
Curso
Modelado de datos en Power BI
3 h
94.8K
Antes de sumergirnos en la arquitectura de Snowflake, repasemos los almacenes de datos para asegurarnos de que todos estamos en la misma página.
Un almacén de datos es un depósito centralizado que almacena grandes cantidades de datos estructurados y organizados procedentes de diversas fuentes para una empresa. Diferentes personas (empleados) de las organizaciones utilizan los datos que contienen para obtener diferentes perspectivas.
Por ejemplo, los analistas de datos, en colaboración con el equipo de marketing, pueden realizar una prueba A/B para una nueva campaña de marketing utilizando la tabla de ventas. Los especialistas en RRHH pueden consultar la información de los empleados para hacer un seguimiento de su rendimiento.
Estos son algunos de los ejemplos de cómo las empresas de todo el mundo utilizan los almacenes de datos para impulsar el crecimiento. Pero sin una implantación y gestión adecuadas mediante herramientas como Snowflake, los almacenes de datos siguen siendo conceptos elaborados.
Puedes aprender más sobre el tema con nuestro curso de Almacenamiento de Datos.
La arquitectura única de Snowflake, diseñada para consultas analíticas más rápidas, proviene de su separación de las capas de almacenamiento y computación. Esta distinción contribuye a los beneficios que hemos mencionado antes.
En Snowflake, la capa de almacenamiento es un componente crítico, que almacena los datos de forma eficiente y escalable. He aquí algunas características clave de esta capa:
Veamos ahora la capa de cálculo.
Como su nombre indica, la capa de cálculo es el motor que ejecuta tus consultas. Trabaja conjuntamente con la capa de almacenamiento para procesar los datos y realizar diversas tareas computacionales. A continuación encontrarás más detalles sobre el funcionamiento de esta capa:
Todos estos principios de diseño de la capa de cálculo contribuyen a la capacidad de Snowflake para gestionar cargas de trabajo diferentes y exigentes en la nube.
La última capa son los servicios en la nube. Como esta capa se integra en todos los componentes de la arquitectura de Snowflake, hay muchos detalles sobre su funcionamiento. Además de las funciones relacionadas con otras capas, tiene las siguientes responsabilidades adicionales:
Ahora que tenemos una imagen de alto nivel de la arquitectura de Snowflake, vamos a escribir algo de SQL en la plataforma.
Snowflake tiene su propia versión de SQL llamada Snowflake SQL. La diferencia entre éste y otros dialectos de SQL es similar a la diferencia entre los acentos del inglés.
Muchas de las consultas analíticas que realizas en dialectos como PostgreSQL no cambian, pero hay algunas discrepancias en los comandos DDL (Lenguaje de Definición de Datos).
Ahora, ¡vamos a ver cómo ejecutar algunas consultas!
Para empezar a utilizar Snowsight, ve a la página de prueba gratuita de 120 días de Snowflake y crea una cuenta. Introduce tus datos personales y selecciona cualquier proveedor de nube de la lista. Esto proporciona una prueba gratuita de 120 días en lugar de la prueba más estándar de 30 días que puedes encontrar en otros sitios. La prueba también incluye créditos por valor de 400 $.
Al inscribirse para una prueba, se recomienda que los usuarios elijan AWS y la región Oeste de EEUU-Oregón. Entre otras razones, Oregón es una de las regiones con costes más bajos para la infraestructura de AWS y, en consecuencia, los créditos de prueba duran más.
Tras verificar tu correo electrónico, serás redirigido a la página Hojas de trabajo. Las hojas de trabajo son entornos interactivos de codificación en vivo en los que puedes escribir, ejecutar y ver los resultados de tus consultas SQL.
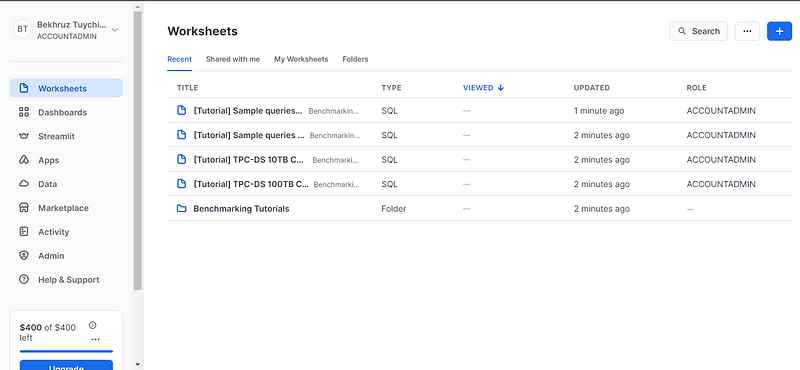
Para realizar algunas consultas, necesitamos una base de datos y una tabla (no utilizaremos los datos de muestra de Snowsight). Para empezar, te sugiero que intentes crear una nueva base de datos (podrías llamarla algo así como test_db) y una tabla con el nombre de un archivo CSV local. Puedes descargar el archivo CSV ejecutando el código de este gist de GitHub en tu terminal.
Después, se te dirigirá a una nueva hoja de cálculo donde podrás ejecutar cualquier consulta SQL que desees. La interfaz de la hoja de cálculo me parece bastante sencilla y muy funcional. Tómate unos minutos para familiarizarte con los paneles, los botones y sus respectivas ubicaciones.
¡Uf! Empezamos con algunos conceptos sencillos, pero hacia el final, nos metimos de lleno en los detalles escabrosos. Bueno, esa es mi idea de un tutorial decente.
Probablemente habrás adivinado que Snowflake es mucho más de lo que hemos visto. De hecho, ¡la documentación de Snowflake incluye guías de inicio rápido que en realidad duran 128 minutos! Pero antes de abordarlas, te recomiendo que te mojes las manos con otros recursos. ¿Qué te parecen éstas?
¡Gracias por leer!
Nuestros programas de certificación te ayudan a destacar y a demostrar que tus aptitudes están preparadas para el trabajo a posibles empleadores.

¡Comienza hoy tu viaje a la base de datos!
Curso
Curso
Curso
blog
Nisha Arya Ahmed
15 min
blog
Gus Frazer
14 min
blog
Kurtis Pykes
10 min
Tutorial
Anneleen Rummens
Tutorial
Moez Ali
Tutorial
Tim Lu
