Curso
Introducción a R
4 h
3.1M

Elaborar un currículum impresionante no es suficiente para entrar en el mercado laboral de la ciencia de datos. Si deseas iniciar una carrera en ciencia de datos, es fundamental crear un portafolio de proyectos relevantes que demuestren tus habilidades en materia de datos durante la entrevista.
La buena noticia es que nunca es demasiado pronto ni demasiado tarde para empezar a crear un portafolio de este tipo. Tanto si eres un principiante total como si ya estás a mitad de camino en el aprendizaje de la ciencia de datos, puedes empezar a trabajar en tus proyectos de R ahora mismo.
No pasa nada si tus primeros proyectos tienen un aspecto amateur. Siempre puedes volver a ellos más adelante, ampliarlos, perfeccionarlos o incluso eliminarlos cuando realices proyectos más avanzados. Lo más importante aquí es comenzar el proceso.
En este artículo, describiremos algunas ideas útiles para tus proyectos de ciencia de datos con R y veremos algunos ejemplos para que puedas empezar. También hablaremos del lenguaje de programación R y de cómo se utiliza para el análisis de datos y la ciencia de datos.
R es un lenguaje de programación utilizado para el análisis de datos, la ciencia de datos y machine learning, y también incluye un entorno para la computación estadística y los gráficos. R está diseñado específicamente para realizar cálculos estadísticos avanzados y rápidos, modelar datos y crear visualizaciones impactantes. Aquí es donde este lenguaje demuestra su verdadero poder.
Además, R:
Encontrarás más información sobre el lenguaje de programación R y cómo aprenderlo en nuestros artículos ¿Qué es R? - La potencia de la computación estadística y Cómo empezar con R. También puedes realizar el curso de DataCamp Introducción a R.
Para empezar a aprender R desde cero o dominar habilidades técnicas específicas, consulta nuestros diversos recursos de aprendizaje, que incluyen cursos, programas de habilidades e itinerarios profesionales. En concreto, para seguir un programa equilibrado y completo en el aprendizaje de R, ten en cuenta los programas de científico de datos con R y de científico de machine learning con R.
Realizar análisis de datos es el primer paso de cualquier proyecto de ciencia de datos. Es lógico: antes de lanzarnos a predecir escenarios futuros utilizando técnicas de machine learning y aprendizaje profundo, tenemos que revelar el estado actual (y pasado) de las cosas.
Por otro lado, el análisis de datos puede ser una tarea independiente. En ambos casos, R nos ofrece una amplia gama de bibliotecas útiles específicamente adaptadas para fines analíticos.
Con R, podemos analizar los datos de los sitios web, limpiarlos y ordenarlos, visualizarlos, explorar sus estadísticas, formular y comprobar hipótesis, y extraer información y patrones significativos a partir de los datos iniciales. Entre estas tareas, el análisis estadístico y las impresionantes visualizaciones son una verdadera baza de R, y es aquí donde este lenguaje de programación suele superar a su principal rival, Python.
Además de los paquetes multipropósito comunes de R, hay muchos módulos diseñados para diversos problemas analíticos aplicados. Por ejemplo:
Activos: Este paquete está diseñado para analizar y modelar activos financieros.
mdapack: Este es un paquete de análisis de datos médicos.
GEOmap: Este paquete se utiliza para la cartografía topográfica y geológica.
AeRobiology: Esta herramienta computacional es para datos aerobiológicos.
galigor: Esta es una colección de paquetes para marketing en Internet.
lingtypology: Este paquete se utiliza para la tipología lingüística y la cartografía.
Además, R incluye bibliotecas hiperespecializadas como:
Como mencionamos anteriormente, R es un lenguaje de programación orientado a la ciencia de datos que ofrece más de 19 000 paquetes de ciencia de datos. Además de las tareas puramente analíticas enumeradas en la sección anterior, podemos utilizar R para problemas más avanzados con el objetivo de pronosticar y modelar datos desconocidos. El uso de R nos permite:
Una vez más, además de los paquetes de ciencia de datos más utilizados (caret para el entrenamiento de clasificación y regresión, naivebayes para implementar el algoritmo Naive Bayes, randomForest para construir modelos de bosques aleatorios, deepNN para el aprendizaje profundo, etc.), existen muchas bibliotecas altamente especializadas, algunas de ellas realmente específicas. Por mencionar algunos:
OenoKPM: Este paquete se utiliza para modelar la cinética de la producción de CO2 en la fermentación alcohólica.
fHMM: Este paquete está diseñado para ajustar modelos ocultos de Markov a datos financieros.
paleopop: Se trata de un marco de modelización orientado a patrones para modelos paleoclimáticos acoplados de nichos y poblaciones.
ibdsim2: Este paquete se utiliza para simular regiones cromosómicas compartidas por miembros de una familia.
rSHAPE: Este paquete está diseñado para simular la evolución de poblaciones haploides asexuales.
Ahora, vamos a ver algunos ejemplos de proyectos R y a descubrir ideas interesantes para seguir desarrollando, tanto para principiantes como para usuarios experimentados.
Una de las formas más útiles de buscar proyectos R es crear tú mismo ejemplos de este tipo.
No te preocupes, no es tan aterrador como parece. Incluso si eres principiante en ciencia de datos en R, puedes optar por proyectos «sandbox» que incluyen datos listos para ser analizados o modelados, te introducen en el contexto de un problema y te proporcionan orientación útil sobre los pasos a seguir y por qué.
Si eres un estudiante más avanzado, siempre eres bienvenido a explorar los datos más a fondo, desde diferentes ángulos, e ir mucho más allá de las instrucciones sugeridas para satisfacer tu curiosidad sobre los datos. En cualquier caso, el aprendizaje activo mientras se hace es una alternativa mejor que limitarse a leer los proyectos de otras personas.
DataCamp ofrece una amplia selección de proyectos de ciencia de datos en R que te permitirán practicar muchas habilidades técnicas. Algunos ejemplos son la importación y limpieza de datos, la manipulación de datos, la visualización de datos, la probabilidad y la estadística, machine learning y mucho más.
Además de los temas populares (como «Explorar el mercado de Airbnb en Nueva York», «Visualizar la COVID-19», «Agrupar datos de pacientes con enfermedades cardíacas» o «Predecir tarifas de taxi con bosques aleatorios») que se analizan tradicionalmente en diversas escuelas de ciencia de datos, aquí también encontrarás muchos otros nuevos y curiosos. No dudes en explorarlos más a fondo:
Después de revisar los proyectos R existentes o realizar algunos guiados por ti mismo, puedes decidir comenzar a crear tus propios proyectos desde cero. Esto siempre es una buena idea, independientemente de la etapa en la que te encuentres en el aprendizaje de R.
Si estás realizando uno de tus primeros proyectos sin guía, lo primero que debes pensar es dónde encontrar los datos con los que trabajar. Afortunadamente, existen numerosos repositorios populares en línea que ofrecen enormes colecciones de conjuntos de datos gratuitos y bien documentados, tanto reales como sintéticos. Algunos ejemplos destacados de estos recursos son DataLab, Kaggle, UCI Machine Learning Repository, Google Dataset Search, Google Cloud Platform, FiveThirtyEight y Quandl.
Ahora que tienes una gran cantidad de datos, ¿qué puedes hacer exactamente con ellos como principiante en R? Dado que estos serán tus primeros proyectos de ciencia de datos en R, considera realizar tareas básicas de limpieza y manipulación de datos, exploración sencilla de datos y visualización de datos.
Spotify es uno de los mayores servicios digitales de música, vídeo y medios de comunicación, donde puedes encontrar millones de canciones, vídeos y podcasts de todo el mundo.
Puedes utilizar un conjunto de datos ya preparado, Spotify Music Data, que contiene unas 600 canciones más populares durante un periodo de tiempo determinado, y explorar sus estadísticas desde múltiples perspectivas. Por ejemplo, considera analizar los siguientes factores y preguntas, complementando tus conclusiones con gráficos significativos cuando sea necesario:
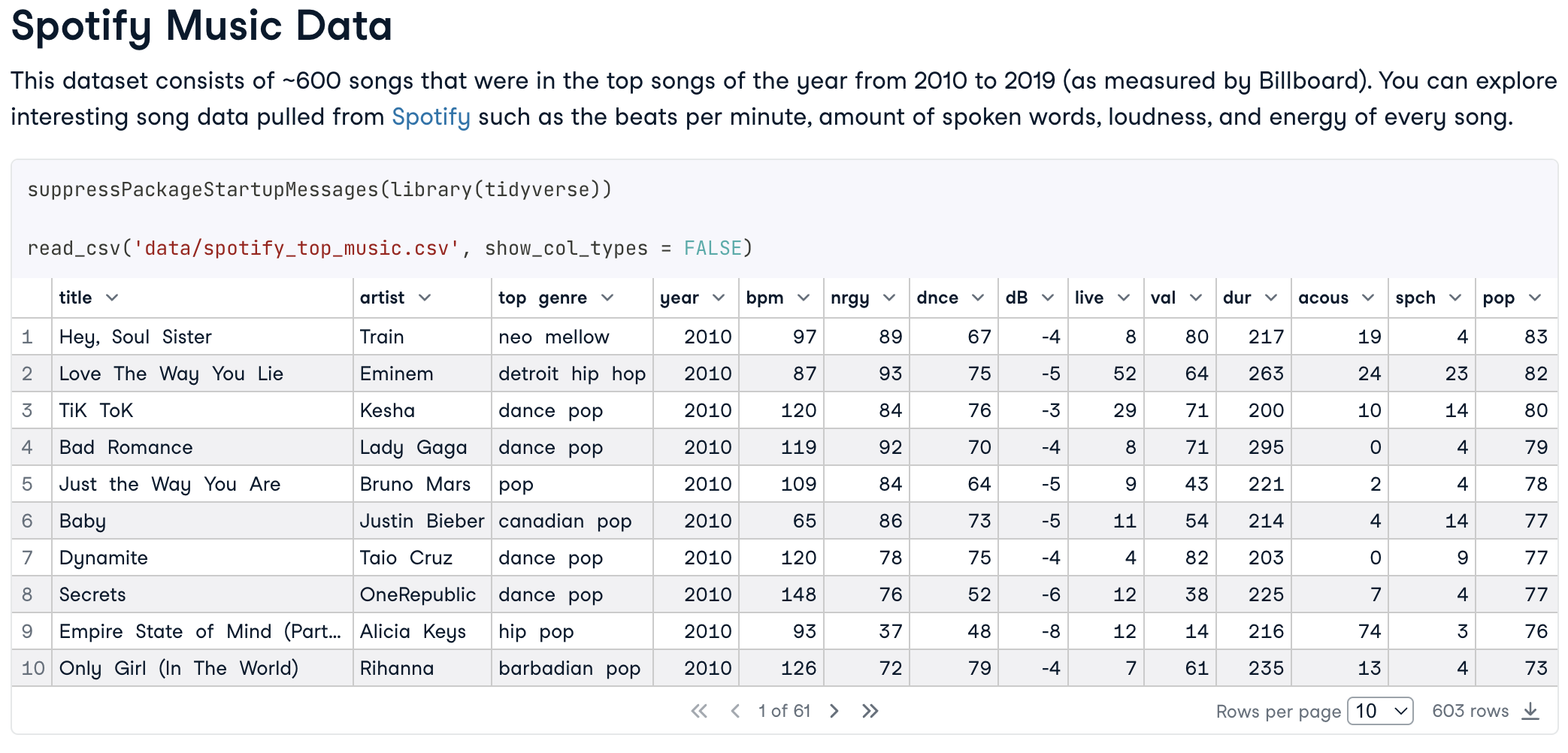
Un ejemplo del proyecto Spotify Music Data R.
La Asociación Nacional de Baloncesto (NBA) es una liga profesional de baloncesto masculino norteamericana compuesta por 30 equipos, una de las más grandes del mundo.
El conjunto de datos de tiros de la NBA contiene los datos recopilados de cuatro jugadores diferentes durante los playoffs de la NBA de 2021. Puedes analizar y visualizar estos datos e intentar responder a las siguientes preguntas:
Un ejemplo del proyecto R sobre estadísticas de tiros de la NBA.
Otra idea interesante para un proyecto R de ciencia de datos para principiantes es investigar las tendencias demográficas mundiales.
El conjunto de datos sobre la población mundial proporciona estadísticas sobre la población total de cada país desde 1960 hasta 2020, así como información adicional por país, como su región, grupo de ingresos y notas especiales (si las hay). Hay varias preguntas que puedes explorar aquí:
No olvides añadir gráficos convincentes siempre que sea útil: ayudarán a tus lectores a comprender mejor las ideas principales de tu análisis.
Si estás a mitad de camino en el aprendizaje de la ciencia de datos en R, es posible que te interese crear proyectos R más sofisticados en los que aplicar tanto tus habilidades de análisis de datos como algunos algoritmos de machine learning.
¿Qué temas puedes seleccionar para ellos? Echemos un vistazo a algunas ideas potenciales para tus proyectos avanzados de ciencia de datos R.
La pérdida de clientes es la tendencia de los clientes a cancelar sus suscripciones a un servicio y, como resultado, dejar de ser clientes de ese servicio. Se calcula como el porcentaje de clientes que han dejado de serlo en un periodo determinado.
Este indicador depende de muchos factores y muestra el bienestar general del negocio de la empresa. Cuando es demasiado alta, la tasa de abandono de clientes representa un grave problema para cualquier empresa, ya que provoca pérdidas de ingresos y daña tu reputación. Por lo tanto, es muy importante poder predecir la tasa de abandono de los clientes para evitarlo.
Puedes utilizar el conjunto de datos sobre la pérdida de clientes en el sector de las telecomunicaciones para crear un proyecto de ciencia de datos sobre la predicción de la tasa de pérdida de clientes en una empresa de telecomunicaciones.
En concreto, en este caso, debes predecir si un cliente te abandonará o no basándote en los datos disponibles y en los factores que aumentan la probabilidad de que un cliente te abandone. Técnicamente, se trata de un problema típico de clasificación de machine learning, en el que los clientes se etiquetan como 1 (baja) o 0 (no baja).
El fraude con tarjetas de crédito es un grave problema en el sector bancario, ya que este ámbito suele gestionar un gran número de transacciones en línea. La detección del fraude con tarjetas de crédito es principalmente un problema de clasificación supervisada en el que podemos aplicar métodos como los k vecinos más cercanos (KNN), la regresión logística, las máquinas de vectores de soporte (SVM) o los árboles de decisión.
Sin embargo, también se puede resolver utilizando enfoques de agrupamiento, reconocimiento de anomalías o redes neuronales artificiales.
Este problema es difícil para el sector bancario en general, ya que los patrones de fraude y las tácticas de los estafadores se perfeccionan constantemente, por lo que los sistemas de detección de fraudes deben adaptarse rápidamente a estos cambios.
Para un científico de datos o un científico especializado en machine learning, el reto también reside en la naturaleza de estos conjuntos de datos: siempre implican un desequilibrio de clases, ya que los casos de fraude son siempre minoritarios (afortunadamente) y están bien ocultos entre las transacciones reales (desafortunadamente).
El conjunto de datos sobre fraude con tarjetas de crédito contiene información sobre transacciones con tarjetas de crédito en el oeste de Estados Unidos. Considera utilizarlo para detectar fraudes con tarjetas de crédito aplicando el enfoque de clasificación.
Como indicación adicional, el modelo debería tender a ser más conservador, lo que significa que, por motivos de seguridad, no es grave etiquetar transacciones como fraudulentas cuando no lo son. También es posible que desees investigar la distribución geoespacial de las tasas de fraude en los diferentes estados.
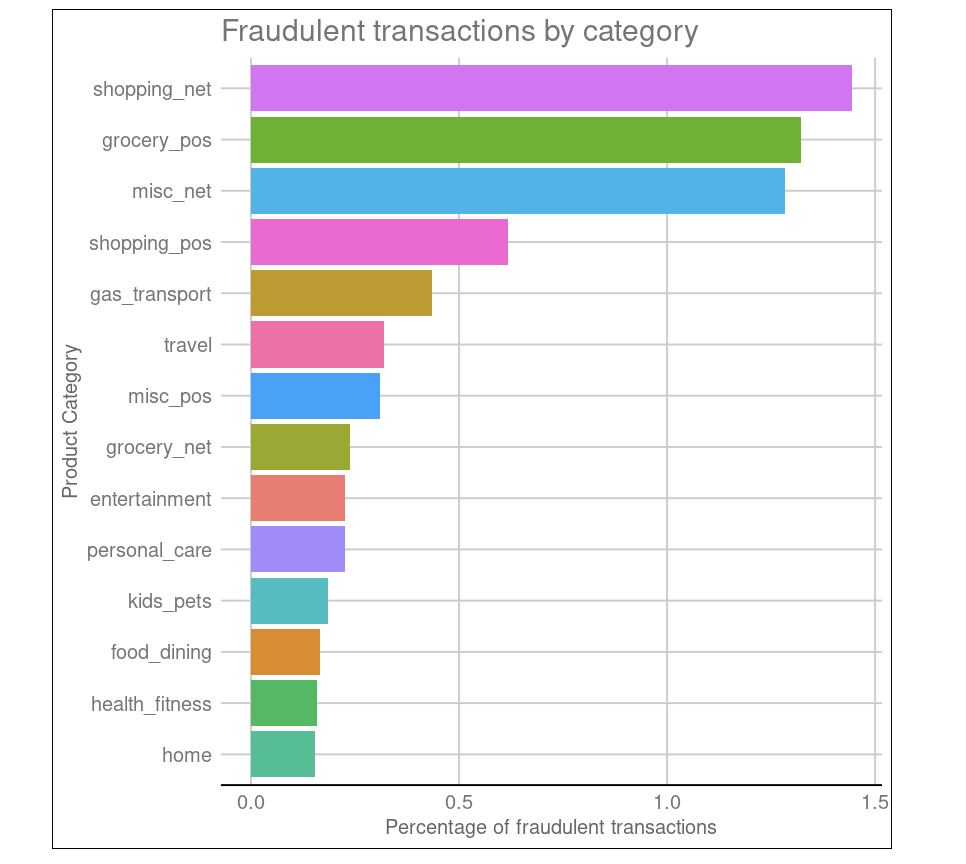
Otro ejemplo de proyecto R de DataCamp
Mientras que los dos proyectos anteriores estaban relacionados con la clasificación de entradas de datos en categorías predefinidas, aquí debes predecir resultados continuos basándote en características de entrada. En otras palabras, debes resolver un problema de regresión aplicando métodos como la regresión lineal, la regresión ridge, la regresión lasso, el árbol de decisión o las máquinas de vectores de soporte (SVM).
El conjunto de datos sobre la demanda de bicicletas compartidas incluye información sobre el número de bicicletas públicas alquiladas en el sistema de bicicletas compartidas de Seúl por hora, el tiempo, la fecha, la hora, si era festivo o no, y mucho más. Tu tarea consiste en predecir el número de bicicletas que se alquilarán basándote en esa información.
También puedes utilizar este proyecto para comparar el número medio de bicicletas alquiladas por franja horaria (mañana, tarde y noche) en las cuatro estaciones del año, explorar la relación entre la temperatura y el número de bicicletas alquiladas, etc. Cuando sea apropiado, añade visualizaciones reveladoras para respaldar tus conclusiones.
Siempre es buena idea incluir en tu portafolio al menos un proyecto que demuestre tu capacidad para aplicar enfoques de aprendizaje no supervisado.
Para ello, consideremos el conjunto de datos de comercio electrónico, que recoge las compras realizadas en una tienda online con sede en el Reino Unido por clientes de diferentes países durante un periodo de tiempo determinado.
Una hipótesis posible es que el minorista quiera hacer un inventario de los artículos disponibles. Como presunto científico de datos que trabaja en esta empresa, debes agrupar los productos en un pequeño número de categorías según su similitud por algunas características comunes (precio, cantidad vendida, etc.). Se trata de un problema de agrupamiento de aprendizaje no supervisado, siendo k-means el algoritmo más popular.
También puedes analizar preguntas adicionales, como cuáles son los cinco países que generan más beneficios o si los pedidos procedentes de países fuera del Reino Unido son significativamente mayores que los pedidos dentro del Reino Unido.
Por último, considera la posibilidad de poner en práctica tus habilidades de procesamiento del lenguaje natural (NLP) en R en uno de tus proyectos.
El conjunto de datos SMS Spam Collection contiene una recopilación de más de 5500 mensajes en inglés etiquetados como spam o no spam («ham»).
Basándote en estos datos, crea un filtro que sea capaz de distinguir con precisión entre mensajes spam y mensajes normales. Para ello, tendrás que utilizar un paquete de PLN de R (por ejemplo, koRpus) para buscar patrones lingüísticos y contextuales en el texto de los mensajes y averiguar qué hace que un mensaje sea spam o ham, para luego generalizar estas observaciones sobre los nuevos datos.
Opcionalmente, puedes investigar cuáles son las palabras más propensas al spam creando una visualización de nube de palabras.
Para terminar, hemos hablado de por qué es importante crear un portafolio de proyectos para iniciar una carrera en ciencia de datos, por qué y cómo utilizar R para el análisis de datos y la ciencia de datos, dónde encontrar datos relevantes y ejemplos de proyectos R, y qué temas puedes desarrollar en esos proyectos, tanto si eres principiante como si tienes un nivel avanzado en ciencia de datos.
Por supuesto, las ideas sugeridas para tus proyectos son solo la punta del iceberg. Con R, puedes hacer mucho más: crear sistemas de recomendación, realizar segmentaciones de clientes, pronosticar cotizaciones bursátiles, llevar a cabo análisis de la opinión de los clientes, identificar el posicionamiento óptimo de los taxis y muchas otras cosas.
Tanto si tu objetivo es convertirte en científico de datos con R, analista de datos con R, científico de machine learning con R o estadístico con R, demostrar tus habilidades a través de proyectos prácticos tiene un valor incalculable. La amplia biblioteca y el soporte de la comunidad de R lo convierten en la opción ideal para el análisis de datos, machine learning y la computación estadística avanzada.
Al comenzar con proyectos sencillos y abordar progresivamente retos más complejos, puedes crear un portafolio que no solo demuestre tu destreza técnica, sino también tu capacidad para obtener información significativa a partir de los datos. Esta experiencia práctica no solo impresionará a los posibles empleadores, sino que también te preparará para los retos diversos y dinámicos a los que te enfrentarás en tu carrera profesional en el campo de la ciencia de datos.
Si deseas obtener más inspiración, visita DataLab, un IDE en línea con conjuntos de datos precargados y plantillas predefinidas para escribir código y analizar datos que te ayudarán a pasar del aprendizaje a la práctica de la ciencia de datos.
Cursos para R
Curso
Curso
Curso
blog
Summer Worsley
15 min
blog
Javier Canales Luna
8 min
blog
Javier Canales Luna
13 min
Tutorial
Adel Nehme
Tutorial
Francisco Javier Carrera Arias
