
Curso
Comprender la ingeniería de datos
2 h
355.8K
Empecemos con las preguntas básicas de la entrevista sobre los conceptos clave de Snowflake.
Snowflake es una plataforma de almacenamiento de datos basada en la nube que separa la computación del almacenamiento, permitiendo a los usuarios escalar sus recursos de procesamiento y almacenamiento de datos de forma independiente. Este proceso es más rentable y produce un alto rendimiento.
Una de las principales características es el autoescalado, que permite ajustar los recursos en función de la demanda de cargas de trabajo y admite entornos multicloud. Otra característica esencial es el enfoque de plataforma para compartir datos, que garantiza que el acceso a los datos en toda la organización sea seguro y fácil, sin ningún movimiento de datos.
La arquitectura de Snowflake es su punto fuerte. Ha sido diseñado para la nube, con características como la arquitectura multicluster, de datos compartidos, y asombrosas capacidades de almacenamiento. La arquitectura Snowflake se divide en tres capas:
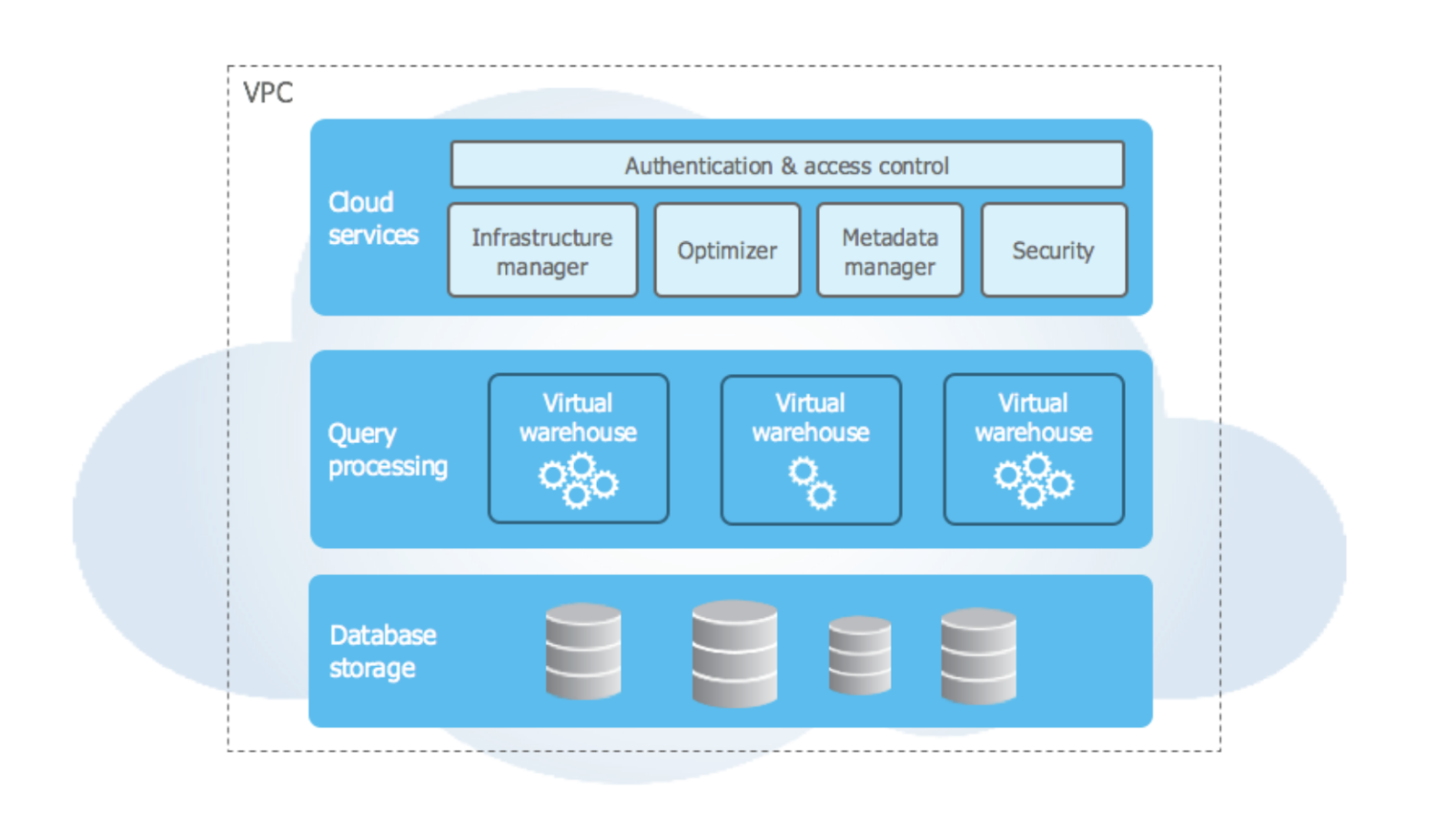
Arquitectura de alto nivel de Snowflake. Fuente de la imagen: Documentación sobre Snowflake.
Las microparticiones son un aspecto fundamental del enfoque de Snowflake para el almacenamiento de datos. Son unidades de almacenamiento comprimidas, gestionadas y en columnas que Snowflake utiliza para almacenar datos de entre 50 MB y 150 MB. El formato columnar permite una compresión de datos y unos esquemas de codificación eficaces.
La capacidad de las microparticiones para comprimir datos permite gestionar grandes volúmenes de datos de forma eficiente, ya que reduce el espacio físico de almacenamiento necesario, reduciendo también los costes de almacenamiento. El rendimiento de la consulta también mejora gracias a la poda de datos, que consiste en acceder a las microparticiones relevantes. Este enfoque de acceso selectivo es muy beneficioso para la recuperación y el análisis de datos.
Las microparticiones son gestionadas automáticamente por Snowflake, lo que elimina la necesidad de introducir manualmente la partición o indexación de los datos, garantizando un almacenamiento óptimo de los datos y reduciendo también el coste del trabajo administrativo.
Los almacenes virtuales se encargan de realizar todas las tareas de procesamiento de datos. Por lo tanto, tienen un profundo impacto en la escalabilidad, el rendimiento y la gestión de costes de las tareas de procesamiento de datos.
Sus funciones de escalabilidad dinámica permiten a los usuarios ampliar o reducir sus recursos informáticos en función de las necesidades de su carga de trabajo. Cuando aumente la demanda de tareas de procesamiento de datos, puedes aprovisionar recursos informáticos adicionales sin que ello afecte a tus operaciones en curso.
Cada almacén virtual no afecta a otro, lo que permite un alto rendimiento y coherencia cuando se trata de tareas específicas de procesamiento de datos, como los análisis sensibles al tiempo. Cuando realizas tareas de procesamiento de datos, pagas por los recursos informáticos que utilizas, lo que proporciona funciones de gestión de costes en comparación con las soluciones tradicionales de almacenamiento de datos.
La tabla siguiente compara los almacenes virtuales con los recursos informáticos tradicionales:
| Función | Almacenes virtuales (Snowflake) | Recursos informáticos tradicionales |
|---|---|---|
| Escalabilidad | Autoescalado, multiclúster; puede ajustar el tamaño hacia arriba o hacia abajo en función de la demanda de carga de trabajo sin afectar a las operaciones. | Capacidad normalmente fija, que requiere actualizaciones manuales para escalar. |
| Aislamiento | Aísla los clusters de cálculo, para que las cargas de trabajo concurrentes se ejecuten de forma independiente. | El reparto de recursos suele dar lugar a una competencia entre tareas. |
| Gestión de costes | Paga sólo por el tiempo activo y aumenta o disminuye según sea necesario, minimizando los costes de inactividad. | Costes fijos independientemente de los cambios en la carga de trabajo, costes ociosos potencialmente más elevados. |
| Optimización del rendimiento | El escalado independiente permite un ajuste separado para tareas específicas, manteniendo un alto rendimiento para las consultas sensibles al tiempo. | Opciones de ajuste limitadas, ya que el escalado afecta a todas las cargas de trabajo por igual. |
ANSI SQL son las siglas de American National Standards Institute Structured Query Language (Instituto Nacional Estadounidense de Normalización) y es un lenguaje estándar para los sistemas de gestión de bases de datos relacionales.
Esto significa que los usuarios de Snowflake pueden utilizar la sintaxis y las operaciones SQL conocidas para consultar datos, como las JOIN, lo que la convierte en una función estupenda para que los usuarios con experiencia en SQL hagan la transición a Snowflake. Otra característica de la compatibilidad con ANSI SQL es la perfecta integración de varios tipos de datos, lo que permite a los usuarios consultar sus datos sin necesidad de transformarlos o cargarlos antes en un esquema predefinido.
Si quieres certificarte en el uso de la plataforma Snowflake, echa un vistazo a ¿Cuál es la mejor certificación Snowflake para 2024?
La función Time Travel de Snowflake permite a los usuarios acceder y consultar datos históricos de un periodo determinado, normalmente de hasta 90 días, según el tipo de cuenta. Esta función es útil para recuperar datos, realizar auditorías y comparar datos. Por ejemplo, los usuarios pueden restaurar tablas borradas accidentalmente o revisar estados de datos anteriores.
El Viaje en el Tiempo minimiza la necesidad de copias de seguridad externas y simplifica el control de versiones de los datos, proporcionando capacidades integradas de recuperación de datos y análisis retrospectivo.
La función de compartir datos de Snowflake permite a las organizaciones compartir datos en directo de forma segura y en tiempo real con usuarios o socios externos sin crear copias de datos adicionales. Esto se consigue gracias a la funcionalidad de Compartición Segura de Datos de Snowflake, que utiliza la arquitectura de datos compartidos en varios clústeres de Snowflake para proporcionar acceso directo a los datos.
Entre las ventajas de compartir datos se incluyen:
La clonación de copia cero es una función de Snowflake que permite a los usuarios crear una copia de una base de datos, esquema o tabla sin duplicar el almacenamiento subyacente. Cuando se crea un clon de copia cero, éste apunta a los datos originales y sólo almacena los cambios realizados en los datos clonados, lo que supone un importante ahorro de almacenamiento. Esta función es valiosa para crear entornos de desarrollo y pruebas o generar instantáneas históricas sin aumentar los costes de almacenamiento. Mejora la eficacia de la gestión de datos al permitir una duplicación de datos rápida y rentable para diversos casos de uso.
Nuestros programas de certificación te ayudan a destacar y a demostrar que tus aptitudes están preparadas para el trabajo a posibles empleadores.

¿Te sientes seguro con las preguntas básicas de la entrevista? Pasemos a algunas preguntas más avanzadas.
Snowflake pretende garantizar el máximo nivel de protección y seguridad de los datos de sus usuarios con la implantación de su proceso de cifrado siempre activo. Se trata de la encriptación automática de datos sin necesidad de establecer o configurar usuarios, lo que garantiza que todos los tipos de datos, desde los brutos hasta los metadatos, se encriptan utilizando un algoritmo de encriptación potente. Su encriptación se gestiona mediante un modelo jerárquico de claves en el que una clave maestra encripta las demás claves y Snowflake rota estas claves para aumentar la seguridad.
Al transferir datos, Snowflake utiliza el proceso TLS (Transport Layer Security) para cifrar los datos que transitan entre Snowflake y los clientes. Esta encriptación de extremo a extremo garantiza que los datos estén siempre encriptados, independientemente del punto del ciclo de vida en que se encuentren, reduciendo el riesgo de fugas y violaciones de datos.
Los procesos Extraer, Transformar, Cargar (ETL) y Extraer, Cargar, Transformar (ELT) son muy utilizados en la plataforma Snowflake debido a su arquitectura y capacidades. La plataforma satisface una amplia gama de necesidades de integración y transformación de datos de los usuarios, permitiendo a las organizaciones optimizar su flujo de trabajo de procesamiento de datos de forma más eficaz.
En la ETL, los datos se extraen de diversas fuentes y luego se transforman en el formato deseado por el usuario antes de cargarlos en el almacén de datos. Snowflake es un potente motor SQL que permite realizar transformaciones complejas mediante consultas SQL después de cargar los datos.
En ELT, los datos se cargan en el almacén de datos primero en su forma bruta y luego se transforman en el almacén. La característica de Snowflake de separar sus capacidades de cálculo y almacenamiento permite cargar rápidamente los datos brutos en el almacén de datos. Las transformaciones de los datos se realizan mediante almacenes virtuales. Snowflake también admite formatos de datos semiestructurados, como JSON y XML, lo que facilita la transición de los datos brutos al almacén de datos sin tener que transformarlos.
Snowflake es compatible con una serie de herramientas ETL, lo que permite a las organizaciones utilizar las herramientas que prefieran cuando se trata de tareas de integración y transformación de datos. Las siguientes herramientas pueden utilizarse en la plataforma de datos en la nube de Snowflake para procesar y trasladar datos a Snowflake para su posterior análisis:
Snowpipe es un servicio de ingestión continua de datos proporcionado por Snowflake que puede cargar archivos en cuestión de minutos. Con Snowpipe puedes cargar datos en pequeños grupos (microlotes), lo que permite a los usuarios de toda la organización acceder a los datos en cuestión de minutos, facilitando su análisis.
Los usuarios especifican la ruta de almacenamiento en la nube donde se colocarán los archivos de datos y también la tabla de destino en Snowflake, donde se cargarán los datos. Se trata de un proceso automatizado de carga de datos en el que Snowpipe detecta automáticamente cuándo se han añadido nuevos archivos a la ruta de almacenamiento. Una vez detectados estos nuevos archivos, Snowpipe ingiere los datos en Snowflake y los carga en la tabla especificada.
Este proceso casi en tiempo real garantiza que los datos estén disponibles lo antes posible. Snowpipe funciona con una arquitectura sin servidor, lo que significa que gestiona automáticamente los recursos informáticos específicamente necesarios para el proceso de ingestión de datos.
Arquitectura de alto nivel de Snowpipe Streaming. Fuente de la imagen: Documentación sobre Snowflake.
Snowflake se ha diseñado como una solución de almacenamiento de datos optimizada para cargas de trabajo de Procesamiento Analítico en Línea (OLAP). OLAP es una tecnología de software que se utiliza para analizar datos empresariales desde distintos puntos de vista. Haciendo de Snowflake un estándar de oro, ya que el diseño de la arquitectura, junto con sus características, ha sido concebido para soportar tareas de datos a gran escala, consultas complejas y mucho más. Entre las características del enfoque OLAP de Snowflake se incluyen la separación del cálculo y el almacenamiento, el procesamiento paralelo masivo (MPP) y el soporte de diferentes estructuras de datos para permitir un procesamiento analítico eficaz.
También tienes cargas de trabajo de Procesamiento de Transacciones en Línea (OLTP), para las que Snowflake no está diseñado tradicionalmente. Las cargas de trabajo OLTP se dan cuando una base de datos recibe tanto peticiones de datos como múltiples modificaciones de estos datos por parte de varios usuarios a lo largo del tiempo, y estas modificaciones se denominan transacciones. Se caracterizan por un gran volumen de transacciones cortas, como inserciones y actualizaciones. Estas funciones se centran más en las bases de datos operativas que en las soluciones de almacenamiento de datos como Snowflake.
En Snowflake, la agrupación organiza los datos en microparticiones para optimizar el rendimiento de las consultas. Por defecto, Snowflake gestiona la agrupación automáticamente, pero para tablas grandes con un orden natural (por ejemplo, datos de series temporales), la agrupación manual puede ser beneficiosa.
La agrupación manual consiste en crear una clave de agrupación en columnas utilizadas frecuentemente en las consultas. Esto permite una poda de datos más eficaz, ya que Snowflake puede omitir las particiones irrelevantes durante las consultas. Sin embargo, la agrupación manual sólo debe utilizarse cuando los beneficios en el rendimiento de la consulta superen el coste de volver a agrupar grandes conjuntos de datos, ya que puede repercutir en los costes de almacenamiento y computación.
A prueba de fallos es una función de recuperación de datos de Snowflake diseñada para restaurar datos que han sido borrados o modificados más allá del periodo de retención de Time Travel. Mientras que el Viaje en el Tiempo permite a los usuarios acceder a los datos históricos en un plazo determinado (hasta 90 días), el A Prueba de Fallos es un periodo de siete días posterior al Viaje en el Tiempo durante el cual Snowflake conserva los datos únicamente para la recuperación en caso de desastre.
A diferencia del Viaje en el Tiempo, los usuarios no pueden acceder directamente a los datos a prueba de fallos, ya que es necesaria la intervención del Soporte de Snowflake.
A prueba de fallos proporciona una capa adicional de protección de datos, pero incurre en costes más elevados y debe utilizarse como último recurso después del Viaje en el Tiempo.
Las vistas materializadas en Snowflake almacenan físicamente los resultados de una consulta, permitiendo una recuperación más rápida para consultas complejas o utilizadas con frecuencia. A diferencia de las vistas estándar, que se vuelven a calcular cada vez que se consultan, las vistas materializadas mantienen el conjunto de resultados hasta que se actualizan los datos. Esto puede mejorar significativamente el rendimiento de las consultas, especialmente para cargas de trabajo analíticas que implican grandes tablas.
Entre los casos de uso de las vistas materializadas se incluyen los cuadros de mando de informes y los resultados de consultas agregadas en los que los datos cambian con poca frecuencia. Sin embargo, las vistas materializadas requieren un mantenimiento periódico y pueden aumentar los costes de almacenamiento, por lo que son más adecuadas para conjuntos de datos estáticos o que cambian lentamente.
Aquí tienes una tabla que cubre los casos de uso de las vistas materializadas frente a las vistas estándar en Snowflake:
| Aspecto | Vistas estándar | Vistas materializadas |
|---|---|---|
| Almacenamiento de datos | No hay almacenamiento físico; las vistas se calculan en el momento de la consulta | Almacena físicamente los resultados de la consulta, mejorando la velocidad de consulta |
| Rendimiento | Adecuado para consultas pequeñas y poco frecuentes | Ideal para conjuntos de datos grandes o complejos con consultas frecuentes |
| Coste de mantenimiento | Mínimo, ya que no necesitan almacenamiento | Mayor debido a los requisitos de almacenamiento y actualización periódica |
| Casos prácticos | Consultas ad hoc y exploración de datos | Cuadros de mando de informes, agregados precalculados |
Basándote en la arquitectura única de Snowflake, debes conocer sus entresijos y poner a prueba tus conocimientos.
Las arquitecturas de disco compartido y de nada compartido son dos enfoques diferentes del diseño de bases de datos y almacenes de datos. La principal diferencia entre ambos es cómo gestionan el almacenamiento y el proceso de datos en varios nodos de un sistema.
En una arquitectura de disco compartido, los nodos del sistema tienen acceso al almacenamiento en disco, lo que significa que cualquier nodo de ese sistema puede leer o escribir en cualquier disco del mismo. Esto permite una alta disponibilidad, ya que el fallo de un solo nodo no causa pérdida de datos ni indisponibilidad. También permite simplificar el proceso de gestión de datos, ya que no es necesario particionarlos ni replicarlos entre nodos.
Por otro lado, la arquitectura "nada compartido" es aquella en la que cada nodo del sistema tiene su propio almacenamiento privado, que no se comparte con otros nodos. Los datos se reparten entre los nodos, lo que significa que cada nodo es responsable de un subconjunto de datos. Esto proporciona escalabilidad, ya que ofrece la posibilidad de añadir más nodos, cada uno con su propio almacenamiento, lo que conlleva un mejor rendimiento.
Cuando cargas datos en una etapa en Snowflake, se conoce como "Puesta en Escena". La puesta en escena externa es cuando los datos se guardan en otra región de la nube, y la puesta en escena interna es cuando los datos se guardan dentro de Snowflake. La puesta en escena interna está integrada en el entorno Snowflake y almacena archivos y datos para cargarlos en las tablas Snowflake. La plataforma Snowflake utiliza proveedores externos de ubicaciones de almacenamiento, como AWS, Google Cloud Platform y Azure, para almacenar los datos que deben cargarse o guardarse.
Snowflake consta de tres tipos de caché. Aquí tienes una tabla comparativa y algunos casos de uso de cada uno de ellos:
| Tipo de caché | Descripción | Duración | Caso práctico |
|---|---|---|---|
| Caché de resultados | Almacena en caché los resultados de las consultas en todos los almacenes virtuales, para que las consultas repetidas puedan recuperar los resultados al instante. | 24 horas | Acelerar consultas idénticas con los mismos resultados |
| Caché de disco local | Almacena los datos a los que se ha accedido recientemente en el disco local de cada almacén virtual, lo que permite una recuperación más rápida de los datos a los que se accede con frecuencia. | Hasta que se suspenda el almacén virtual | Mejora el rendimiento de las consultas repetidas en el mismo almacén |
| Caché remoto | Almacenamiento de datos a largo plazo en discos remotos para mayor durabilidad, permitiendo el acceso a los datos incluso tras interrupciones del servicio. | Permanente, con una durabilidad del 99,999999999%. | Garantiza que los datos estén disponibles y sean resistentes en caso de fallo del centro de datos |
Hay 3 estados diferentes del Almacén Virtual:
Snowflake gestiona la distribución de datos mediante microparticiones, que son creadas y gestionadas automáticamente por Snowflake. Estas microparticiones son pequeñas unidades de almacenamiento (50-150 MB cada una) que almacenan datos en formato de columnas.
La agrupación automática de Snowflake garantiza una distribución eficaz de los datos, minimizando la necesidad de particionarlos manualmente. El uso de microparticiones permite la poda de datos, en la que sólo se accede a las particiones relevantes durante las consultas, lo que mejora el rendimiento. A diferencia de las bases de datos tradicionales, Snowflake abstrae la partición de datos, por lo que los usuarios no necesitan gestionar la distribución de datos manualmente, lo que permite una mejor escalabilidad y facilidad de uso.
Aquí tienes una tabla que contrasta estos mecanismos:
| Mecanismo | Descripción | Benefíciate |
|---|---|---|
| Microparticiones | Pequeñas unidades de almacenamiento en columnas que organizan y comprimen los datos. | Permite la poda de datos, reduciendo la cantidad de datos escaneados para consultas más rápidas. |
| Agrupación automática | Snowflake mantiene automáticamente la agrupación de los datos en microparticiones, adaptándose a medida que cambian los datos. | Simplifica la gestión de datos, sin necesidad de reagrupación manual |
| Poda de datos | Sólo se accede a las microparticiones relevantes basándose en los metadatos, minimizando el escaneo innecesario de datos. | Mejora el rendimiento de la consulta accediendo sólo a los datos necesarios |
El Servicio de Metadatos de Snowflake forma parte de la Capa de Servicios en la Nube, y desempeña un papel fundamental en la optimización de consultas y la gestión de datos. Este servicio rastrea las ubicaciones de almacenamiento de datos, los patrones de acceso y los metadatos de tablas, columnas y particiones. Al recuperar rápidamente los metadatos, permite la poda de datos durante la ejecución de la consulta, lo que reduce la cantidad de datos escaneados y mejora el rendimiento.
Además, el Servicio de Metadatos gestiona y actualiza la Caché de Resultados, lo que permite recuperar consultas más rápidamente cuando se ejecutan consultas similares en un breve espacio de tiempo. En general, el Servicio de Metadatos mejora la eficacia de las consultas y reduce el consumo de recursos.
Las funciones de suspensión y reanudación automáticas de Snowflake ayudan a optimizar el uso de los recursos informáticos y a reducir costes. Cuando un almacén virtual permanece inactivo durante un periodo definido, la suspensión automática apagará automáticamente el almacén para evitar gastos de cálculo innecesarios.
Por el contrario, la función de reanudación automática pone en marcha el almacén automáticamente cuando se recibe una nueva consulta. Esto garantiza que los usuarios sólo paguen por el tiempo de cálculo cuando el almacén esté procesando activamente las consultas.
Estas funciones son especialmente beneficiosas en entornos con cargas de trabajo esporádicas, ya que optimizan la rentabilidad manteniendo la disponibilidad.
Se puede crear un almacén virtual a través de la interfaz web o utilizando SQL. Estos son los 3 métodos diferentes:
CREATE [ OR REPLACE ] WAREHOUSE [ IF NOT EXISTS ] <name>
[ [ WITH ] objectProperties ]
[ [ WITH ] TAG ( <tag_name> = '<tag_value>' [ , <tag_name> = '<tag_value>' , ... ] ) ]
[ objectParams ]Para crear una tarea Snowflake, tendrás que utilizar la opción "CREAR TAREA". Tendrás que definir la sentencia SQL o el procedimiento almacenado en la definición de la tarea y asegurarte de que tienes el permiso necesario para crear tareas. Estos son los siguientes pasos:
CREATE TASK', a continuación del nombre de tu tarea.WAREHOUSE'SCHEDULE'.AS'.CALL' utilizando el procedimiento almacenado.Por ejemplo:
CREATE TASK daily_sales_datacamp
WAREHOUSE = 'datacampwarehouse'
SCHEDULE = 'USING CRON 0 1 * * * UTC'
AS
CALL daily_sales_datacamp();Esta consulta demuestra cómo trabajar con datos JSON semiestructurados en Snowflake:
SELECT
feedback_details:customer_id::INT AS customer_id,
feedback_details:feedback_text::STRING AS feedback_text,
feedback_details:timestamp::TIMESTAMP AS feedback_timestamp
FROM
customer_feedback
WHERE
feedback_details:customer_id::INT = 123; -- Replace 123 with the specific customer_id you're interested inPara verificar el historial de una tarea Snowflake, puedes utilizar la función de la tabla 'TASK_HISTORY'. Esto te proporcionará información detallada sobre el historial de ejecución de tareas en un periodo de tiempo concreto.
SELECT *
FROM TABLE(INFORMATION_SCHEMA.TASK_HISTORY(
TASK_NAME => '<task_name>',
START_TIME => '<start_time>',
END_TIME => '<end_time>'
))
ORDER BY SCHEDULED_TIME DESC;Tendrás que utilizar la sentencia 'CREAR TABLA TEMPORAL' en Snowflake. Esto creará una tabla específica de la sesión que sólo existirá durante el tiempo establecido por el usuario.
CREATE TEMPORARY TABLE table_name (
column_name1 data_type1,
column_name2 data_type2,
...
);Snowflake proporciona la función CONVERT_TIMEZONE para convertir marcas de tiempo entre zonas horarias. Aquí tienes un ejemplo de cómo convertir una marca de tiempo de UTC a Hora Estándar del Este (EST):
SELECT
customer_id,
CONVERT_TIMEZONE('UTC', 'America/New_York', order_timestamp) AS order_timestamp_est
FROM
orders;En esta consulta, sustituye customer_id y order_timestamp por las columnas concretas de tu tabla. Esta función permite conversiones flexibles de zonas horarias, por lo que es ideal para informes globales.
Puedes crear un clon de copia cero de una tabla en Snowflake utilizando la sentencia CREATE TABLE ... CLONE. Este clon comparte el mismo almacenamiento subyacente, ahorrando costes y espacio de almacenamiento.
CREATE TABLE cloned_table_name CLONE original_table_name;Por ejemplo, para clonar una tabla llamada sales_datala sintaxis sería
CREATE TABLE sales_data_clone CLONE sales_data;Esta tabla clonada tendrá los mismos datos y esquema que la original en el momento de la clonación. Cualquier cambio realizado en la tabla clonada después de su creación no afectará a la original.
Puedes utilizar la cláusula GROUP BY con ORDER BY y LIMIT para recuperar los 5 valores más frecuentes de una columna concreta. Por ejemplo, si quieres encontrar los 5 productos más comunes en la columna product_id:
SELECT
product_id,
COUNT(*) AS frequency
FROM
sales
GROUP BY
product_id
ORDER BY
frequency DESC
LIMIT 5;Esta consulta agrupa la columna product_id columna por frecuencia, los ordena en orden descendente y limita los resultados a los 5 primeros, mostrando los productos vendidos con más frecuencia.
Cuando te prepares para cualquier entrevista, es importante que hagas lo siguiente:
Por último, pero no por ello menos importante, ¡ten confianza en ti mismo y da lo mejor de ti!
En este artículo hemos cubierto las preguntas de la entrevista de Snowflake para 4 niveles diferentes:
Si buscas recursos para refrescar o poner a prueba tus conocimientos sobre Snowflake, echa un vistazo a nuestros tutoriales sobre Introducción a Snowflake y Primeros pasos en el análisis de datos en Snowflake utilizando Python y SQL y también a nuestro curso Introducción a NoSQL, donde aprenderás a utilizar Snowflake para trabajar con big data.
Escucha también nuestro episodio de podcast con Bob Muglia, ex director general de Snowflake, sobre "Por qué la IA lo cambiará todo".
¡Comienza hoy tu viaje con Snowflake!
Curso
Curso
blog
Abid Ali Awan
15 min
blog
Matt Crabtree
12 min
blog
Austin Chia
15 min
blog
Josep Ferrer
15 min
blog
Abid Ali Awan
15 min
