Data Types in Python
BeginnerSkill Level
4 h
67.6K learners
Ejecuta y edita el código de este tutorial en línea
Ejecutar código
Si observa la salida de las variables dataScientist y dataEngineer anteriores, observe que los valores del conjunto no están en el orden en que se añadieron. Esto se debe a que los conjuntos no están ordenados.
Los conjuntos que contienen valores también pueden inicializarse utilizando llaves.
dataScientist = {'Python', 'R', 'SQL', 'Git', 'Tableau', 'SAS'}
dataEngineer = {'Python', 'Java', 'Scala', 'Git', 'SQL', 'Hadoop'}
Tenga en cuenta que las llaves sólo pueden utilizarse para inicializar un conjunto que contenga valores. La siguiente imagen muestra que el uso de llaves sin valores es una de las formas de inicializar un diccionario y no un conjunto.

Para añadir o eliminar valores de un conjunto, primero hay que inicializarlo.
# Initialize set with values
graphicDesigner = {'InDesign', 'Photoshop', 'Acrobat', 'Premiere', 'Bridge'}Puede utilizar el método add para añadir un valor a un conjunto.
graphicDesigner.add('Illustrator')
Es importante tener en cuenta que sólo se puede añadir un valor que sea inmutable (como una cadena o una tupla) a un conjunto. Por ejemplo, obtendrías un TypeError si intentas añadir una lista a un conjunto.
graphicDesigner.add(['Powerpoint', 'Blender'])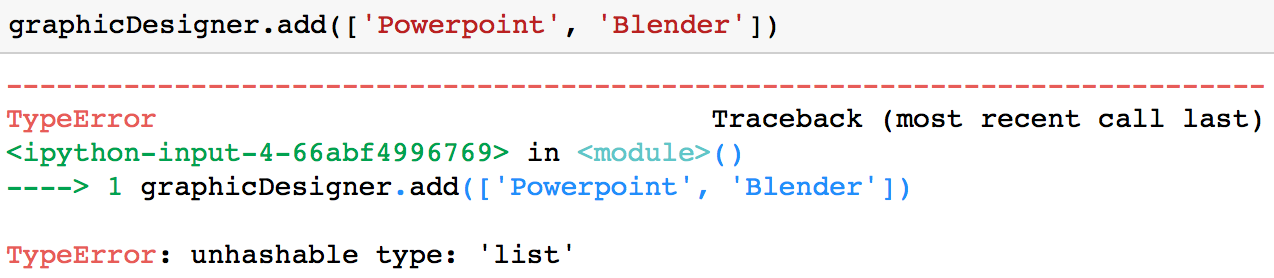
Hay un par de formas de eliminar un valor de un conjunto.
Opción 1: Puede utilizar el método remove para eliminar un valor de un conjunto.
graphicDesigner.remove('Illustrator')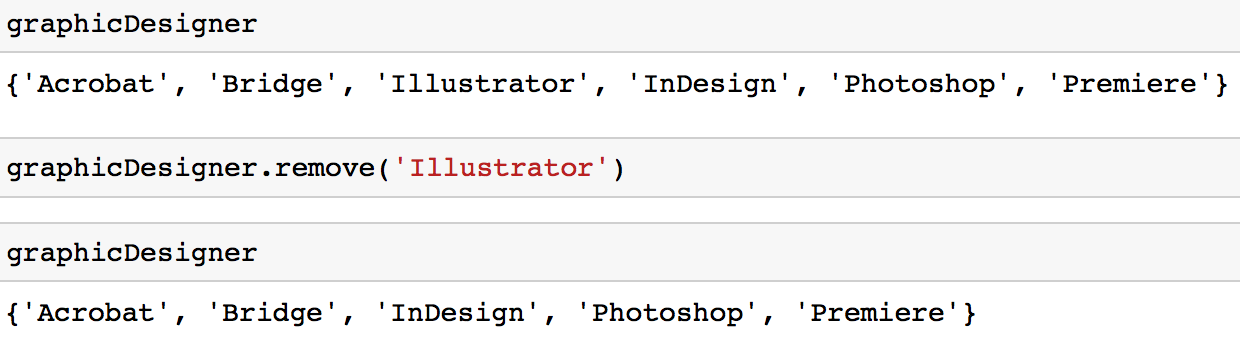
El inconveniente de este método es que si intenta eliminar un valor que no está en su conjunto, obtendrá un KeyError.
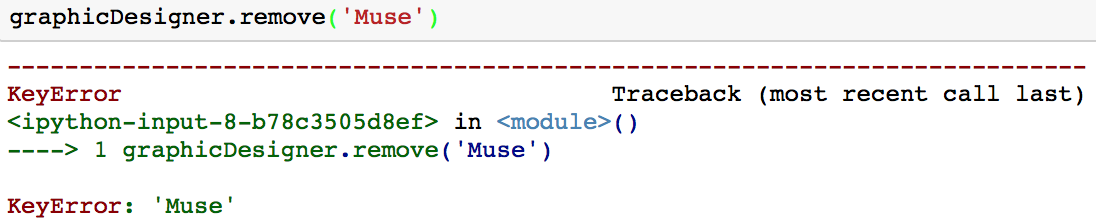
Opción 2: Puede utilizar el método discard para eliminar un valor de un conjunto.
graphicDesigner.discard('Premiere')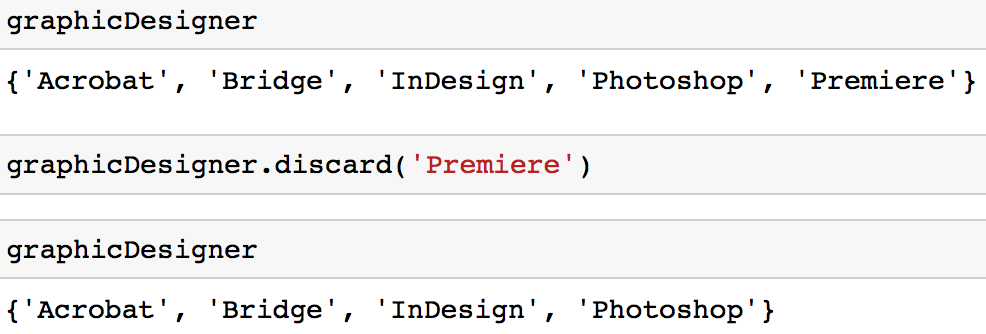
La ventaja de este enfoque sobre el método remove es que si intenta eliminar un valor que no forma parte del conjunto, no obtendrá un KeyError. Si estás familiarizado con los diccionarios, verás que esto funciona de forma similar al método get del diccionario.
Opción 3: También puede utilizar el método pop para eliminar y devolver un valor arbitrario de un conjunto.
graphicDesigner.pop()
Es importante tener en cuenta que el método genera un KeyError si el conjunto está vacío.
Puede utilizar el método clear para eliminar todos los valores de un conjunto.
graphicDesigner.clear()
El método de actualización añade los elementos de un conjunto a un conjunto. Requiere un único argumento que puede ser un conjunto, lista, tuplas o diccionario. El método .update() convierte automáticamente otros tipos de datos en conjuntos y los añade al conjunto.
En el ejemplo, hemos inicializado tres conjuntos y utilizado una función de actualización para añadir elementos del conjunto2 al conjunto1 y luego del conjunto3 al conjunto1.
# Initialize 3 sets
set1 = set([7, 10, 11, 13])
set2 = set([11, 8, 9, 12, 14, 15])
set3 = {'d', 'f', 'h'}
# Update set1 with set2
set1.update(set2)
print(set1)
# Update set1 with set3
set1.update(set3)
print(set1)
Como muchos tipos de datos estándar de python, es posible iterar a través de un conjunto.
# Initialize a set
dataScientist = {'Python', 'R', 'SQL', 'Git', 'Tableau', 'SAS'}
for skill in dataScientist:
print(skill)
Si observa la salida de imprimir cada uno de los valores en dataScientist, note que los valores impresos en el conjunto no están en el orden en que fueron agregados. Esto se debe a que los conjuntos no están ordenados.
En este tutorial se ha hecho hincapié en que los conjuntos no están ordenados. Si necesita obtener los valores de su conjunto de forma ordenada, puede utilizar la función sorted, que genera una lista ordenada.
type(sorted(dataScientist))
El código siguiente muestra los valores del conjunto dataScientist en orden alfabético descendente (Z-A en este caso).
sorted(dataScientist, reverse = True)
Parte del contenido de esta sección fue explorado previamente en el tutorial 18 preguntas más comunes sobre listas en Python, pero es importante enfatizar que los conjuntos son la forma más rápida de eliminar duplicados de una lista. Para demostrarlo, estudiemos la diferencia de rendimiento entre dos enfoques.
Enfoque 1: Utilice un conjunto para eliminar duplicados de una lista.
print(list(set([1, 2, 3, 1, 7])))Enfoque 2: Utilice una comprensión de lista para eliminar duplicados de una lista (si desea refrescar conocimientos sobre las comprensiones de lista, consulte este tutorial).
def remove_duplicates(original):
unique = []
[unique.append(n) for n in original if n not in unique]
return(unique)
print(remove_duplicates([1, 2, 3, 1, 7]))La diferencia de rendimiento puede medirse utilizando la biblioteca timeit, que permite cronometrar el código Python. El siguiente código ejecuta el código para cada enfoque 10000 veces y muestra el tiempo total que tardó en segundos.
import timeit
# Approach 1: Execution time
print(timeit.timeit('list(set([1, 2, 3, 1, 7]))', number=10000))
# Approach 2: Execution time
print(timeit.timeit('remove_duplicates([1, 2, 3, 1, 7])', globals=globals(), number=10000))
La comparación de estos dos enfoques muestra que el uso de conjuntos para eliminar duplicados es más eficaz. Aunque pueda parecer una pequeña diferencia de tiempo, puede ahorrarle mucho tiempo si tiene listas muy grandes.
Un uso común de los conjuntos en Python es el cálculo de operaciones matemáticas estándar como la unión, la intersección, la diferencia y la diferencia simétrica. La siguiente imagen muestra un par de operaciones matemáticas estándar sobre dos conjuntos A y B. La parte roja de cada diagrama de Venn es el conjunto resultante de una operación de conjunto determinada.
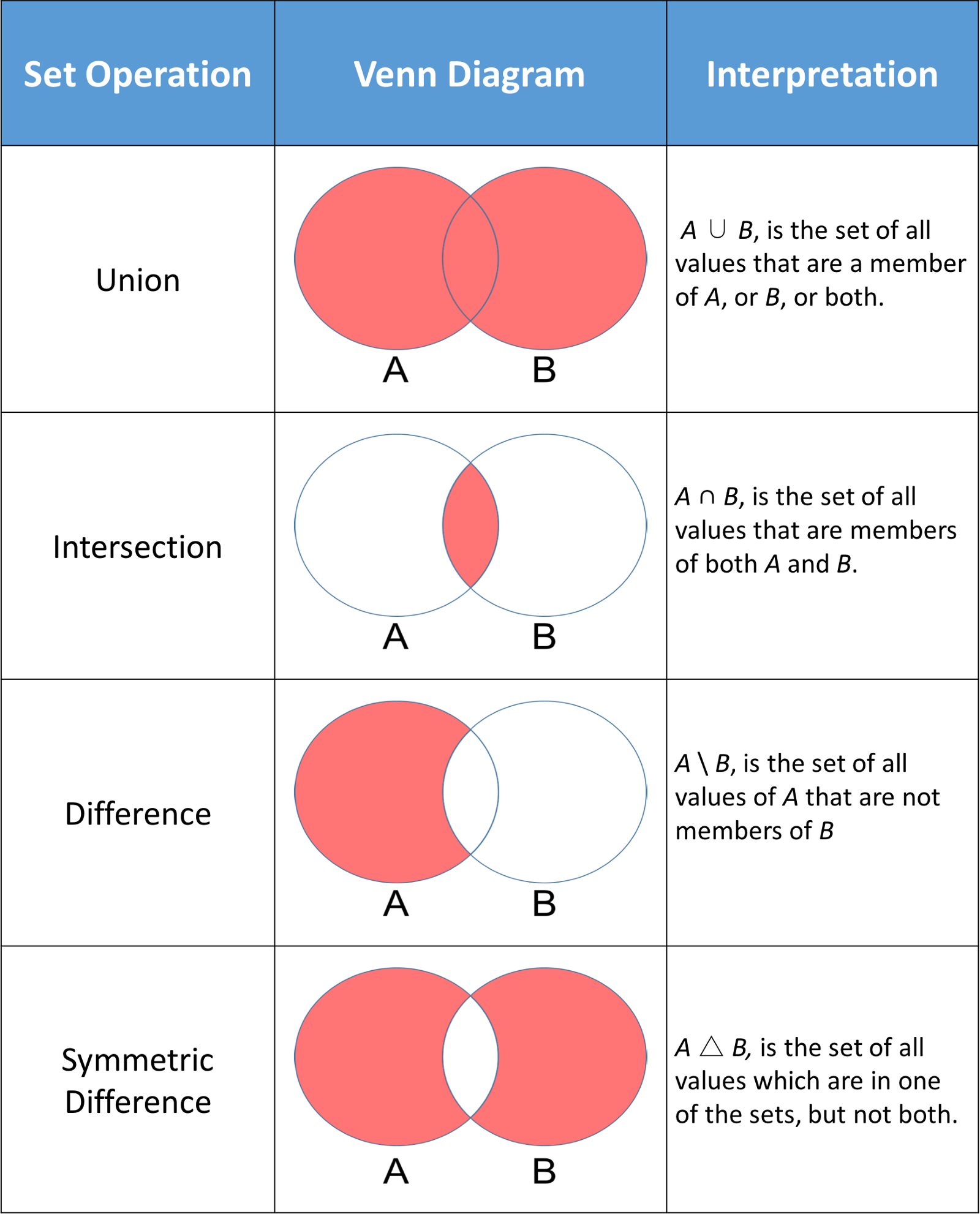
Los conjuntos de Python tienen métodos que permiten realizar estas operaciones matemáticas, así como operadores que ofrecen resultados equivalentes.
Antes de explorar estos métodos, vamos a empezar por inicializar dos conjuntos dataScientist y dataEngineer.
dataScientist = set(['Python', 'R', 'SQL', 'Git', 'Tableau', 'SAS'])
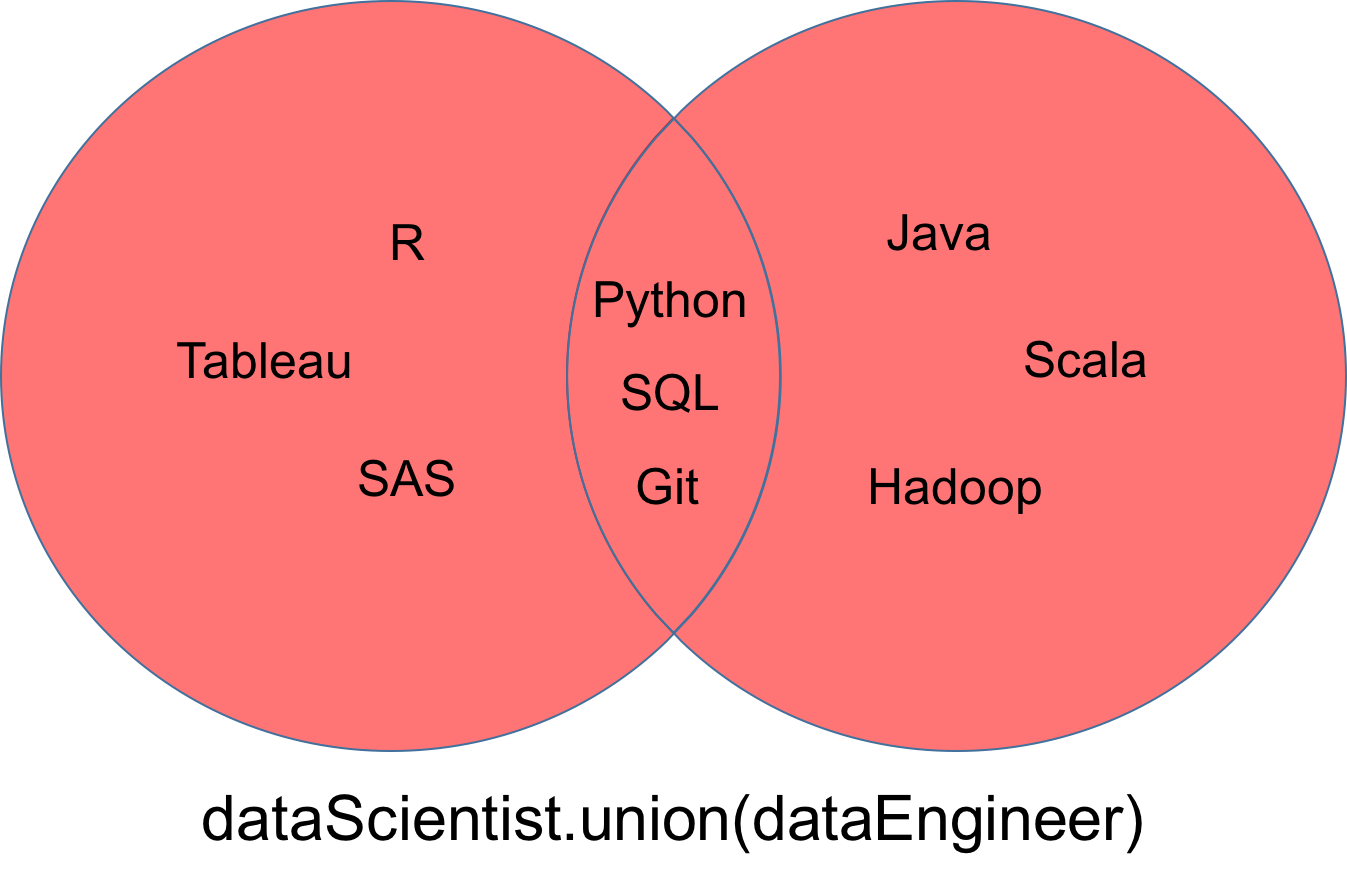
dataEngineer = set(['Python', 'Java', 'Scala', 'Git', 'SQL', 'Hadoop'])Una unión, denotada dataScientist ∪ dataEngineer, es el conjunto de todos los valores que son valores de dataScientist, o dataEngineer, o ambos. Puede utilizar el método union para averiguar todos los valores únicos de dos conjuntos.
# set built-in function union
dataScientist.union(dataEngineer)
# Equivalent Result
dataScientist | dataEngineer
El conjunto resultante de la unión puede visualizarse como la parte roja del diagrama de Venn.
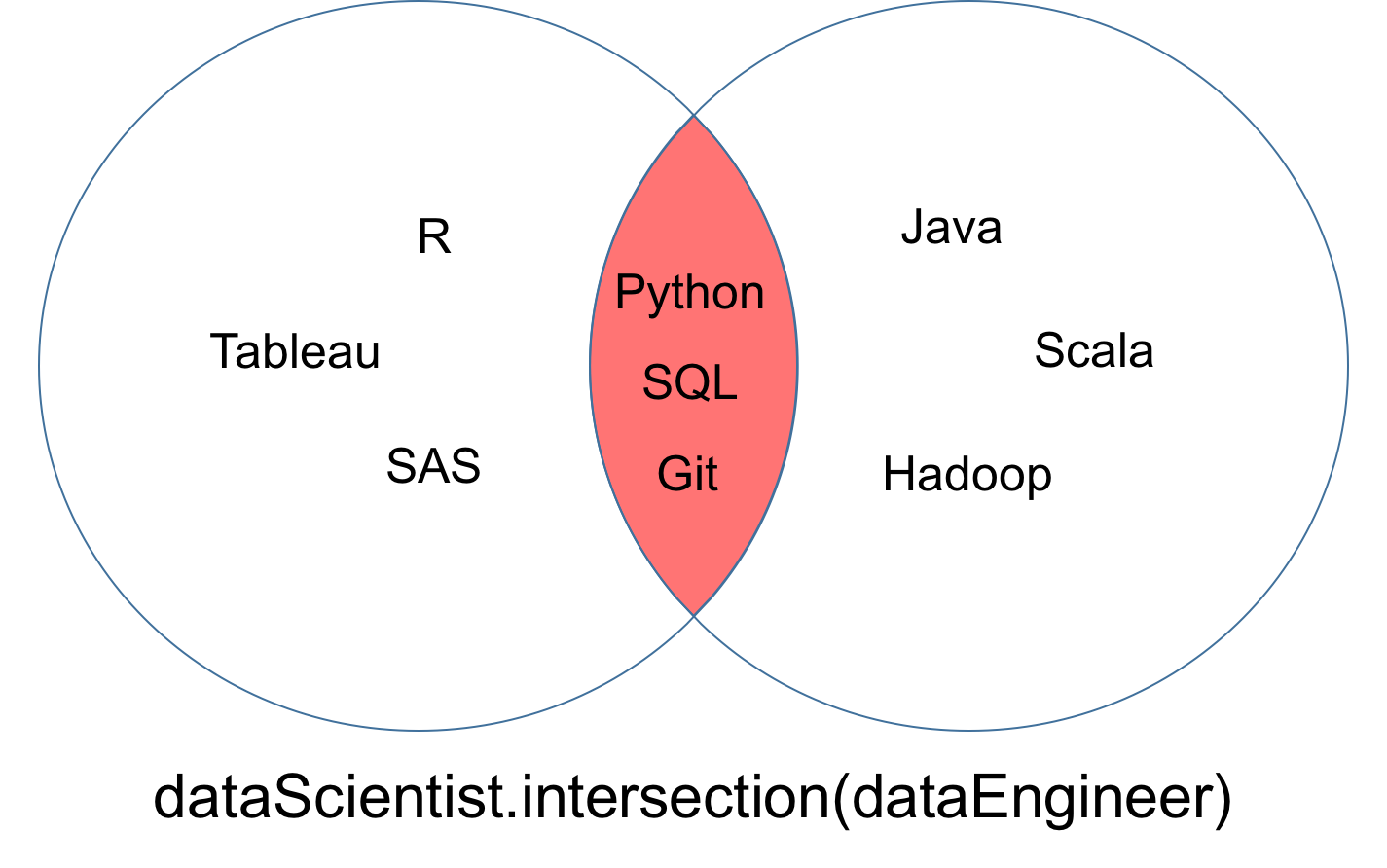
Una intersección de dos conjuntos dataScientist y dataEngineer, denotada dataScientist ∩ dataEngineer, es el conjunto de todos los valores que son valores tanto de dataScientist como de dataEngineer.
# Intersection operation
dataScientist.intersection(dataEngineer)
# Equivalent Result
dataScientist & dataEngineer
El conjunto resultante de la intersección puede visualizarse como la parte roja del diagrama de Venn.
Es posible que te encuentres con un caso en el que quieras asegurarte de que dos conjuntos no tienen ningún valor en común. En otras palabras, quieres dos conjuntos que tengan una intersección vacía. Estos dos conjuntos se denominan conjuntos disjuntos. Puede comprobar si hay conjuntos disjuntos utilizando el método isdisjoint.
# Initialize a set
graphicDesigner = {'Illustrator', 'InDesign', 'Photoshop'}
# These sets have elements in common so it would return False
dataScientist.isdisjoint(dataEngineer)
# These sets have no elements in common so it would return True
dataScientist.isdisjoint(graphicDesigner)
Puede observar en la intersección que se muestra en el diagrama de Venn de abajo que los conjuntos disjuntos dataScientist y graphicDesigner no tienen valores en común.
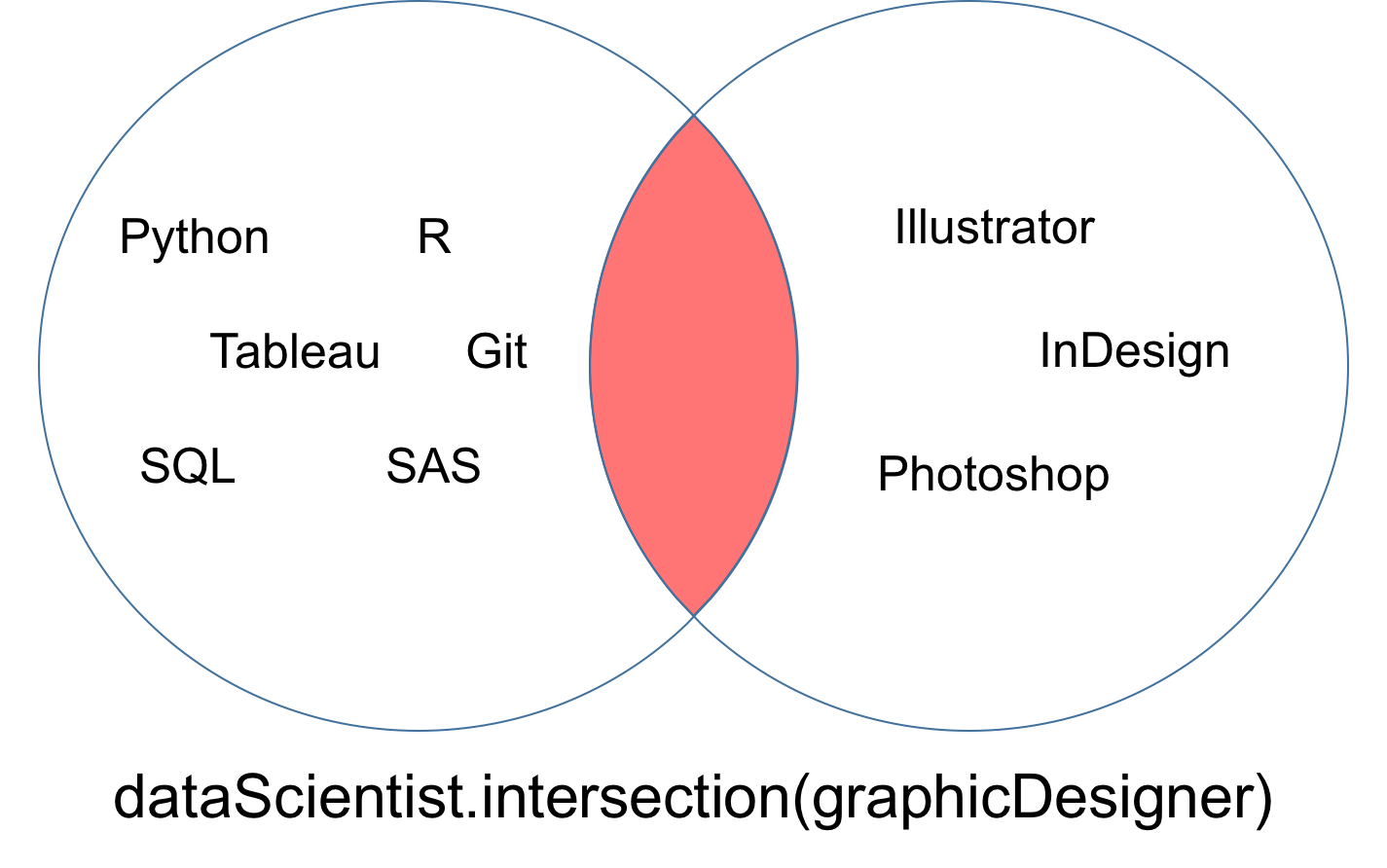
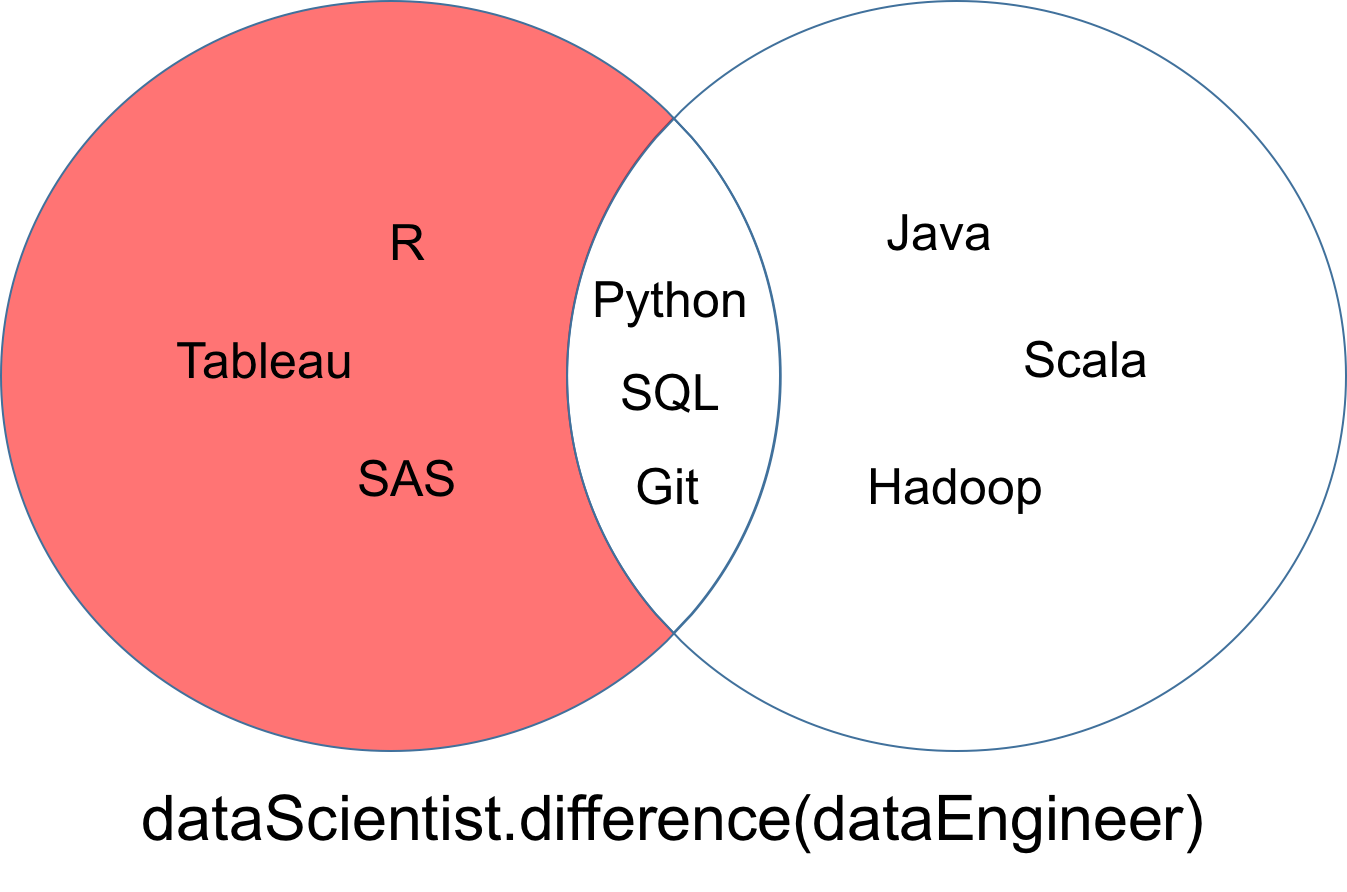
Una diferencia de dos conjuntos dataScientist y dataEngineer, denotada dataScientist \ dataEngineer, es el conjunto de todos los valores de dataScientist que no son valores de dataEngineer.
# Difference Operation
dataScientist.difference(dataEngineer)
# Equivalent Result
dataScientist - dataEngineer
El conjunto resultante de la diferencia puede visualizarse como la parte roja del diagrama de Venn que aparece a continuación.
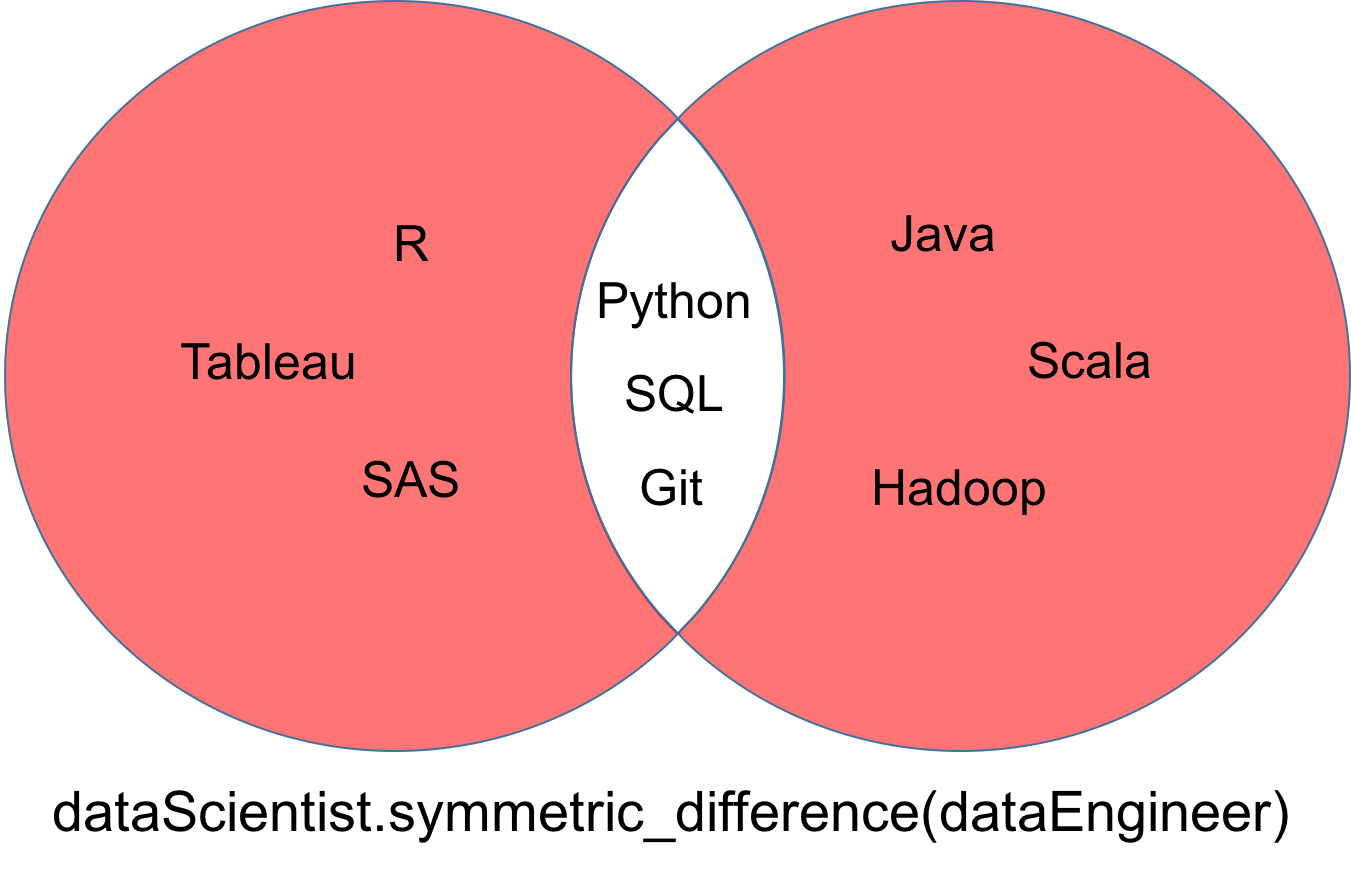
Una diferencia simétrica de dos conjuntos dataScientist y dataEngineer, denotada dataScientist △ dataEngineer, es el conjunto de todos los valores que son valores de exactamente uno de los dos conjuntos, pero no de ambos.
# Symmetric Difference Operation
dataScientist.symmetric_difference(dataEngineer)
# Equivalent Result
dataScientist ^ dataEngineer
El conjunto devuelto por la diferencia simétrica puede visualizarse como la parte roja del diagrama de Venn que aparece a continuación.
Es posible que ya hayas aprendido sobre la comprensión de listas, la comprensión de diccionarios y la comprensión de generadores. También existen las comprensiones de conjuntos de Python. Las comprensiones de conjuntos son muy similares. Las comprensiones de conjuntos en Python se pueden construir de la siguiente manera:
{skill for skill in ['SQL', 'SQL', 'PYTHON', 'PYTHON']}
La salida anterior es un conjunto de 2 valores porque los conjuntos no pueden tener múltiples ocurrencias del mismo elemento.
La idea que subyace tras el uso de las comprensiones de conjuntos es permitirte escribir y razonar en código de la misma forma que harías matemáticas a mano.
{skill for skill in ['GIT', 'PYTHON', 'SQL'] if skill not in {'GIT', 'PYTHON', 'JAVA'}}El código anterior es similar a una diferencia de conjunto que aprendiste antes. Simplemente parece un poco diferente.
Las pruebas de pertenencia comprueban si un elemento específico está contenido en una secuencia, como cadenas, listas, tuplas o conjuntos. Una de las principales ventajas de utilizar conjuntos en Python es que están muy optimizados para las pruebas de pertenencia. Por ejemplo, los conjuntos realizan pruebas de pertenencia de forma mucho más eficaz que las listas. En caso de que tenga conocimientos de informática, esto se debe a que la complejidad temporal media de las pruebas de pertenencia a conjuntos es O(1) frente a O(n) en el caso de las listas.
El código siguiente muestra una prueba de pertenencia utilizando una lista.
# Initialize a list
possibleList = ['Python', 'R', 'SQL', 'Git', 'Tableau', 'SAS', 'Java', 'Spark', 'Scala']
# Membership test
'Python' in possibleList
Algo similar puede hacerse para los conjuntos. Resulta que los conjuntos son más eficientes.
# Initialize a set
possibleSet = {'Python', 'R', 'SQL', 'Git', 'Tableau', 'SAS', 'Java', 'Spark', 'Scala'}
# Membership test
'Python' in possibleSet
Puesto que possibleSet es un conjunto y el valor 'Python' es un valor de possibleSet, esto puede denotarse como 'Python' ∈ possibleSet.
Si tuvieras un valor que no formara parte del conjunto, como 'Fortran', se denotaría como 'Fortran' ∉ possibleSet.
Una aplicación práctica de la comprensión de la pertenencia son los subconjuntos.
Inicialicemos primero dos conjuntos.
possibleSkills = {'Python', 'R', 'SQL', 'Git', 'Tableau', 'SAS'}
mySkills = {'Python', 'R'}Si cada valor del conjunto mySkills es también un valor del conjunto possibleSkills, entonces se dice que mySkills es un subconjunto de possibleSkills, escrito matemáticamente mySkills ⊆ possibleSkills.
Puede comprobar si un conjunto es subconjunto de otro mediante el método issubset.
mySkills.issubset(possibleSkills)
Dado que el método devuelve True en este caso, se trata de un subconjunto. En el siguiente diagrama de Venn, observe que cada valor del conjunto mySkills es también un valor del conjunto possibleSkills.
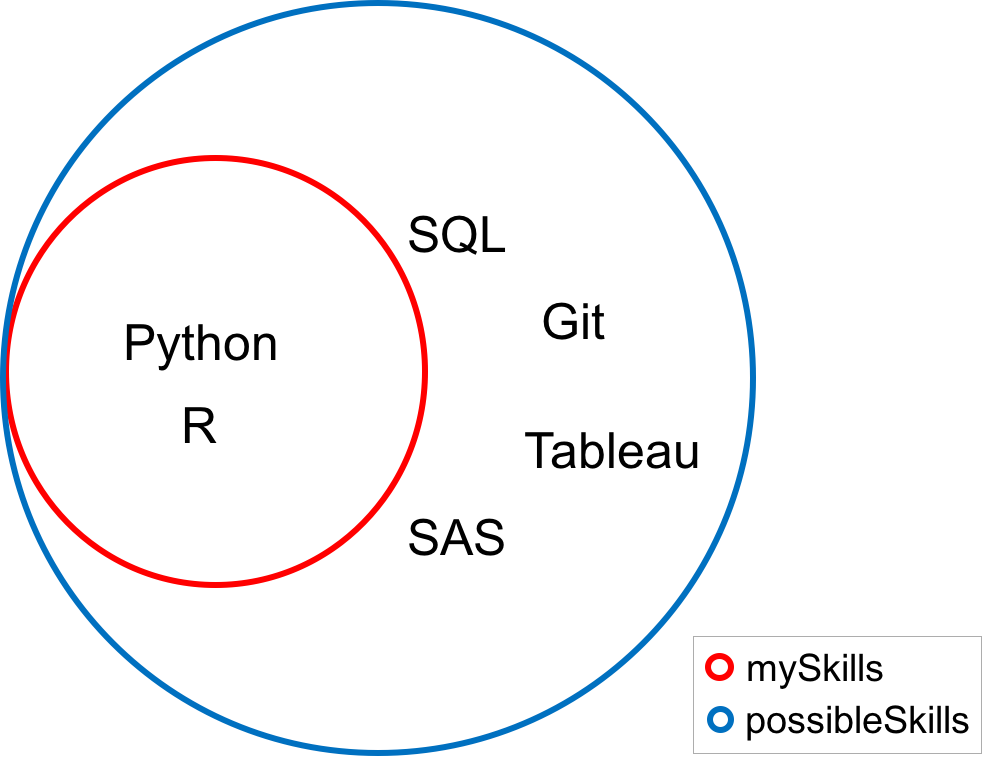
Ya se ha encontrado con listas y tuplas anidadas.
# Nested Lists and Tuples
nestedLists = [['the', 12], ['to', 11], ['of', 9], ['and', 7], ['that', 6]]
nestedTuples = (('the', 12), ('to', 11), ('of', 9), ('and', 7), ('that', 6))
El problema con los conjuntos anidados es que normalmente no se pueden tener conjuntos Python anidados, ya que los conjuntos no pueden contener valores mutables, incluidos los conjuntos.
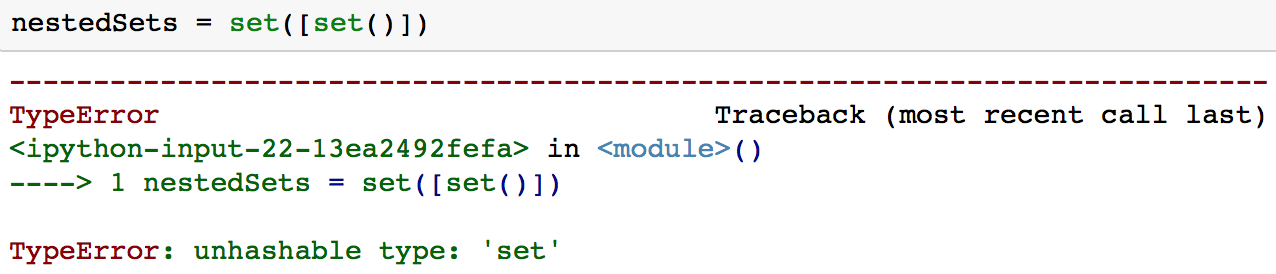
Esta es una de las situaciones en las que se puede utilizar un frozenset. Un frozenset es muy similar a un conjunto, salvo que un frozenset es inmutable.
Se hace un frozenset utilizando frozenset().
# Initialize a frozenset
immutableSet = frozenset()
Puede hacer un conjunto anidado si utiliza un frozenset similar al código siguiente.
nestedSets = set([frozenset()])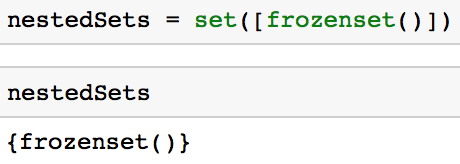
Es importante tener en cuenta que una desventaja importante de un frozenset es que al ser inmutables, significa que no se pueden añadir o eliminar valores.
Los conjuntos de Python son muy útiles para eliminar eficazmente valores duplicados de una colección como una lista y para realizar operaciones matemáticas comunes como uniones e intersecciones. Algunos de los problemas que se plantean a menudo son cuándo utilizar los distintos tipos de datos. Por ejemplo, si crees que no estás seguro de cuándo es ventajoso utilizar un diccionario frente a un conjunto, te animo a que eches un vistazo al modo de práctica diaria de DataCamp. Si tienes alguna pregunta o comentario sobre el tutorial, no dudes en escribirnos en los comentarios o a través de Twitter.
Cursos de Python
Curso
Curso
Curso
Tutorial
Théo Vanderheyden
Tutorial
Abid Ali Awan
Tutorial
Sejal Jaiswal