
Curso
Ajuste fino con Llama 3
2 h
3.7K
En este tutorial, aprenderemos a ejecutar el modelo de generación de imágenes FLUX.2 de forma local. Configuraremos el entorno de la GPU, descargaremos una versión cuantificada de FLUX.2, la cargaremos de manera eficiente en la GPU y la memoria RAM, ejecutaremos la inferencia y, a continuación, experimentaremos con diferentes opciones de configuración.
Ejecutar un modelo de este tamaño en una RTX 3090 puede resultar complicado, por lo que este tutorial se centra en la forma más sencilla y práctica de hacer funcionar FLUX.2 de forma local sin complicaciones innecesarias.
Si te interesan las técnicas avanzadas de gestión y optimización de modelos, incluyendo la poda, la cuantificación y el registro, te recomiendo que realices el curso curso Modelos de IA escalables con PyTorch Lightning .
FLUX.2 es un modelo de generación de imágenes creado para el trabajo creativo real, no solo para experimentos. Crea imágenes realistas y de alta calidad, manteniendo la coherencia de los personajes, los estilos y los productos en múltiples imágenes de referencia. Basado en el modelo original modelo FLUX, sigue las instrucciones con precisión, reproduce el texto con claridad y maneja bien la iluminación, los diseños y la marca.
FLUX.2 también admite la edición de imágenes en alta resolución y está disponible tanto en forma de API listas para usar como de modelos abiertos que puedes ejecutar localmente, lo que lo hace práctico, flexible y fácil de integrar en los flujos de trabajo de producción reales.
FLUX.2 está disponible en cuatro variantes principales:
Cada uno está diseñado para diferentes niveles de control, rendimiento y necesidades de implementación.
En comparaciones más amplias de clasificaciones, las tres variantes de FLUX.2 se encuentran entre los 10 mejores modelos de edición de imágenes en la clasificación de Artificial Analysis, y FLUX.2 [max] y FLUX.2 [pro] superan a modelos como GPT-5 y las variantes FLUX.1 Kontext de la generación anterior.
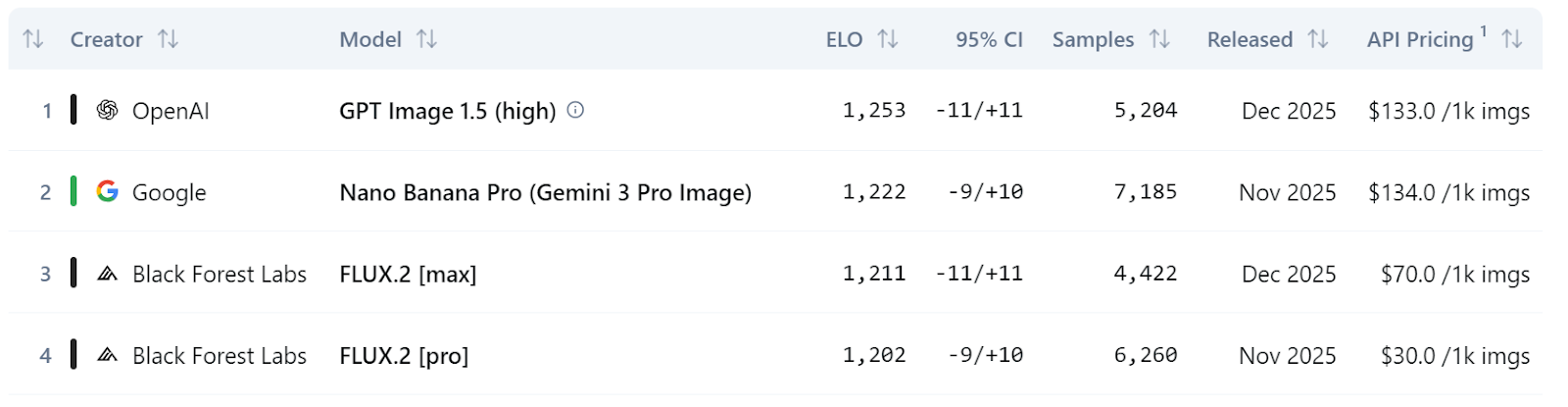
Fuente: Tabla de clasificación de texto a imagen | Análisis artificial
En los pasos siguientes, explicaré todo lo que necesitas saber para ejecutar FLUX.2 localmente utilizando una GPU RTX 3090.
Antes de ejecutar FLUX.2 localmente, asegúrate de que tu sistema esté configurado correctamente para la inferencia de GPU.
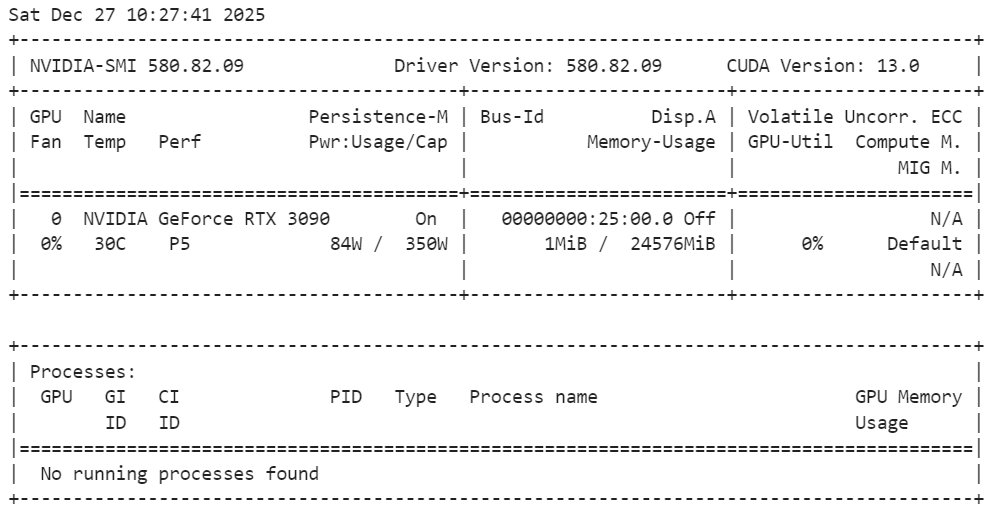
Ejecuta el siguiente comando en el terminal para verificar la instalación:
nvidia-smiComo podemos ver, tenemos una GPU RTX 3090 con CUDA versión 13.
pip install jupyterlab notebookNota: Estamos utilizando Jupyter Notebook como entorno de programación, lo que facilita la experimentación, la ejecución de inferencias paso a paso y la generación y edición iterativa de imágenes directamente en el cuaderno.
En este paso, instalaremos PyTorch con soporte CUDA para que la inferencia se ejecute en la GPU en lugar de en la CPU. El siguiente comando instala PyTorch, TorchVision y TorchAudio con binarios CUDA precompilados, lo que elimina la necesidad de compilar CUDA desde el código fuente.
!pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu130Después de la instalación, PyTorch utilizará automáticamente la GPU si está disponible y correctamente configurada.
A continuación, instalamos las bibliotecas principales necesarias para ejecutar FLUX.2 localmente. Estos paquetes gestionan la carga de modelos, la inferencia, la aceleración de la GPU y la cuantizacióny la transferencia eficiente de datos.
!pip install -q diffusers transformers accelerate bitsandbytes huggingface_hub protobuf sentencepiece hf_transferUna vez instalado, tu entorno estará listo para cargar FLUX.2 y comenzar a ejecutar la generación de imágenes y la edición de inferencias.
Antes de cargar FLUX.2, verificamos que PyTorch pueda ver la GPU y que sea compatible con la cuantificación de 4 bits. Este paso es importante para garantizar que el modelo pueda ejecutarse de manera eficiente dentro de los límites de memoria de una RTX 3090.
import torch
import bitsandbytes as bnb
print(f"PyTorch Version: {torch.__version__}")
print(f"CUDA Version: {torch.version.cuda}")
print(f"Is CUDA available? {torch.cuda.is_available()}")
print(f"GPU Name: {torch.cuda.get_device_name(0)}")
# Check if 4-bit quantization is supported (Ampere 3090 supports this natively)
try:
print(f"BitsAndBytes Version: {bnb.__version__}")
print("4-bit quantization check: PASSED")
except ImportError:
print("BitsAndBytes not installed correctly.")El resultado confirma que PyTorch está correctamente instalado con soporte CUDA, que se ha detectado tu GPU RTX 3090 y que bitsandbytes funciona correctamente con la cuantificación de 4 bits habilitada, por lo que el sistema está listo para una inferencia eficiente de la GPU.
PyTorch Version: 2.8.0+cu128
CUDA Version: 12.8
Is CUDA available? True
GPU Name: NVIDIA GeForce RTX 3090
BitsAndBytes Version: 0.49.0
4-bit quantization check: PASSEDEn este paso, cargamos FLUX.2 [dev] utilizando un punto de control cuantificado de 4 bits para reducir el uso de memoria de la GPU y mantener al mismo tiempo una alta calidad de imagen. Esto es esencial para ejecutar un modelo grande como FLUX.2 en una RTX 3090.
Comenzamos importando las bibliotecas necesarias y definiendo algunos ajustes clave.
repo_id apunta al punto de control de desarrollo FLUX.2 de 4 bits.device selecciona tu GPU (primer dispositivo CUDA).torch_dtype bfloat16Establece la precisión de cálculo utilizada durante la inferencia. Se suele utilizar la precisión de cálculo de 0,00000000000000000000000000000000000000000000000000000000000000000000000000000import torch
from transformers import Mistral3ForConditionalGeneration
from diffusers import Flux2Pipeline, Flux2Transformer2DModel
repo_id = "diffusers/FLUX.2-dev-bnb-4bit"
device = "cuda:0"
torch_dtype = torch.bfloat16A continuación, cargamos primero en la CPU el transformador de imágenes FLUX.2 (el componente principal responsable de generar las imágenes latentes). Esto evita llenar la VRAM durante la carga inicial y proporciona al canal más flexibilidad para mover módulos a la GPU solo cuando sea necesario.
transformer = Flux2Transformer2DModel.from_pretrained(
repo_id, subfolder="transformer", torch_dtype=torch_dtype, device_map="cpu"
)A continuación, cargamos el codificador de texto en la CPU también. El codificador de texto convierte tu indicación en incrustaciones que guían la generación de imágenes. Mantenerlo en la CPU durante la configuración ayuda a liberar memoria de la GPU para las partes más pesadas del proceso de generación.
text_encoder = Mistral3ForConditionalGeneration.from_pretrained(
repo_id, subfolder="text_encoder", dtype=torch_dtype, device_map="cpu"
)Por último, montamos el tubería de difusores inyectando el transformador y el codificador de texto que hemos cargado.
La línea clave aquí es « enable_model_cpu_offload() »: activa la descarga automática de CPU ↔ GPU, lo que significa que el canal traslada partes del modelo a la GPU solo cuando son necesarias, y luego las vuelve a trasladar a la CPU. Esta es una de las formas más sencillas de ejecutar modelos grandes en GPU de consumo sin tener que gestionar manualmente la ubicación de los dispositivos.
pipe = Flux2Pipeline.from_pretrained(
repo_id, transformer=transformer, text_encoder=text_encoder, torch_dtype=torch_dtype
)
pipe.enable_model_cpu_offload()Ahora estamos listos para generar nuestra primera imagen utilizando FLUX.2. Para simplificar las cosas, comenzamos con un único texto que describe una fotografía macro hiperrealista de una mariquita.
prompt = (
"Realistic macro photo of a ladybug perched on the edge of a dew-covered rose petal, "
"early morning mist, soft natural light, shallow depth of field, crisp detail, creamy bokeh."
)
A continuación, pasamos la indicación al canal y ejecutamos la inferencia.
image = pipe(
prompt=prompt,
generator=torch.Generator(device=device).manual_seed(42),
num_inference_steps=28,
guidance_scale=4,
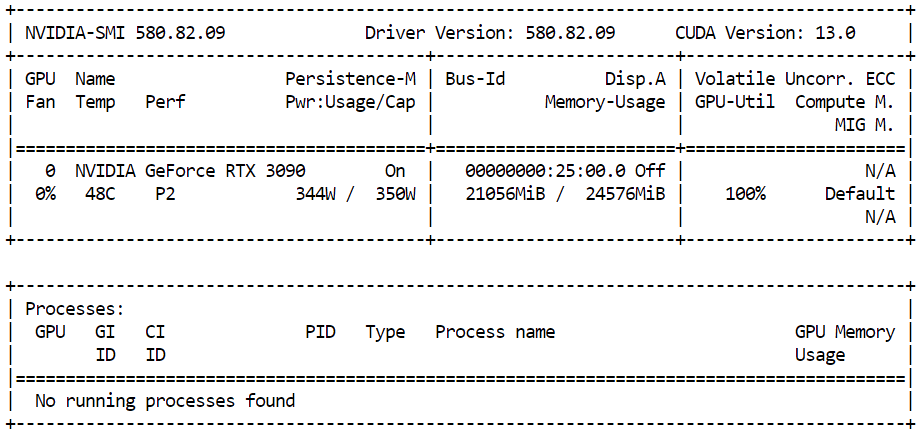
).images[0]Para supervisar cuánta memoria GPU se está utilizando durante la inferencia, abre un terminal y ejecuta:
nvidia-smiDeberías ver cerca de 21 GB de VRAM de GPU en uso con una alta utilización de la GPU, lo que indica que el modelo está utilizando de manera eficiente los recursos disponibles y funcionando a pleno rendimiento en la RTX 3090.
Una vez completada la inferencia, puedes ver la imagen generada directamente dentro del Jupyter Notebook simplemente mostrando el objeto de imagen:
imageEl resultado es muy detallado y realista. El modelo sigue fielmente las instrucciones, al tiempo que añade detalles sutiles, como la iluminación y la textura, que no se especificaban explícitamente.

Por último, guardamos la imagen generada localmente:
output_path = "flux2_local_full.png"
image.save(output_path)
print(f"Image saved to {output_path}")Salida:
Image saved to flux2_local_full.pngFLUX.2 admite técnicas avanzadas de sugerencias que van más allá del texto sin formato, lo que permite un control mucho más preciso sobre la imagen final. Mediante indicaciones JSON estructuradas, puedes definir explícitamente la disposición de la escena, los sujetos, la iluminación, los ajustes de la cámara, el ambiente e incluso las paletas de colores utilizando códigos hexadecimales precisos.
En esta sección, utilizamos una indicación JSON estructurada para describir la escena con detalle. En lugar de una sola frase, definimos el entorno, los temas, el estilo, los colores, la iluminación, las propiedades de la cámara y las restricciones negativas en un formato claro y organizado.
Esto ayuda a FLUX.2 a comprender mejor las instrucciones complejas y a producir resultados más predecibles y de mayor calidad.
advanced_prompt = """
{
"scene": "New Year's Eve night on a rooftop overlooking a glowing city skyline",
"subjects": [
{
"description": "Group of close friends including men and women in winter clothing, natural facial proportions, diverse appearances",
"position": "center and slightly spread across the frame",
"action": "standing together in a loose circle, some smiling softly, others quietly reflective, sharing the moment before midnight"
}
],
"style": "Cinematic semi-realistic illustration with grounded realism, subtle painterly softness",
"color_palette": ["#0B132B", "#1C2541", "#EAEAEA", "#F4D35E"],
"lighting": "Soft moonlight as ambient key light, warm glow from sparklers and nearby string lights illuminating faces, gentle contrast",
"mood": "Warm, intimate, reflective, hopeful",
"background": "Out-of-focus city skyline with distant fireworks softly lighting the sky, minimal visual noise",
"composition": "Wide medium shot, balanced framing, friends forming a natural arc, negative space above for sky and fireworks",
"camera": {
"angle": "eye-level",
"lens": "50mm cinematic look",
"depth_of_field": "sharp focus on group, gentle background blur"
},
"details": [
"subtle breath vapor in cold air",
"soft fabric textures on coats and scarves",
"sparklers emitting warm golden particles",
"natural body language and expressions",
"no exaggerated poses or faces"
],
"negative_prompt": [
"cartoon style",
"emote proportions",
"chibi",
"oversized heads",
"text",
"watermark",
"logo",
"overcrowded scene",
"harsh neon lighting",
"over-saturation",
"extra limbs",
"distorted faces"
]
}
"""A continuación, realizamos una inferencia con un mayor número de pasos para capturar más detalles, manteniendo al mismo tiempo una escala de orientación moderada para conseguir un aspecto natural.
image_2 = pipe(
prompt=advanced_prompt,
generator=torch.Generator(device=device).manual_seed(42),
num_inference_steps=50,
guidance_scale=4,
).images[0]Para mostrar la imagen generada dentro del cuaderno Jupyter:
image_2La imagen resultante sigue fielmente las instrucciones estructuradas, capturando la escena, el ambiente, la iluminación y la composición exactamente como se especificó.

FLUX.2 también admite la edición de imágenes, en la que se utiliza una imagen de referencia como base y el modelo aplica los cambios guiado por un mensaje de texto. Esto resulta especialmente útil cuando deseas conservar la identidad, los rasgos faciales y el tono de piel, mientras cambias la escena, el ambiente o el entorno que rodea al sujeto.
Para este ejemplo, utilizamos una foto de una mujer india obtenida de Pexels.com como imagen de referencia:

Foto de cottonbro studio: https://www.pexels.com/photo/a-woman-with-a-nose-piercing-9317190/
Diseñamos cuidadosamente la indicación para instruir al modelo que mantenga intactos el rostro y los tonos naturales de la piel de la mujer, mientras se cambia el escenario, la iluminación y la expresión emocional. El objetivo es editar la imagen sin alterar tu identidad.
from diffusers.utils import load_image
prompt = (
"Using the provided reference image, generate a realistic photograph of a woman with a similar face, "
"standing at night and looking up at the sky with stars with a subtle, sad expression. "
"Natural skin tones, soft moonlight, gentle shadows, shallow depth of field, "
"with blurred city lights in the background."
)A continuación, cargamos la imagen de referencia y la pasamos al proceso. FLUX.2 admite varias imágenes de referencia, pero aquí utilizamos una sola imagen para guiar la edición.
indian_woman = load_image("https://images.pexels.com/photos/9317190/pexels-photo-9317190.jpeg")
image_3 = pipe(
prompt=prompt,
image=[indian_woman],
generator=torch.Generator(device=device).manual_seed(42),
num_inference_steps=28,
guidance_scale=4,
).images[0]Para ver el resultado editado dentro del cuaderno Jupyter:
image_3El resultado es muy realista. El modelo conserva la estructura facial y el tono de piel de la mujer, al tiempo que la coloca de forma natural en una nueva escena con una iluminación, un ambiente y un fondo diferentes.
El resultado parece menos una edición con IA y más una fotografía tomada por un fotógrafo profesional en un lugar y momento diferentes.

Según mi experiencia, FLUX.2 solo empezó a funcionar de forma fiable a nivel local después de cambiar al modelo cuantificado de 4 bits y utilizar una configuración basada en código con Transformers y Diffusers.
Antes, me aparecían errores de memoria insuficiente en una RTX 3090 de 24 GB cuando intentaba cargar demasiada información directamente en CUDA.
Las herramientas de interfaz de usuario como Stable Diffusion WebUI y ComfyUI también pueden alcanzar los límites de memoria más fácilmente, ya que suelen mantener en la memoria búferes intermedios adicionales, vistas previas y el estado del flujo de trabajo, a menos que se ajusten cuidadosamente sus opciones de baja VRAM.
Consejos para optimizar la VRAM (lo que realmente me ayudó):
device_map="cpu") y evita enviar todo a CUDA por adelantado.pipe.enable_model_cpu_offload()) para que solo las partes activas se ejecuten en la GPU.nvidia-smi y cierra cualquier otra aplicación que consuma muchos recursos de la GPU.Si sigues teniendo problemas de memoria insuficiente después de seguir estos pasos, consulta este cuaderno de DataLab para obtener más ejemplos de resolución de problemas y optimización de la memoria.
Estoy realmente impresionado por lo lejos que han llegado los modelos de generación de imágenes de código abierto.
Modelos como FLUX.2 ahora son claramente competitivos con los sistemas patentados, tanto en términos de calidad visual como de comprensión rápida. Con la configuración adecuada, algo de experimentación y un poco de optimización de la memoria, es posible generar imágenes realistas y de alta calidad de forma local y gratuita, incluso en GPU de consumo.
Lo que más destaca es el nivel de control. Las sugerencias avanzadas, el JSON estructurado, la edición multirreferencia y los flujos de trabajo de imagen a imagen facilitan ir más allá de las simples generaciones.
Puedes crear escenas cinematográficas, desarrollar imágenes para contar historias, realizar ediciones de imágenes de calidad profesional y repetir rápidamente sin depender de plataformas cerradas.
Para los creadores, investigadores y programadores, esto abre un amplio abanico de posibilidades creativas y hace que la generación de imágenes de alta calidad sea más accesible que nunca.
Los mejores cursos de DataCamp
Curso
Curso
Curso