
Cursus
Développeur Python
28 h
Lorsque les professionnels des données évoquent aujourd'hui le stockage des données, ils font généralement référence à l'emplacement où les données sont stockées, qu'il s'agisse de fichiers locaux, de bases de données SQL ou nosql, ou du cloud. Cependant, un autre aspect important lié au stockage des données concerne la manière dont celles-ci sont stockées.
Le mode de stockage des données se déroule souvent à un niveau inférieur, au cœur même des langages de programmation. Cela concerne la conception des outils que nous utilisons plutôt que la manière de les utiliser. Cependant, il est essentiel de comprendre comment les données sont stockées pour appréhender les mécanismes sous-jacents qui rendent le travail possible. De plus, ces connaissances peuvent nous aider à prendre de meilleures décisions pour améliorer les performances informatiques.
Si vous êtes véritablement intéressé par les hachages associatifs, ainsi que par les listes chaînées, les piles, les files d'attente et les graphes, nous vous invitons à vous inscrire sur DataCamp afin de suivre notre cours sur les structures de données et les algorithmes en Python.
Pour définir une table de hachage, il est nécessaire de comprendre ce qu'est le hachage. Le hachage est le processus qui consiste à transformer une clé ou une chaîne de caractères donnée en une autre valeur. Le résultat est généralement une valeur plus courte et de longueur fixe, qui facilite les calculs par rapport à la clé d'origine.
Les tables de hachage, également appelées hashtables, constituent l'une des implémentations les plus courantes du hachage. Les tables de hachage stockent des paires clé-valeur (par exemple, l'identifiant et le nom d'un employé) dans une liste accessible via son index. Nous pourrions dire qu'une table de hachage est une structure de données qui utilise des techniques de hachage pour stocker des données de manière associative. Il s'agit de structures de données optimisées qui permettent des opérations plus rapides, notamment l'insertion, la suppression et la recherche.
Le principe des hashmaps consiste à répartir les entrées (paires clé/valeur) dans un ensemble de compartiments. À partir d'une clé, une fonction de hachage calcule un index distinct qui indique où l'entrée peut être trouvée. L'utilisation d'un index à la place de la clé d'origine rend les tables de hachage particulièrement adaptées aux opérations multiples sur les données, notamment l'insertion, la suppression et la recherche de données.
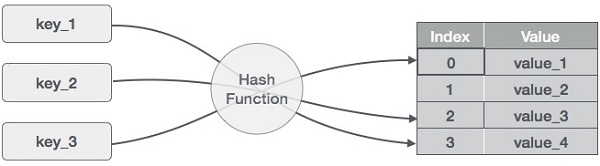
Fonctionnement d'une table de hachage. Image par l'auteur
Pour calculer la valeur de hachage, ou simplement le hachage, une fonction de hachage génère de nouvelles valeurs selon un algorithme mathématique de hachage. Étant donné que les paires clé-valeur sont, en théorie, illimitées, la fonction de hachage mappera les clés en fonction d'une taille de tableau donnée.
Il existe plusieurs fonctions de hachage, chacune présentant ses avantages et ses inconvénients. L'objectif principal d'une fonction de hachage est de toujours renvoyer la même valeur pour une même entrée.
Les plus courants sont les suivants :
Python implémente les tables de hachage via le type de données intégré « dictionnaire ». {key:value} À l'instar des hachages, les dictionnaires stockent les données sous forme de paires clé-valeur. Une fois le dictionnaire créé (voir la section suivante), Python appliquera une fonction de hachage pratique en arrière-plan pour calculer le hachage de chaque clé.
Les dictionnaires Python présentent les caractéristiques suivantes :
Si vous vous êtes déjà interrogé sur les différences entre les hashmaps et les dictionnaires, la réponse est simple. Un dictionnaire est simplement l'implémentation native des tables de hachage en Python. Alors qu'une table de hachage est une structure de données pouvant être créée à l'aide de plusieurs techniques de hachage, un dictionnaire est une table de hachage spécifique basée sur Python, dont la conception et le comportement sont spécifiés dans la classe dict de Python.
De nombreux langages de programmation modernes, tels que Python, Java et C++, prennent en charge les tables de hachage. En Python, les tables de hachage sont implémentées à l'aide de dictionnaires, une structure de données largement utilisée que vous connaissez probablement déjà. Dans les sections suivantes, nous aborderons les principes fondamentaux des dictionnaires, leur fonctionnement et leur implémentation à l'aide de différents paquets Python.
Examinons quelques-unes des opérations les plus courantes effectuées sur un dictionnaire. Pour en savoir plus sur l'utilisation des dictionnaires, veuillez consulter notre tutoriel sur les dictionnaires Python.
La création de dictionnaires en Python est relativement simple. Il vous suffit d'utiliser des accolades et d'insérer les paires clé-valeur séparées par des virgules. Vous pouvez également utiliser la fonction intégrée dict(). Créons un dictionnaire qui associe les capitales aux pays :
# Create dictionary
dictionary_capitals = {'Madrid': 'Spain', 'Lisboa': 'Portugal', 'London': 'United Kingdom'}
# Print the content of the dictionary
print(dictionary_capitals)
# Expected output:
# {'Madrid': 'Spain', 'Lisboa': 'Portugal', 'London': 'United Kingdom'}Il est important de noter qu'une clé doit être unique dans un dictionnaire ; aucun doublon n'est autorisé. Cependant, en cas de clés en double, plutôt que de générer une erreur, Python considérera la dernière instance de la clé comme valide et ignorera simplement la première paire clé-valeur. Veuillez constater par vous-même :
dictionary_capitals = {'Madrid': 'China', 'Lisboa': 'Portugal',
'London': 'United Kingdom','Madrid':'Spain'}
print(dictionary_capitals)
# Expected output:
# {'Madrid': 'Spain', 'Lisboa': 'Portugal', 'London': 'United Kingdom'}Pour rechercher des informations dans notre dictionnaire, nous devons spécifier la clé entre parenthèses, et Python renverra la valeur associée, comme suit :
# Search for data
print(dictionary_capitals['Madrid'])
# Expected output: SpainSi vous tentez d'accéder à une clé qui n'est pas présente dans le dictionnaire, Python générera une erreur. Pour éviter cela, vous pouvez également accéder aux clés à l'aide de la méthode .get(). Si la clé n'existe pas, la fonction renvoie simplement la valeur None :
print(dictionary_capitals.get('Prague'))
# Expected output: NoneAjoutons une nouvelle paire capitale-pays :
# Create a new key-value pair
dictionary_capitals['Berlin'] = 'Italy'
print(dictionary_capitals)
# Expected output:
# {'Madrid': 'Spain', 'Lisboa': 'Portugal', 'London': 'United Kingdom', 'Berlin': 'Italy'}La même syntaxe peut être utilisée pour mettre à jour la valeur associée à une clé. Veuillez corriger la valeur associée à Berlin :
# Update the value of a key
dictionary_capitals['Berlin'] = 'Germany'
print(dictionary_capitals)
# Expected output:
# {'Madrid': 'Spain', 'Lisboa': 'Portugal', 'London': 'United Kingdom', 'Berlin': 'Germany'}Supprimons maintenant l'une des paires de notre dictionnaire.
# Delete key-value pair
del dictionary_capitals['Lisboa']
print(dictionary_capitals)
# Expected output:
# {'Madrid': 'Spain', 'London': 'United Kingdom', 'Berlin': 'Germany'}Ou, si vous souhaitez supprimer toutes les paires clé-valeur du dictionnaire, vous pouvez utiliser la méthode .clear():
dictionary_capitals.clear()
print(dictionary_capitals)
# Expected output: {}Si vous souhaitez récupérer toutes les paires clé-valeur, veuillez utiliser la méthode .items(), et Python récupérera une liste itérable de tuples :
dictionary_capitals = {'Madrid': 'Spain', 'Lisboa': 'Portugal',
'London': 'United Kingdom', 'Berlin': 'Germany'}
print(dictionary_capitals.items())
# Expected output:
# dict_items([('Madrid', 'Spain'), ('Lisboa', 'Portugal'),
# ('London', 'United Kingdom'), ('Berlin', 'Germany')])# Iterate over key-value pairs
for key, value in dictionary_capitals.items():
print('the capital of {} is {}'.format(value, key))
# Expected output:
# the capital of Spain is Madrid
# the capital of Portugal is Lisboa
# the capital of United Kingdom is London
# the capital of Germany is BerlinDe même, si vous souhaitez récupérer une liste itérable avec les clés et les valeurs, vous pouvez utiliser respectivement les méthodes .keys() et .values():
print(dictionary_capitals.keys())
# Expected output:
# dict_keys(['Madrid', 'Lisboa', 'London', 'Berlin'])for key in dictionary_capitals.keys():
print(key.upper())
# Expected output:
# MADRID
# LISBOA
# LONDON
# BERLINprint(dictionary_capitals.values())
# Expected output:
# dict_values(['Spain', 'Portugal', 'United Kingdom', 'Germany'])for value in dictionary_capitals.values():
print(value.upper())
# Expected output:
# SPAIN
# PORTUGAL
# UNITED KINGDOM
# GERMANYLes tables de hachage sont des structures de données puissantes utilisées dans presque tous les domaines du monde numérique. Vous trouverez ci-dessous une liste d'applications concrètes des tables de hachage :
Les tables de hachage sont des structures de données extrêmement polyvalentes et efficaces. Cependant, ils présentent également des inconvénients et des limites. Afin de relever les défis courants associés aux tables de hachage, il est important de garder à l'esprit certaines considérations et bonnes pratiques.
Cela est logique : si le contenu de la clé change, la fonction de hachage renverra un hachage différent, et Python ne pourra donc pas trouver la valeur associée à la clé.
Le hachage ne fonctionne que si chaque élément est associé à un emplacement unique dans le tableau de hachage. Cependant, il arrive parfois que les fonctions de hachage renvoient le même résultat pour des entrées différentes. Par exemple, si vous utilisez une fonction de hachage par division, différents nombres entiers peuvent avoir la même fonction de hachage (ils peuvent renvoyer le même reste lors de l'application de la division modulaire), ce qui crée un problème appelé collision. Les collisions doivent être résolues, et plusieurs techniques existent. Heureusement, dans le cas des dictionnaires, Python gère les conflits potentiels en arrière-plan.
Le facteur de charge est défini comme le rapport entre le nombre d'éléments dans les tableaux et le nombre total de compartiments. Il s'agit d'une mesure permettant d'évaluer la qualité de la distribution des données. En règle générale, plus les données sont réparties de manière uniforme, moins il y a de risques de collisions. Dans le cas des dictionnaires, Python adapte automatiquement la taille du tableau en cas d'insertion ou de suppression de nouvelles paires clé-valeur.
Une fonction de hachage efficace minimiserait le nombre de collisions, serait facile à calculer et répartirait uniformément les éléments dans le tableau de hachage. Cela pourrait être réalisé en augmentant la taille du tableau ou la complexité de la fonction de hachage. Bien que cela soit pratique pour un petit nombre d'éléments, cela n'est pas envisageable lorsque le nombre d'éléments possibles est important, car cela entraînerait des tables de hachage gourmandes en mémoire et moins efficaces.
Les dictionnaires sont très utiles, mais d'autres structures de données peuvent être plus adaptées à vos données et besoins spécifiques. En fin de compte, les dictionnaires ne prennent pas en charge les opérations courantes telles que l'indexation, le découpage et la concaténation, ce qui les rend moins flexibles et plus difficiles à utiliser dans certains scénarios.
Comme mentionné précédemment, Python implémente les tables de hachage à l'aide de dictionnaires intégrés. Il est toutefois important de noter qu'il existe d'autres outils Python natifs, ainsi que des bibliothèques tierces, permettant de tirer parti de la puissance des tables de hachage.
Examinons quelques-uns des exemples les plus courants.
Chaque fois que vous tentez d'accéder à une clé qui n'est pas présente dans votre dictionnaire, Python renvoie une erreur KeyError. Une méthode pour éviter cela consiste à rechercher des informations en utilisant la méthode de recherche par élimination .get(). Cependant, une méthode optimisée pour y parvenir consiste à utiliser Defaultdict, disponible dans le module collections. Defaultdict et dictionnaires sont pratiquement identiques. La seule différence réside dans le fait que Defaultdict ne génère jamais d'erreur, car il fournit une valeur par défaut pour les clés inexistantes.
from collections import defaultdict
# Defining the dict
capitals = defaultdict(lambda: "The key doesn't exist")
capitals['Madrid'] = 'Spain'
capitals['Lisboa'] = 'Portugal'
print(capitals['Madrid'])
print(capitals['Lisboa'])
print(capitals['Ankara'])
# Expected output:
# Spain
# Portugal
# The key doesn't existCounter est une sous-classe d'un dictionnaire Python spécialement conçu pour compter les objets hachables. Il s'agit d'un dictionnaire dans lequel les éléments sont stockés en tant que clés et leur nombre en tant que valeurs.
Il existe plusieurs méthodes pour initialiser Counter:
Par une séquence d'éléments.
Par clés et nombres dans un dictionnaire.
Utilisation de la cartographie d'name:value.
from collections import Counter
# a new counter from an iterable
c1 = Counter(['aaa','bbb','aaa','ccc','ccc','aaa'])
# a new counter from a mapping
c2 = Counter({'red': 4, 'blue': 2})
# a new counter from keyword args
c3 = Counter(cats=4, dogs=8)
# print results
print(c1)
print(c2)
print(c3)
# Expected output:
# Counter({'aaa': 3, 'ccc': 2, 'bbb': 1})
# Counter({'red': 4, 'blue': 2})
# Counter({'dogs': 8, 'cats': 4})La classe counter est fournie avec une série de méthodes pratiques permettant d'effectuer des calculs courants.
print('keys of the counter: ', c3.keys())
print('values of the counter: ',c3.values())
print('list with all elements: ', list(c3.elements()))
print('number of elements: ', c3.total()) # number elements
print('2 most common occurrences: ', c3.most_common(2)) # 2 most common occurrences
# Expected output:
# keys of the counter: dict_keys(['cats', 'dogs'])
# values of the counter: dict_values([4, 8])
# list with all elements: ['cats', 'cats', 'cats', 'cats', 'dogs', 'dogs', 'dogs', 'dogs', 'dogs', 'dogs', 'dogs', 'dogs']
# number of elements: 12
# 2 most common occurrences: [('dogs', 8), ('cats', 4)]Scikit-learn, également connu sous le nom de sklearn, est une bibliothèque Python open source et robuste dédiée à l'apprentissage automatique. Il a été conçu pour simplifier le processus de mise en œuvre de l'apprentissage automatique et des modèles statistiques en Python.
Sklearn propose diverses méthodes de hachage qui peuvent s'avérer très utiles pour les processus d'ingénierie des caractéristiques.
L'une des méthodes les plus courantes est la méthode de CountVectorizer. Il est utilisé pour transformer un texte donné en un vecteur basé sur la fréquence de chaque mot apparaissant dans l'ensemble du texte. L'analyse de mots fréquents ( CountVectorizer ) est particulièrement utile dans le contexte de l'analyse de texte.
from sklearn.feature_extraction.text import CountVectorizer
import pandas as pd
documents = ["Welcome to this new DataCamp Python course",
"Welcome to this new DataCamp R skill track",
"Welcome to this new DataCamp Data Analyst career track"]
# Create a Vectorizer Object
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(documents)
# print unique values
print('unique words: ', vectorizer.get_feature_names_out())
# print sparse matrix with word frequency
pd.DataFrame(X.toarray(), columns = vectorizer.get_feature_names_out())
# Expected output:
# unique words: ['analyst' 'career' 'course' 'data' 'datacamp' 'new' 'python' 'skill'
# 'this' 'to' 'track' 'welcome']
Il existe d'autres méthodes de hachage dans sklearn, notamment FeatureHasher et DictVectorizer. Notre étude de cas sur la budgétisation scolaire à l'aide du machine learning en Python constitue un excellent exemple qui vous permettra de comprendre comment ces techniques fonctionnent dans la pratique.
Félicitations pour avoir terminé ce tutoriel sur les tables de hachage. Nous espérons que vous comprenez désormais mieux les hashmaps et les dictionnaires Python. Si vous souhaitez approfondir vos connaissances sur les dictionnaires et leur utilisation dans des scénarios réels, nous vous recommandons vivement de consulter notre tutoriel dédié aux dictionnaires Python, ainsi que notre tutoriel sur la compréhension des dictionnaires Python.
Enfin, si vous débutez avec Python et souhaitez approfondir vos connaissances, nous vous recommandons de suivre le cours Introduction à la science des données avec Python proposé par DataCamp et de consulter notre tutoriel Python pour débutants.
Commencez votre parcours Python dès aujourd'hui !
Cursus
Cours
Cours
Tutoriel
Sejal Jaiswal
Tutoriel
Neetika Khandelwal
Tutoriel
DataCamp Team
Tutoriel
Samuel Shaibu
Tutoriel
Abid Ali Awan
Tutoriel
Sejal Jaiswal

