
Kurs
Datenmodellierung in Power BI
3 Std.
94.7K
Bevor wir uns mit der Architektur von Snowflake befassen, sollten wir einen Blick auf die Data Warehouses werfen, um sicherzustellen, dass wir alle auf derselben Seite stehen.
Ein Data Warehouse ist ein zentraler Speicher, der große Mengen an strukturierten und organisierten Daten aus verschiedenen Quellen für ein Unternehmen speichert. Verschiedene Personas (Mitarbeiter/innen) in Organisationen nutzen die Daten, um unterschiedliche Erkenntnisse zu gewinnen.
Zum Beispiel können Datenanalysten in Zusammenarbeit mit dem Marketingteam einen A/B-Test für eine neue Marketingkampagne durchführen und dabei die Tabelle mit den Verkäufen verwenden. Personalspezialisten können die Mitarbeiterdaten abfragen, um die Leistung zu verfolgen.
Dies sind einige Beispiele dafür, wie Unternehmen weltweit Data Warehouses nutzen, um ihr Wachstum voranzutreiben. Aber ohne eine ordnungsgemäße Implementierung und Verwaltung mithilfe von Tools wie Snowflake bleiben Data Warehouses nur ein kompliziertes Konzept.
Mit unserem Kurs Data Warehousing kannst du mehr über dieses Thema erfahren.
Die einzigartige Architektur von Snowflake, die für schnellere analytische Abfragen entwickelt wurde, beruht auf der Trennung von Speicher- und Rechenebenen. Diese Unterscheidung trägt zu den Vorteilen bei, die wir bereits erwähnt haben.
In Snowflake ist die Speicherschicht eine wichtige Komponente, die Daten effizient und skalierbar speichert. Hier sind einige wichtige Merkmale dieser Ebene:
Schauen wir uns nun die Rechenschicht an.
Wie der Name schon sagt, ist der Compute Layer die Engine, die deine Abfragen ausführt. Sie arbeitet mit der Speicherschicht zusammen, um die Daten zu verarbeiten und verschiedene Rechenaufgaben durchzuführen. Im Folgenden erfährst du mehr darüber, wie diese Ebene funktioniert:
Diese Konstruktionsprinzipien der Rechenschicht tragen alle dazu bei, dass Snowflake unterschiedliche und anspruchsvolle Arbeitslasten in der Cloud bewältigen kann.
Die letzte Schicht sind die Cloud-Dienste. Da diese Schicht in jede Komponente der Architektur von Snowflake integriert ist, gibt es viele Details zu ihrer Funktionsweise. Zusätzlich zu den Merkmalen der anderen Schichten hat sie die folgenden zusätzlichen Aufgaben:
Jetzt, wo wir einen Überblick über die Architektur von Snowflake haben, können wir ein wenig SQL auf der Plattform schreiben.
Snowflake hat seine eigene Version von SQL, Snowflake SQL. Der Unterschied zwischen ihm und anderen SQL-Dialekten ist vergleichbar mit dem Unterschied zwischen englischen Akzenten.
Viele der analytischen Abfragen, die du in Dialekten wie PostgreSQL durchführst, ändern sich nicht, aber es gibt einige Diskrepanzen bei den DDL-Befehlen (Data Definition Language).
Jetzt zeige ich dir, wie du ein paar Abfragen machen kannst!
Um mit Snowsight zu beginnen, rufe die 120-tägige kostenlose Testseite von Snowflake auf und erstelle ein Konto. Gib deine persönlichen Daten ein und wähle einen der aufgeführten Cloud-Anbieter aus. Das bedeutet, dass du 120 Tage lang kostenlos testen kannst und nicht wie sonst üblich nur 30 Tage. Die Studie beinhaltet außerdem Gutschriften im Wert von 400 $.
Wenn du dich für eine Testversion anmeldest, solltest du AWS und die Region US-Oregon West wählen. Unter anderem ist Oregon eine der Regionen mit den niedrigsten Kosten für AWS-Infrastruktur, weshalb die Testgutschriften länger gelten.
Nachdem du deine E-Mail verifiziert hast, wirst du auf die Seite mit den Arbeitsblättern weitergeleitet. Arbeitsblätter sind interaktive Live-Coding-Umgebungen, in denen du deine SQL-Abfragen schreiben, ausführen und die Ergebnisse ansehen kannst.
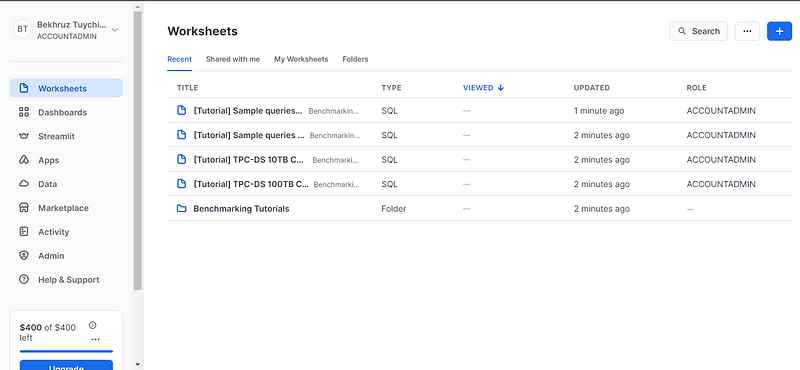
Um einige Abfragen durchzuführen, brauchen wir eine Datenbank und eine Tabelle (wir werden die Beispieldaten in Snowsight nicht verwenden). Für den Anfang empfehle ich dir, eine neue Datenbank zu erstellen (du könntest sie z.B. test_db nennen) und eine Tabelle mit einer lokalen CSV-Datei zu erstellen. Du kannst die CSV-Datei herunterladen, indem du den Code in diesem GitHub gist in deinem Terminal ausführst.
Danach wirst du zu einem neuen Arbeitsblatt weitergeleitet, auf dem du jede beliebige SQL-Abfrage ausführen kannst. Ich finde, die Arbeitsblattschnittstelle ist ziemlich einfach und sehr funktional. Nimm dir ein paar Minuten Zeit, um dich mit den Bedienfeldern, den Tasten und ihren jeweiligen Positionen vertraut zu machen.
Uff! Wir haben mit einfachen Konzepten angefangen, aber zum Ende hin haben wir uns in die knorrigen Details gestürzt. Das ist meine Vorstellung von einem anständigen Lernprogramm.
Du hast wahrscheinlich schon geahnt, dass Snowflake noch viel mehr zu bieten hat als das, was wir hier beschrieben haben. Die Snowflake-Dokumentation enthält sogar Schnellstartanleitungen, die 128 Minuten lang sind! Aber bevor du diese in Angriff nimmst, empfehle ich dir, dich mit einigen anderen Ressourcen vertraut zu machen. Wie wäre es mit diesen:
Danke fürs Lesen!
Unsere Zertifizierungsprogramme helfen dir, dich von anderen abzuheben und potenziellen Arbeitgebern zu beweisen, dass deine Fähigkeiten für den Job geeignet sind.

Beginne deine Reise in die Datenbank noch heute!
Kurs
Kurs
Kurs
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
4 Min.
Tutorial
Sejal Jaiswal
Tutorial
Matt Crabtree
Tutorial
Javier Canales Luna
Tutorial
Laiba Siddiqui


