R es una potente herramienta para la implementación de la clasificación KNN, y generalmente es utilizada por científicos de datos y estadísticos para diversas aplicaciones de aprendizaje automático.
En este tutorial, aprenderemos sobre K-Nearest Neighbors, cómo funciona y revisaremos algunas ventajas y desventajas. Además, utilizaremos el paquete R 'class' y 'caret' para implementar fácilmente el modelo de clasificación KNN.
¿Qué es K-Nearest Neighbors?
K-Nearest Neighbors (KNN) es un modelo de aprendizaje automático supervisado que puede utilizarse tanto para tareas de regresión como de clasificación. El algoritmo es no paramétrico, lo que significa que no hace ninguna suposición sobre la distribución subyacente de los datos.
El algoritmo KNN predice las etiquetas del conjunto de datos de prueba observando las etiquetas de sus vecinos más cercanos en el espacio de características del conjunto de datos de entrenamiento. K" es el hiperparámetro más importante que puede ajustarse para optimizar el rendimiento del modelo.
KNN es un algoritmo sencillo e intuitivo que proporciona buenos resultados para una amplia gama de problemas de clasificación. Es fácil de aplicar y comprender, y se aplica tanto a conjuntos de datos pequeños como grandes. Sin embargo, también presenta algunos inconvenientes, y la principal desventaja es que puede ser costoso desde el punto de vista informático para grandes conjuntos de datos o espacios de características de alta dimensión.
El algoritmo KNN se utiliza en motores de recomendación de comercio electrónico, reconocimiento de imágenes, detección de fraudes, clasificación de textos, detección de anomalías y muchos más. En este tutorial, utilizaremos el algoritmo KNN para un sistema de aprobación de préstamos.
Si está confundido y no sabe cómo comenzar su viaje en la ciencia de datos, tome Data Scientist Professional con la pista de carrera de R y prepárese para una carrera exitosa en la ciencia de datos. El itinerario de habilidades le ayudará a dominar la programación en R, la ingesta de datos, la limpieza de datos, la manipulación de datos, la visualización de datos, el aprendizaje automático, las pruebas de hipótesis, los diseños experimentales, SQL y Git.
¿Cómo funciona la clasificación K-Nearest Neighbors?
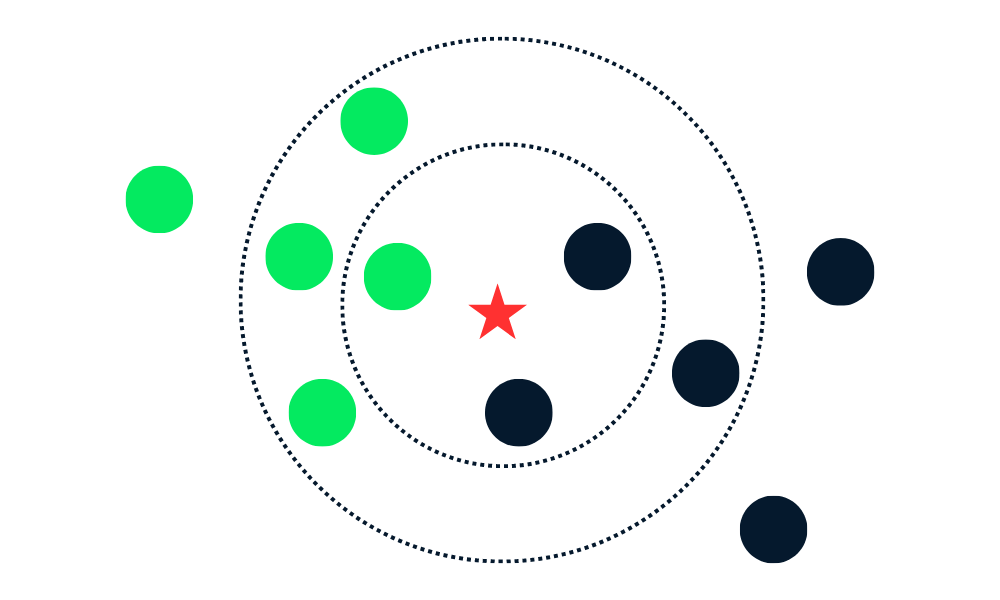
El algoritmo de clasificación KNN funciona encontrando K vecinos (puntos de datos más cercanos) en el conjunto de datos de entrenamiento a un nuevo punto de datos. A continuación, asigna la etiqueta de la clase mayoritaria entre los vecinos a los nuevos puntos de datos.
Desglosemos los algoritmos en varias partes.
En primer lugar, calcula la distancia entre los nuevos puntos de datos y todos los demás puntos de datos del conjunto de entrenamiento y selecciona los K puntos más cercanos. La métrica utilizada para calcular la distancia puede variar en función de los problemas. La métrica más utilizada es la distancia euclídea.
Tras identificar a los K vecinos más cercanos, el algoritmo asigna al nuevo punto de datos la etiqueta de la clase mayoritaria entre esos vecinos. Por ejemplo, si las dos etiquetas son "azul" y una es "rojo", el algoritmo asignará la etiqueta "azul" a un nuevo punto de datos.
Gif de eunsukim.me
Resumen:
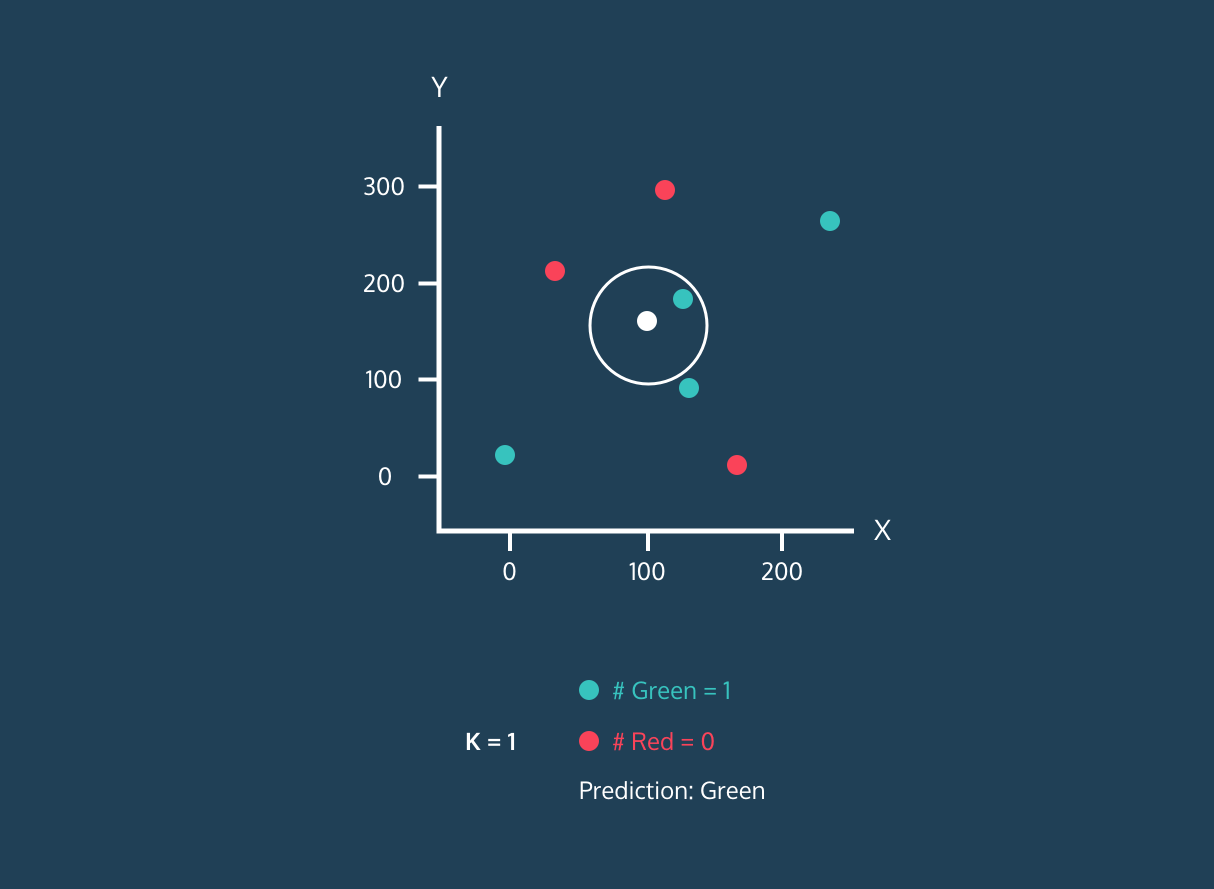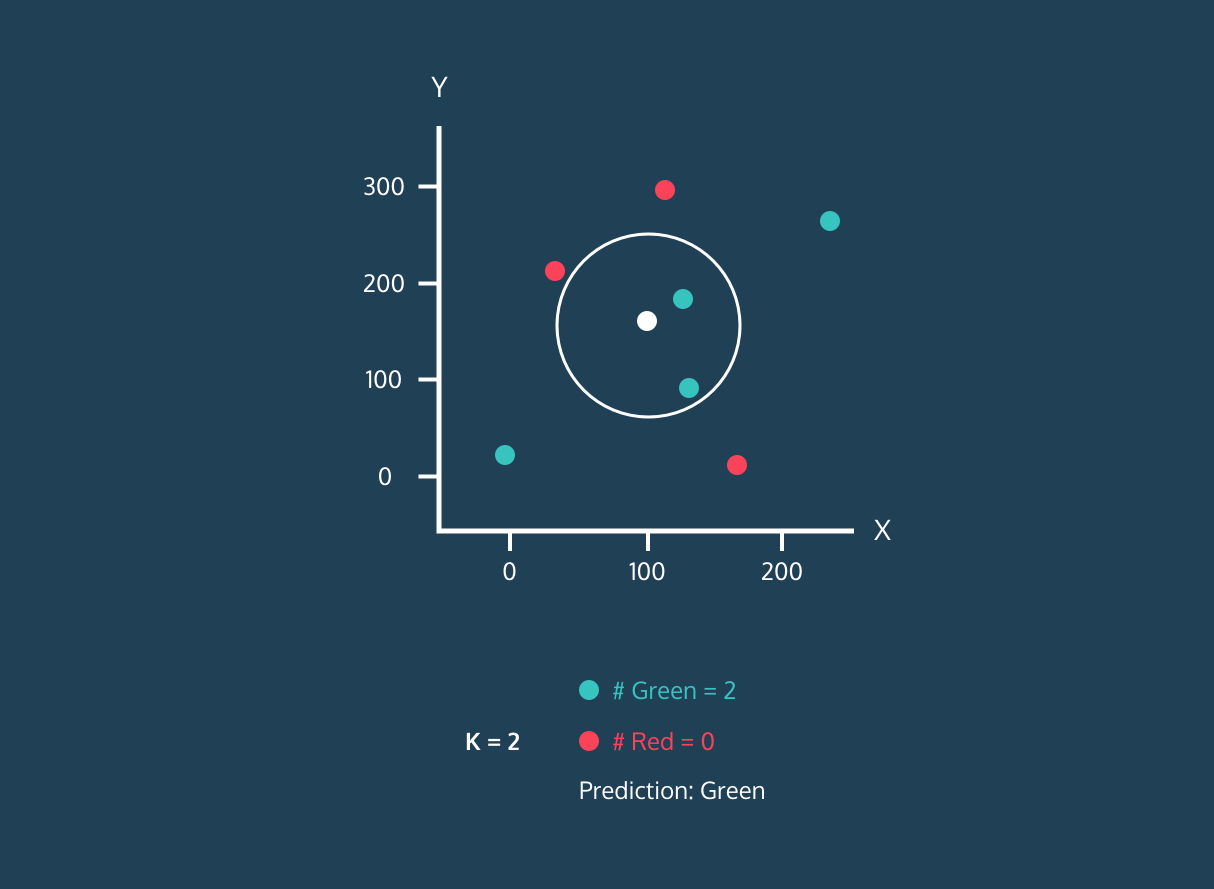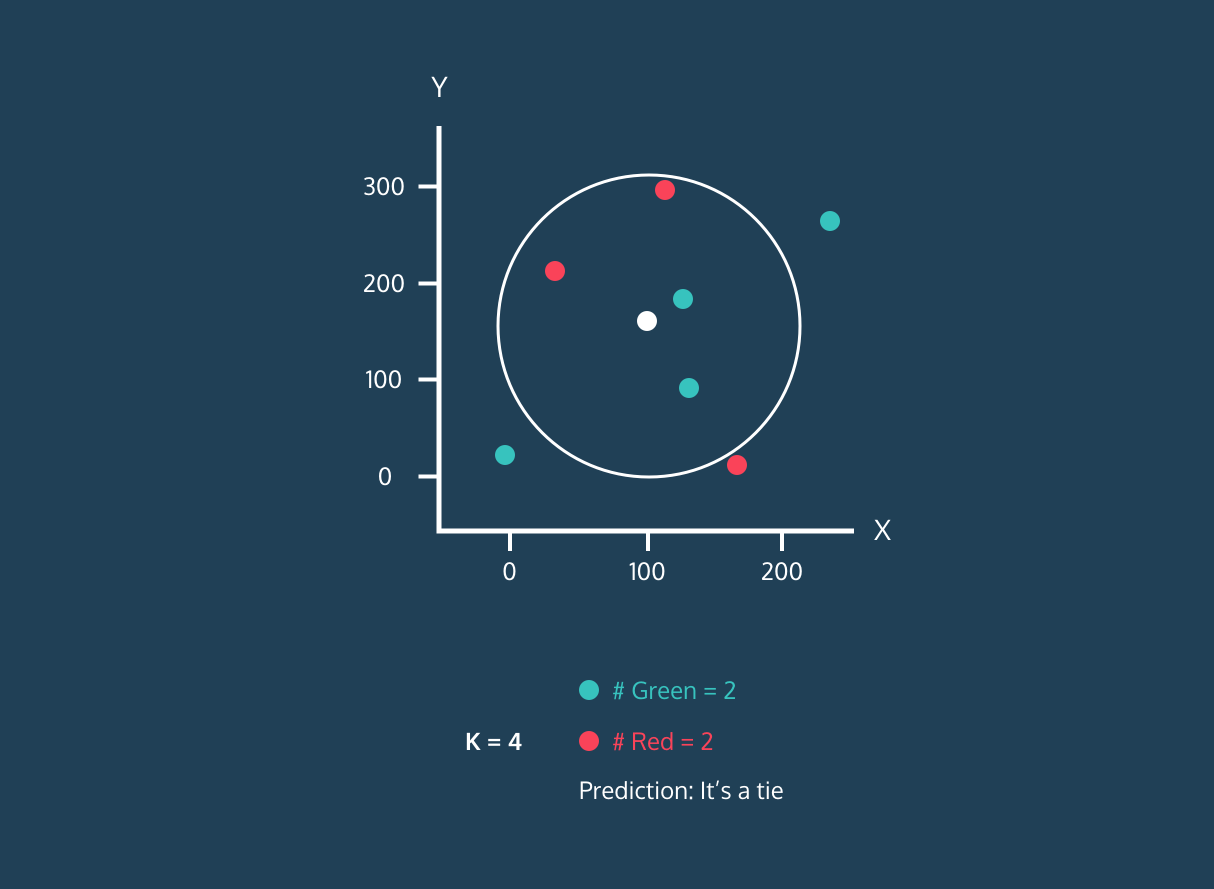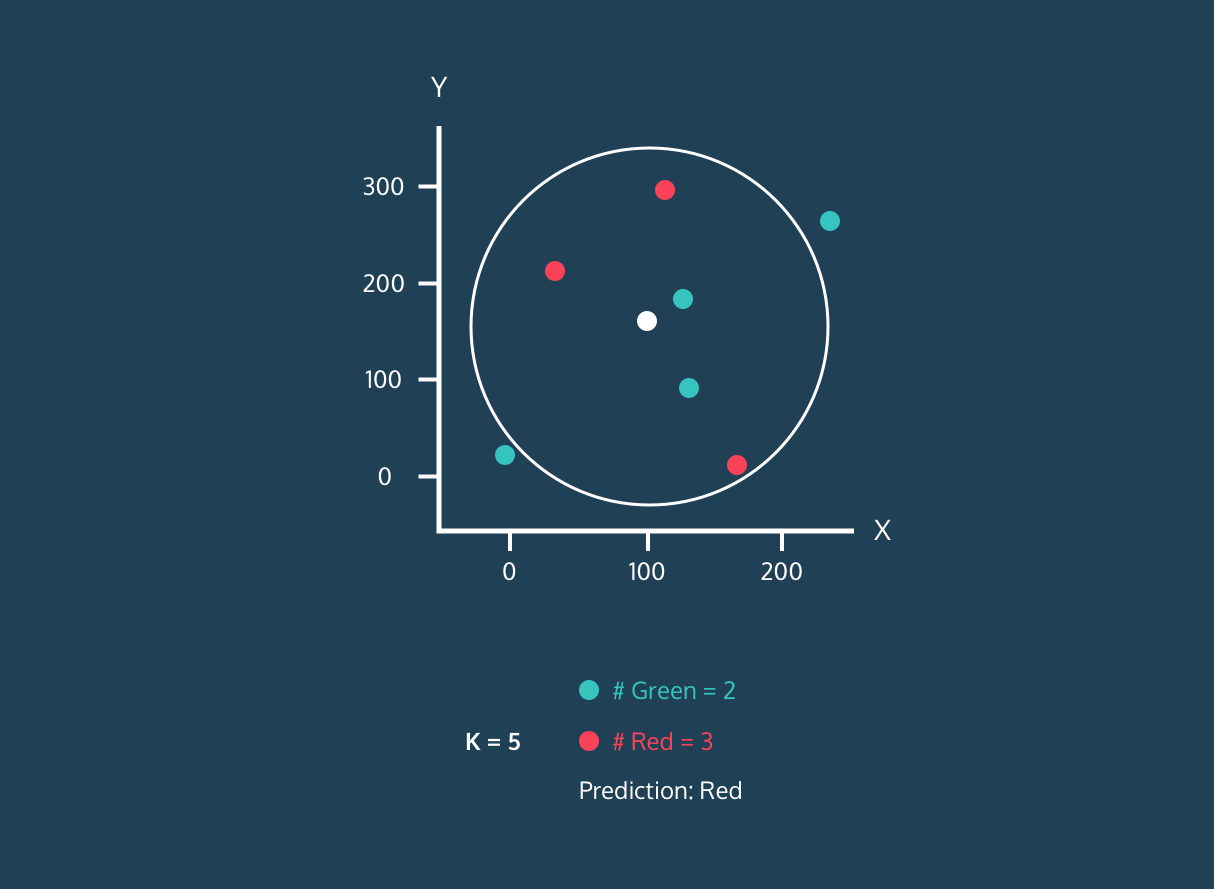
- Elegiremos el valor de K, que es el número de vecinos más cercanos que se utilizarán para hacer la predicción.
- Calcula la distancia entre ese punto y todos los puntos del conjunto de entrenamiento.
- Seleccione los K vecinos más próximos en función de las distancias calculadas.
- Asigne la etiqueta de la clase mayoritaria al nuevo punto de datos.
- Repita los pasos 2 a 4 para todos los puntos de datos del conjunto de prueba.
- Evaluar la precisión del algoritmo.
El valor de "K" lo proporciona el usuario y puede utilizarse para optimizar el rendimiento del algoritmo. Los valores de K más pequeños pueden llevar a un ajuste excesivo, y los valores más grandes a un ajuste insuficiente. Por lo tanto, es crucial encontrar valores óptimos que proporcionen estabilidad y el mejor ajuste.
Implementación de KNN en R
En esta sección, utilizaremos Datos de Préstamos y entrenaremos la clasificación KNN utilizando el paquete class. El conjunto de datos consta de 10.000 préstamos, y averiguaremos si un préstamo se devolverá basándonos en los datos del cliente.
Cargar los datos
Importaremos la biblioteca tidyverse para acceder a paquetes R esenciales para la carga, manipulación y visualización de datos. suppressPackageStartupMessages suprimirá las advertencias y obtendrá una salida limpia.
A continuación, utilizaremos read_csv para cargar el conjunto de datos, eliminar la columna "propósito" del marco de datos mediante la función subset y mostrar las 3 muestras principales.
suppressPackageStartupMessages(library(tidyverse))
data <- read_csv('data/loans.csv.gz', show_col_types = FALSE)
data <- subset(data, select = -c(purpose))
head(data,3)
Formar y probar la división
Podemos dividir el conjunto de datos manualmente, pero utilizar la biblioteca caTools es mucho más limpio.
- Establecer la semilla de la reproducibilidad.
- Utilice
sample.splitpara crear un índice para los conjuntos de datos de entrenamiento y prueba en una proporción de 75:25. - Utilice
subsetpara crear un conjunto de datos de entrenamiento y de prueba, como se muestra a continuación.
library(caTools)
set.seed(255)
split = sample.split(data$not_fully_paid,
SplitRatio = 0.75)
train = subset(data,
split == TRUE)
test = subset(data,
split == FALSE)Escalado de características
Ahora escalaremos tanto el conjunto de entrenamiento como el de pruebas. En el backend, la función utiliza (x - mean(x)) / sd(x). Sólo escalamos las características y eliminamos las etiquetas objetivo de los conjuntos de prueba y entrenamiento.
train_scaled = scale(train[-13])
test_scaled = scale(test[-13])Entrenamiento del clasificador KNN y predicción
La biblioteca class es bastante popular para entrenar la clasificación KNN. Es sencillo y rápido. Proporcionaremos un conjunto de datos de entrenamiento y prueba a escala, una columna objetivo y un hiperparámetro "k".
library(class)
test_pred <- knn(
train = train_scaled,
test = test_scaled,
cl = train$not_fully_paid,
k=10
)Evaluación de modelos
Para evaluar los resultados del modelo, mostraremos una matriz de confusión utilizando una función table. Hemos proporcionado etiquetas reales (objetivo de prueba) y predichas a la función table, y como podemos ver, tenemos resultados bastante buenos para la clase mayoritaria.
El algoritmo KNN no es bueno para tratar datos desequilibrados, y por eso vemos un rendimiento pobre en las clases minoritarias.
actual <- test$not_fully_paid
cm <- table(actual,test_pred)
cm test_pred
actual 0 1
0 1988 23
1 373 10Podemos calcular la precisión sumando los valores positivos verdaderos de la matriz de confusión y dividiéndolos por la longitud total de las columnas objetivo.
Como podemos observar, tenemos una buena precisión en un modelo vainilla. Podemos mejorar esta precisión ajustando el hiperparámetro "K" y equilibrando el conjunto de datos.
accuracy <- sum(diag(cm))/length(actual)
sprintf("Accuracy: %.2f%%", accuracy*100)'Accuracy: 83.46%'Clasificación KNN en R utilizando caret
En esta sección, utilizaremos caret para todo. caret es un paquete de R para construir y evaluar modelos de aprendizaje automático. Proporciona una interfaz para los principales algoritmos de aprendizaje automático.
Lo utilizaremos para dividir y preprocesar el conjunto de datos, realizar el ajuste de hiperparámetros y entrenar y evaluar modelos.
Formar y probar la división
Importaremos el paquete caret y estableceremos la semilla para la reproducibilidad. Después, convertiremos la variable de destino de un número entero a un factor. Al final, utilizaremos createDataPartition para dividir el conjunto de datos en conjuntos de datos de entrenamiento y de prueba utilizando una proporción de 80:20.
suppressPackageStartupMessages(library(caret))
set.seed(255)
data$not_fully_paid <- factor(data$not_fully_paid, levels = c(0, 1))
trainIndex <- createDataPartition(data$not_fully_paid,
times=1,
p = .8,
list = FALSE)
train <- data[trainIndex, ]
test <- data[-trainIndex, ]Preprocesamiento de datos
A continuación, escalaremos tanto el conjunto de entrenamiento como el de pruebas utilizando la función preProcess.
preProcValues <- preProcess(train, method = c("center", "scale"))
trainTransformed <- predict(preProcValues, train)
testTransformed <- predict(preProcValues, test)Ajuste de modelos
Antes de entrenar nuestro modelo KNN, tenemos que encontrar el valor óptimo de "K" utilizando la función de entrenamiento. La función entrenar requiere una fórmula, un conjunto de datos de entrenamiento a escala, el nombre del modelo, el método de control del entrenamiento (validación cruzada) y una lista de hiperparámetros. Vamos a comprobar el rendimiento del modelo cuando "K" es 3, 5 y 7.
knnModel <- train(
not_fully_paid ~ .,
data = trainTransformed,
method = "knn",
trControl = trainControl(method = "cv"),
tuneGrid = data.frame(k = c(3,5,7))
)Formación Modelo más eficaz
Después de encontrar el mejor valor de "K", entrenaremos el modelo de clasificación KNN con un conjunto de datos de entrenamiento escalado.
best_model<- knn3(
not_fully_paid ~ .,
data = trainTransformed,
k = knnModel$bestTune$k
)Evaluación de modelos
caret ofrece una función de evaluación de modelos sencilla y potente. Para mostrar los resultados de rendimiento del modelo, primero tenemos que predecir etiquetas para el conjunto de datos de prueba no visto. A continuación, utilizaremos los valores previstos y reales para evaluar el rendimiento del modelo mediante la función confusionMatrix .
predictions <- predict(best_model, testTransformed,type = "class")
# Calculate confusion matrix
cm <- confusionMatrix(predictions, testTransformed$not_fully_paid)
cmComo resultado, obtenemos la matriz de confusión, la precisión del modelo, el valor P, la sensibilidad del modelo y otras métricas importantes que nos ayudarán a determinar la estabilidad y el rendimiento del modelo.
Como podemos ver, el modelo ha funcionado bastante mal en "Neg Pred Value", que es una clase minoritaria, y nuestra precisión equilibrada es del 51%. Podemos obtener un resultado similar con el lanzamiento de una moneda.
Podemos mejorar el resultado equilibrando las clases mediante métodos de sobremuestreo y submuestreo. También podemos realizar ingeniería de rasgos y crear nuevos rasgos y eliminar rasgos muy correlacionados.
Confusion Matrix and Statistics
Reference
Prediction 0 1
0 1570 288
1 39 18
Accuracy : 0.8292
95% CI : (0.8116, 0.8458)
No Information Rate : 0.8402
P-Value [Acc > NIR] : 0.9091
Kappa : 0.0516
Mcnemar's Test P-Value : <2e-16
Sensitivity : 0.97576
Specificity : 0.05882
Pos Pred Value : 0.84499
Neg Pred Value : 0.31579
Prevalence : 0.84021
Detection Rate : 0.81984
Detection Prevalence : 0.97023
Balanced Accuracy : 0.51729
'Positive' Class : 0También podemos simplificar nuestro resultado mostrándolo como un marco de datos.
data.frame(Accuracy = cm$overall["Accuracy"],
Sensitivity = cm$byClass["Sensitivity"],
Specificity = cm$byClass["Specificity"])
Si eres un amante de Python y quieres aprender a realizar la clasificación KNN, lee nuestro tutorial K-Nearest Neighbors (KNN) Classification with scikit-learn para entender los conceptos KNN y el flujo de trabajo con ejemplos.
Ventajas e inconvenientes del uso de KNN
Advantages
- Es un algoritmo sencillo de entender y aplicar.
- Es versátil y puede utilizarse tanto para tareas de regresión como de clasificación.
- Proporciona resultados interpretables que pueden visualizarse y comprenderse, ya que la clase predicha se basa en las etiquetas de los vecinos más próximos en los datos de entrenamiento.
- KNN no hace suposiciones sobre el límite de decisión entre clases, y esta característica le permite capturar relaciones no lineales entre características.
- El algoritmo no hace suposiciones sobre la distribución de los datos, lo que lo hace adecuado para una amplia gama de problemas.
- KNN no construye el modelo. Almacena los datos de entrenamiento y los utiliza para la predicción.
Disadvantages
- Es costoso desde el punto de vista informático y de memoria para conjuntos de datos grandes y complejos.
- El rendimiento de KNN disminuye con datos desequilibrados. Muestra prejuicios hacia la clase mayoritaria, lo que puede dar lugar a malos resultados para las clases minoritarias.
- No es adecuado para datos ruidosos. Dado que los vecinos más cercanos de un punto de datos pueden no ser representativos de la verdadera etiqueta de clase.
- No es adecuado para datos de alta dimensión, ya que la alta dimensionalidad puede hacer que la distancia entre todos los puntos de datos sea similar.
- Encontrar el número óptimo de K vecinos puede llevar mucho tiempo.
- KNN es sensible a los valores atípicos, ya que elige a los vecinos en función de la métrica de evidencia.
- No maneja bien los valores que faltan en el conjunto de datos de entrenamiento.
Conclusión
En este tutorial, hemos aprendido a utilizar la clasificación K-Nearest Neighbors (KNN) con R. Hemos cubierto el concepto básico de KNN y cómo funciona. Además, hemos conocido dos bibliotecas, class y caret, para entrenar y evaluar modelos de clasificación KNN en un conjunto de datos real.
Visite Supervised Learning in R: Clasificación curso para conocer otros algoritmos de aprendizaje automático supervisado con programación R. Aprenderá sobre Naive Bayes, Regresión Logística y Árboles de Clasificación con ejemplos y ejercicios de código.
Los tutoriales de R incluyen pasos para manipular, dividir y procesar el conjunto de datos, ajustar los hiperparámetros, entrenar los modelos y evaluar los resultados. Debido a un conjunto de datos desequilibrado, obtuvimos el peor rendimiento en la clase minoritaria.
Hay que entender que el algoritmo KNN no es perfecto, también tiene algunas desventajas, y hay que tener muchas cosas en cuenta antes de seleccionarlo como modelo principal.
