Curso
Introducción a R
4 h
3M
Ejecuta y edita el código de este tutorial en línea
Ejecutar código¿Está interesado en aprender más sobre la manipulación de datos en R con dplyr? Eche un vistazo al curso Data Manipulation in R with dplyr de DataCamp.
Para entender qué es el operador pipa en R y qué se puede hacer con él, es necesario considerar el cuadro completo, aprender la historia que hay detrás. Preguntas como "¿de dónde viene esta extraña combinación de símbolos y por qué se hizo así?" pueden rondar por tu cabeza. En esta sección descubrirá las respuestas a estas y otras preguntas.
Ahora, puedes mirar la historia desde tres perspectivas: desde un punto de vista matemático, desde un punto de vista holístico de los lenguajes de programación y desde el punto de vista del propio lenguaje R. En lo que sigue se tratarán los tres.
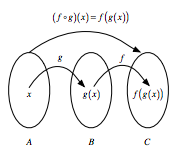
Si tienes dos funciones, digamos $f : B → C$ y $g : A → B$, puedes encadenar estas funciones tomando la salida de una función e insertándola en la siguiente. En pocas palabras, "encadenar" significa que pasas un resultado intermedio a la siguiente función, pero eso lo verás más adelante.
Por ejemplo, se puede decir, $f(g(x))$: $g(x)$ sirve como entrada para $f()$, mientras que $x$, por supuesto, sirve como entrada para $g()$.
Si quieres anotar esto, utilizarás la notación $f ◦ g$, que se lee como "f sigue a g". Alternativamente, puedes representarlo visualmente como:
Como se mencionó en la introducción de esta sección, este operador no es nuevo en programación: en el Shell o Terminal, puede pasar comandos de uno a otro con el carácter de canalización |. Del mismo modo, F# dispone de un operador de tubería hacia delante, que resultará importante más adelante. Por último, también es bueno saber que Haskell contiene muchas operaciones de tuberías que se derivan de la Shell o Terminal.
Ahora que ya has visto algo de historia del operador pipe en otros lenguajes de programación, es hora de centrarnos en R. La historia de este operador en R comienza el 17 de enero de 2012, cuando un usuario anónimo hizo la siguiente pregunta en este post de Stack Overflow:
¿Cómo se puede implementar el operador forward pipe de F# en R? El operador permite encadenar fácilmente una secuencia de cálculos. Por ejemplo, si tiene un dato de entrada y desea llamar a las funciones
fooybaren secuencia, puede escribirdata |> foo |> bar?
La respuesta la dio Ben Bolker, profesor de la Universidad McMaster:
No sé hasta qué punto se sostendría en un uso real, pero esto parece (?) hacer lo que quieres, al menos para funciones de un solo argumento ...
"%>%" <- function(x,f) do.call(f,list(x)) pi %>% sin [1] 1.224606e-16 pi %>% sin %>% cos [1] 1 cos(sin(pi)) [1] 1
Unos nueve meses después, Hadley Wickham creó el paquete dplyr en GitHub. Puede que ya conozca a Hadley, científico jefe de RStudio, como autor de muchos paquetes populares de R (¡como este último paquete!) y como instructor del curso Writing Functions in R de DataCamp.
Sin embargo, no fue hasta 2013 cuando apareció la primera tubería %.% en este paquete. Como bien menciona Adolfo Álvarez en su entrada del blog, la función se denominó chain(), que tenía el propósito de simplificar la notación para la aplicación de varias funciones a un mismo marco de datos en R.
La tubería %.% no duraría mucho, ya que Stefan Bache propuso el 29 de diciembre de 2013 una alternativa que incluía la operadora tal y como podrías conocerla ahora:
iris %>%
subset(Sepal.Length > 5) %>%
aggregate(. ~ Species, ., mean)
Bache siguió trabajando con esta operación de tuberías y, a finales de 2013, vio la luz el paquete magrittr. Mientras tanto, Hadley Wickham siguió trabajando en dplyr y, en abril de 2014, el operador de %.% fue sustituido por el que ahora conoces, %>%.
Ese mismo año, Kun Ren publicó en GitHub el paquete pipeR, que incorporaba un operador de tuberías diferente, %>>%, diseñado para añadir más flexibilidad al proceso de tuberías. Sin embargo, se puede afirmar con seguridad que la %>% está ahora establecida en el lenguaje R, especialmente con la reciente popularidad del Tidyverse.
Conocer la historia es una cosa, pero eso todavía no te da una idea de lo que es el operador forward pipe de F# ni lo que realmente hace en R.
En F#, el operador pipe-forward |> es azúcar sintáctico para llamadas a métodos encadenados. O, dicho de forma más sencilla, permite pasar un resultado intermedio a la siguiente función.
Recuerda que "encadenar" significa que invocas múltiples llamadas a métodos. Como cada método devuelve un objeto, se pueden encadenar las llamadas en una única sentencia, sin necesidad de variables para almacenar los resultados intermedios.
En R, el operador de tubería es, como ya ha visto, %>%. Si no está familiarizado con F#, puede pensar que este operador es similar a + en una sentencia ggplot2. Su función es muy similar a la que has visto del operador F#: toma la salida de una sentencia y la convierte en la entrada de la siguiente sentencia. Al describirlo, se puede pensar en él como un "ENTONCES".
Tome, por ejemplo, el siguiente fragmento de código y léalo en voz alta:
iris %>%
subset(Sepal.Length > 5) %>%
aggregate(. ~ Species, ., mean)
Tienes razón, el trozo de código anterior se traducirá en algo así como "tomas los datos de Iris, luego los subconjuntas y luego los agregas".
Esta es una de las cosas más poderosas del Tidyverse. De hecho, disponer de una cadena estandarizada de acciones de procesamiento se denomina "pipeline". Crear canalizaciones para un formato de datos es genial, porque puedes aplicar esa canalización a los datos entrantes que tengan el mismo formato y hacer que salgan en un formato compatible con ggplot2, por ejemplo.
R es un lenguaje funcional, lo que significa que su código suele contener muchos paréntesis, ( y ). Cuando se tiene un código complejo, esto suele significar que habrá que anidar los paréntesis. Esto hace que tu código R sea difícil de leer y entender. Aquí es donde %>% viene al rescate.
Eche un vistazo al siguiente ejemplo, que es un ejemplo típico de código anidado:
# Initialize `x`
x <- c(0.109, 0.359, 0.63, 0.996, 0.515, 0.142, 0.017, 0.829, 0.907)
# Compute the logarithm of `x`, return suitably lagged and iterated differences,
# compute the exponential function and round the result
round(exp(diff(log(x))), 1)
Con la ayuda de %<%, puede reescribir el código anterior de la siguiente manera:
# Import `magrittr`
library(magrittr)
# Perform the same computations on `x` as above
x %>% log() %>%
diff() %>%
exp() %>%
round(1)
¿Le parece difícil? No te preocupes. Más adelante aprenderás cómo hacerlo.
Tenga en cuenta que debe importar la bibliotecamagrittr para que el código anterior funcione. Esto se debe a que el operador de tuberías es, como has leído más arriba, parte de la biblioteca magrittr y es, desde 2014, también una parte de dplyr. Si olvida importar la biblioteca, obtendrá un error como Error in eval(expr, envir, enclos): could not find function "%>%".
Además, tenga en cuenta que no es un requisito formal añadir paréntesis después de log, diff y exp, pero, dentro de la comunidad R, algunos lo utilizarán para aumentar la legibilidad del código.
En resumen, aquí tienes cuatro razones por las que deberías usar tuberías en R:
Estas razones están extraídas de la propia documentación demagrittr . Implícitamente, se recuperan los argumentos de legibilidad y flexibilidad.
Aunque %>% es el operador de tuberías (principal) del paquete magrittr, hay un par de operadores más que debería conocer y que forman parte del mismo paquete:
%<>%;# Initialize `x`
x <- rnorm(100)
# Update value of `x` and assign it to `x`
x %<>% abs %>% sort
%T>%;rnorm(200) %>%
matrix(ncol = 2) %T>%
plot %>%
colSums
Tenga en cuenta que es bueno saber por ahora que el trozo de código anterior es en realidad un atajo para:
rnorm(200) %>%
matrix(ncol = 2) %T>%
{ plot(.); . } %>%
colSums
Pero de eso ya hablaremos más adelante.
%$%.data.frame(z = rnorm(100)) %$%
ts.plot(z)
Por supuesto, estos tres operadores funcionan de forma ligeramente diferente al operador principal %>%. Verás más sobre sus funcionalidades y su uso más adelante en este tutorial.
Tenga en cuenta que, aunque la mayoría de las veces verá las tuberías de magrittr, también puede encontrar otras tuberías a medida que avanza. Algunos ejemplos son wrapr's dot arrow pipe %.>% o to dot pipe %>.%, o el Bizarro pipe ->.;.
Ahora que ya sabe cómo se originó el operador %>%, qué es en realidad y por qué debe utilizarlo, es hora de que descubra cómo puede utilizarlo en su beneficio. Verás que puedes utilizarlo de muchas maneras.
Antes de entrar en los usos más avanzados del operador, conviene echar un vistazo a los ejemplos más básicos en los que se utiliza. En esencia, verás que hay tres reglas que puedes seguir cuando estás empezando:
f(x) puede reescribirse como x %>% fEn resumen, esto significa que las funciones que toman un argumento, function(argument), pueden reescribirse de la siguiente manera: argument %>% function(). Eche un vistazo al siguiente ejemplo, más práctico, para entender cómo estos dos son equivalentes:
# Compute the logarithm of `x`
log(x)
# Compute the logarithm of `x`
x %>% log()
f(x, y) puede reescribirse como x %>% f(y)Por supuesto, hay muchas funciones que no sólo aceptan un argumento, sino varios. Este es el caso aquí: se ve que la función toma dos argumentos, x y y. De forma similar a lo que ha visto en el primer ejemplo, puede reescribir la función siguiendo la estructura argument1 %>% function(argument2), donde argument1 es el marcador de posición magrittr y argument2 la llamada a la función.
Todo esto parece bastante teórico. Veamos un ejemplo más práctico:
# Round pi
round(pi, 6)
# Round pi
pi %>% round(6)
x %>% f %>% g %>% h puede reescribirse como h(g(f(x)))Esto puede parecer complejo, pero no lo es tanto si se observa un ejemplo real en R:
# Import `babynames` data
library(babynames)
# Import `dplyr` library
library(dplyr)
# Load the data
data(babynames)
# Count how many young boys with the name "Taylor" are born
sum(select(filter(babynames,sex=="M",name=="Taylor"),n))
# Do the same but now with `%>%`
babynames%>%filter(sex=="M",name=="Taylor")%>%
select(n)%>%
sum
Observe cómo trabaja de dentro a fuera cuando reescribe el código anidado: primero pone el babynames, luego utiliza %>% para filter() primero los datos. Después, seleccionarás n y por último, sum() todo.
Recuerde también que ya vio otro ejemplo de código anidado de este tipo convertido a código más legible al principio de este tutorial, donde utilizó las funciones log(), diff(), exp() y round() para realizar cálculos en x.
Desgraciadamente, hay algunas excepciones a las normas más generales expuestas en la sección anterior. Veamos algunas de ellas.
Considere este ejemplo, en el que utiliza la función assign() para asignar el valor 10 a la variable x.
# Assign `10` to `x`
assign("x", 10)
# Assign `100` to `x`
"x" %>% assign(100)
# Return `x`
x
10
Se ve que la segunda llamada con la función assign(), en combinación con la tubería, no funciona correctamente. El valor de x no se actualiza.
¿Por qué?
Esto se debe a que la función asigna el nuevo valor 100 a un entorno temporal utilizado por %>%. Por lo tanto, si desea utilizar assign() con la tubería, debe ser explícito sobre el medio ambiente:
# Define your environment
env <- environment()
# Add the environment to `assign()`
"x" %>% assign(100, envir = env)
# Return `x`
x
100
Los argumentos dentro de las funciones sólo se calculan cuando la función los utiliza en R. Esto significa que no se calculan argumentos antes de llamar a la función. Esto también significa que la tubería calcula cada elemento de la función sucesivamente.
Un lugar donde esto es un problema es tryCatch(), que le permite capturar y manejar errores, como en este ejemplo:
tryCatch(stop("!"), error = function(e) "An error")
stop("!") %>%
tryCatch(error = function(e) "An error")
"Un error
Error in eval(expr, envir, enclos): !
Traceback:
1. stop("!") %>% tryCatch(error = function(e) "An error")
2. eval(lhs, parent, parent)
3. eval(expr, envir, enclos)
4. stop("!")
Verás que la forma anidada de escribir esta línea de código funciona perfectamente, mientras que la alternativa canalizada devuelve un error. Otras funciones con el mismo comportamiento son try(), suppressMessages(), y suppressWarnings() en base R.
También hay casos en los que puede utilizar el operador de tubería como marcador de posición de argumentos. Eche un vistazo a los siguientes ejemplos:
f(x, y) puede reescribirse como y %>% f(x, .)En algunos casos, no querrá el valor o el marcador de posición magrittr a la llamada de función en la primera posición, que ha sido el caso en todos los ejemplos que ha visto hasta ahora. Reconsidera esta línea de código:
pi %>% round(6)
Si reescribiera esta línea de código, pi sería el primer argumento de su función round(). ¿Pero qué pasa si quieres reemplazar el segundo, tercer, ... argumento y usar ese como el marcador de posición magrittr para tu llamada a la función?
Observe este ejemplo, en el que el valor se encuentra en la tercera posición de la llamada a la función:
"Ceci n'est pas une pipe" %>% gsub("une", "un", .)
'Ceci n\'est pas un pipe'
f(y, z = x) puede reescribirse como x %>% f(y, z = .)Del mismo modo, es posible que desee hacer que el valor de un argumento específico dentro de su llamada a la función sea el marcador de posición magrittr. Considere la siguiente línea de código:
6 %>% round(pi, digits=.)
Es sencillo utilizar el marcador de posición varias veces en una expresión del lado derecho. Sin embargo, cuando el marcador de posición sólo aparece en una expresión anidada magrittr seguirá aplicando la regla del primer argumento. La razón es que, en la mayoría de los casos, así se obtiene un código más limpio.
Éstas son algunas "reglas" generales que puede tener en cuenta cuando trabaje con marcadores de posición de argumentos en llamadas a funciones anidadas:
f(x, y = nrow(x), z = ncol(x)) puede reescribirse como x %>% f(y = nrow(.), z = ncol(.))# Initialize a matrix `ma`
ma <- matrix(1:12, 3, 4)
# Return the maximum of the values inputted
max(ma, nrow(ma), ncol(ma))
# Return the maximum of the values inputted
ma %>% max(nrow(ma), ncol(ma))
12
12
El comportamiento puede anularse encerrando el lado derecho entre llaves:
f(y = nrow(x), z = ncol(x)) puede reescribirse como x %>% {f(y = nrow(.), z = ncol(.))}# Only return the maximum of the `nrow(ma)` and `ncol(ma)` input values
ma %>% {max(nrow(ma), ncol(ma))}
4
Para terminar, observe también el siguiente ejemplo, en el que posiblemente desee ajustar el funcionamiento del marcador de posición de argumento en la llamada a función anidada:
# The function that you want to rewrite
paste(1:5, letters[1:5])
# The nested function call with dot placeholder
1:5 %>%
paste(., letters[.])
Verá que si el marcador de posición sólo se utiliza en una llamada a una función anidada, ¡el marcador de posición magrittr también se colocará como primer argumento! Si quieres evitar que esto ocurra, puedes utilizar las llaves { y }:
# The nested function call with dot placeholder and curly brackets
1:5 %>% {
paste(letters[.])
}
# Rewrite the above function call
paste(letters[1:5])
Las funciones unarias son funciones que toman un argumento. Cualquier canalización que puedas hacer que consista en un punto ., seguido de funciones y que esté encadenado con %>% puede ser usado más tarde si quieres aplicarlo a valores. Eche un vistazo al siguiente ejemplo:
. %>% cos %>% sin
Esta tubería tomaría algunos datos de entrada, tras lo cual se le aplicarían las funciones cos() y sin().
¡Pero aún no has llegado! Si quieres que esta tubería haga exactamente lo que acabas de leer, tienes que asignarlo primero a una variable f, por ejemplo. Después, puede reutilizarlo más tarde para realizar las operaciones contenidas en el pipeline sobre otros valores.
# Unary function
f <- . %>% cos %>% sin
f
structure(function (value)
freduce(value, `_function_list`), class = c("fseq", "function"
))Recuerde también que podría poner paréntesis después de las funciones cos() y sin() en la línea de código si desea mejorar la legibilidad. Consideremos el mismo ejemplo con paréntesis: . %>% cos() %>% sin().
La creación de funciones en magrittr es muy similar a la creación de funciones en R básico. Si no estás seguro de lo parecidas que son en realidad, mira la línea anterior y compárala con la siguiente línea de código; ¡ambas líneas tienen el mismo resultado!
# is equivalent to
f <- function(.) sin(cos(.))
f
function (.)
sin(cos(.))Hay situaciones en las que se desea sobrescribir el valor del lado izquierdo, como en el ejemplo de abajo. Intuitivamente, utilizará el operador de asignación <- para hacer esto.
# Load in the Iris data
iris <- read.csv(url("http://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data"), header = FALSE)
# Add column names to the Iris data
names(iris) <- c("Sepal.Length", "Sepal.Width", "Petal.Length", "Petal.Width", "Species")
# Compute the square root of `iris$Sepal.Length` and assign it to the variable
iris$Sepal.Length <-
iris$Sepal.Length %>%
sqrt()
Sin embargo, existe un operador de tubería de asignación compuesta, que le permite utilizar una notación abreviada para asignar el resultado de su tubería inmediatamente al lado izquierdo:
# Compute the square root of `iris$Sepal.Length` and assign it to the variable
iris$Sepal.Length %<>% sqrt
# Return `Sepal.Length`
iris$Sepal.Length
Tenga en cuenta que el operador de asignación compuesta %<>% debe ser el primer operador de tubería de la cadena para que esto funcione. Esto concuerda completamente con lo que acabas de leer acerca de que el operador es una notación abreviada para una notación más larga con repetición, en la que se utiliza el operador de asignación normal <-.
Como resultado, este operador asignará un resultado de una canalización en lugar de devolverlo.
El operador tee funciona exactamente igual que %>%, pero devuelve el valor del lado izquierdo en lugar del resultado potencial de las operaciones del lado derecho.
Esto significa que el operador tee puede resultar útil en situaciones en las que se han incluido funciones que se utilizan por su efecto secundario, como el trazado con plot() o la impresión en un archivo.
En otras palabras, funciones como plot() normalmente no devuelven nada. Esto significa que, después de llamar a plot(), por ejemplo, su canalización terminaría. Sin embargo, en el siguiente ejemplo, el operador tee %T>% le permite continuar su canalización incluso después de haber utilizado plot():
set.seed(123)
rnorm(200) %>%
matrix(ncol = 2) %T>%
plot %>%
colSums
Cuando trabaje con R, encontrará que muchas funciones toman un argumento data. Consideremos, por ejemplo, la funciónlm() o la funciónwith() . Estas funciones son útiles en una canalización en la que primero se procesan los datos y luego se pasan a la función.
Para las funciones que no tienen un argumento data, como la función cor(), sigue siendo útil poder exponer las variables de los datos. Ahí es donde entra en juego el operador %$%. Considere el siguiente ejemplo:
iris %>%
subset(Sepal.Length > mean(Sepal.Length)) %$%
cor(Sepal.Length, Sepal.Width)
0.336696922252551
Con la ayuda de %$% te aseguras de que Sepal.Length y Sepal.Width están expuestos a cor(). Del mismo modo, se ve que los datos de la función data.frame() se pasan a ts.plot() para trazar varias series temporales en un gráfico común:
data.frame(z = rnorm(100)) %$%
ts.plot(z)
dplyr y magrittrEn la introducción de este tutorial, ya aprendiste que el desarrollo de dplyr y magrittr se produjo más o menos al mismo tiempo, es decir, alrededor de 2013-2014. Y, como ha podido leer, el paquete magrittr también forma parte del Tidyverse.
En esta sección, descubrirá lo emocionante que puede ser combinar ambos paquetes en su código R.
Para los que no conozcan el paquete dplyr, deben saber que este paquete de R se construyó en torno a cinco verbos, a saber, "seleccionar", "filtrar", "ordenar", "mutar" y "resumir". Si ya has manipulado datos para algún proyecto de ciencia de datos, sabrás que estos verbos conforman la mayoría de las tareas de manipulación de datos que generalmente necesitas realizar en tus datos.
Tomemos un ejemplo de código tradicional que utiliza estas funciones dplyr:
library(hflights)
grouped_flights <- group_by(hflights, Year, Month, DayofMonth)
flights_data <- select(grouped_flights, Year:DayofMonth, ArrDelay, DepDelay)
summarized_flights <- summarise(flights_data,
arr = mean(ArrDelay, na.rm = TRUE),
dep = mean(DepDelay, na.rm = TRUE))
final_result <- filter(summarized_flights, arr > 30 | dep > 30)
final_result
| Año | Mes | DayofMonth | arr | dep |
|---|---|---|---|---|
| 2011 | 2 | 4 | 44.08088 | 47.17216 |
| 2011 | 3 | 3 | 35.12898 | 38.20064 |
| 2011 | 3 | 14 | 46.63830 | 36.13657 |
| 2011 | 4 | 4 | 38.71651 | 27.94915 |
| 2011 | 4 | 25 | 37.79845 | 22.25574 |
| 2011 | 5 | 12 | 69.52046 | 64.52039 |
| 2011 | 5 | 20 | 37.02857 | 26.55090 |
| 2011 | 6 | 22 | 65.51852 | 62.30979 |
| 2011 | 7 | 29 | 29.55755 | 31.86944 |
| 2011 | 9 | 29 | 39.19649 | 32.49528 |
| 2011 | 10 | 9 | 61.90172 | 59.52586 |
| 2011 | 11 | 15 | 43.68134 | 39.23333 |
| 2011 | 12 | 29 | 26.30096 | 30.78855 |
| 2011 | 12 | 31 | 46.48465 | 54.17137 |
Al ver este ejemplo, se entiende inmediatamente por qué dplyr y magrittr pueden trabajar tan bien juntos:
hflights %>%
group_by(Year, Month, DayofMonth) %>%
select(Year:DayofMonth, ArrDelay, DepDelay) %>%
summarise(arr = mean(ArrDelay, na.rm = TRUE), dep = mean(DepDelay, na.rm = TRUE)) %>%
filter(arr > 30 | dep > 30)
Ambos trozos de código son bastante largos, pero se podría argumentar que el segundo trozo de código es más claro si se quieren seguir todas las operaciones. Con la creación de variables intermedias en el primer trozo de código, es posible que se pierda la "fluidez" del código. Con %>% se obtiene una visión más clara de las operaciones que se realizan con los datos.
En resumen, dplyr y magrittr son el equipo ideal para manipular datos en R.
Añadir todas estas tuberías a tu código R puede ser todo un reto. Para hacerte la vida más fácil, John Mount, cofundador y consultor principal de Win-Vector, LLC e instructor de DataCamp, ha publicado un paquete con algunos complementos de RStudio que te permiten crear atajos de teclado para tuberías en R. Los complementos son en realidad funciones de R con un poco de metadatos de registro especiales. Un ejemplo de complemento sencillo puede ser, por ejemplo, una función que inserte un fragmento de texto de uso común, ¡pero también puede llegar a ser muy complejo!
Con estos complementos, podrá ejecutar funciones de R de forma interactiva desde el IDE de RStudio, ya sea mediante atajos de teclado o a través del menú Complementos.
Tenga en cuenta que este paquete es en realidad una bifurcación del paquete de complementos original de RStudio. Sin embargo, tenga cuidado: la compatibilidad con complementos sólo está disponible en la versión más reciente de RStudio. Consulte este artículo sobre los complementos de RStudio para obtener más información sobre el tema.
Puedes descargar los complementos y los atajos de teclado desde GitHub.
En lo anterior, has visto que las tuberías son definitivamente algo que deberías estar usando cuando estás programando con R. Más específicamente, has visto esto al cubrir algunos casos en los que las tuberías demuestran ser muy útiles. Sin embargo, hay algunas situaciones, descritas por Hadley Wickham en "R for Data Science", en las que es mejor evitarlas:
En casos como éste, es mejor crear objetos intermedios con nombres significativos. No sólo te resultará más fácil depurar tu código, sino que también entenderás mejor tu código y a los demás les resultará más fácil entenderlo.
Si no se transforma un objeto primario, sino que se combinan dos o más objetos, es mejor no utilizar la tubería.
Las tuberías son fundamentalmente lineales y expresar relaciones complejas con ellas sólo dará lugar a un código complejo que será difícil de leer y entender.
El uso de tuberías en el desarrollo interno de paquetes no es recomendable, ya que dificulta la depuración.
Para más reflexiones sobre este tema, echa un vistazo a este debate de Stack Overflow. Otras situaciones que aparecen en esa discusión son los bucles, las dependencias de paquetes, el orden de los argumentos y la legibilidad.
En resumen, podría resumirlo todo así: tenga en cuenta las dos cosas que hacen que esta construcción sea tan estupenda, a saber, la legibilidad y la flexibilidad. En cuanto una de estas dos grandes ventajas se vea comprometida, puede plantearse algunas alternativas a favor de las tuberías.
Después de todo lo que has leído puede que también te interesen algunas alternativas que existen en el lenguaje de programación R. Algunas de las soluciones que has visto en este tutorial han sido las siguientes:
En lugar de encadenar todas las operaciones y obtener un único resultado, rompa la cadena y asegúrese de guardar los resultados intermedios en variables separadas. Ten cuidado con el nombre de estas variables: ¡el objetivo debe ser siempre que tu código sea lo más comprensible posible!
Una de las posibles objeciones que podrías tener contra las tuberías es el hecho de que va en contra del "flujo" al que has estado acostumbrado con R base. La solución es entonces seguir anidando tu código! Pero, ¿qué hacer entonces si no te gustan las tuberías, pero también crees que el anidamiento puede ser bastante confuso? La solución puede ser utilizar pestañas para resaltar la jerarquía.
Has cubierto mucho terreno en este tutorial de tuberías R: has visto de dónde viene %>%, qué es exactamente, por qué deberías usarlo y cómo deberías usarlo. Ya has visto que los paquetes dplyr y magrittr funcionan de maravilla juntos, y que hay aún más operadores por ahí. Por último, también has visto algunos casos en los que no deberías utilizarlo cuando estás programando en R y qué alternativas puedes utilizar en esos casos.
Si está interesado en aprender más sobre el Tidyverse, considere el curso Introducción al Tidyverse de DataCamp.
Cursos R
Curso
Curso
Curso
Tutorial
Eladio Montero Porras
Tutorial
Francisco Javier Carrera Arias
Tutorial
Elena Kosourova
Tutorial
DataCamp Team
Tutorial
Carlo Fanara
Tutorial
Łukasz Deryło