
Curso
Fine-Tuning with Llama 3
2 h
3.7K
Neste tutorial, vamos aprender como rodar o modelo de geração de imagens FLUX.2 localmente. Vamos configurar o ambiente da GPU, baixar uma versão quantizada do FLUX.2, carregá-la de forma eficiente na GPU e na memória RAM, executar a inferência e, em seguida, experimentar diferentes opções de configuração.
Executar um modelo desse tamanho em uma RTX 3090 pode ser complicado, e este tutorial foca na maneira mais simples e prática de fazer o FLUX.2 funcionar localmente sem complicações desnecessárias.
Se você curte técnicas avançadas de gerenciamento e otimização de modelos, incluindo poda, quantização e registro, recomendo fazer o Modelo de IA escalável com PyTorch Lightning .
FLUX.2 é um modelo de geração de imagens feito pra trabalhos criativos de verdade, não só para experimentos. Ele cria imagens realistas e de alta qualidade, mantendo a consistência dos personagens, estilos e produtos em várias imagens de referência. Com base no modelo original FLUX, ele segue instruções com precisão, renderiza textos com clareza e lida bem com iluminação, layouts e branding.
O FLUX.2 também suporta edição de imagens em alta resolução e está disponível tanto como APIs prontas para uso quanto como modelos abertos que você pode executar localmente, tornando-o prático, flexível e fácil de se encaixar em fluxos de trabalho de produção reais.
O FLUX.2 vem em quatro versões principais:
Cada um foi feito para diferentes níveis de controle, desempenho e necessidades de implantação.
Em comparações mais amplas do ranking, todas as três variantes do FLUX.2 estão entre os 10 melhores modelos de edição de imagens no ranking da Artificial Analysis, com o FLUX.2 [max] e o FLUX.2 [pro] superando modelos como o GPT-5 e as variantes FLUX.1 Kontext da geração anterior.
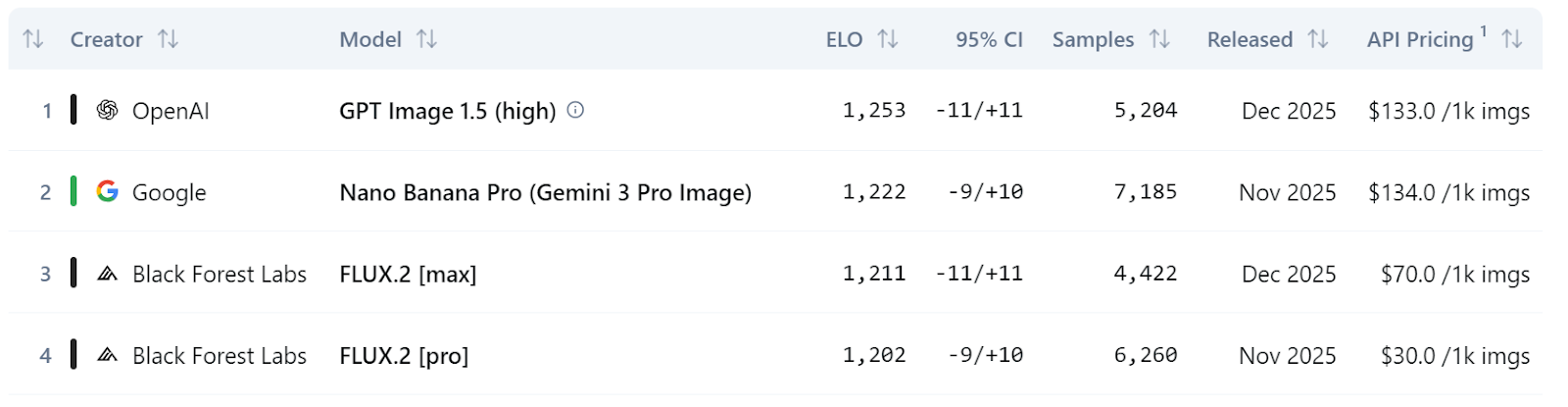
Fonte: Classificação de texto para imagem | Análise artificial
Nas etapas abaixo, vou explicar tudo o que você precisa saber para rodar o FLUX.2 localmente usando uma GPU RTX 3090.
Antes de rodar o FLUX.2 localmente, certifique-se de que seu sistema está configurado corretamente para inferência de GPU.
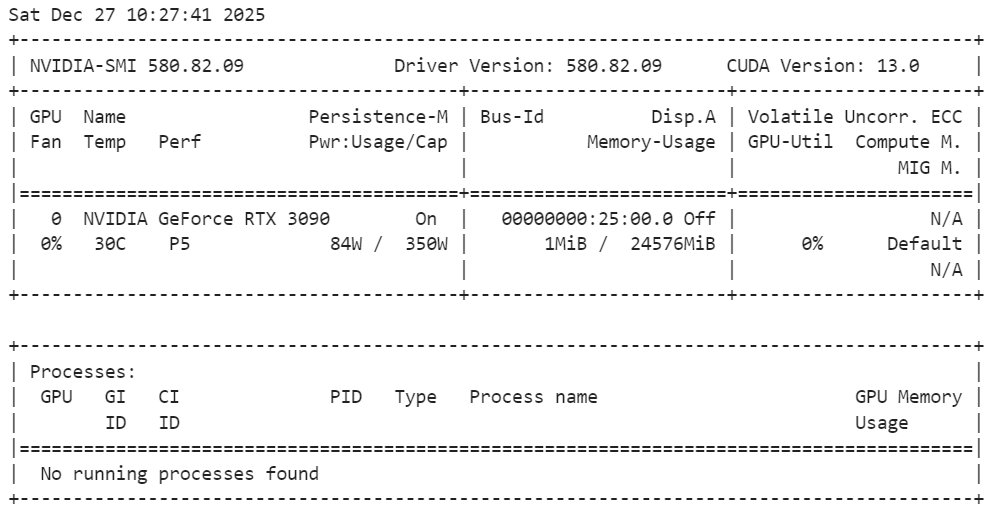
Execute o seguinte comando no terminal para verificar a instalação:
nvidia-smiComo dá pra ver, a gente tem uma GPU RTX 3090 com CUDA versão 13.
pip install jupyterlab notebookObservação: A gente tá usando o Jupyter Notebook como nosso ambiente de codificação, o que facilita experimentar, fazer inferências passo a passo e gerar e editar imagens direto no notebook.
Nesta etapa, a gente instala o PyTorch com suporte CUDA para que a inferência seja executada na GPU em vez da CPU. O comando abaixo instala o PyTorch, o TorchVision e o TorchAudio com binários CUDA pré-compilados, sem precisar compilar o CUDA a partir do código-fonte.
!pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu130Depois de instalar, o PyTorch vai usar automaticamente a GPU, se ela estiver disponível e configurada direitinho.
Depois, a gente instala as bibliotecas principais necessárias para rodar o FLUX.2 localmente. Esses pacotes cuidam do carregamento do modelo, inferência, aceleração da GPU, quantizaçãoe transferência eficiente de dados.
!pip install -q diffusers transformers accelerate bitsandbytes huggingface_hub protobuf sentencepiece hf_transferDepois de instalar, seu ambiente estará pronto para carregar o FLUX.2 e começar a gerar imagens e editar inferências.
Antes de carregar o FLUX.2, a gente verifica se o PyTorch consegue ver a GPU e se a quantização de 4 bits é suportada. Essa etapa é importante pra garantir que o modelo funcione bem dentro dos limites de memória de uma RTX 3090.
import torch
import bitsandbytes as bnb
print(f"PyTorch Version: {torch.__version__}")
print(f"CUDA Version: {torch.version.cuda}")
print(f"Is CUDA available? {torch.cuda.is_available()}")
print(f"GPU Name: {torch.cuda.get_device_name(0)}")
# Check if 4-bit quantization is supported (Ampere 3090 supports this natively)
try:
print(f"BitsAndBytes Version: {bnb.__version__}")
print("4-bit quantization check: PASSED")
except ImportError:
print("BitsAndBytes not installed correctly.")A saída confirma que o PyTorch está instalado corretamente com suporte a CUDA, sua GPU RTX 3090 foi detectada e o bitsandbytes está funcionando bem com quantização de 4 bits ativada, então o sistema está pronto para uma inferência eficiente da GPU.
PyTorch Version: 2.8.0+cu128
CUDA Version: 12.8
Is CUDA available? True
GPU Name: NVIDIA GeForce RTX 3090
BitsAndBytes Version: 0.49.0
4-bit quantization check: PASSEDNesta etapa, carregamos o FLUX.2 [dev] usando um ponto de verificação quantizado de 4 bits para reduzir o uso de memória da GPU, mantendo a alta qualidade da imagem. Isso é essencial para rodar um modelo grande como o FLUX.2 em uma RTX 3090.
Começamos importando as bibliotecas necessárias e definindo algumas configurações importantes.
repo_id aponta para o ponto de verificação FLUX.2 de 4 bits.device seleciona sua GPU (primeiro dispositivo CUDA).torch_dtype define a precisão de cálculo usada durante a inferência. A precisão de 10 dígitos ( bfloat16 ) é normalmente usada porque reduz a memória e pode melhorar a velocidade, mantendo as saídas estáveis.import torch
from transformers import Mistral3ForConditionalGeneration
from diffusers import Flux2Pipeline, Flux2Transformer2DModel
repo_id = "diffusers/FLUX.2-dev-bnb-4bit"
device = "cuda:0"
torch_dtype = torch.bfloat16Depois, carregamos primeiro o backbone do transformador de imagens FLUX.2 (o principal componente responsável por gerar as latências das imagens) na CPU. Isso evita que a VRAM fique cheia durante o carregamento inicial e dá mais flexibilidade ao pipeline para mover os módulos para a GPU só quando for preciso.
transformer = Flux2Transformer2DModel.from_pretrained(
repo_id, subfolder="transformer", torch_dtype=torch_dtype, device_map="cpu"
)Depois, carregamos o codificador de texto na CPU também. O codificador de texto transforma o seu prompt em embeddings que orientam a geração da imagem. Manter isso na CPU durante a configuração ajuda a manter a memória da GPU livre para as partes mais pesadas do processo de geração.
text_encoder = Mistral3ForConditionalGeneration.from_pretrained(
repo_id, subfolder="text_encoder", dtype=torch_dtype, device_map="cpu"
)Por fim, montamos todo o pipeline do Diffusers injetando o transformador e o codificador de texto que carregamos.
A linha principal aqui é enable_model_cpu_offload(): ela ativa o descarregamento automático da CPU para a GPU, o que significa que o pipeline move partes do modelo para a GPU só quando elas são realmente necessárias e, depois, as move de volta para a CPU. Essa é uma das maneiras mais fáceis de rodar modelos grandes em GPUs comuns sem precisar gerenciar manualmente a colocação dos dispositivos.
pipe = Flux2Pipeline.from_pretrained(
repo_id, transformer=transformer, text_encoder=text_encoder, torch_dtype=torch_dtype
)
pipe.enable_model_cpu_offload()Agora estamos prontos para gerar nossa primeira imagem usando o FLUX.2. Pra simplificar, vamos começar com um único texto que descreve uma foto macro hiper-realista de uma joaninha.
prompt = (
"Realistic macro photo of a ladybug perched on the edge of a dew-covered rose petal, "
"early morning mist, soft natural light, shallow depth of field, crisp detail, creamy bokeh."
)
Depois, a gente passa o prompt para o pipeline e faz a inferência.
image = pipe(
prompt=prompt,
generator=torch.Generator(device=device).manual_seed(42),
num_inference_steps=28,
guidance_scale=4,
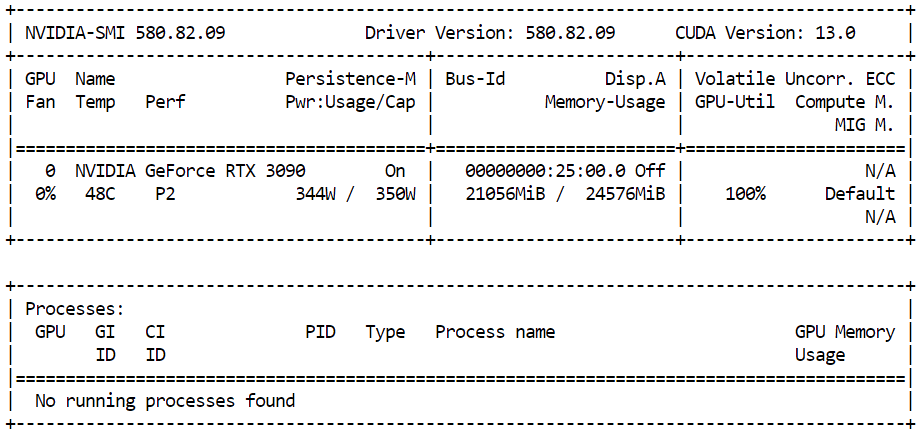
).images[0]Pra ver quanto de memória da GPU tá sendo usada durante a inferência, abre um terminal e executa:
nvidia-smiVocê deve ver cerca de 21 GB de VRAM da GPU em uso com alta utilização da GPU, o que mostra que o modelo está usando os recursos disponíveis de forma eficiente e rodando com desempenho total na RTX 3090.
Quando a inferência terminar, você pode ver a imagem gerada direto no Jupyter Notebook, só precisa mostrar o objeto da imagem:
imageO resultado é super detalhado e realista. O modelo segue o prompt de perto, ao mesmo tempo em que adiciona detalhes sutis, como iluminação e textura, que não foram explicitamente especificados.

Por fim, salvamos a imagem gerada localmente:
output_path = "flux2_local_full.png"
image.save(output_path)
print(f"Image saved to {output_path}")Resultado:
Image saved to flux2_local_full.pngO FLUX.2 suporta técnicas avançadas de prompting que vão além do texto simples, permitindo um controle muito mais preciso sobre a imagem final. Usando prompts JSON estruturados, você pode definir explicitamente o layout da cena, os objetos, a iluminação, as configurações da câmera, o clima e até mesmo as paletas de cores usando códigos hexadecimais precisos.
Nesta seção, usamos um prompt JSON estruturado para descrever a cena em detalhes. Em vez de uma única frase, a gente define o ambiente, os assuntos, o estilo, as cores, a iluminação, as propriedades da câmera e as restrições negativas de um jeito claro e organizado.
Isso ajuda o FLUX.2 a entender melhor instruções complexas e produzir resultados mais previsíveis e de alta qualidade.
advanced_prompt = """
{
"scene": "New Year's Eve night on a rooftop overlooking a glowing city skyline",
"subjects": [
{
"description": "Group of close friends including men and women in winter clothing, natural facial proportions, diverse appearances",
"position": "center and slightly spread across the frame",
"action": "standing together in a loose circle, some smiling softly, others quietly reflective, sharing the moment before midnight"
}
],
"style": "Cinematic semi-realistic illustration with grounded realism, subtle painterly softness",
"color_palette": ["#0B132B", "#1C2541", "#EAEAEA", "#F4D35E"],
"lighting": "Soft moonlight as ambient key light, warm glow from sparklers and nearby string lights illuminating faces, gentle contrast",
"mood": "Warm, intimate, reflective, hopeful",
"background": "Out-of-focus city skyline with distant fireworks softly lighting the sky, minimal visual noise",
"composition": "Wide medium shot, balanced framing, friends forming a natural arc, negative space above for sky and fireworks",
"camera": {
"angle": "eye-level",
"lens": "50mm cinematic look",
"depth_of_field": "sharp focus on group, gentle background blur"
},
"details": [
"subtle breath vapor in cold air",
"soft fabric textures on coats and scarves",
"sparklers emitting warm golden particles",
"natural body language and expressions",
"no exaggerated poses or faces"
],
"negative_prompt": [
"cartoon style",
"emote proportions",
"chibi",
"oversized heads",
"text",
"watermark",
"logo",
"overcrowded scene",
"harsh neon lighting",
"over-saturation",
"extra limbs",
"distorted faces"
]
}
"""Depois, fazemos uma inferência com mais etapas pra capturar mais detalhes, mantendo a escala de orientação moderada pra um visual natural.
image_2 = pipe(
prompt=advanced_prompt,
generator=torch.Generator(device=device).manual_seed(42),
num_inference_steps=50,
guidance_scale=4,
).images[0]Para mostrar a imagem gerada dentro do Jupyter Notebook:
image_2A imagem resultante segue de perto a instrução estruturada, capturando a cena, o clima, a iluminação e a composição exatamente como especificado.

O FLUX.2 também dá suporte à edição de imagens, onde uma imagem de referência é usada como base e o modelo faz as alterações seguindo as instruções de um prompt de texto. Isso é super útil quando você quer manter a identidade, as características faciais e o tom de pele, enquanto muda a cena, o clima ou o ambiente ao redor do sujeito.
Neste exemplo, usamos uma foto de uma mulher indiana tirada do site Pexels.com como imagem de referência:

Foto por cottonbro studio: https://www.pexels.com/photo/a-woman-with-a-nose-piercing-9317190/
A gente cria cuidadosamente o prompt para instruir o modelo a manter o rosto da mulher e os tons naturais da pele intactos, enquanto altera o cenário, a iluminação e a expressão emocional. O objetivo é editar a imagem sem mudar a identidade dela.
from diffusers.utils import load_image
prompt = (
"Using the provided reference image, generate a realistic photograph of a woman with a similar face, "
"standing at night and looking up at the sky with stars with a subtle, sad expression. "
"Natural skin tones, soft moonlight, gentle shadows, shallow depth of field, "
"with blurred city lights in the background."
)Depois, carregamos a imagem de referência e a passamos para o pipeline. O FLUX.2 aceita várias imagens de referência, mas aqui usamos uma única imagem para orientar a edição.
indian_woman = load_image("https://images.pexels.com/photos/9317190/pexels-photo-9317190.jpeg")
image_3 = pipe(
prompt=prompt,
image=[indian_woman],
generator=torch.Generator(device=device).manual_seed(42),
num_inference_steps=28,
guidance_scale=4,
).images[0]Para ver o resultado editado dentro do Jupyter Notebook:
image_3O resultado é super realista. O modelo mantém a estrutura facial e o tom de pele da mulher, enquanto a coloca naturalmente em um novo cenário com iluminação, clima e fundo diferentes.
O resultado parece menos uma edição feita por IA e mais uma foto tirada por um fotógrafo profissional em um lugar e momento diferentes.

Pela minha experiência, rodar o FLUX.2 localmente só ficou confiável depois que mudei para o modelo quantizado de 4 bits e usei uma configuração code-first com Transformers e Diffusers.
Antes, eu ficava recebendo erros de memória insuficiente em uma RTX 3090 de 24 GB quando tentava carregar muita coisa diretamente na CUDA.
Ferramentas de interface do usuário como Stable Diffusion WebUI e ComfyUI também podem atingir os limites de memória mais facilmente, porque muitas vezes mantêm buffers intermediários extras, visualizações e o estado do fluxo de trabalho na memória, a menos que você ajuste cuidadosamente suas opções de VRAM baixa.
Dicas para otimizar a VRAM (o que realmente me ajudou):
device_map="cpu") e evite enviar tudo para a CUDA logo de cara.pipe.enable_model_cpu_offload()) para que apenas as partes ativas fiquem na GPU.nvidia-smi e feche todos os outros aplicativos que usam muito a GPU.Se você ainda estiver enfrentando problemas de falta de memória depois de seguir essas etapas, consulte este caderno do DataLab para ver mais exemplos de solução de problemas e otimização de memória.
Estou realmente impressionado com o quanto os modelos de geração de imagens de código aberto evoluíram.
Modelos como o FLUX.2 agora são claramente competitivos com sistemas proprietários, tanto em termos de qualidade visual quanto de compreensão rápida. Com a configuração certa, algumas experiências e um pouco de otimização de memória, dá pra gerar imagens realistas e de alta qualidade localmente e de graça, mesmo em GPUs comuns.
O que mais chama a atenção é o nível de controle. Sugestões avançadas, JSON estruturado, edição com várias referências e fluxos de trabalho de imagem para imagem facilitam ir além das gerações simples.
Você pode criar cenas cinematográficas, desenvolver imagens para contar histórias, fazer edições de imagens com qualidade profissional e iterar rapidamente sem depender de plataformas fechadas.
Para criadores, pesquisadores e desenvolvedores, isso abre muitas possibilidades de liberdade criativa e torna a geração de imagens de alta qualidade mais acessível do que nunca.
Cursos mais populares do DataCamp
Curso
Curso
Curso
blog
Dr Ana Rojo-Echeburúa
9 min
Tutorial
Tutorial
Tutorial
Zoumana Keita
Tutorial
Arjun Sarkar
Tutorial
Abid Ali Awan



