
Course
Data Modeling in Power BI
3 hr
94.7K
Before we dive into Snowflake’s architecture, let’s review data warehouses to ensure we are all on the same page.
A data warehouse is a centralized repository that stores large amounts of structured and organized data from various sources for a company. Different personas (employees) in organizations use the data within to derive different insights.
For example, data analysts, in collaboration with the marketing team, may run an A/B test for a new marketing campaign using the sales table. HR specialists may query the employee information to track performance.
These are some of the examples of how companies globally use data warehouses to drive growth. But without proper implementation and management using tools like Snowflake, data warehouses remain as elaborate concepts.
You can learn more about the subject with our Data Warehousing course.
Snowflake’s unique architecture, designed for faster analytical queries, comes from its separation of the storage and compute layers. This distinction contributes to the benefits we’ve mentioned earlier.
In Snowflake, the storage layer is a critical component, storing data in an efficient and scalable manner. Here are some key features of this layer:
Now, let’s look at the compute layer.
As the name suggests, the compute layer is the engine that executes your queries. It works in conjunction with the storage layer to process the data and perform various computational tasks. Below are some more details about how this layer operates:
These design principles of the compute layer all contribute to Snowflake’s ability to handle different and demanding workloads in the cloud.
The final layer is cloud services. As this layer integrates into every component of Snowflake’s architecture, there are many details on its operation. In addition to the features related to other layers, it has the following additional responsibilities:
Now that we have a high-level picture of Snowflake’s architecture, let’s write some SQL on the platform.
Snowflake has its own version of SQL called Snowflake SQL. The difference between it and other SQL dialects is akin to the difference between English accents.
Many of the analytical queries you perform in dialects like PostgreSQL don’t change, but there are some discrepancies in DDL (Data Definition Language) commands.
Now, le'ts see how to run some queries!
To begin with Snowsight, navigate to the Snowflake 120-day free trial page and create an account. Input your personal information and select any listed cloud provider. This gives a 120-day free trial rather than the more standard 30-day trial you find elsewhere. The trial also inludes $400 worth of credits.
When signing up for a trial, it's recommend that users pick AWS and the US-Oregon West region. Among other reasons, Oregon is one of the lowest-cost regions for AWS infrastructure and, as a result, trial credits last longer.
After verifying your email, you’ll be redirected to the Worksheets page. Worksheets are interactive, live-coding environments where you can write, execute, and view the results of your SQL queries.
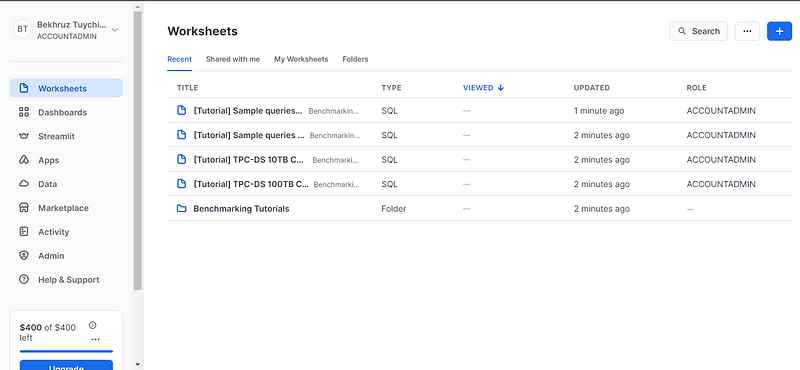
To run some queries, we need a database and a table (we won’t be using the sample data in Snowsight). To get started, I suggest you try to create a new database (you could name it something like test_db) and a table named using a local CSV file. You can download the CSV file by running the code in this GitHub gist in your terminal.
Afterward, you will be directed to a new worksheet where you can run any SQL query you want. I find the worksheet interface is quite straightforward and highly functional. Take a few minutes to familiarize yourself with the panels, the buttons, and their respective locations.
Whew! We started off with some simple concepts, but towards the end, we really dove into the gnarly details. Well, that’s my idea of a decent tutorial.
You’ve probably guessed that there is much more to Snowflake than what we’ve covered. In fact, the Snowflake documentation includes quickstart guides that are actually 128 minutes long! But before you tackle those, I recommend getting your hands wet with some other resources. How about these:
Thank you for reading!
Our certification programs help you stand out and prove your skills are job-ready to potential employers.

Start Your Database Journey Today!
Course
Course
Course
blog
Tim Lu
12 min
blog
Bex Tuychiev
12 min
Tutorial
Bex Tuychiev
Tutorial
Gus Frazer
Tutorial
Tim Lu
Tutorial
Tim Lu

