

programa
Desarrollar grandes modelos lingüísticos
16 h
¿Has soñado alguna vez con ejecutar tu propio ChatGPT directamente en tu portátil?
Con los rápidos avances en los Modelos de Grandes Lenguajes (LLM), la posibilidad de llevar esos potentes modelos al hardware de consumo se está convirtiendo en una realidad.
La clave para liberar este potencial reside en la cuantización, una técnica que permite reducir el tamaño de estos modelos cada vez más grandes para que se ejecuten en dispositivos cotidianos con una degradación mínima del rendimiento- ¡si se aplica correctamente!
En esta guía, profundizaremos en el concepto de cuantización, explicando cómo funciona y las distintas posibilidades de cuantizar los LLM. Por último, cuantizaremos nuestro modelo en dos sencillos pasos utilizando la biblioteca Quanto de Hugging Face.
¡Vamos a profundizar! Puedes seguirlo utilizando el DataCamp DataLab.
A medida que los LLM han evolucionado, su complejidad ha crecido exponencialmente, lo que ha provocado un aumento significativo de su número de parámetros. Por ejemplo, el primer modelo GPT, lanzado en 2018, tenía 0,11 mil millones de parámetros. A finales de 2019, GPT-2 lo amplió a 1.500 millones, y GPT-3, publicado a finales de 2020, lo disparó a 175.000 millones de parámetros.
En la actualidad, la GPT-4 cuenta con más de 1 billón de parámetros. Este gran aumento supone un reto: a medida que crecen los modelos, también lo hacen sus requisitos de memoria, que a menudo superan la capacidad de los aceleradores de hardware avanzados, como las GPU.
Esta creciente demanda de memoria limita tanto el entrenamiento como el alojamiento de los modelos para la inferencia, restringiendo en consecuencia la accesibilidad y adopción de soluciones basadas en LLM.
Este crecimiento conduce a una necesidad acuciante de hacer más accesibles estos modelos reduciendo su tamaño. Al cambiar la precisión de algunos componentes del modelo, la cuantización reduce la huella de memoria del modelo manteniendo niveles de rendimiento similares.
La cuantización es una técnica de compresión de modelos que convierte los pesos y las activaciones de un gran modelo lingüístico de valores de alta precisión a otros de menor precisión. Esto significa cambiar los datos de un tipo que puede contener más información a otro que contiene menos. Un ejemplo típico es convertir datos de un número de coma flotante de 32 bits a un entero de 8 bits.
Reducir el número de bits necesarios para cada uno de los pesos o activaciones del modelo conlleva una disminución significativa de su tamaño total. En consecuencia, la cuantización reduce los LLM a consumen menos memoria, requieren menos espacio de almacenamiento y los hace más eficientes energéticamente.
Una analogía eficaz para entender la cuantización es la compresión de imágenes. Las imágenes de alta resolución suelen comprimirse para utilizarlas en los sitios web. Consiste en reducir el tamaño de la imagen eliminando algunos datos o bits de información. Aunque esto suele reducir la calidad de la imagen en cierta medida, también disminuye las dimensiones de la imagen y el tamaño del archivo, haciendo que las páginas web se carguen más rápido sin dejar de ofrecer una experiencia visual satisfactoria.
Esquema de compresión de imágenes para una carga más rápida en aplicaciones como páginas web.
Del mismo modo, la cuantización de un LLM reduce sus requisitos computacionales, lo que le permite funcionar en un hardware menos potente sin dejar de ofrecer un rendimiento adecuado. Las imágenes comprimidas son más fáciles de manejar, al igual que los modelos cuantizados son más desplegables en diversas plataformas, aunque hay una ligera compensación en el detalle o la precisión. Como veremos, el proceso de cuantización también introduce algo de ruido.
La cuantización se aplica normalmente a los pesos de un modelo lingüístico grande, aunque también puede aplicarse a las activaciones. Los pesos del modelo son parámetros de una red neuronal que determinan la fuerza de las conexiones entre neuronas de distintas capas. Los pesos son esencialmente los coeficientes aprendidos que transforman los datos de entrada a medida que pasan por la red.
Los pesos se fijan inicialmente en valores aleatorios, sin sentido, y se ajustan durante el entrenamiento en función del error entre la salida prevista y los objetivos reales. Este proceso de ajuste se guía por algoritmos de optimización como el descenso de gradiente.
Si quieres saber más sobre el funcionamiento interno de los LLM, el curso Desarrollo de grandes modelos lingüísticos ¡es para ti!
Una opción para cuantizar un modelo es reducir la precisión de sus pesos de modelo. Para ilustrarlo, centrémonos en la matriz de la izquierda de la imagen siguiente, que representa una matriz 3x3 de pesos con una precisión de cuatro decimales:
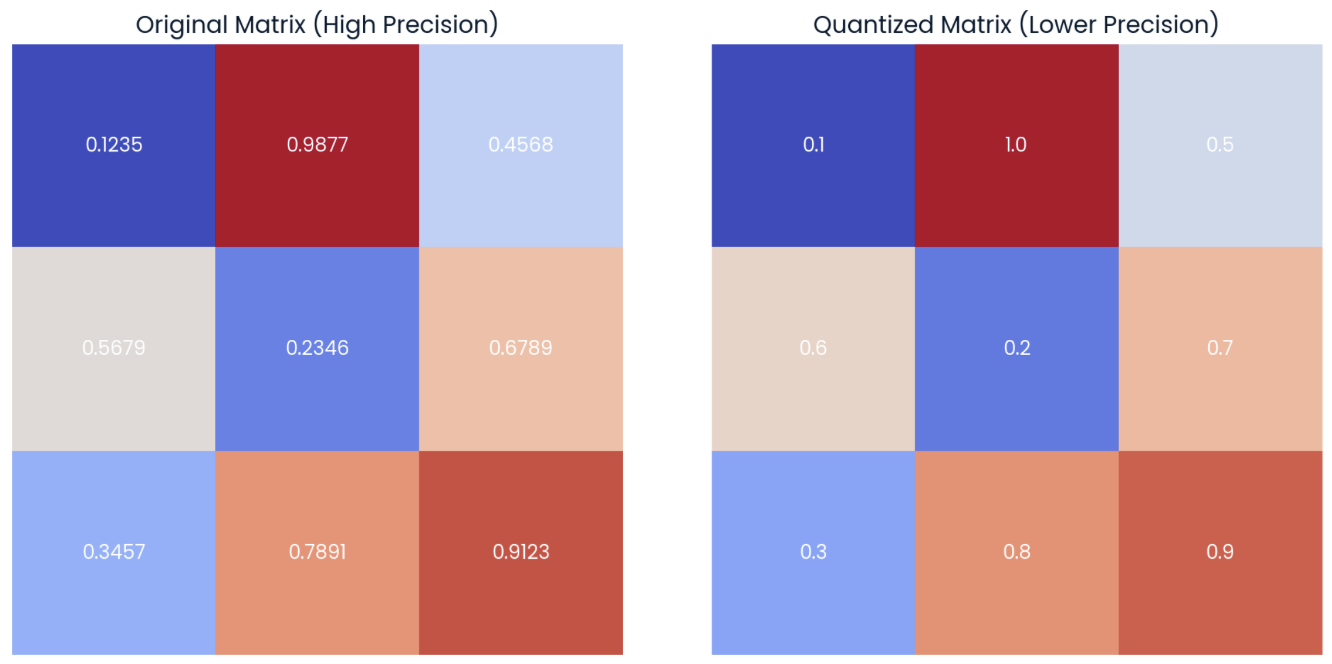
Ejemplo de una matriz aleatoria de pesos con precisión de cuatro decimales (izquierda) con su forma cuantificada (derecha) aplicando el redondeo a precisión de un decimal.
En la matriz de la derecha, podemos observar la versión cuantizada de la matriz original. Esta matriz "cuantizada" se calcula redondeando los elementos de la matriz original a un decimal.
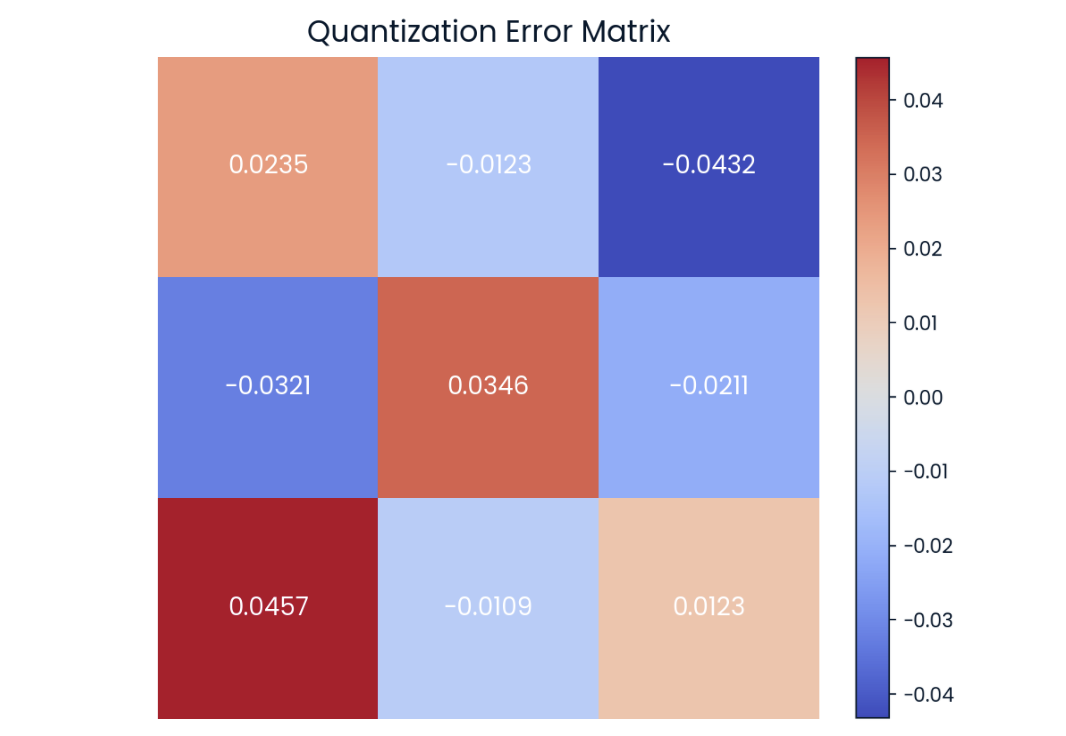
Podemos observar que las matrices anteriores no son completamente iguales, pero son muy parecidas. La diferencia valor a valor se conoce comoerror de cuantización , que también podemos representar en forma matricial:
Error de cuantificación en la matriz de. Cuanto más oscuro sea el color, mayor será el error.
La investigación actual en cuantización se centra en intentar reducir al máximo esta diferencia para evitar cualquier degradación del rendimiento.
En este sencillo ejemplo, sólo estamos redondeando los elementos de la matriz. En la práctica, la cuantización se realiza convirtiendo los valores numéricos a un tipo de datos diferente, por ejemplo, de un tipo de datos de mayor precisión a otro de menor precisión. Por ejemplo, el tipo de datos de almacenamiento por defecto para la mayoría de los modelos es float32.
En este caso, tendríamos que asignar 4 bytes por parámetro (4 veces la precisión de 8 bits). Por tanto, para una matriz de 3x3 como la del ejemplo, la huella de memoria total de esta matriz es de 36 bytes.
Cambiando el tipo de datos -también conocido como downcasting- a int8, sólo necesitaríamos un byte por parámetro. Por tanto, la huella de memoria total de la matriz se convierte en 9 bytes.
El tipo de datos seleccionado para las ponderaciones del modelo determina cuánto podemos reducir el modelo. Los tipos tradicionales de coma flotante, como float32 y float16, han sido el estándar en muchas aplicaciones de aprendizaje automático, ya que proporcionan un equilibrio entre precisión y eficiencia computacional. En concreto, aunque float32 ofrece una gran precisión y un amplio rango dinámico, requiere más memoria y potencia de cálculo. Por el contrario, float16 ofrece una precisión y un alcance reducidos, lo que acelera considerablemente los cálculos.
float32y float16. Esto llevó a la creación del llamado Punto Flotante Cerebral (bfloat16), que conserva el rango dinámico de float32 pero con una precisión reducida.
Downcasting es el término formal para convertir un tipo de datos de mayor precisión en un tipo de datos de menor precisión. Al utilizar el downcasting, reducimos la huella de memoria y aumentamos la velocidad, ya que los cálculos que utilizan menor precisión también requieren menos memoria.
En esta sección, exploraremos cómo funciona el downcasting desde float32- el tipo de datos de almacenamiento por defecto de la mayoría de los modelos- al tipo de datos de Google bfloat16y observaremos cómo suele provocar alguna pérdida de datos.
Empecemos definiendo un tensor aleatorio en PyTorch con elementos de tipo float32 y mostrando los cinco primeros elementos:
import torch
# random pytorch tensor: float32, size=1000
tensor_fp32 = torch.rand(1000, dtype = torch.float32)
print(tensor_fp32[:5])
>> tensor([0.2257, 0.0480, 0.8520, 0.3115, 0.1373])Ahora podemos reducir el tensor a bfloat16 utilizando el método .to(dtype) y observar los 5 primeros elementos nuevos:
# downcast the tensor to bfloat16 using the "to" method
tensor_fp32_to_bf16 = tensor_fp32.to(dtype = torch.bfloat16)
print(tensor_fp32_to_bf16[:5])
>> tensor([0.2256, 0.0481, 0.8516, 0.3105, 0.1377], dtype=torch.bfloat16)Como vemos, los valores son bastante próximos, aunque no iguales. La diferencia se hace más notable cuando empezamos a realizar operaciones con los valores. Por ejemplo, al multiplicar el tensor original por sí mismo:
# tensor_fp32 x tensor_fp32
m_float32 = torch.dot(tensor_fp32, tensor_fp32)
print(m_float32)
>> tensor(322.1082)Si realizamos el mismo cálculo con el tensor cuantizado, vemos que la diferencia es mayor:
# tensor_fp32_to_bf16 x tensor_fp32_to_bf16
m_bfloat16 = torch.dot(tensor_fp32_to_bf16, tensor_fp32_to_bf16)
print(m_bfloat16)
>> tensor(256., dtype=torch.bfloat16)Podemos observar una clara diferencia entre los resultados finales debido a la propagación del error.
El mismo efecto de propagación de errores al operar con tensores cuantizados se produce al reducir los LLM, lo que provoca una pérdida de información. Como hemos visto, utilizar menos memoria implica que el cálculo puede ser menos preciso. El efecto de la multiplicación es similar a la propagación real del error capa por capa, que se acumula y acaba afectando a algunas predicciones de fichas.
Con el downcasting, el rendimiento sigue siendo aceptable cuando se utiliza el tipo bfloat16 pero no con tipos de datos más pequeños.
El downcasting no se suele utilizar como técnica de cuantización eficaz debido a esta restricción en los tipos de datos. En su lugar, se utilizan otros métodos que mantienen un rendimiento más próximo al modelo original mediante la conversión a float32 durante la inferencia.
Hay varios tipos de cuantización, y a continuación describimos cada uno en detalle:
La cuantización lineal es uno de los esquemas de cuantización más populares para los LLM. En términos sencillos, consiste en mapear uniformemente el rango de valores en coma flotante de los pesos originales a un rango de valores en coma fija, utilizando el tipo de datos de alta precisión para la inferencia.
Para simplificarlo al máximo, repasemos los pasos necesarios para aplicar la cuantización lineal a un modelo. Ten en cuenta que las fórmulas reales se muestran en la imagen de abajo:
s) y el punto cero (s): La escala ajusta el rango de valores de coma flotante para que quepan dentro del rango de enteros. El punto cero garantiza que cero en el rango de punto flotante esté representado con precisión por un número entero, manteniendo la precisión y estabilidad numérica, especialmente para valores cercanos a cero.q ): Este paso consiste en mapear valores de coma flotante a un rango de enteros de menor precisión utilizando un factor de escala s y un punto ceros calculado en el paso anterior. La operación de redondeo garantiza que el resultado final sea un número entero discreto, adecuado para el almacenamiento y el cálculo en formatos de menor precisión.Asociemos cada uno de los pasos descritos anteriormente con su fórmula correspondiente:
Ecuaciones de cuantización utilizadas para aplicar la cuantización lineal a cualquier matriz de pesos.
¿Es difícil imaginar cómo aplicar estas fórmulas? ¡Pongámonos manos a la obra!
Si aplicamos estas fórmulas al tensor de pesos 3x3 de la izquierda de la imagen siguiente, obtendremos la matriz cuantizada que se muestra a la derecha. Te recomiendo que dediques unos minutos a calcular los valores máximo y mínimo del rango cuantizado y algunos de los valores cuantizados:
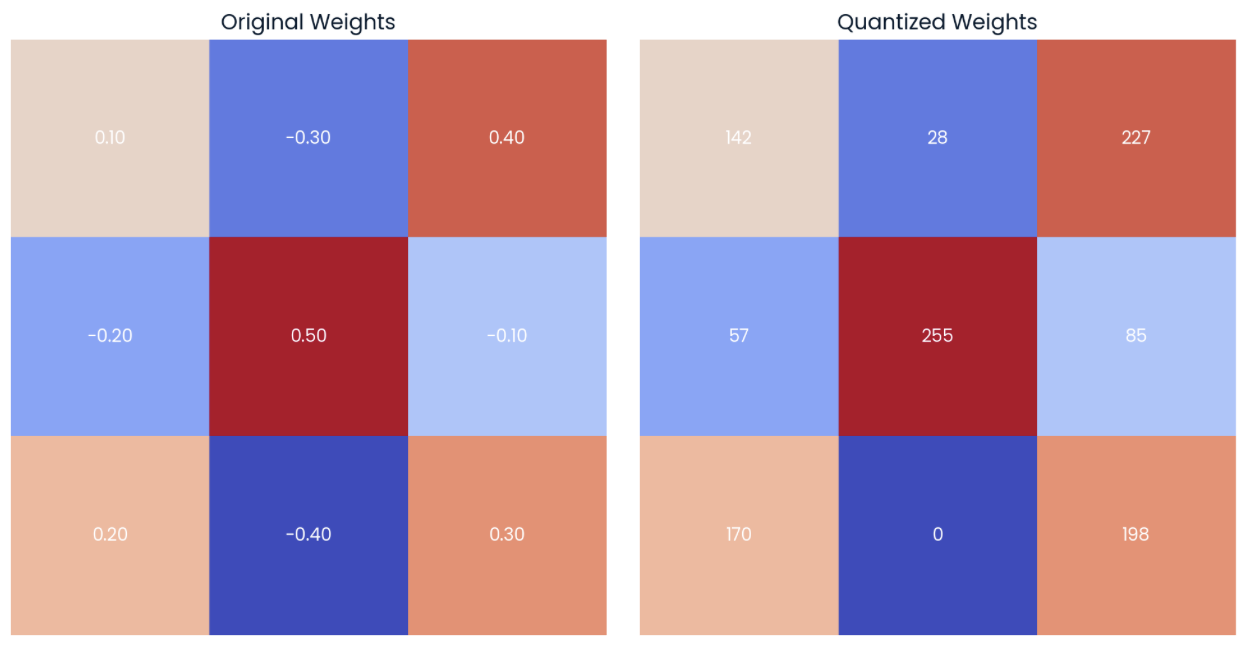
Ejemplo de una matriz aleatoria de pesos con precisión de dos decimales (izquierda) con su forma cuantizada (derecha) a int8 tipo de datos.
Podemos ver que el límite inferior del valor int8 corresponde al valor inferior del tensor original (-0.40 → 0), mientras que el límite superior corresponde al valor superior del tensor original (0.50 → 255).
Si ahora descuantificamos los valores utilizando la fórmula (4), podemos ver que los valores descuantificados se aproximan a los valores originales (matriz de la izquierda). Podemos calcular el error de cuantización calculando la diferencia punto por punto (matriz de la derecha):
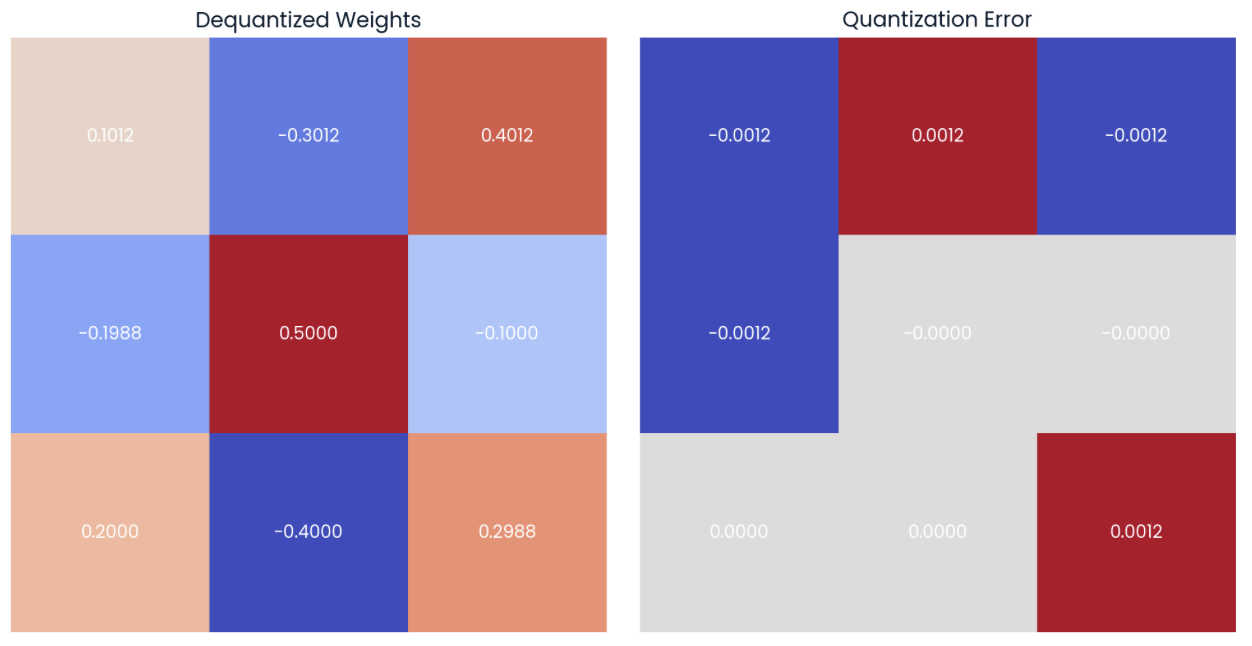
Los valores se pueden descuantificar utilizando los pesos cuantificados y los valores de escala y punto cero (izquierda). Se puede calcular la diferencia punto por punto o error de cuantificación (derecha).
La cuantización lineal reduce el tamaño del modelo almacenando en memoria sólo los pesos cuantizados y los valores de escala y punto cero, mientras los utiliza para calcular los pesos originales para la inferencia y mantener el rendimiento.
La cuantización lineal es una opción popular por su sencillez, pero hay múltiples formas de construir un mapeo. Otro método bastante popular hoy en día es lacuantización Blockwise , que es más precisa que la cuantización lineal para modelos con distribuciones de pesos no uniformes.
La cuantificación en bloques es un método más sofisticado que consiste en cuantificar los pesos en bloques más pequeños en lugar de en todo el rango. Este método se basa en dos conceptos clave:
Durante nuestros ejemplos de matrices, nos hemos centrado principalmente en el proceso de cuantificación de los pesos de un modelo. Aunque la cuantización del peso es un paso crucial para la optimización del modelo, también es importante tener en cuenta que las activaciones de un modelo también se pueden cuantizar.
Cuantificación de la activación se refiere al proceso de reducir la precisión de las salidas intermedias de cada capa de la red. A diferencia de los pesos, que son estáticos (constantes) una vez entrenado el modelo, las activaciones son dinámicas. Esto significa quelas activaciones de cambian con cada entrada a la red, lo que hace que su alcance sea más difícil de predecir.
En general, la cuantización por activación es más difícil de aplicar que la cuantización por peso. Requiere una calibración cuidadosa para garantizar que se capta bien el rango dinámico de las activaciones.
La cuantización por peso y la cuantización por activación son técnicas complementarias. Aplicando ambas técnicas, podemos conseguir mejoras significativas en el tamaño del modelo sin comprometer demasiado el rendimiento.
La cuantificación también puede realizarse en distintos momentos. Si tomamos un modelo preentrenado y cuantizamos los parámetros del modelo durante la fase de inferencia, estamos realizando una Cuantización Postentrenamiento (PTQ).
Este método no implica ningún cambio en el propio proceso de entrenamiento. El rango dinámico de los parámetros se recalcula en tiempo de ejecución, de forma similar a como trabajamos con las matrices de ejemplo.
Por otro lado, también existe la opción de aplicar la Formación Consciente de la Cuantización (QAT). Este enfoque consiste en modificar el proceso de entrenamiento para simular los efectos de la cuantización durante el entrenamiento. El modelo se entrena para que sea robusto al ruido de cuantización, lo que se traduce en una mayor precisión.
Durante el QAT, los estados intermedios del entrenamiento contienen tanto una versión cuantizada de los pesos como los pesos originales sin cuantizar (¡también en memoria!). Por lo tanto, utilizamos la versión cuantizada del modelo para la inferencia, pero la versión no cuantizada de los pesos del modelo se actualizará durante la retropropagación.
Como era de esperar aunque es más complejo y requiere más tiempo, el QAT suele dar como resultado una mayor precisión en comparación con el PTQ.
Algunos métodos de cuantización requieren un paso de calibración. Por ejemplo, debemos determinar el rango de activación original de un modelo antes de la cuantización. La calibración general suele implicar la ejecución de la inferencia en un conjunto de datos representativo para optimizar los parámetros de cuantización y minimizar el error de cuantificación.
Durante este proceso de calibración, el algoritmo de cuantización recoge estadísticas sobre la distribución y el rango de las activaciones y pesos del modelo. Estas estadísticas ayudan a determinar los mejores parámetros de cuantización. Calcular la escala y el punto cero al cuantizar los pesos también es una especie de calibración, pero hay otros tipos:
Sin embargo, los métodos de cuantización como QLoRA pueden utilizarse sin ningún paso de calibración.
Estos métodos suelen sustituir todas las capas lineales del modelo por capas lineales cuantizadas (QLinear). Las capasQLinear están diseñadas para manejar la cuantización internamente, eliminando así la necesidad de un paso adicional de calibración. Esto hace que el proceso de cuantización sea más sencillo de aplicar, manteniendo el rendimiento del modelo.
Varias herramientas y bibliotecas en Python admiten la cuantización, proporcionando herramientas tanto para PTQ como para QAT. Por ejemplo, pytorch y tensorflow proporcionan métodos de cuantización, aunque integrar la cuantización sin problemas en los modelos existentes requiere un profundo conocimiento de las bibliotecas y de las partes internas del modelo. Consulta opciones de cuantización en la documentación oficial de PyTorch.
Si estás interesado en aprender estos potentes frameworks, te recomiendo el curso Aprendizaje profundo en Python.
Mi opción favorita para implementar la cuantización en sencillos pasos hasta ahora es el Quanto de Hugging Face, diseñada para simplificar el proceso de cuantización de los modelos PyTorch.
Un flujo de trabajo de cuantización típico utilizando la biblioteca Quanto de Hugging Face consistiría en los siguientes pasos:
1. Selecciona y carga un modelo preentrenado y su correspondiente tokenizador. En este caso, vamos a utilizar el Pythia 410M de EuletherAI:
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "EleutherAI/pythia-410m"
model = AutoModelForCausalLM.from_pretrained(model_name,
low_cpu_mem_usage=True)
tokenizer = AutoTokenizer.from_pretrained(model_name)El método model.gpt_neox puede ayudar a visualizar las distintas capas del modelo cargado:
print(model.gpt_neox)
Esquema por capas del modelo original. El modelo se compone de distintos tipos de capas, como capas lineales y capas de normalización.
Podemos comprobar que el modelo funciona correctamente realizando algunas inferencias de prueba. Por ejemplo,
text = "Once upon a time, there was a"
inputs = tokenizer(text, return_tensors="pt")
outputs = model.generate(**inputs, max_new_tokens=10)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
Además, como la cuantización del modelo nos permitirá reducir su tamaño, también es interesante comprobar el tamaño original del modelo antes de iniciar el proceso:
import torch
module_sizes = compute_module_sizes(model)
print(f"The model size is {module_sizes[''] * 1e-9} GB")
Nota: En el DataCamp DataLab podemos encontrar el método compute_module_sizes() implementado.
Por último, también podemos visualizar los tensores densos del modelo original de la siguiente manera:
print(model.gpt_neox.layers[0].attention.dense.weight)
Como podemos observar, se parece a la matriz no cuantificada con la que hemos estado trabajando durante este artículo.
2. Cuantizar. El método quantize() permite convertir directamente el modelo estándar predeterminado de flotador en un modelo cuantizado.
from quanto import quantize, freeze
quantize(model, weights=torch.int8, activations=None)En este caso, estamos cuantizando sólo los pesos del modelo a un tipo de datosint8. Este método convierte el modelo para que utilice aritmética de menor precisión, incluido el paso de calibración.
Si ahora imprimimos las capas del modelo, veremos que las capas lineales originales (Linear) se han sustituido por capas lineales cuantizadas (QLinear):
print(model)
Esquema por capas del modelo cuantizado. Observa cómo todas las capas lineales originales se han convertido en capas lineales cuantizadas ( QLinear).
Sin embargo, si imprimimos la matriz de pesos, veremos que no se han transformado:
print(model.gpt_neox.layers[0].attention.dense.weight)
3. Freeze. Para aplicar el efecto de cuantización a los pesos, tenemos que utilizar el método freeze().
freeze(model)Este método incorpora los parámetros de cuantización en el modelo, convirtiendo efectivamente los pesos al tipo de datos objetivo. Observemos ahora los parámetros cuantificados del modelo:
print(model.gpt_neox.layers[0].attention.dense.weight)
Como podemos ver, los pesos están ahora dentro del rango del tipo de datos Pytorch int8 de Pytorch.
4. Comprobaciones finales. Una vez cuantizado el modelo, podemos comprobar el nuevo tamaño reducido del modelo:
module_sizes = compute_module_sizes(model)
print(f"The model size is {module_sizes[''] * 1e-9} GB")
¡Hemos conseguido un modelo que sólo ocupa el 35% del tamaño original!
Por último, comprobemos el nuevo rendimiento del modelo con una simple inferencia:
outputs = model.generate(**inputs, max_new_tokens=10)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
Por supuesto, comprobar el rendimiento con una sola inferencia no tiene sentido, por lo que sería una buena práctica definir un método cuantitativo para evaluarlo.
¡Ahora es tu momento de intentarlo!
Las crecientes demandas de memoria de los LLM limitan tanto su entrenamiento como su alojamiento para la inferencia, restringiendo en consecuencia la accesibilidad y la adopción de aplicaciones basadas en LLM.
En este artículo hemos introducido el concepto de cuantización, que consiste en reducir la precisión de los pesos y las activaciones del modelo para disminuir su huella de memoria y sus requisitos computacionales. Este proceso ayuda a que los modelos sean más eficientes y accesibles, sobre todo para su despliegue en dispositivos con recursos limitados.
Abordamos esta técnica utilizando algunos ejemplos, redondeando los valores numéricos de las ponderaciones. Después, pasamos a un tipo sencillo de cuantización conocido como downcasting. Al reducir un modelo, los parámetros se convierten a un tipo de datos más compacto, como bfloat16para la inferencia. Aunque esto permite al modelo realizar cálculos y activaciones en este tipo de datos más pequeño, el rendimiento suele degradarse con el tamaño del tipo de datos, siendo ineficaz con tipos enteros como int8.
Para solucionarlo, introdujimos lacuantización lineal, que mantiene el rendimiento más próximo al modelo original convirtiéndolo de nuevo a float32 durante la inferencia. Esto permite utilizar tipos de datos aún más pequeños, como int8.
Recorrimos los pasos numéricos de la aplicación de la cuantización lineal e implementamos nuestra cuantización del peso utilizando la bibliotecaQuanto de Hugging Face. En particular, con la biblioteca Quanto, podemos cuantizar cualquier modelo PyTorch, incluidos los disponibles en Hugging Face.
Para los interesados en probar modelos más pesados como LLaMa 2 o Mistralconsidera la posibilidad de actualizar tu espacio DataCamp a Premium para obtener más potencia de cálculo.
![]()
Para modelos más grandes, es posible que necesitemos recursos adicionales a los que se puede acceder en el Plan DataCamp Premium.
Dominando las técnicas de cuantización podemos liberar todo el potencial de los Modelos de Lenguaje de Gran Tamaño requiriendo menos recursoshaciendo que la IA avanzada sea más eficaz, accesible y versátil.
¡Espero que este artículo te ayude a ponerte manos a la obra con la cuantización para LLMs!
Los mejores cursos LLM
programa
Curso
Curso
blog
Abid Ali Awan
10 min
Tutorial
Abid Ali Awan
Tutorial
Zoumana Keita
Tutorial
Moez Ali



