Curso
Comprender la arquitectura de datos moderna
2 h
22.4K
Teniendo en cuenta las características que acabamos de mencionar, he aquí un resumen conciso de las ventajas de Athena:
|
Benefíciate |
Función |
Descripción |
|
Eficiencia de costes |
Modelo de pago por consulta |
Sólo pagas por los datos con los que interactúan tus consultas; sin costes iniciales ni licencias complejas; es posible optimizar los costes con partición, compresión de datos y formatos columnares. |
|
Facilidad de uso |
SQL estándar y sin servidor |
No es necesario configurar ni gestionar la infraestructura; los usuarios pueden empezar a consultar datos en cuestión de minutos utilizando la conocida sintaxis SQL, lo que lo hace accesible y fácil de usar. |
|
Flexibilidad |
Soporte multiformato |
Admite una amplia gama de formatos de datos (por ejemplo, CSV, JSON, Parquet), lo que permite a los usuarios consultar datos en su formato nativo directamente desde S3 sin necesidad de procesos ETL. |
|
Ideas rápidas |
Análisis rápidos y consultas directas al S3 |
Permite el análisis inmediato de datos con una arquitectura sin servidor, lo que permite una rápida extracción de información directamente de los datos almacenados en S3 y reduce el tiempo de obtención de valor para las decisiones basadas en datos. |
Hemos definido Athena y mencionado sus características y ventajas, pero ¿para qué se utiliza? En esta sección, repasaremos algunos de los casos de uso más populares.
Amazon Athena se utiliza con frecuencia para el análisis de logs, en particular para consultar y analizar logs almacenados en Amazon S3. Las organizaciones suelen generar volúmenes masivos de datos de registro procedentes de diversas fuentes, como registros de aplicaciones, registros de servidores y registros de acceso.
Al almacenar estos registros en S3 y consultarlos mediante Athena, los usuarios pueden identificar rápidamente tendencias, diagnosticar problemas y supervisar el rendimiento del sistema sin necesidad de una configuración compleja.
La arquitectura sin servidor de Athena y su compatibilidad con SQL estándar la convierten en una herramienta excelente para la exploración de datos ad hoc. Tanto si eres un científico de datos, un analista o un ingeniero, Athena te permite consultar rápidamente los datos almacenados en S3 sin cargarlos en una base de datos tradicional.
A medida que las organizaciones adoptan cada vez más los lagos de datos para almacenar grandes cantidades de datos brutos y procesados, Athena sirve como un potente motor de consulta para estos lagos de datos. Permite a los usuarios realizar análisis directamente sobre los datos almacenados en S3, lo que lo convierte en parte integrante de una arquitectura moderna de lago de datos.
Athena también se utiliza habitualmente como parte de una pila de inteligencia empresarial (BI), donde se integra con herramientas de BI como Amazon QuickSight para permitir la visualización de datos y la elaboración de informes. Al consultar los datos en S3 con Athena y visualizarlos en QuickSight, las organizaciones pueden crear cuadros de mando e informes interactivos para la toma de decisiones.
Si estás familiarizado con Amazon Redshift, puede que te preguntes en qué se diferencia de Athena.
Aunque tanto Athena como Redshift tratan con conjuntos de datos, sus objetivos son diferentes. El principal caso de uso de Redshift es el almacenamiento de datos y la analítica habitual con big data. AWS Athena se centra en permitir a los usuarios realizar análisis ad hoc de los datos almacenados en S3.
Aquí tienes una comparación detallada de Athena frente a Redshift:
|
Criterios |
Amazon Athena |
Amazon Redshift |
|
Arquitectura |
Servicio de consultas sin servidor; ejecuta consultas SQL directamente sobre datos almacenados en Amazon S3 con escalado automático; sin gestión de infraestructura. |
Almacén de datos totalmente gestionado; requiere un clúster de almacén de datos con infraestructura dedicada; puede escalar en función de las necesidades. La opción Redshift sin servidor está disponible. |
|
Casos prácticos |
Es ideal para consultas y análisis ad hoc sobre datos S3 y para escenarios que prioricen la flexibilidad y la rentabilidad sin transformación de datos. |
Adecuado para análisis e informes complejos a gran escala; ideal para datos estructurados que requieren consultas y transformaciones frecuentes. |
|
Estructura de costes |
Modelo de pago por consulta: cobra en función de los datos escaneados por las consultas, lo que lo hace rentable para cargas de trabajo intermitentes o variables. |
Los precios se basan en el tamaño y el uso del clúster; hay precios de instancia reservada para consultas predecibles y de gran volumen. |
|
Rendimiento |
Depende del tamaño y formato de los datos; optimizado mediante partición y compresión; mejor para consultas más pequeñas y menos complejas. |
Alto rendimiento para consultas complejas; utiliza almacenamiento en columnas, procesamiento paralelo y optimización avanzada para cargas de trabajo intensivas. |
|
Integración de datos |
Consulta directamente los datos en S3 sin necesidad de transformación o carga; admite varios formatos y conectores extensibles, incluido Redshift. |
Requiere que los datos se carguen en el almacén, se integra con los servicios de AWS y admite varios métodos de ingestión de datos, pero sólo lee de sus datos almacenados. |
Es hora de ponerse manos a la obra, configurar Athena y ejecutar algunas consultas.
Utilizar AWS Athena requiere una cuenta de AWS. Si no tienes una, debes crearla. Para ello, sigue las instrucciones de la guía de configuración de AWS.
Aunque no existe una capa gratuita para AWS Athena, deberías poder ejecutar 2-3 pequeñas consultas de prueba (~10 MB de tamaño) para comprender cómo funciona el sistema. Sigue las instrucciones del portal y verifica tu identidad. A continuación, inicia sesión en tu cuenta de AWS.
Como todos los productos de Amazon AWS, Athena utiliza políticas IAM (gestión de identidad y acceso) para los permisos. Serás el usuario root de tu cuenta y deberás tener los permisos necesarios para ejecutar consultas Athena en tus propios buckets S3.
Puedes administrar los permisos de IAM buscando el servicio IAM en la barra de búsqueda superior de tu panel de inicio de AWS y utilizando esta completa guía de IAM. La documentación de AWS también proporciona más información sobre la configuración específica de Athena.
Antes de ejecutar las consultas, tenemos que configurar un bucket de S3 para almacenar nuestros datos.
Amazon S3 significa Simple Storage Service (Servicio de Almacenamiento Simple) y es un componente crítico de cómo AWS gestiona el almacenamiento y los datos dentro del entorno de la nube. Siguiendo esta guía bien escrita sobre la creación de buckets de Amazon S3, podemos crear el entorno de almacenamiento para nuestros datos y consultas.
En resumen, buscarás el servicio S3 en la barra de búsqueda para llegar a la página principal de S3:
Verás un botón "Crear cubo" en la barra lateral derecha de la página de inicio. Siguiendo las instrucciones de esta página, crearás un bucket que permitirá a tu servicio Athena almacenar los resultados de las consultas.
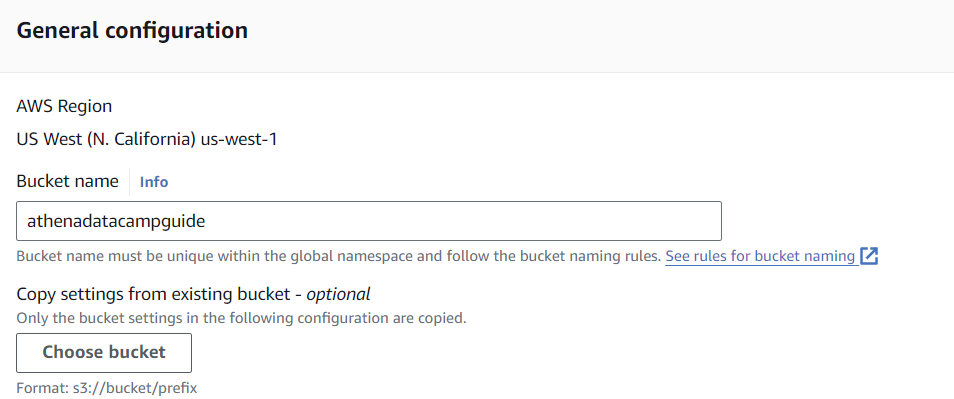
Voy a crear un cubo llamado "athenadatacampguide" utilizando todas las demás opciones predeterminadas. Como los buckets deben ser globalmente únicos en todo AWS, debes elegir otro nombre para este tutorial.
Ahora, tenemos que conectar este cubo a Athena. Iré a la consola Athena y haré clic en "Editar configuración" en la pequeña barra de notificaciones que hay cerca de la parte superior.

A continuación, seleccionaré el cubo que acabo de crear. Para encontrar tu cubo, utiliza el botón "Examinar S3" de la derecha o escribe el nombre precedido de "s3://".
Una vez seleccionado el cubo, haz clic en "Guardar" y vuelve al Editor haciendo clic sobre él en la barra de herramientas superior.

AWS Athena organiza los datos jerárquicamente. Utiliza "catálogos de datos", un conjunto de bases de datos también conocido como esquema.
Las tablas reales que consultamos están dentro de las bases de datos. Para crear un nuevo catálogo de datos, podrías utilizar Amazon Lambda y conectarte a una fuente de datos externa. A continuación, el catálogo de datos puede guardarse como catálogo de datos Lambda, Hive o Glue.
Por defecto, en AWS se utiliza el servicio Glue como repositorio central del catálogo de datos. Nos centraremos en construir una base de datos que contenga nuestras tablas para realizar consultas.
En el Editor, ve al panel Editor de consultas. Aquí es donde escribiremos nuestras consultas para crear bases de datos, consultar tablas y ejecutar análisis.
Para crear nuestra primera base de datos, ejecutaremos la siguiente consulta:
CREATE DATABASE mydatabaseEjecutar esta consulta te permitirá seleccionar una base de datos del desplegable situado debajo de "Base de datos" en la barra lateral izquierda.
Ahora que tenemos una base de datos, nos centraremos en crear una tabla para tener algo que consultar.
La introducción de datos en tu base de datos variará ligeramente en función de tu configuración de AWS. Puedes utilizar datos almacenados en un almacén de datos como Redshift o datos de streaming utilizando AWS Kinesis y Lambda para generar datos tabulares.
Hoy utilizaremos datos de muestra de Registros de AWS Cloudfront. Debido a la complejidad de los datos, parte del proceso de creación utiliza grupos RegEx para analizar los datos URl en columnas.
Utilizando el siguiente SQL, podemos crear una tabla. Nota: a continuación, sustituye "mi región" por tu región AWS.
CREATE EXTERNAL TABLE IF NOT EXISTS cloudfront_logs (
Date DATE,
Time STRING,
Location STRING,
Bytes INT,
RequestIP STRING,
Method STRING,
Host STRING,
Uri STRING,
Status INT,
Referrer STRING,
os STRING,
Browser STRING,
BrowserVersion STRING
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe'
WITH SERDEPROPERTIES (
"input.regex" = "^(?!#)([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+[^\(]+[\(]([^\;]+).*\%20([^\/]+)[\/](.*)Si la tabla aparece en la barra lateral izquierda, ¡estás listo para empezar a consultar!
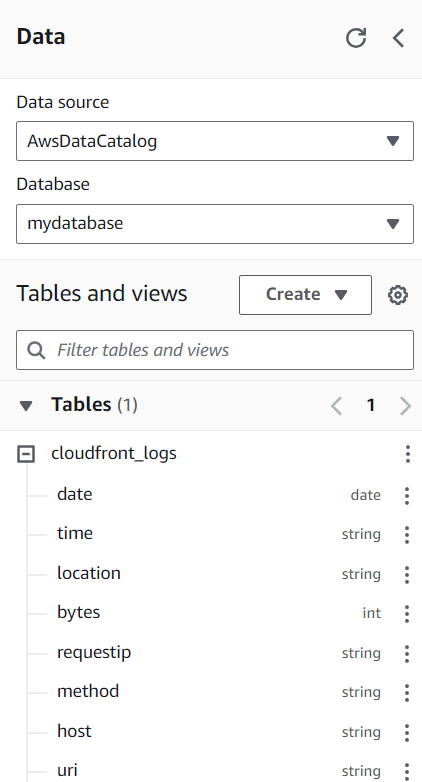
Escribir consultas en Athena es similar a escribir consultas en SQL tradicional. Sólo tienes que escribir y enviar la consulta a Athena, y te devolverá los resultados deseados.
Una buena práctica es escribir tus declaraciones FROM con la siguiente sintaxis: "DataSource". "base de datos". "tabla". De este modo, nunca habrá confusión sobre la procedencia de los datos.
Probemos con una simple declaración SELECT para empezar.
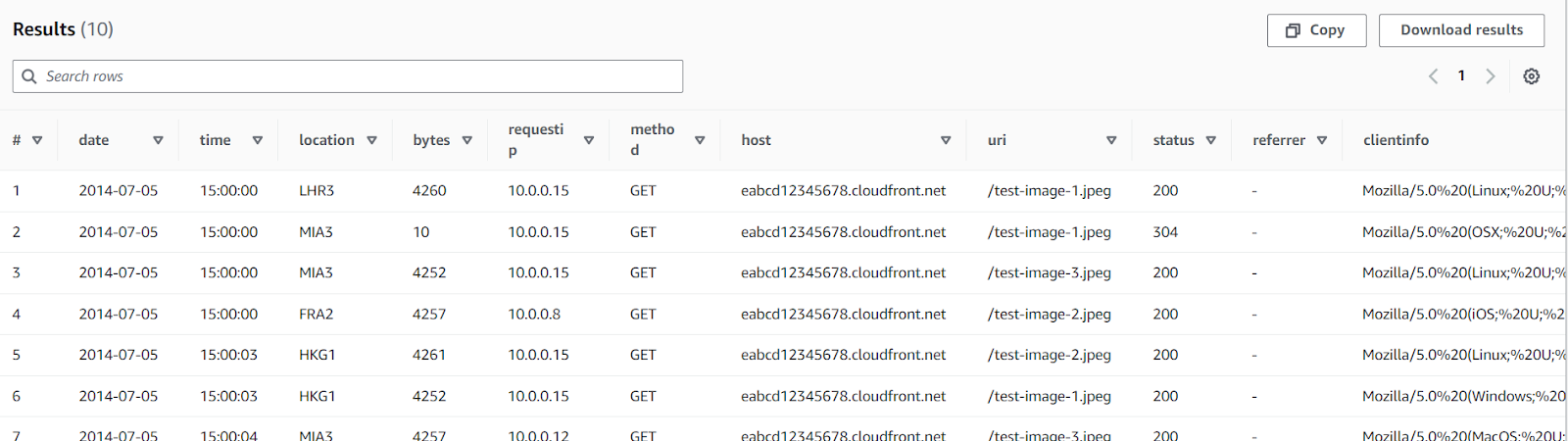
SELECT *
FROM "AwsDataCatalog"."mydatabase"."cloudfront_logs"
LIMIT 10Esto debería devolver una tabla con 10 resultados. Athena te permite copiar o descargar los resultados. Al mismo tiempo, estos resultados se guardan en el bucket S3 que conectaste a tu servicio Athena.
Incluso podemos escribir consultas sencillas en GROUP BY. Éste, en concreto, nos permite saber cuántos requestip (no necesariamente únicos) estaban implicados con métodos HTTP específicos.
SELECT
method,
COUNT(requestip)
FROM "AwsDataCatalog"."mydatabase"."cloudfront_logs"
GROUP BY 1Una buena forma de utilizar Athena es para consultas más complejas, como las funciones de ventana. Gracias a la optimización de Athena, podemos realizar cálculos complicados más rápidamente.
Por ejemplo, podemos utilizar Athena para generar el ROW NUMBER() de cada registro particionado por su región y fecha organizado por tiempo de forma descendente. A continuación, podemos elegir el registro más reciente para cada región y fecha utilizando un filtro WHERE para elegir la primera fila.
SELECT *
FROM (
SELECT
location,
date,
time,
ROW_NUMBER() OVER(PARTITION BY location, date ORDER BY time DESC) row_num
FROM "AwsDataCatalog"."mydatabase"."cloudfront_logs"
)
WHERE row_num = 1
Esto es sólo el principio con Atenea. Puedes seguir escribiendo cualquier consulta que creas que te permitirá aprovechar las capacidades de Athena.
AWS Athena requiere una serie de buenas prácticas, como cualquier otra herramienta de procesamiento de datos. Estas prácticas no sólo te harán la vida más fácil, sino que también mejorarán su rendimiento.
Además, como AWS es un servicio basado en la nube y a los usuarios se les cobra en función de diversos factores de almacenamiento y computación, ¡estas prácticas pueden suponer un importante ahorro de costes!
Varios formatos de datos son más prácticos de utilizar en AWS Athena. Dado que Athena extrae los datos de un bucket de S3, elegir un formato de datos que sea fácil de leer y esté comprimido mejorará el rendimiento y el coste.
Los datos en bruto almacenados en CSV pueden ser los más sencillos, pero ineficaces. Almacenar nuestros datos en un formato comprimido como el Parquet o el formato ORC ahorrará costes de lectura de datos.
Una ventaja adicional de Parquet y ORC es su compresión basada en columnas. El optimizador de Athena le permite buscar sólo determinadas columnas de datos en lugar de recorrer toda la tabla para realizar los cálculos.
Particionar datos significa dividir regularmente un conjunto de datos en función de una clave concreta, como una fecha. Por ejemplo, podemos tener particiones diarias en las que los datos están configurados para dividirse y almacenarse automáticamente por días.
Cuando nuestros datos están particionados, el motor SQL puede realizar una mejor optimización fijándose en las particiones relevantes. Esto conlleva una mejora directa en la reducción de la cantidad de datos escaneados, reduciendo el coste total.
Aunque se espera cierta complejidad al realizar análisis de datos, optimizar las consultas puede ayudar a reducir el tiempo y el coste computacional. Algunos de los costes no proceden directamente de Athena, sino de otros servicios que utiliza AWS Athena.
El principal componente del coste de Athena es escanear y procesar los datos, pero puedes incurrir en costes de S3 si guardas resultados enormes. También podemos mejorar el rendimiento de las consultas y reducir costes asegurándonos de que se optimizan siguiendo las mejores prácticas habituales de SQL.
Por ejemplo, todo lo siguiente ayudará a la optimización:
SELECT * siempre que sea posibleLIMIT cuando pruebes las consultas¡Estas buenas prácticas mejorarán el rendimiento de las consultas y reducirán los costes!
AWS Athena puede conectarse a Amazon CloudWatch para almacenar métricas de consulta. Podemos descubrir consultas ineficaces o problemas observando los registros de rendimiento de las consultas.
Como ya se ha mencionado, AWS Athena se integra con varios otros servicios de AWS, mejorando sus capacidades de catalogación, visualización, procesamiento y almacenamiento de datos.
A continuación se muestra cómo funciona Athena con servicios como AWS Glue, Amazon QuickSight, AWS Lambda y Amazon Redshift.
Cuando se integra con AWS Athena, AWS Glue es un repositorio central de metadatos que cataloga automáticamente los datos en Amazon S3. Esta integración elimina la necesidad de definiciones manuales de esquemas, agilizando la consulta de datos en Athena.
Glue también proporciona capacidades ETL, transformando y preparando los datos para una consulta óptima en Athena mediante la automatización de tareas como la compresión de datos, la partición y la conversión de formatos, garantizando un procesamiento de datos eficiente y eficaz.
Amazon QuickSight se integra con AWS Athena para convertir los resultados de las consultas en paneles e informes interactivos. Esta conexión te permite visualizar los datos directamente desde las consultas de Athena, posibilitando la creación rápida y sencilla de perspectivas visuales.
QuickSight admite funciones como la actualización automática de datos y el análisis avanzado, lo que la convierte en una potente herramienta para explorar y presentar datos.
AWS Lambda automatiza los flujos de trabajo de procesamiento de datos con Athena en un entorno sin servidor. Las funciones lambda pueden lanzar consultas Athena en respuesta a eventos, como nuevos datos en S3, permitiendo el procesamiento en tiempo real.
Lambda también puede automatizar acciones posteriores basadas en los resultados de las consultas, creando flujos de trabajo escalables y basados en eventos sin intervención manual.
Mientras que Athena es ideal para la consulta ad hoc de datos de S3, Amazon Redshift ofrece una solución analítica robusta, estructurada y compleja. Puedes utilizar Athena para el análisis rápido de datos sin procesar y Redshift para consultas más intensivas y de alto rendimiento.
La integración permite el movimiento de datos entre S3 y Redshift, aprovechando los puntos fuertes de ambos servicios para una solución analítica completa.
AWS Athena es un potente motor de consultas integrado directamente en el ecosistema de AWS. Al permitir a los usuarios acceder rápidamente a los datos almacenados en buckets S3 y guardar los resultados de las consultas en buckets S3, AWS Athena permite a los usuarios sumergirse en sus datos con mayor flexibilidad. Aprovecha las ventajas de otros servicios de AWS, como ser sin servidor, escalable y sencillo.
Si quieres saber más sobre AWS, DataCamp ofrece varios recursos:
¡Aprende más sobre AWS y la ingeniería de datos con estos cursos!
Curso
Curso
Curso
blog
Joleen Bothma
12 min
blog
Kurtis Pykes
12 min
Tutorial
Sejal Jaiswal
Tutorial
Arunn Thevapalan
Tutorial
Oluseye Jeremiah
