
Cours
Ajustement fin avec Llama 3
2 h
3.7K
Dans ce tutoriel, nous allons apprendre à exécuter localement le modèle de génération d'images FLUX.2. Nous allons configurer l'environnement GPU, télécharger une version quantifiée de FLUX.2, la charger efficacement dans la mémoire GPU et RAM, exécuter l'inférence, puis tester différentes options de configuration.
L'exécution d'un modèle de cette taille sur une RTX 3090 peut s'avérer complexe. Ce tutoriel se concentre sur la méthode la plus simple et la plus pratique pour faire fonctionner FLUX.2 localement sans complexité inutile.
Si vous êtes intéressé par les techniques avancées de gestion et d'optimisation des modèles, notamment l'élagage, la quantification et la journalisation, je vous recommande de suivre le cours cours « Modèles d'IA évolutifs avec PyTorch Lightning ». .
FLUX.2 est un modèle de génération d'images conçu pour un travail créatif réel, et non pas uniquement à des fins expérimentales. Il génère des images réalistes de haute qualité tout en assurant la cohérence des personnages, des styles et des produits dans plusieurs images de référence. Basé sur le modèle original modèle FLUX, il suit les instructions avec précision, affiche clairement le texte et gère efficacement l'éclairage, les mises en page et l'image de marque.
FLUX.2 prend également en charge l'édition d'images en haute résolution et est disponible à la fois sous forme d'API prêtes à l'emploi et de modèles ouverts que vous pouvez exécuter localement, ce qui le rend pratique, flexible et facile à intégrer dans les flux de production réels.
FLUX.2 est disponible en quatre variantes principales :
Chacun est conçu pour répondre à différents niveaux de contrôle, de performances et de besoins de déploiement.
Dans les classements plus généraux, les trois variantes FLUX.2 se classent parmi les 10 meilleurs modèles d'édition d'images du classement Artificial Analysis, FLUX.2 [max] et FLUX.2 [pro] surpassant des modèles tels que GPT-5 et les variantes FLUX.1 Kontext de la génération précédente.
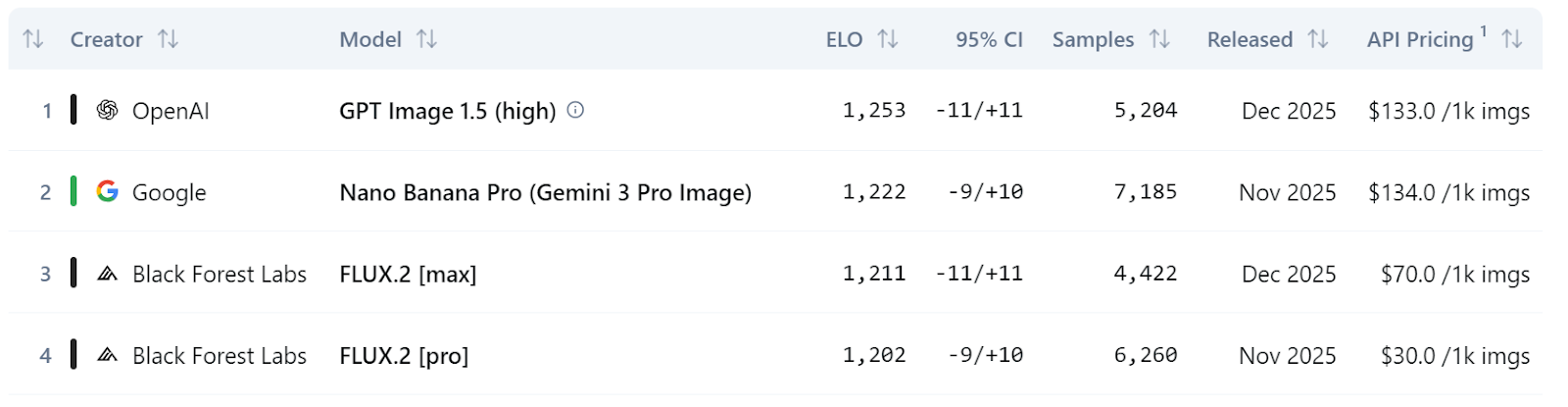
Source : Classement texte-image | Analyse artificielle
Dans les étapes ci-dessous, je vais vous expliquer tout ce que vous devez savoir pour exécuter FLUX.2 localement à l'aide d'un GPU RTX 3090.
Avant d'exécuter FLUX.2 localement, veuillez vous assurer que votre système est correctement configuré pour l'inférence GPU.
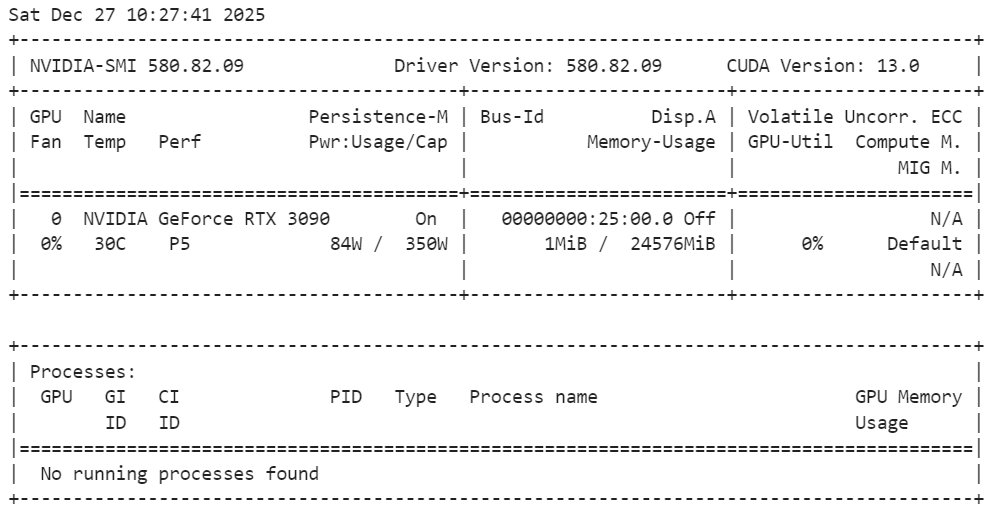
Veuillez exécuter la commande suivante dans le terminal pour vérifier l'installation :
nvidia-smiComme nous pouvons le constater, nous disposons d'un GPU RTX 3090 avec la version 13 de CUDA.
pip install jupyterlab notebookRemarque : Nous utilisons Jupyter Notebook comme environnement de codage, ce qui facilite les expérimentations, l'exécution étape par étape de l'inférence et la génération et l'édition itératives d'images directement dans le notebook.
Dans cette étape, nous installons PyTorch avec le support CUDA afin que l'inférence s'exécute sur le GPU plutôt que sur le CPU. La commande ci-dessous installe PyTorch, TorchVision et TorchAudio avec des binaires CUDA précompilés, ce qui évite d'avoir à compiler CUDA à partir du code source.
!pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu130Une fois installé, PyTorch utilisera automatiquement le GPU s'il est disponible et correctement configuré.
Ensuite, nous installons les bibliothèques principales nécessaires pour exécuter FLUX.2 localement. Ces paquets gèrent le chargement des modèles, l'inférence, l'accélération GPU et la quantification. quantificationet le transfert efficace des données.
!pip install -q diffusers transformers accelerate bitsandbytes huggingface_hub protobuf sentencepiece hf_transferUne fois installé, votre environnement est prêt à charger FLUX.2 et à commencer à générer des images et à éditer des inférences.
Avant de charger FLUX.2, nous nous assurons que PyTorch peut détecter le GPU et que la quantification 4 bits est prise en charge. Cette étape est importante pour garantir que le modèle puisse fonctionner efficacement dans les limites de mémoire d'une RTX 3090.
import torch
import bitsandbytes as bnb
print(f"PyTorch Version: {torch.__version__}")
print(f"CUDA Version: {torch.version.cuda}")
print(f"Is CUDA available? {torch.cuda.is_available()}")
print(f"GPU Name: {torch.cuda.get_device_name(0)}")
# Check if 4-bit quantization is supported (Ampere 3090 supports this natively)
try:
print(f"BitsAndBytes Version: {bnb.__version__}")
print("4-bit quantization check: PASSED")
except ImportError:
print("BitsAndBytes not installed correctly.")La sortie confirme que PyTorch est correctement installé avec la prise en charge CUDA, que votre GPU RTX 3090 est détecté et que bitsandbytes fonctionne correctement avec la quantification 4 bits activée. Le système est donc prêt pour une inférence GPU efficace.
PyTorch Version: 2.8.0+cu128
CUDA Version: 12.8
Is CUDA available? True
GPU Name: NVIDIA GeForce RTX 3090
BitsAndBytes Version: 0.49.0
4-bit quantization check: PASSEDDans cette étape, nous chargeons FLUX.2 [dev] à l'aide d'un point de contrôle quantifié sur 4 bits afin de réduire l'utilisation de la mémoire GPU tout en conservant une qualité d'image élevée. Ceci est essentiel pour exécuter un modèle volumineux tel que FLUX.2 sur une RTX 3090.
Nous commençons par importer les bibliothèques requises et définir quelques paramètres clés.
repo_id indique le point de contrôle FLUX.2 4 bits.device sélectionne votre GPU (premier périphérique CUDA).torch_dtype définit la précision de calcul utilisée lors de l'inférence. La précision de calcul « bfloat16 » est couramment utilisée car elle réduit la mémoire et peut améliorer la vitesse tout en conservant des résultats stables.import torch
from transformers import Mistral3ForConditionalGeneration
from diffusers import Flux2Pipeline, Flux2Transformer2DModel
repo_id = "diffusers/FLUX.2-dev-bnb-4bit"
device = "cuda:0"
torch_dtype = torch.bfloat16Ensuite, nous chargeons d'abord le transformateur d'images FLUX.2 (le composant principal responsable de la génération des latences d'images) sur le processeur. Cela évite de saturer la mémoire VRAM lors du chargement initial et offre au pipeline une plus grande flexibilité pour déplacer les modules vers le GPU uniquement lorsque cela est nécessaire.
transformer = Flux2Transformer2DModel.from_pretrained(
repo_id, subfolder="transformer", torch_dtype=torch_dtype, device_map="cpu"
)Ensuite, nous chargeons également l'encodeur de texte sur le processeur. L'encodeur de texte transforme votre invite en intégrations qui guident la génération d'images. Le fait de le conserver sur le processeur pendant la configuration permet de libérer la mémoire du processeur graphique pour les parties les plus lourdes du processus de génération.
text_encoder = Mistral3ForConditionalGeneration.from_pretrained(
repo_id, subfolder="text_encoder", dtype=torch_dtype, device_map="cpu"
)Enfin, nous assemblons l'ensemble du pipeline de diffuseurs. pipeline Diffusers en intégrant le transformateur et l'encodeur de texte que nous avons chargés.
La ligne clé ici est « enable_model_cpu_offload() » : elle active le déchargement automatique CPU ↔ GPU, ce qui signifie que le pipeline transfère certaines parties du modèle vers le GPU uniquement lorsqu'elles sont activement nécessaires, puis les transfère à nouveau vers le CPU par la suite. Il s'agit de l'une des méthodes les plus simples pour exécuter des modèles volumineux sur des GPU grand public sans avoir à gérer manuellement le placement des appareils.
pipe = Flux2Pipeline.from_pretrained(
repo_id, transformer=transformer, text_encoder=text_encoder, torch_dtype=torch_dtype
)
pipe.enable_model_cpu_offload()Nous sommes désormais prêts à générer notre première image à l'aide de FLUX.2. Pour simplifier, nous commençons par une seule invite textuelle qui décrit une photographie macro hyperréaliste d'une coccinelle.
prompt = (
"Realistic macro photo of a ladybug perched on the edge of a dew-covered rose petal, "
"early morning mist, soft natural light, shallow depth of field, crisp detail, creamy bokeh."
)
Ensuite, nous transmettons l'invite au pipeline et exécutons l'inférence.
image = pipe(
prompt=prompt,
generator=torch.Generator(device=device).manual_seed(42),
num_inference_steps=28,
guidance_scale=4,
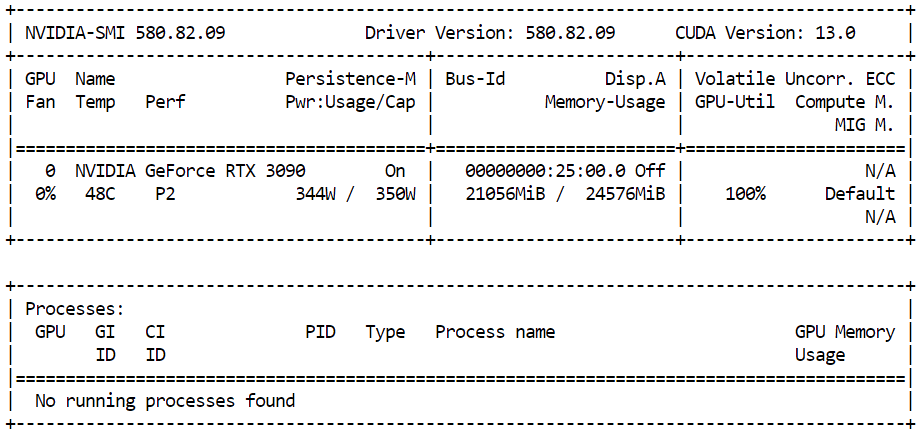
).images[0]Pour surveiller la quantité de mémoire GPU utilisée pendant l'inférence, veuillez ouvrir un terminal et exécuter :
nvidia-smiVous devriez observer une utilisation proche de 21 Go de VRAM GPU avec une utilisation élevée du GPU, ce qui indique que le modèle utilise efficacement les ressources disponibles et fonctionne à pleine performance sur la RTX 3090.
Une fois l'inférence terminée, vous pouvez visualiser l'image générée directement dans le notebook Jupyter en affichant simplement l'objet image :
imageLe résultat est extrêmement détaillé et réaliste. Le modèle suit scrupuleusement les instructions tout en ajoutant des détails subtils, tels que l'éclairage et la texture, qui n'étaient pas explicitement spécifiés.

Enfin, nous enregistrons l'image générée localement :
output_path = "flux2_local_full.png"
image.save(output_path)
print(f"Image saved to {output_path}")Résultat :
Image saved to flux2_local_full.pngFLUX.2 prend en charge des techniques avancées de prompting qui vont au-delà du texte brut, permettant un contrôle beaucoup plus précis de l'image finale. À l'aide d'invites JSON structurées, vous pouvez définir explicitement la disposition de la scène, les sujets, l'éclairage, les réglages de la caméra, l'ambiance et même les palettes de couleurs à l'aide de codes hexadécimaux précis.
Dans cette section, nous utilisons une invite JSON structurée pour décrire la scène en détail. Au lieu d'une seule phrase, nous définissons l'environnement, les sujets, le style, les couleurs, l'éclairage, les propriétés de la caméra et les contraintes négatives dans un format clair et organisé.
Cela permet à FLUX.2 de mieux comprendre les instructions complexes et de produire des résultats plus prévisibles et de meilleure qualité.
advanced_prompt = """
{
"scene": "New Year's Eve night on a rooftop overlooking a glowing city skyline",
"subjects": [
{
"description": "Group of close friends including men and women in winter clothing, natural facial proportions, diverse appearances",
"position": "center and slightly spread across the frame",
"action": "standing together in a loose circle, some smiling softly, others quietly reflective, sharing the moment before midnight"
}
],
"style": "Cinematic semi-realistic illustration with grounded realism, subtle painterly softness",
"color_palette": ["#0B132B", "#1C2541", "#EAEAEA", "#F4D35E"],
"lighting": "Soft moonlight as ambient key light, warm glow from sparklers and nearby string lights illuminating faces, gentle contrast",
"mood": "Warm, intimate, reflective, hopeful",
"background": "Out-of-focus city skyline with distant fireworks softly lighting the sky, minimal visual noise",
"composition": "Wide medium shot, balanced framing, friends forming a natural arc, negative space above for sky and fireworks",
"camera": {
"angle": "eye-level",
"lens": "50mm cinematic look",
"depth_of_field": "sharp focus on group, gentle background blur"
},
"details": [
"subtle breath vapor in cold air",
"soft fabric textures on coats and scarves",
"sparklers emitting warm golden particles",
"natural body language and expressions",
"no exaggerated poses or faces"
],
"negative_prompt": [
"cartoon style",
"emote proportions",
"chibi",
"oversized heads",
"text",
"watermark",
"logo",
"overcrowded scene",
"harsh neon lighting",
"over-saturation",
"extra limbs",
"distorted faces"
]
}
"""Nous effectuons ensuite une inférence avec un nombre plus élevé d'étapes afin de capturer davantage de détails tout en conservant une échelle de guidage modérée pour un rendu naturel.
image_2 = pipe(
prompt=advanced_prompt,
generator=torch.Generator(device=device).manual_seed(42),
num_inference_steps=50,
guidance_scale=4,
).images[0]Pour afficher l'image générée dans le notebook Jupyter :
image_2L'image obtenue suit de près les instructions structurées, capturant la scène, l'ambiance, l'éclairage et la composition exactement comme spécifié.

FLUX.2 prend également en charge l'édition d'images, où une image de référence est utilisée comme base et le modèle applique des modifications guidées par une invite textuelle. Cette fonctionnalité est particulièrement utile lorsque vous souhaitez conserver l'identité, les traits du visage et le teint de la peau, tout en modifiant la scène, l'ambiance ou l'environnement autour du sujet.
Pour cet exemple, nous utilisons une photographie d'une femme indienne provenant du site Pexels.com comme image de référence :

Photo par cottonbro studio : https://www.pexels.com/photo/a-woman-with-a-nose-piercing-9317190/
Nous concevons soigneusement la consigne afin d'indiquer au modèle de conserver le visage et les tons naturels de la peau de la femme, tout en modifiant le décor, l'éclairage et l'expression émotionnelle. L'objectif est de modifier l'image sans altérer son identité.
from diffusers.utils import load_image
prompt = (
"Using the provided reference image, generate a realistic photograph of a woman with a similar face, "
"standing at night and looking up at the sky with stars with a subtle, sad expression. "
"Natural skin tones, soft moonlight, gentle shadows, shallow depth of field, "
"with blurred city lights in the background."
)Ensuite, nous chargeons l'image de référence et la transmettons au pipeline. FLUX.2 prend en charge plusieurs images de référence, mais nous utilisons ici une seule image pour guider la modification.
indian_woman = load_image("https://images.pexels.com/photos/9317190/pexels-photo-9317190.jpeg")
image_3 = pipe(
prompt=prompt,
image=[indian_woman],
generator=torch.Generator(device=device).manual_seed(42),
num_inference_steps=28,
guidance_scale=4,
).images[0]Pour visualiser le résultat modifié dans le notebook Jupyter :
image_3Le résultat est extrêmement réaliste. Le modèle conserve la structure faciale et le teint de la femme tout en l'intégrant naturellement dans un nouveau décor avec un éclairage, une ambiance et un arrière-plan différents.
Le résultat ressemble moins à une retouche effectuée par une intelligence artificielle qu'à une photographie prise par un photographe professionnel dans un lieu et à un moment différents.

D'après mon expérience, l'exécution locale de FLUX.2 n'est devenue fiable qu'après être passé au modèle quantifié 4 bits et avoir utilisé une configuration « code-first » avec Transformers et Diffusers.
Auparavant, je rencontrais régulièrement des erreurs de mémoire insuffisante sur une RTX 3090 de 24 Go lorsque je tentais de charger trop de données directement sur CUDA.
Les outils d'interface utilisateur tels que Stable Diffusion WebUI et ComfyUI peuvent également atteindre plus facilement les limites de mémoire, car ils conservent souvent des tampons intermédiaires supplémentaires, des aperçus et l'état du flux de travail en mémoire, à moins que vous ne régliez soigneusement leurs options de faible VRAM.
Conseils pour optimiser la VRAM (ce qui m'a réellement aidé) :
device_map="cpu") et éviter de transférer tout vers CUDA dès le début.pipe.enable_model_cpu_offload()) afin que seules les parties actives soient gérées par le GPU.nvidia-smi et fermer toutes les autres applications gourmandes en ressources GPU.Si vous rencontrez toujours des problèmes de mémoire insuffisante après avoir suivi ces étapes, veuillez consulter ce cahier DataLab pour obtenir des exemples supplémentaires de dépannage et d'optimisation de la mémoire.
Je suis sincèrement impressionné par les progrès réalisés par les modèles de génération d'images open source.
Les modèles tels que FLUX.2 sont désormais clairement compétitifs par rapport aux systèmes propriétaires, tant en termes de qualité visuelle que de compréhension rapide. Avec une configuration adéquate, quelques essais et une optimisation de la mémoire, il est possible de générer localement et gratuitement des images réalistes de haute qualité, même sur des processeurs graphiques grand public.
Ce qui ressort le plus, c'est le niveau de contrôle. Les invites avancées, le JSON structuré, l'édition multi-références et les flux de travail image à image facilitent la réalisation de tâches plus complexes que de simples générations.
Vous pouvez créer des scènes cinématiques, faire évoluer des images pour raconter des histoires, effectuer des retouches d'images de qualité professionnelle et itérer rapidement sans dépendre de plateformes fermées.
Pour les créateurs, les chercheurs et les développeurs, cela offre une grande liberté créative et rend la génération d'images haut de gamme plus accessible que jamais.
Meilleurs cours DataCamp
Cours
Cours
Cours
blog
Kurtis Pykes
9 min
blog
Nisha Arya Ahmed
15 min
blog
Kurtis Pykes
15 min