected output:
# SPAIN
# PORTUGAL
# UNITED KINGDOM
# GERMANYHashmaps are powerful data structures that are used nearly everywhere in the digital world. Below you can find a list of real-world applications of hashmaps:
Hashmaps are incredibly versatile and efficient data structures. However, they also come with problems and limitations. To address the common challenges associated with hashmaps, it’s important to keep in mind some considerations and good practices.
This makes sense: if the content of the key changes, the hash function will return a different hash, so Python won’t be able to find the value associated with the key.
Hashing only works if each item maps to a unique location in the hash table. But sometimes, hash functions can return the same output for different inputs. For example, if you’re using a division hash function, different integers may have the same hash function (they may return the same remainder when applying the module division), thereby creating a problem called collision. Collisions must be resolved, and several techniques exist. Luckily, in the case of dictionaries, Python handles potential collisions under the hood.
The load factor is defined as the ratio of the number of elements in the table to the total number of buckets. It’s a measure to estimate how well-distributed the data is. As a rule of thumb, the more evenly the data is distributed, the less likelihood of collisions. Again, in the case of dictionaries, Python automatically adapts the table size in case of new key-value pair insertions or deletions.
A good hash function would minimize the number of collisions, be easy to compute, and evenly distribute the items in the hash table. This could be done by increasing the table size or the complexity of the hash function. Although this is practical for small numbers of items, it is not feasible when the number of possible items is large, as it would result in memory-consuming, less efficient hashmaps.
Dictionaries are great, but other data structures may be more suitable for your specific data and needs. In the end, dictionaries do not support common operations, such as indexing, slicing, and concatenation, making them less flexible and more difficult to work with in certain scenarios.
As already mentioned, Python implements hashmaps through built-in dictionaries. However, it’s important to note that there are other native Python tools, as well as third-party libraries, to leverage the power of hashmaps.
Let’s see some of the most popular examples.
Every time you try to access a key that is not present in your dictionary, Python will return a KeyError. A way to prevent this is by searching for information using the .get() method. However, an optimized way to do that is by using Defaultdict, available in the module collections. Defaultdict and dictionaries are almost the same. The sole difference is that Defaultdict never raises an error because it provides a default value for non-existent keys.
from collections import defaultdict
# Defining the dict
capitals = defaultdict(lambda: "The key doesn't exist")
capitals['Madrid'] = 'Spain'
capitals['Lisboa'] = 'Portugal'
print(capitals['Madrid'])
print(capitals['Lisboa'])
print(capitals['Ankara'])
# Expected output:
# Spain
# Portugal
# The key doesn't existCounter is a subclass of a Python dictionary that is specifically designed for counting hashable objects. It’s a dictionary where elements are stored as keys and their counts are stored as values.
There are several ways to initialize Counter:
By a sequence of items.
By keys and counts in a dictionary.
Using name:value mapping.
from collections import Counter
# a new counter from an iterable
c1 = Counter(['aaa','bbb','aaa','ccc','ccc','aaa'])
# a new counter from a mapping
c2 = Counter({'red': 4, 'blue': 2})
# a new counter from keyword args
c3 = Counter(cats=4, dogs=8)
# print results
print(c1)
print(c2)
print(c3)
# Expected output:
# Counter({'aaa': 3, 'ccc': 2, 'bbb': 1})
# Counter({'red': 4, 'blue': 2})
# Counter({'dogs': 8, 'cats': 4})The counter class comes with a series of handy methods to make common calculations.
print('keys of the counter: ', c3.keys())
print('values of the counter: ',c3.values())
print('list with all elements: ', list(c3.elements()))
print('number of elements: ', c3.total()) # number elements
print('2 most common occurrences: ', c3.most_common(2)) # 2 most common occurrences
# Expected output:
# keys of the counter: dict_keys(['cats', 'dogs'])
# values of the counter: dict_values([4, 8])
# list with all elements: ['cats', 'cats', 'cats', 'cats', 'dogs', 'dogs', 'dogs', 'dogs', 'dogs', 'dogs', 'dogs', 'dogs']
# number of elements: 12
# 2 most common occurrences: [('dogs', 8), ('cats', 4)]Scikit-learn, also known as sklearn, is an open-source, robust Python machine learning library. It was created to help simplify the process of implementing machine learning and statistical models in Python.
Sklearn comes with various hashing methods that can be very useful for feature engineering processes.
One of the most common is the CountVectorizer method. It is used to transform a given text into a vector based on the frequency of each word that occurs in the entire text. CountVectorizer is particularly helpful in text analysis contexts.
from sklearn.feature_extraction.text import CountVectorizer
import pandas as pd
documents = ["Welcome to this new DataCamp Python course",
"Welcome to this new DataCamp R skill track",
"Welcome to this new DataCamp Data Analyst career track"]
# Create a Vectorizer Object
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(documents)
# print unique values
print('unique words: ', vectorizer.get_feature_names_out())
# print sparse matrix with word frequency
pd.DataFrame(X.toarray(), columns = vectorizer.get_feature_names_out())
# Expected output:
# unique words: ['analyst' 'career' 'course' 'data' 'datacamp' 'new' 'python' 'skill'
# 'this' 'to' 'track' 'welcome']
There are other hashing methods in sklearn, including FeatureHasher and DictVectorizer. Our School Budgeting with Machine Learning in Python case study is a great example where you can learn how they work in practice.
Congratulations on finishing this tutorial on hashmaps. We hope you now have a better understanding of hashmaps and Python dictionaries. If you feel you want to learn more about dictionaries and how to use them in real scenarios, we highly recommend you to read our dedicated Python Dictionaries Tutorial, as well as our Python Dictionary Comprehension Tutorial.
Finally, If you are just getting started in Python and would like to learn more, take DataCamp's Introduction to Data Science in Python course and check out our Python Tutorial for Beginners.
Start Your Python Journey Today!
Track
Course
Course
Tutorial
Aditya Sharma
Tutorial
Rajesh Kumar
Tutorial
Austin Chia
Tutorial
DataCamp Team
Tutorial
Rajesh Kumar

