LlamaIndex is a data framework for Large Language Models (LLMs) based applications. LLMs like GPT-4 come pre-trained on massive public datasets, allowing for incredible natural language processing capabilities out of the box. However, their utility is limited without access to your own private data.
LlamaIndex lets you ingest data from APIs, databases, PDFs, and more via flexible data connectors. This data is indexed into intermediate representations optimized for LLMs. LlamaIndex then allows natural language querying and conversation with your data via query engines, chat interfaces, and LLM-powered data agents. It enables your LLMs to access and interpret private data on large scales without retraining the model on newer data.
Whether you're a beginner looking for a simple way to query your data in natural language or an advanced user requires deep customization, LlamaIndex provides the tools. The high-level API allows getting started in just five lines of code, while lower-level APIs allow full control over data ingestion, indexing, retrieval, and more.
How LlamaIndex Works?
LlamaIndex uses Retrieval Augmented Generation (RAG) systems that combine large language models with a private knowledge base. It generally consists of two stages: the indexing stage and the querying stage.
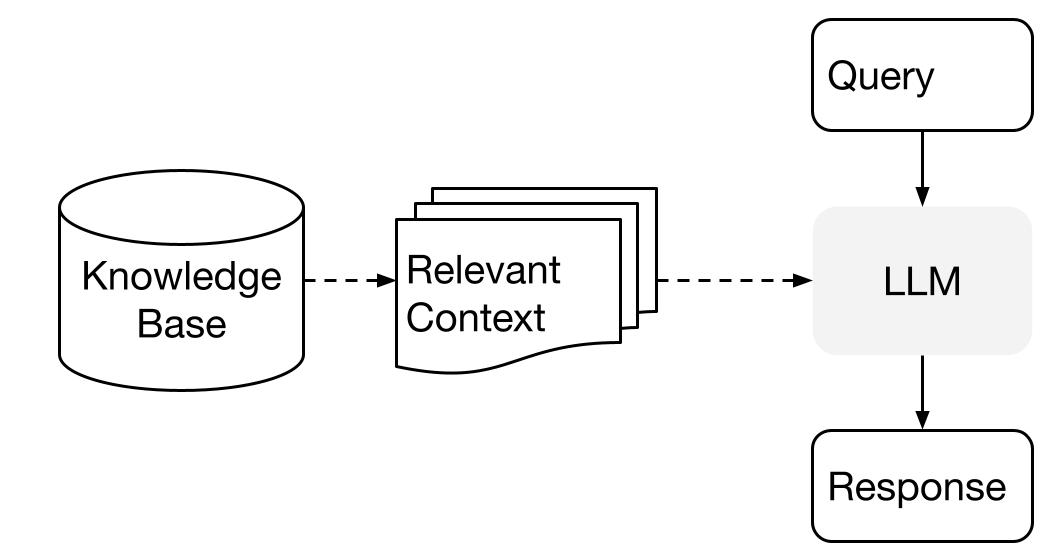
Image from High-Level Concepts
Indexing stage
LlamaIndex will efficiently index private data into a vector index during the indexing stage. This step helps create a searchable knowledge base specific to your domain. You can input text documents, database records, knowledge graphs, and other data types.
Essentially, indexing converts the data into numerical vectors or embeddings that capture its semantic meaning. It enables quick similarity searches across the content.
Querying stage
During the querying stage, the RAG pipeline searches for the most relevant information based on the user's query. This information is then given to the LLM, along with the query, to create an accurate response.
This process allows the LLM to have access to current and updated information that may not have been included in its initial training.
The main challenge during this stage is retrieving, organizing, and reasoning over potentially multiple knowledge bases.
Learn more about RAG in our code-along on Retrieval Augmented Generation with PineCone.
Setting up LlamaIndex
Before we dive into our LlamaIndex tutorial and project, we have to install the Python package and set up the API.
We can simply install LlamaIndex using pip.
pip install llama-indexBy default, LlamaIndex uses OpenAI GPT-3 text-davinci-003 model. To use this model, you must have an OPENAI_API_KEY setup. You can create a free account and get an API key by logging into OpenAI’s new API token.
import os
os.environ["OPENAI_API_KEY"] = "INSERT OPENAI KEY"Also, make sure you have installed the openai package.
pip install openaiAdding Personal Data to LLMs using LlamaIndex
In this section, we will learn to use LlamaIndex to create a resume reader. You can download your resume by going on to the Linkedin profile page, clicking on More, and then Save to PDF.
Please note that we are using DataLab for running the Python code. You can access all relevant code and output in the LlamaIndex: Adding Personal Data to LLMs workbook; you can easily create your own copy to run all the code without having to install anything on your computer!
Before running anything, we must install llama-index, openai, and pypdf. We are installing pypdf so that we can read and convert PDF files.
%pip install llama-index openai pypdfLoading data and creating the index
We have a directory named "Private-Data" containing only one PDF file. We will use the SimpleDirectoryReader to read it and then convert it into an index using the TreeIndex.
from llama_index import TreeIndex, SimpleDirectoryReader
resume = SimpleDirectoryReader("Private-Data").load_data()
new_index = TreeIndex.from_documents(resume)Running a query
Once the data has been indexed, you can begin asking questions by using as_query_engine(). This function enables you to ask questions about specific information within the document and receive a corresponding response with the help of OpenAI GPT-3 text-davinci-003 model.
Note: you can set up the OpenAI API in DataLab by following Using GPT-3.5 and GPT-4 via the OpenAI API in Python tutorial.
As we can see, the LLM model has accurately responded to the query. It searched the index and found the relevant information.
query_engine = new_index.as_query_engine()
response = query_engine.query("When did Abid graduated?")
print(response)Abid graduated in February 2014.We can inquire further about certification. It seems that LlamaIndex has gained a complete understanding of the candidate, which can be advantageous for companies seeking particular individuals.
response = query_engine.query("What is the name of certification that Abid received?")
print(response)Data Scientist ProfessionalSaving and loading the context
Creating an index is a time-consuming process. We can avoid re-creating indexes by saving the context. By default, the following command will save the index store in the ./storage directory.
new_index.storage_context.persist()
Once that is done, we can quickly load the storage context and create an index.
from llama_index import StorageContext, load_index_from_storage
storage_context = StorageContext.from_defaults(persist_dir="./storage")
index = load_index_from_storage(storage_context)To verify that it is functioning correctly, we will ask the query engine the question from the resume. It appears that we have successfully loaded the context.
query_engine = index.as_query_engine()
response = query_engine.query("What is Abid's job title?")
print(response)Abid's job title is Technical Writer.Chatbot
Instead of Q&A, we can also use LlamaIndex to create a personal Chatbot. We just have to initialize the index with the as_chat_engine() function.
We will ask a simple question.
query_engine = index.as_chat_engine()
response = query_engine.chat("What is the job title of Abid in 2021?")
print(response)Abid's job title in 2021 is Data Science Consultant.And without giving additional context, we will ask follow-up questions.
response = query_engine.chat("What else did he do during that time?")
print(response)In 2021, Abid worked as a Data Science Consultant for Guidepoint, a Writer for Towards Data Science and Towards AI, a Technical Writer for Machine Learning Mastery, an Ambassador for Deepnote, and a Technical Writer for Start It Up.It is evident that the chat engine is functioning flawlessly.
After building your language application, the next step on your timeline is to read about the pros and cons of using Large Language Models (LLMs) in the cloud versus running them locally. This will help you determine which approach works best for your needs.
Building Wiki Text to Speech with LlamaIndex
Our next project involves developing an application that can respond to questions sourced from Wikipedia and convert them into speech.
The code source and additional information are available in this DataLab workbook.
Web scraping Wikipedia page
First, we will scrape the data from Italy - Wikipedia webpage and save it as italy_text.txt file in the data folder.
from pathlib import Path
import requests
response = requests.get(
"https://en.wikipedia.org/w/api.php",
params={
"action": "query",
"format": "json",
"titles": "Italy",
"prop": "extracts",
# 'exintro': True,
"explaintext": True,
},
).json()
page = next(iter(response["query"]["pages"].values()))
italy_text = page["extract"]
data_path = Path("data")
if not data_path.exists():
Path.mkdir(data_path)
with open("data/italy_text.txt", "w") as fp:
fp.write(italy_text)
Loading the data and building the index
Next, we need to install the necessary packages. The elevenlabs package allows us to easily convert text to speech using an API.
%pip install llama-index openai elevenlabsBy using SimpleDirectoryReader we will load the data and convert the TXT file into a vector store using VectorStoreIndex.
from llama_index import VectorStoreIndex, SimpleDirectoryReader
from IPython.display import Markdown, display
from llama_index.tts import ElevenLabsTTS
from IPython.display import Audio
documents = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(documents)Query
Our plan is to ask a general question about the country and receive a response from the LLM query_engine.
query = "Tell me an interesting fact about the country?"
query_engine = index.as_query_engine()
response = query_engine.query(query)
display(Markdown(f"<b>{query}</b>"))
display(Markdown(f"<p>{response}</p>"))
Text to speech
After that, we will use the llama_index.tts module to access the ElevenLabsTTS api. You need to provide ElevenLabs API key to initiate the audio generation function. You can get an API key at ElevenLabs website for free.
import os
elevenlabs_key = os.environ["ElevenLabs_key"]
tts = ElevenLabsTTS(api_key=elevenlabs_key)We will add the response to the generate_audio function to generate natural voice. To listen to the audio, we will use IPython.display’s Audio function.
audio = tts.generate_audio(str(response))
Audio(audio)
This is a simple example. You can use multiple modules to create your assistant, like Siri, that responds to your questions by interpreting your private data. For more information, please refer to the LlamaIndex documentation.
In addition to LlamaIndex, LangChain also allows you to build LLM-based applications. Additionally, you can read Introduction to LangChain for Data Engineering & Data Applications to understand an overview of what you can do with LangChain, including the problems that LangChain solves and examples of data use cases.
LlamaIndex Use Cases
LlamaIndex provides a complete toolkit to build language-based applications. On top of that, you can use various data loaders and agent tools from Llama Hub to develop complex applications with multiple functionalities.
You can connect custom data sources to your LLM with one or more plugins Data Loaders.
Data Loaders from Llama Hub
You can also use Agent tools to integrate third-party tools and APIs.
Agent Tools from Llama Hub
In short, you can use LlamaIndex to build:
- Q&A over Documents
- Chatbots
- Agents
- Structured Data
- Full-Stack Web Application
- Private Setup
To learn about these use cases in detail, head to the LlamaIndex documentation.
Conclusion
LlamaIndex provides a powerful toolkit for building retrieval-augmented generation systems that combine the strengths of large language models with custom knowledge bases. It enables creating an indexed store of domain-specific data and leveraging it during inference to provide relevant context to the LLM to generate high-quality responses.
In this tutorial, we learned about LlamaIndex and how it works. Additionally, we built a resume reader and text-to-speech project with only a few lines of Python code. Creating an LLM application with LlamaIndex is simple, and it offers a vast library of plugins, data loaders, and agents.
To become an expert LLM developer, the next natural step is to enroll in the Master Large Language Models Concepts course. This course will give you a comprehensive understanding of LLMs, including their applications, training methods, ethical considerations, and the latest research.



